分布式数据库-事务一致性
version: v-2023060601
author: 路__
一、什么是“强一致性”

分布式数据库的“强一致性”应该包含两个方面:serializability(串行) and linearizability(线性一致),上述图为“Highly Available Transactions: Virtues and Limitations”论文中对于一致性模型的介绍。图中箭头表示一致性模型之间的关系。对于异步网络上的分布式系统,颜色表示每个模型的可用性。本次内容主要围绕“serializability”介绍,从左侧图从我们应该看出了事务的隔离级别,下面我们就从事务入手开始本篇内容。
讲到事务想到的就是“ACID”和“BASA”理论,在NoSQL数据库中base理论应该是比较经典的。
二、事务的介绍
2.1 那么什么是Base呢?
-
BA表示基本可用性(Basically Available):是指某些部分出现故障,那么系统的其余部分依然可用。
-
S表示软状态(Soft State):是指数据处理过程中,存在数据状态暂时不一致的情况,但最终会实现事务的一致性。
-
E表示最终一致性(Eventual Consistency):是指单数据项的多副本,经过一段时间,最终达成一致。
Base其实是一套理论,所以很多实现细节并没有指定,所做的约束也是十分有限。从base的三个特性与ACID相比,我们也感觉到,其理论是在性能和一致性中达到一个平衡。
2.2 ACID是什么呢?
说到ACID我们想到的第一个就是“事务”,“事务”是由多个操作构成的序列。1970年詹姆斯 · 格雷(Jim Gray)提出了事务的ACID四大特性:
-
原子性(Atomicity):事务中的所有变更要么全部发生,要么一个也不发生。
介绍:是数据库区别于其他存储系统的重要标志,对于现在阶段的分布式数据库具有挑战,因为网络的不可靠性,所以很多NoSQL数据库都选择跳过这个问题,从对原子性不敏感的细分场景切入。
-
一致性(Consistency):事务要保持数据的完整性。
介绍: 可以看做对“事务”整体目标的阐述。
-
隔离性(Isolation):多事务并行执行所得到的结果,与串行执行(一个接一个)完全相同。
介绍:其是事务中最为复杂的,隔离性可以分为多个隔离级别,较低的隔离级别就是在正确性上做妥协,从而获得更好的性能。
-
持久性(Durability):一旦事务提交,它对数据的改变将被永久保留,不应受到任何系统故障的影响。
介绍: 数据库的基本要求,其核心思想是应对系统故障,我们可以将故障分为两个:
存储硬件无损、可恢复的故障: 主要依托于预写日志(Write Ahead Log, WAL)保证第一时间存储数据。WAL采用顺序写入的方式,可以保证数据库的低延时响应。
存储硬件损坏、不可恢复的故障:用到日志复制技术,将本地日志及时同步到其他节点,也即是备份,实现高可用功能,此处为日志备份。
实现方式大体有三种:
第一种是单体数据库自带的同步或半同步的方式,其中半同步方式具有一定的容错能力,实践中被更多采用;
第二种是将日志存储到共享存储系统上,后者会通过冗余存储保证日志的安全性,亚马逊的Aurora采用了这种方式,也被称为Share Storage;
第三种是基于Paxos/Raft的共识算法同步日志数据,在分布式数据库中被广泛使用。
事务中非常重要的一个特性就是隔离性,下面我们针对性的学习隔离性。
2.3. 隔离性
ANSI SQL-92(简称SQL-92),它定义的隔离级别和异常现象如下所示:
| 隔离级别 | 脏读 (Dirty Read) | 不可重复读(Non-Repeatable) | 幻读 (Phantom) |
|---|---|---|---|
| 读未提交(Read Uncommitted) | 会 | 会 | 会 |
| 读已提交(Read Committed) | 不会 | 会 | 会 |
| 可重复读(Repeatable Read) | 不会 | 不会 | 会 |
| 串行化(Serializable) | 不会 | 不会 | 不会 |
脏读 (Dirty Read):是一个事务读取了另一个事务未提交的数据。
在不久之后的1995年,Jim Gray等人发表了论文“A Critique of ANSI SQL Isolation Levels”(以下简称Critique),对于事务隔离性进行了更加深入的分析。
2.3.1 Critique
Critique中定义了六种隔离级别和八种异常现象。
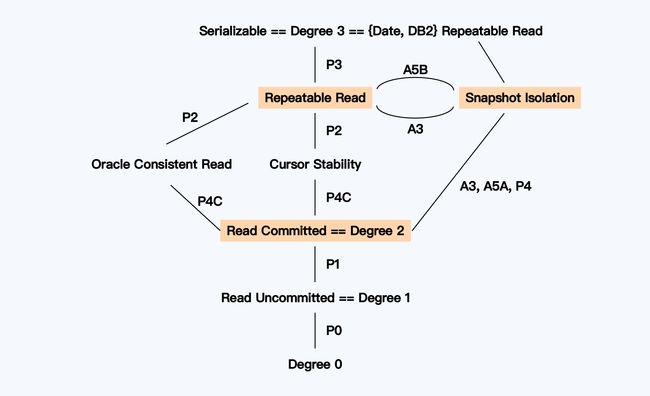
快照隔离(Snapshot Isolation, SI)级别:
可以用于解决幻读(Phantom),之前解决幻读问题的就是可串行化。但却无法处理写倾斜(Write Skew)问题,也不符合可串行化要求,有时写倾斜也被称为写偏序,都是一个意思。
因此,今天,使用最广泛的隔离级别有四个,就是已提交读、可重复读、快照隔离、可串行化。
SQL-92没有添加SI的原因是,其出发点是基于锁(Lock-base)的并发控制,而快照隔离的实现基础则是多版本并发控制(MVCC),在现在很多数据都采用了MVCC进行实现,例如图数据库中的TuGraph其采用的便是MVCC。
1.幻读(Phantom)
幻读指在同一事务内多次执行相同查询时,可能会看到不同的行数或记录。幻读也是因为数据库没有对同时进行的事务进行隔离而产生的问题。解决使用表级锁。
场景:事务T1使用特定的查询条件获得一个结果集,事务T2插入新的数据,并且这些数据符合T1刚刚执行的查询条件。T2 提交成功后,T1再次执行同样的查询,此时得到的结果集会增大。这种异常现象就是幻读。
幻读与不可重复差异:
-
相同:都是在一个事务内用相同的条件查询两次,但两次的结果不一样。
-
差异:
1.不可重复读来说,第二次的结果集相对第一次,有些记录被修改(Update)或删除(Delete)了;
2.幻读是第二次结果集里出现了第一次结果集没有的记录(Insert)。幻读是在第一次结果集的记录“间隙”中增加了新的记录。所以,MySQL将防止出现幻读的锁命名为间隙锁(Gap Lock)。
2. 写倾斜
下面通过一个案例来理解写倾斜: 在我们的用户表(user)中有以下数据
| id(用户标识) | sex(性别) |
|---|---|
| 1 | 0 |
| 2 | 1 |
| 3 | 0 |
| 4 | 1 |
上述0代表女,1代表男,下面我们有两个事务需要并发执行语句如下:
// 语句1: 将表中所有女变成男
begin
update user set sex = 1
where sex = 0
commit
// 语句2: 将表中所有男变成女
begin
update user set sex = 0
where sex = 1
commit在并发执行的情况下,上述结果会发生一半是男一半是女的情况。但是根据可串行化的定义,“多事务并行执行所得到的结果,与串行执行完全相同”,如果按照串行执行,那么要么都是男,要么都是女,这就违背了可串行化的定义了。