EM算法与变分推断
一、EM算法
目的:找到含有潜变量模型的极大似然解
应用背景:对于某些数据直接估计模型参数较为困难,但通过引入潜变量可以降低模型的求解难度。但引入潜变量后怎样来求解?——EM算法。
1. 直观感受EM算法
对对数似然函数 log P ( X ∣ θ ) \log P(X|\theta) logP(X∣θ)有 log P ( X ∣ θ ) = log ∑ Z P ( X , Z ∣ θ ) \log P(X|\theta)=\log \sum_Z{P(X,Z|\theta)} logP(X∣θ)=log∑ZP(X,Z∣θ),这样处理的目的是为了引入潜变量,但这样同时也会导致如下两个问题
- 求和操作在对数里面使得对数运算无法直接作用在联合分布上
- 由于 Z Z Z是隐变量,我们无法得知关于它的信息
为了解决以上这两个问题,我们可以将 arg max θ log P ( X ∣ θ ) \arg\max_{\theta}\log P(X|\theta) argmaxθlogP(X∣θ)近似为
arg max θ ∑ Z P ( Z ∣ X , θ ) log P ( X , Z ∣ θ ) (1) \arg\max_{\theta}\sum_ZP(Z|X,\theta)\log P(X,Z|\theta) \tag{1} argθmaxZ∑P(Z∣X,θ)logP(X,Z∣θ)(1)
(为什么可以这样近似在后面会讲述),近似后的目标函数相比于原目标函数的优势在于
- 求和符号从对数里面提到了对数外面降低了处理难度
- ∑ Z P ( X , Z ∣ θ ) \sum_ZP(X,Z|\theta) ∑ZP(X,Z∣θ)不好直接处理,但对转化后的目标函数,我们可以利用已知数据对 Z Z Z进行推断得到 P ( Z ∣ X , θ ) P(Z|X,\theta) P(Z∣X,θ),再利用推断得到的 P ( Z ∣ X , θ ) P(Z|X,\theta) P(Z∣X,θ)来进行求和
在近似处理结束后,对于目标 θ ∗ = arg max θ ∑ Z P ( Z ∣ X , θ ) log P ( X , Z ∣ θ ) \theta^*=\arg\max_{\theta}\sum_ZP(Z|X,\theta)\log P(X,Z|\theta) θ∗=argmaxθ∑ZP(Z∣X,θ)logP(X,Z∣θ),可以采用交替更新的方式来对目标进行求解,具体来说求解算法包括两步(这两步分别被称为E步和M步):
- E步:在E步中我们利用数据和现有参数(记为 θ o l d \theta^{old} θold)来对Z的概率进行推断,并用得到的 P ( Z ∣ X , θ o l d ) P(Z|X,\theta^{old}) P(Z∣X,θold)计算 Q ( θ , θ o l d ) = ∑ Z P ( Z ∣ X , θ o l d ) log P ( X , Z ∣ θ ) Q(\theta,\theta^{old})=\sum_ZP(Z|X,\theta^{old})\log P(X,Z|\theta) Q(θ,θold)=∑ZP(Z∣X,θold)logP(X,Z∣θ),因为这里利用 P ( Z ∣ X , θ o l d ) P(Z|X,\theta^{old}) P(Z∣X,θold)对 log P ( X , Z ∣ θ ) \log P(X,Z|\theta) logP(X,Z∣θ)进行了期望运算,进而这一步也被称为E(Expectation)步。
- M步:在M步中对于E步所获得的期望 Q ( θ , θ o l d ) Q(\theta,\theta^{old}) Q(θ,θold),我们寻找最优的新参数 θ n e w = arg max θ Q ( θ , θ o l d ) \theta^{new}=\arg\max_{\theta}Q(\theta,\theta^{old}) θnew=argmaxθQ(θ,θold),并令 θ o l d = θ n e w \theta^{old}=\theta^{new} θold=θnew在这一步骤中因为涉及到了最大化期望,因而它也被称为M(Maximization)步
通过不断交替重复E步和M步,直至收敛条件满足或达到最大迭代次数,得到参数 θ \theta θ
2. 从数学角度推导EM
在这里我们假设潜变量 Z Z Z服从分布 q ( Z ) q(Z) q(Z)则
log P ( X ∣ θ ) = ∑ Z q ( Z ) log P ( X ∣ θ ) = ∑ Z q ( Z ) log ( P ( X ∣ θ ) P ( X , Z ∣ θ ) P ( X , Z ∣ θ ) q ( Z ) q ( Z ) ) = ∑ Z q ( Z ) log ( q ( Z ) P ( Z ∣ X , θ ) ) + ∑ Z q ( Z ) log P ( X , Z ∣ θ ) q ( Z ) = ∑ Z q ( Z ) log ( q ( Z ) P ( Z ∣ X , θ ) ) + ∑ Z q ( Z ) log P ( X , Z ∣ θ ) − ∑ Z q ( Z ) log q ( Z ) = K L ( q ( Z ) ∣ ∣ P ( Z ∣ X , θ ) ) + ∑ Z q ( Z ) log P ( X , Z ∣ θ ) + H ( Z ) \begin{aligned} \log P(X|\theta)=\sum_Z{q(Z)\log P(X|\theta)}&=\sum_Z{q(Z)\log(\frac{P(X|\theta)}{P(X,Z|\theta)}\frac{P(X,Z|\theta)}{q(Z)}q(Z))}\\ &=\sum_Z{q(Z)\log(\frac{q(Z)}{P(Z|X,\theta)})}+\sum_Z{q(Z)\log \frac{P(X,Z|\theta)}{q(Z)}}\\ &=\sum_Z{q(Z)\log(\frac{q(Z)}{P(Z|X,\theta)})}+\sum_Z{q(Z)\log P(X,Z|\theta)}-\sum_Z{q(Z)\log q(Z)}\\ &=KL(q(Z)||P(Z|X,\theta))+\sum_Z{q(Z)\log P(X,Z|\theta)}+H(Z) \end{aligned} logP(X∣θ)=Z∑q(Z)logP(X∣θ)=Z∑q(Z)log(P(X,Z∣θ)P(X∣θ)q(Z)P(X,Z∣θ)q(Z))=Z∑q(Z)log(P(Z∣X,θ)q(Z))+Z∑q(Z)logq(Z)P(X,Z∣θ)=Z∑q(Z)log(P(Z∣X,θ)q(Z))+Z∑q(Z)logP(X,Z∣θ)−Z∑q(Z)logq(Z)=KL(q(Z)∣∣P(Z∣X,θ))+Z∑q(Z)logP(X,Z∣θ)+H(Z)
这里注意到 H ( Z ) H(Z) H(Z)是与 X , θ X,\theta X,θ无关的,我们不考虑它,从而得到一个新的目标函数
L = K L ( q ( Z ) ∣ ∣ P ( Z ∣ X , θ ) ) + ∑ Z q ( Z ) ln P ( X , Z ∣ θ ) (2) \mathcal{L}=KL(q(Z)||P(Z|X,\theta))+\sum_Z{q(Z)\ln P(X,Z|\theta)}\tag{2} L=KL(q(Z)∣∣P(Z∣X,θ))+Z∑q(Z)lnP(X,Z∣θ)(2)
注意式(2)中的第二部分与式(1)很像。在这里,最大化 L \mathcal{L} L等价于最大化似然函数 log P ( X ∣ θ ) \log P(X|\theta) logP(X∣θ). 对目标函数 L \mathcal{L} L我们可以采取两步优化的方式来最大化。
- 优化KL散度: L \mathcal{L} L在 θ \theta θ( θ = θ o l d \theta=\theta^{old} θ=θold)给定的时候是一个定值,此时最小化KL散度可以使 ∑ Z q ( Z ) log P ( X , Z ∣ θ o l d ) \sum_Z{q(Z)\log P(X,Z|\theta^{old})} ∑Zq(Z)logP(X,Z∣θold)最大。由KL散度的性质不难得到当 q ( Z ) = p ( Z ∣ X , θ o l d ) q(Z)=p(Z|X,\theta^{old}) q(Z)=p(Z∣X,θold)时KL散度最小其值为0. 当 q ( Z ) = p ( Z ∣ X , θ o l d ) q(Z)=p(Z|X,\theta^{old}) q(Z)=p(Z∣X,θold), K L ( q ( Z ) ∣ ∣ P ( Z ∣ X , θ o l d ) ) = 0 KL(q(Z)||P(Z|X,\theta^{old}))=0 KL(q(Z)∣∣P(Z∣X,θold))=0,这时 L = ∑ Z q ( Z ∣ X , θ o l d ) log P ( X , Z ∣ θ o l d ) \mathcal{L}=\sum_Z{q(Z|X,\theta^{old})\log P(X,Z|\theta^{old})} L=∑Zq(Z∣X,θold)logP(X,Z∣θold),正好是EM算法E步的Q函数的形式。
- 最大化 L \mathcal{L} L : arg max θ ∑ Z P ( Z ∣ X , θ o l d ) log P ( X , Z ∣ θ ) \arg\max_\theta\sum_ZP(Z|X,\theta^{old})\log P(X,Z|\theta) argmaxθ∑ZP(Z∣X,θold)logP(X,Z∣θ),此时最大化 L \mathcal{L} L等价于最大化似然函数。同时由于 θ \theta θ的更新导致 q ( Z ) = P ( Z ∣ X , θ o l d ) ≠ P ( Z ∣ X , θ n e w ) q(Z)=P(Z|X,\theta^{old})\ne P(Z|X,\theta^{new}) q(Z)=P(Z∣X,θold)=P(Z∣X,θnew),这会使得KL散度不再为0导致 L \mathcal{L} L上升,同时KL不为0又使得我们可以进行新的一轮优化。这也是EM算法为什么可以最大化似然函数的原因。
整个过程的示意图如下: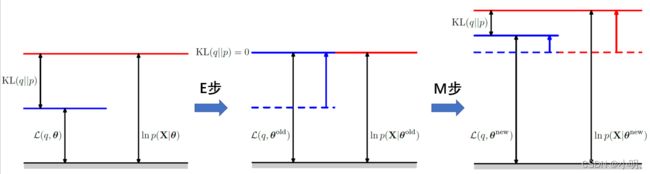
注:
- 省略 H ( Z ) H(Z) H(Z)是否合理:在E步中通过 q ( Z ) = P ( Z ∣ X , θ o l d ) q(Z)=P(Z|X,\theta^{old}) q(Z)=P(Z∣X,θold)来估计 q ( Z ) q(Z) q(Z)。在得到 q ( Z ) q(Z) q(Z)的估计后 log P ( X ∣ θ ) \log P(X|\theta) logP(X∣θ)变为 log P ( X ∣ θ ) = ∑ Z q ( Z ∣ X , θ o l d ) log P ( X , Z ∣ θ ) + ∑ Z q ( Z ∣ X , θ o l d ) log q ( Z ∣ X , θ o l d ) \log P(X|\theta)=\sum_Z{q(Z|X,\theta^{old})\log P(X,Z|\theta)}+\sum_Z{q(Z|X,\theta^{old})\log q(Z|X,\theta^{old})} logP(X∣θ)=∑Zq(Z∣X,θold)logP(X,Z∣θ)+∑Zq(Z∣X,θold)logq(Z∣X,θold)。显然 H ( Z ) H(Z) H(Z)在这个时候是定值与 θ \theta θ无关,因此在优化时省略掉也是合理的。
- 在这里可以把 ∑ Z q ( Z ) log P ( X ∣ θ ) \sum_Z{q(Z) \log P(X|\theta)} ∑Zq(Z)logP(X∣θ)换为 E q ( Z ) log P ( X ∣ θ ) E_{q(Z)}\log P(X|\theta) Eq(Z)logP(X∣θ)也成立(后者是更一般的情况)。
二、变分推断
变分推断(Variational Inference, VI)
目的:近似推断后验分布 P ( Z ∣ X ) P(Z|X) P(Z∣X)
核心思想:假设一个密度族,然后再在密度族中找出一个与目标密度最为接近的密度。(一般两个密度之间的距离用KL散度刻画。)
1. ELBO的引入
这里尝试从两个不同的角度分别引入ELBO
a. 近似推断
由于对 P ( Z ∣ X ) P(Z|X) P(Z∣X)的推断较为困难(潜在空间维度高或 P ( Z ∣ X ) P(Z|X) P(Z∣X)的形式复杂)。因此尝试在一个密度函数族 Q Q Q中找到一个 q ( Z ) q(Z) q(Z)使其与 P ( Z ∣ X ) P(Z|X) P(Z∣X)尽可能接近即 q ∗ ( Z ) = arg min q ( Z ) ∈ Q K L ( q ( Z ) ∣ ∣ P ( Z ∣ X ) ) q^*(Z)=\arg\min_{q(Z)\in Q}KL(q(Z)||P(Z|X)) q∗(Z)=argminq(Z)∈QKL(q(Z)∣∣P(Z∣X))。其中(这一部分的 E [ ⋅ ] E[\cdot] E[⋅]是关于分布 q ( Z ) q(Z) q(Z)求期望)
arg min q ∗ ( Z ) ∈ Q K L ( q ( Z ) ∣ ∣ P ( Z ∣ X ) ) = E [ log q ( Z ) ] − E [ log P ( Z ∣ X ) ] = E [ log q ( Z ) ] − E [ log P ( X , Z ) ] + E [ log P ( X ) ] \begin{aligned} \arg\min_{q^*(Z)\in Q}KL(q(Z)||P(Z|X))&=E[\log q(Z)]-E[\log P(Z|X)]\\ &=E[\log q(Z)]-E[\log P(X,Z)]+E[\log P(X)] \end{aligned} argq∗(Z)∈QminKL(q(Z)∣∣P(Z∣X))=E[logq(Z)]−E[logP(Z∣X)]=E[logq(Z)]−E[logP(X,Z)]+E[logP(X)]
但这个目标并不好优化,因为其中含有 P ( X ) P(X) P(X),而 P ( X ) = ∫ Z P ( X , Z ) d Z P(X)=\int_Z P(X,Z)dZ P(X)=∫ZP(X,Z)dZ计算起来较为困难。但我们注意到 P ( X ) P(X) P(X)与 q ( Z ) q(Z) q(Z)没有直接联系,因此对目标函数进行转化,得到以下等价目标函数证据下界 (evidence lower bound, ELBO)。
E L B O ( q ) = E [ log P ( X , Z ) ] − E [ log q ( Z ) ] ELBO(q)=E[\log P(X,Z)]-E[\log q(Z)] ELBO(q)=E[logP(X,Z)]−E[logq(Z)]
ELBO等于负的KL散度加上 log P ( X ) \log P(X) logP(X),因此最大化 E L B O ( q ) ELBO(q) ELBO(q)等价于最小化 K L ( q ( Z ) ∣ ∣ P ( Z ∣ X ) ) KL(q(Z)||P(Z|X)) KL(q(Z)∣∣P(Z∣X))。此外对ELBO的表达式还可以有以下直观理解:
-
ELBO可以进行如下转化
E L B O ( q ) = E [ log P ( X , Z ) ] − E [ log q ( Z ) ] = E [ log P ( X ∣ Z ) ] + E [ log P ( Z ) ] − E [ log q ( Z ) ] = E [ log P ( X ∣ Z ) ] − K L ( q ( Z ) ∣ ∣ P ( Z ) ) \begin{aligned} ELBO(q)&=E[\log P(X,Z)]-E[\log q(Z)]\\ &=E[\log P(X|Z)]+E[\log P(Z)]-E[\log q(Z)]\\ &=E[\log P(X|Z)]-KL(q(Z)||P(Z)) \end{aligned} ELBO(q)=E[logP(X,Z)]−E[logq(Z)]=E[logP(X∣Z)]+E[logP(Z)]−E[logq(Z)]=E[logP(X∣Z)]−KL(q(Z)∣∣P(Z))
其中第一项为对数似然要求潜变量尽可能解释观测数据的分布,第二项为KL散度要求让后验 q ( Z ) q(Z) q(Z)分布尽可能接近先验分布 P ( Z ) P(Z) P(Z) -
log P ( X ) ≥ E L B O ( q ) \log P(X) \ge ELBO(q) logP(X)≥ELBO(q): log P ( X ) = E L B O ( q ) + K L ( q ( Z ) ∣ ∣ P ( Z ∣ X ) ) \log P(X)=ELBO(q)+KL(q(Z)||P(Z|X)) logP(X)=ELBO(q)+KL(q(Z)∣∣P(Z∣X)),而KL散度大于等于0。从这里我们也可以知道ELBO名字的由来。
b. 极大似然
计算 P ( Z ∣ X ) P(Z|X) P(Z∣X)的目的是在合适的条件下使 log P ( X ) \log P(X) logP(X)(似然函数)最大。因此我们可以基于 log P ( X ) \log P(X) logP(X)来推导 E L B O ( q ) ELBO(q) ELBO(q)
log P ( X ) = ∫ q ( Z ) log P ( X ) d Z = ∫ q ( Z ) log P ( X ) P ( X , Z ) P ( X , Z ) q ( Z ) q ( Z ) = ∫ q ( Z ) log q ( Z ) P ( Z ∣ X ) d Z + ∫ q ( Z ) log P ( X , Z ) q ( Z ) d Z = K L ( q ( Z ) ∣ ∣ p ( Z ∣ X ) ) + L ( q ) \begin{aligned} \log P(X)&=\int q(Z)\log P(X)dZ\\ &=\int q(Z)\log{\frac{P(X)}{P(X,Z)}\frac{P(X,Z)}{q(Z)}q(Z)}\\ &=\int q(Z)\log\frac{q(Z)}{P(Z|X)}dZ+\int q(Z)\log\frac{P(X,Z)}{q(Z)}dZ\\ &=KL(q(Z)||p(Z|X))+\mathcal{L}(q) \end{aligned} logP(X)=∫q(Z)logP(X)dZ=∫q(Z)logP(X,Z)P(X)q(Z)P(X,Z)q(Z)=∫q(Z)logP(Z∣X)q(Z)dZ+∫q(Z)logq(Z)P(X,Z)dZ=KL(q(Z)∣∣p(Z∣X))+L(q)
其中 L ( q ) = ∫ q ( Z ) log P ( X , Z ) q ( Z ) d Z = E [ log p ( X , Z ) ] − E [ log q ( Z ) ] \mathcal{L}(q)=\int q(Z)\log\frac{P(X,Z)}{q(Z)}dZ=E[\log p(X,Z)]-E[\log q(Z)] L(q)=∫q(Z)logq(Z)P(X,Z)dZ=E[logp(X,Z)]−E[logq(Z)]为 E L B O ( q ) ELBO(q) ELBO(q)。注意到,在样本给定的时候 log P ( X ) \log P(X) logP(X)是一个定值,因此在这种情况下最大化 L ( q ) \mathcal{L}(q) L(q)等价于最小化 K L ( q ( Z ) ∣ ∣ p ( Z ∣ X ) ) KL(q(Z)||p(Z|X)) KL(q(Z)∣∣p(Z∣X))
2.几种特殊的变分推断
a. 平均场变分推断
平均场假设(Mean-Field Assumption): q ( Z ) = ∏ i q i ( Z i ) q(Z)=\prod_i q_i(Z_i) q(Z)=∏iqi(Zi) 这里 Z i Z_i Zi并非特指单个随机变量,而可以理解成是一个团。
基于平均场假设
L ( q ) = ∫ q ( Z ) log P ( X , Z ) d Z − ∫ q ( Z ) log q ( Z ) d Z = ∫ q j ( log p ( X , Z ) ∏ i ≠ j q i d Z i ) d Z j − ∫ q j log q j d Z j + const = ∫ q j log p ~ ( X , Z j ) d Z j − ∫ q j log q j d Z j + const \begin{aligned} \mathcal{L}(q)&=\int q(Z)\log P(X,Z)dZ-\int q(Z)\log q(Z)dZ\\ &=\int q_j(\log p(X,Z)\prod_{i\ne j}q_idZ_i)dZ_j-\int q_j\log q_j dZ_j+\text{const}\\ &=\int q_j\log \tilde{p}(X,Z_j)dZ_j-\int q_j\log q_j dZ_j+\text{const} \end{aligned} L(q)=∫q(Z)logP(X,Z)dZ−∫q(Z)logq(Z)dZ=∫qj(logp(X,Z)i=j∏qidZi)dZj−∫qjlogqjdZj+const=∫qjlogp~(X,Zj)dZj−∫qjlogqjdZj+const
这里 log p ~ ( X , Z j ) = E i ≠ j [ log P ( X , Z ) ] + const \log\tilde{p}(X,Z_j)=E_{i\ne j}[\log P(X,Z)]+\text{const} logp~(X,Zj)=Ei=j[logP(X,Z)]+const。在这里保持 { q i ≠ j } \{q_{i \ne j}\} {qi=j}固定,关于分布 q j ( Z j ) q_j(Z_j) qj(Zj)来最大化 L ( q ) = − K L ( q j ∣ ∣ p ~ ( X , Z j ) ) + const \mathcal{L}(q)=-KL(q_j||\tilde{p}(X,Z_j))+\text{const} L(q)=−KL(qj∣∣p~(X,Zj))+const。此时最大化 L \mathcal{L} L等价于最小化KL散度。由KL散度的定义易知 log q j ∗ ( Z j ) = E i ≠ j [ log P ( X , Z ) ] + const \log q^*_j(Z_j)=E_{i\ne j}[\log P(X,Z)]+\text{const} logqj∗(Zj)=Ei=j[logP(X,Z)]+const,于是我们可以得到如下方程组
q j ∗ ( Z j ) = exp ( E i ≠ j [ log P ( X , Z ) ] ) ∫ exp ( E i ≠ j [ log P ( X , Z ) ] ) d Z j ( j = 1 , ⋯ , n ) q^*_j(Z_j)=\frac{\exp(E_{i\ne j}[\log P(X,Z)])}{\int\exp(E_{i\ne j}[\log P(X,Z)])dZ_j}\quad (j=1,\cdots,n) qj∗(Zj)=∫exp(Ei=j[logP(X,Z)])dZjexp(Ei=j[logP(X,Z)])(j=1,⋯,n)
这个方程组无显示解,因此采用一种交替迭代的方法来求解(CAVI)具体表现为:在给出一个恰当的初始话后,循环更新 q ( Z i ) q(Z_i) q(Zi)(用 q ∗ ( Z i ) q^*(Z_i) q∗(Zi)给出估计)。
b. 随机梯度变分推断
对目标函数: q ^ = arg min q K L ( q ∣ ∣ p ) = arg min L ( q ) \hat{q}=\arg\min_q KL(q||p)=\arg\min \mathcal{L}(q) q^=argminqKL(q∣∣p)=argminL(q),设 Z Z Z服从分布 q ϕ ( Z ) q_\phi(Z) qϕ(Z),这样目标函数变为 ϕ ^ = arg min ϕ L ( ϕ ) \hat{\phi}=\arg\min_{\phi} \mathcal{L}(\phi) ϕ^=argminϕL(ϕ)
∇ ϕ L ( ϕ ) = ∇ ϕ E q ϕ [ log P θ ( X , Z ) − log q ϕ ] = E q ϕ [ ∇ ϕ ( log P θ ( X , Z ) − log q ϕ ) ] = ∫ ∇ ϕ q ϕ ( log P θ ( X , Z ) − log q ϕ ) d Z + ∫ q ϕ ∇ ϕ [ log P θ ( X , Z ) − log q ϕ ] d Z \begin{aligned} \nabla_\phi\mathcal{L}(\phi)&=\nabla_\phi E_{q_\phi}[\log P_\theta(X,Z)-\log q_\phi]\\ &=E_{q_\phi}[\nabla_\phi(\log P_\theta(X,Z)-\log q_\phi)]\\ &=\int\nabla_\phi q_\phi(\log P_\theta(X,Z)-\log q_\phi)dZ+\int q_\phi\nabla_\phi[\log P_\theta(X,Z)-\log q_\phi]dZ \end{aligned} ∇ϕL(ϕ)=∇ϕEqϕ[logPθ(X,Z)−logqϕ]=Eqϕ[∇ϕ(logPθ(X,Z)−logqϕ)]=∫∇ϕqϕ(logPθ(X,Z)−logqϕ)dZ+∫qϕ∇ϕ[logPθ(X,Z)−logqϕ]dZ
这里 ∫ q ϕ ∇ ϕ [ log P θ ( X , Z ) − log q ϕ ] d Z = − ∫ q ϕ ∇ ϕ log q ϕ d Z = − ∫ ∇ ϕ q ϕ d Z = − ∇ ϕ ∫ q ϕ d Z = 0 \int q_\phi\nabla_\phi[\log P_\theta(X,Z)-\log q_\phi]dZ=-\int q_\phi\nabla_\phi \log q_\phi dZ=-\int\nabla_\phi q_\phi dZ= -\nabla_\phi\int q_\phi dZ=0 ∫qϕ∇ϕ[logPθ(X,Z)−logqϕ]dZ=−∫qϕ∇ϕlogqϕdZ=−∫∇ϕqϕdZ=−∇ϕ∫qϕdZ=0,进而
∇ ϕ L ( ϕ ) = ∫ q ϕ ∇ ϕ log q ϕ ( log P θ ( X , Z ) − log q ϕ ) d Z = E q ϕ [ ∇ ϕ log q ϕ ( log P θ ( X , Z ) − log q ϕ ) ] (3) \begin{aligned} \nabla_\phi\mathcal{L}(\phi)&=\int q_\phi \nabla_\phi \log q_\phi(\log P_\theta(X,Z)-\log q_\phi)dZ\\ &=E_{q_\phi}[\nabla_\phi \log q_\phi(\log P_\theta(X,Z)-\log q_\phi)] \end{aligned}\tag{3} ∇ϕL(ϕ)=∫qϕ∇ϕlogqϕ(logPθ(X,Z)−logqϕ)dZ=Eqϕ[∇ϕlogqϕ(logPθ(X,Z)−logqϕ)](3)
注:对于(3)式中的期望计算可以利用MCMC来估计,即记 Z ( l ) ∼ q ( z ) l = 1 , 2 , ⋯ , L Z^{(l)}\sim q(z)\quad l=1,2,\cdots,L Z(l)∼q(z)l=1,2,⋯,L,则 ∇ ϕ L ( ϕ ) = 1 L ∑ l ∇ ϕ log q ϕ ( log P θ ( X , Z ( l ) ) − log q ϕ ( Z ( l ) ) \nabla_\phi\mathcal{L}(\phi)=\frac{1}{L}\sum_l{\nabla_\phi \log q_\phi(\log P_\theta(X,Z^{(l)})-\log q_\phi(Z^{(l)})} ∇ϕL(ϕ)=L1∑l∇ϕlogqϕ(logPθ(X,Z(l))−logqϕ(Z(l)),若采样过程中 Z ( l ) Z^{(l)} Z(l)过小会导致 log q ϕ ( Z ( l ) ) \log q_\phi(Z^{(l)}) logqϕ(Z(l))过大,使得计算不稳定,为了稳定则需要大量采样。
c. 重参数技巧
不妨设 Z = g ϕ ( ϵ , X ) Z=g_\phi(\epsilon,X) Z=gϕ(ϵ,X),这里 ϵ ∼ p ( ϵ ) \epsilon \sim p(\epsilon) ϵ∼p(ϵ)同时有 ∣ q ϕ ( Z ∣ X ) d Z ∣ = ∣ p ( ϵ ) d ϵ ∣ |q_\phi(Z|X)dZ|=|p(\epsilon)d\epsilon| ∣qϕ(Z∣X)dZ∣=∣p(ϵ)dϵ∣,于是我们可以推导
∇ ϕ L ( ϕ ) = ∇ ϕ E q ϕ [ log P θ ( X , Z ) − log q ϕ ] = ∇ ϕ ∫ [ log P θ ( X , Z ) − log q ϕ ] q ϕ d Z = ∇ ϕ ∫ [ log P θ ( X , Z ) − log q ϕ ] p ( ϵ ) d ϵ = E p ( ϵ ) [ ∇ ϕ ( log P θ ( X , Z ) − log q ϕ ) ] = E p ( ϵ ) [ ∇ Z ( log P θ ( X , Z ) − log q ϕ ) ∇ ϕ g ϕ ( ϵ , X ) ] \begin{aligned} \nabla_\phi\mathcal{L}(\phi)&=\nabla_\phi E_{q_\phi}[\log P_\theta(X,Z)-\log q_\phi]\\ &=\nabla_\phi\int[\log P_\theta(X,Z)- \log q_\phi]q_\phi dZ\\ &=\nabla_\phi\int[\log P_\theta(X,Z)- \log q_\phi]p(\epsilon) d\epsilon\\ &=E_{p(\epsilon)}[\nabla_\phi(\log P_\theta(X,Z)-\log q_\phi)]\\ &=E_{p(\epsilon)}[\nabla_Z(\log P_\theta(X,Z)-\log q_\phi)\nabla_\phi g_\phi(\epsilon,X)] \end{aligned} ∇ϕL(ϕ)=∇ϕEqϕ[logPθ(X,Z)−logqϕ]=∇ϕ∫[logPθ(X,Z)−logqϕ]qϕdZ=∇ϕ∫[logPθ(X,Z)−logqϕ]p(ϵ)dϵ=Ep(ϵ)[∇ϕ(logPθ(X,Z)−logqϕ)]=Ep(ϵ)[∇Z(logPθ(X,Z)−logqϕ)∇ϕgϕ(ϵ,X)]
注:VI和EM的一个差异,在EM中 θ \theta θ是固定的, Z Z Z是随机的;但在VI中只有一个随机的 Z Z Z,因此EM可以视为VI的特例。
参考
[1] Blei, D. M., Kucukelbir, A., & McAuliffe, J. D. (2017). Variational inference: A review for statisticians. Journal of the American statistical Association, 112(518), 859-877.
[2] Bishop, C. M., & Nasrabadi, N. M. (2006). Pattern recognition and machine learning (Vol. 4, No. 4, p. 738). New York: springer.
[3]https://www.bilibili.com/video/BV1DW41167vr?spm_id_from=333.999.0.0