计算机内核态、用户态和零拷贝技术详解

存储介质的性能
话不多说,先看一张图,下图左边是磁盘到内存的不同介质,右边形象地描述了每种介质的读写速率。一句话总结就是越靠近cpu,读写性能越快。了解了不同硬件介质的读写速率后,你会发现零拷贝技术是多么的香,对于追求极致性能的读写系统而言,掌握这个技术是多么的优秀~
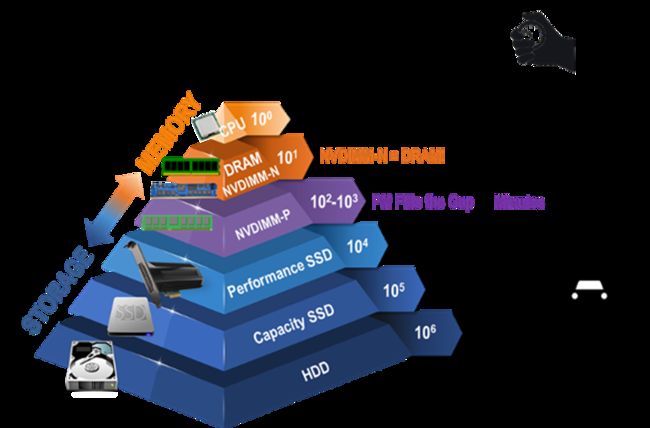
上图是当前主流存储介质的读写性能,从磁盘到内存、内存到缓存、缓存到寄存器,每上一个台阶,性能就提升10倍。如果我们打开一个文件去读里面的内容,你会发现时间读取的时间是远大于磁盘提供的这个时延的,这是为什么呢?问题就在内核态和用户态这2个概念后面深藏的I/O逻辑作怪。
内核态和用户态
内核态:也称为内核空间。cpu可以访问内存的所有数据,还控制着外围设备的访问,例如硬盘、网卡、鼠标、键盘等。cpu也可以将自己从一个程序切换到另一个程序。
用户态:也称为用户空间。只能受限的访问内存地址,cpu资源可以被其他程序获取。

计算机资源的管控范围
坦白地说内核态就是一个高级管理员,它可以控制整个资源的权限,用户态就是一个业务,每个人都可以使用它。那计算机为啥要这么分呢?且看下文......
由于需要限制不同的程序之间的访问能力, 防止他们获取别的程序的内存数据, 或者获取外围设备的数据, 并发送到网络。CPU划分出两个权限等级:用户态和内核态。
32 位操作系统和 64 位操作系统的虚拟地址空间大小是不同的,在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,如下所示:
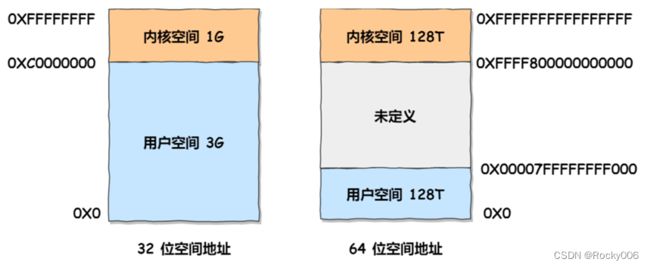
通过这里可以看出:
32 位系统的内核空间占用 1G,位于最高处,剩下的 3G 是用户空间;
64 位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
内核态控制的是内核空间的资源管理,用户态访问的是用户空间内的资源。
从用户态到内核态切换可以通过三种方式:
系统调用,其实系统调用本身就是中断,但是软件中断,跟硬中断不同。
异常:如果当前进程运行在用户态,如果这个时候发生了异常事件,就会触发切换。例如:缺页异常。
外设中断:当外设完成用户的请求时,会向CPU发送中断信号。
内核态和用户态是怎么控制数据传输的
举个例子:当计算机 A 上 a 进程要把一个文件传送到计算机 B 上的 b 进程空间里面去,它是怎么做的呢?在当前的计算机系统架构下,它的 I/O 路径如下图所示:
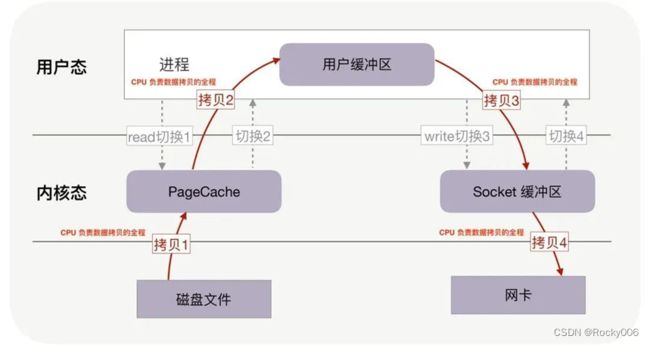
计算机A的进程a先要通过系统调用Read(内核态)打开一个磁盘上的文件,这个时候就要把数据copy一次到内核态的PageCache中,进入了内核态;
进程a负责将数据从内核空间的 Page Cache 搬运到用户空间的缓冲区,进入用户态;
进程a负责将数据从用户空间的缓冲区搬运到内核空间的 Socket(资源由内核管控) 缓冲区中,进入内核态。
进程a负责将数据从内核空间的 Socket 缓冲区搬运到的网络中,进入用户态;
从以上4个步骤我们可以发现,正是因为用户态没法控制磁盘和网络资源,所以需要来回的在内核态切换。这样一个发送文件的过程就产生了4 次上下文切换:
read 系统调用读磁盘上的文件时:用户态切换到内核态;
read 系统调用完毕:内核态切换回用户态;
write 系统调用写到socket时:用户态切换到内核态;
write 系统调用完毕:内核态切换回用户态。
如此笨拙的设计,我们觉得计算机是不是太幼稚了,为啥要来回切换不能直接在用户态做数据传输吗?
CPU 全程负责内存内的数据拷贝,参考磁盘介质的读写性能,这个操作是可以接受的,但是如果要让内存的数据和磁盘来回拷贝,这个时间消耗就非常的难看,因为磁盘、网卡的速度远小于内存,内存又远远小于 CPU;
4 次 copy + 4 次上下文切换,代价太高。
所以计算机体系结构的大佬们就想到了能不能单独地做一个模块来专职负责这个数据的传输,不因为占用cpu而降低系统的吞吐呢?方案就是引入了DMA(Direct memory access)
什么是 DMA ?
没有 DMA ,计算机程序访问磁盘上的数据I/O 的过程是这样的:
CPU 先发出读指令给磁盘控制器(发出一个系统调用),然后返回;
磁盘控制器接受到指令,开始准备数据,把数据拷贝到磁盘控制器的内部缓冲区中,然后产生一个中断;
CPU 收到中断信号后,让出CPU资源,把磁盘控制器的缓冲区的数据一次一个字节地拷贝进自己的寄存器,然后再把寄存器里的数据拷贝到内存,而在数据传输的期间 CPU 是无法执行其他任务的。
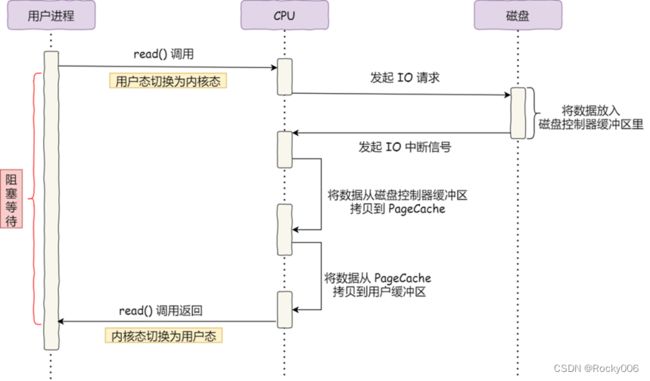
可以看到,整个数据的传输有几个问题:一是数据在不同的介质之间被拷贝了多次;二是每个过程都要需要 CPU 亲自参与(搬运数据的过程),在这个过程,在数据拷贝没有完成前,CPU 是不能做额外事情的,被IO独占。
如果I/O操作能比较快的完成,比如简单的字符数据,那没问题。如果我们用万兆网卡或者硬盘传输大量数据,CPU就会一直被占用,其他服务无法使用,对单核系统是致命的。
为了解决上面的CPU被持续占用的问题,大佬们就提出了 DMA 技术,即直接内存访问(Direct Memory Access) 技术。
那到底什么是 DMA 技术
所谓的 DMA(Direct Memory Access,即直接存储器访问)其实是一个硬件技术,其主要目的是减少大数据量传输时的 CPU 消耗,从而提高 CPU 利用效率。其本质上是一个主板和 IO 设备上的 DMAC 芯片。CPU 通过调度 DMAC 可以不参与磁盘缓冲区到内核缓冲区的数据传输消耗,从而提高效率。
那有了DMA,数据读取过程是怎么样的呢?下面我们来具体看看。
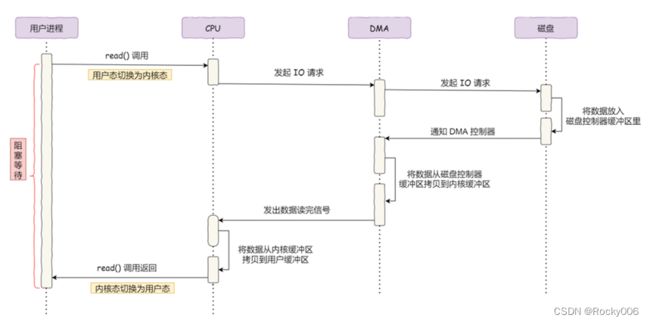
详细过程:
用户进程a调用系统调用read 方法,向OS内核(资源总管)发出 I/O 请求,请求读取数据到自己的内存缓冲区中,进程进入阻塞状态;
OS内核收到请求后,进一步将 I/O 请求发送 DMA,然后让 CPU 执行其他任务;
DMA 再将 I/O 请求发送给磁盘控制器;
磁盘控制器收到 DMA 的 I/O 请求,把数据从磁盘拷贝到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被写满后,它向 DMA 发起中断信号,告知自己缓冲区已满;
DMA 收到磁盘的中断信号后,将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中,此时不占用 CPU,CPU 可以执行其他任务;
当 DMA 读取了一个固定buffer的数据,就会发送中断信号给 CPU;
CPU 收到 DMA 的信号,知道数据已经Ready,于是将数据从内核拷贝到用户空间,结束系统调用;
DMA技术就是释放了CPU的占用时间,它只做事件通知,数据拷贝完全由DMA完成。虽然DMA优化了CPU的利用率,但是并没有提高数据读取的性能。为了减少数据在2种状态之间的切换次数,因为状态切换是一个非常、非常、非常繁重的工作。为此,大佬们就提了零拷贝技术。
零拷贝技术实现的方式
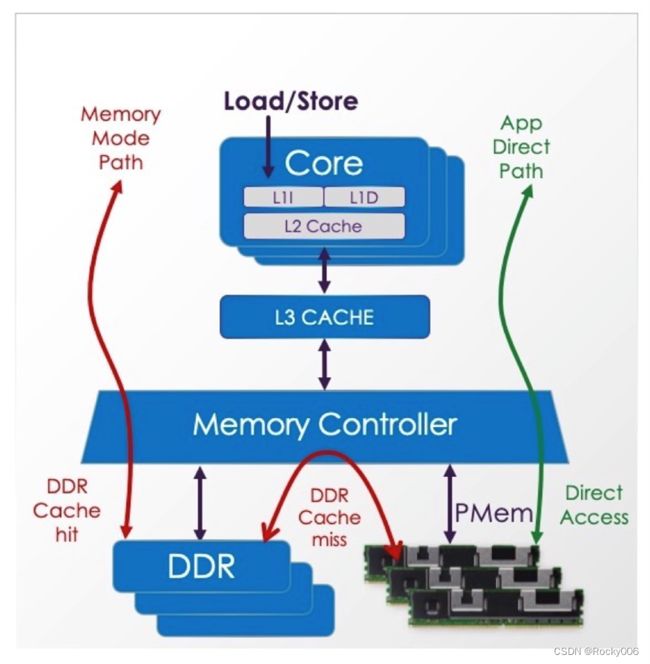
常见的有2种,而今引入持久化内存后,还有APP直接访问内存数据的方式,这里先不展开。下面介绍常用的2种方案,它们的目的减少“上下文切换”和“数据拷贝”的次数。
mmap + write(系统调用)
sendfile
mmap + write
主要目的,减少数据的拷贝
read() 系统调用:把内核缓冲区的数据拷贝到用户的缓冲区里,用 mmap() 替换 read() ,mmap() 直接把内核缓冲区里的数据映射到用户空间,减少这一次拷贝。
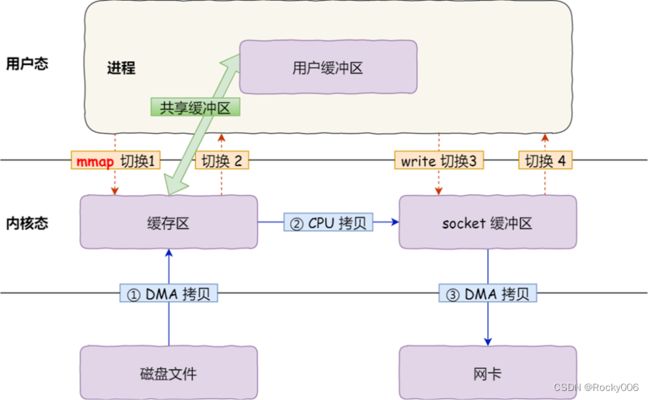
具体过程如下:
应用进程调用了 mmap() 后,DMA 会把磁盘的数据拷贝到内核的缓冲区里。因为建立了这个内存的mapping,所以用户态的数据可以直接访问了;
应用进程再调用 write(),CPU将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态
DMA把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里
由上可知,系统调用mmap() 来代替 read(), 可以减少一次数据拷贝。那我们是否还有优化的空间呢?毕竟用户态和内核态仍然需要 4 次上下文切换,系统调用还是 2 次。
那继续研究下是否还能继续减少切换和数据拷贝呢?答案是确定的:可以
sendfile
Linux 内核版本 2.1 提供了一个专门发送文件的系统调用函数 sendfile()。
参数说明:
前2个参数分别是目的端和源端的文件描述符,
后2个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
首先,使用sendfile()可以替代前面的 read() 和 write() 这两个系统调用,减少一次系统调用和 2 次上下文切换。
其次,sendfile可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,优化后只有 2 次上下文切换,和 3 次数据拷贝。如下图:
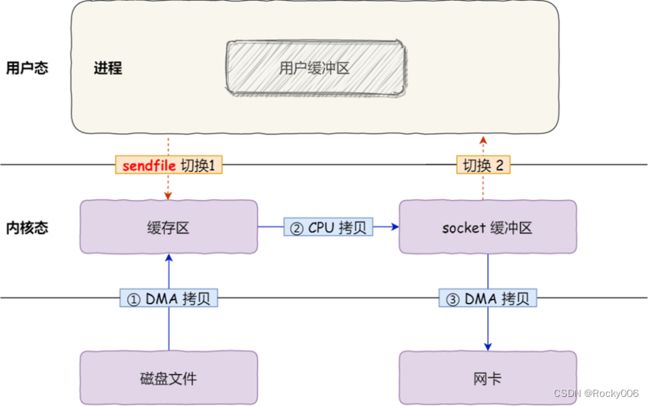
尽管如此,我们还是又数据拷贝,这不符合我们的标题目标。如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术,我们就可以进一步减少通过 CPU 把内核缓冲区里的数据拷贝到 socket 缓冲区的过程。
我们可以在 Linux 系统下通过下面的命令,查看网卡是否支持 scatter-gather 特性:
于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里;
在这个过程之中,实际上只进行了 2 次数据拷贝,如下图:

这就是零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
零拷贝技术的文件传输方式相比传统文件传输的方式,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
所以,零拷贝技术可以把文件传输的性能提高至少一倍。
为啥要聊PageCache
回顾第一节的存储介质的性能,如果我们总是在磁盘和内存间传输数据,一个大文件的跨机器传输肯定会让你抓狂。那有什么方法加速呢?直观的想法就是建立一个离CPU近的一个临时通道,这样就可以加速文件的传输。这个通道就是我们前文提到的「内核缓冲区」,这个「内核缓冲区」实际上是磁盘高速缓存(PageCache)。
零拷贝就是使用了DMA + PageCache 技术提升了性能,我们来看看 PageCache 是如何做到的。
从开篇的介质性能看,磁盘相比内存读写的速度要慢很多,所以优化的思路就是尽量的把「读写磁盘」替换成「读写内存」。因此通过 DMA 把磁盘里的数据搬运到内存里,转为直接读内存,这样就快多了。但是内存的空间是有限的,成本也比磁盘贵,它只能拷贝磁盘里的一小部分数据。
那就不可避免的产生一个问题,到底选择哪些磁盘数据拷贝到内存呢?
从业务的视角来看,业务的数据有冷热之分,我们通过一些的淘汰算法可以知道哪些是热数据,因为数据访问的时序性,被访问过的数据可能被再次访问的概率很高,于是我们可以用 PageCache 来缓存最近被访问的数据,当空间不足时淘汰最久未被访问的数据。
读 Cache
当内核发起一个读请求时(例如进程发起read()请求),首先会检查请求的数据是否缓存到了Page Cache中。如果有,那么直接从内存中读取,不需要访问磁盘,这被称为cache命中(cache hit);如果cache中没有请求的数据,即 cache 未命中(cache miss),就必须从磁盘中读取数据。然后内核将读取的数据缓存到 cache 中,这样后续的读请求就可以命中 cache 了。
page 可以只缓存一个文件部分的内容,不需要把整个文件都缓存进来。
写 Cache
当内核发起一个写请求时(例如进程发起write()请求),同样是直接往cache中写入,后备存储中的内容不会直接更新(当服务器出现断电关机时,存在数据丢失风险)。
内核会将被写入的page标记为dirty,并将其加入dirty list中。内核会周期性地将dirty list中的page写回到磁盘上,从而使磁盘上的数据和内存中缓存的数据一致。
当满足以下两个条件之一将触发脏数据刷新到磁盘操作:
数据存在的时间超过了 dirty_expire_centisecs (默认300厘秒,即30秒) 时间;
脏数据所占内存 > dirty_background_ratio,也就是说当脏数据所占用的内存占总内存的比例超过dirty_background_ratio(默认10,即系统内存的10%)的时候会触发pdflush刷新脏数据。
还有一点,现在的磁盘是擦除式读写,每次需要读一个固定的大小,随机读取带来的磁头寻址会增加时延,为了降低它的影响,PageCache 使用了「预读功能」。
在某些应用场景下,比如我们每次打开文件只需要读取或者写入几个字节的情况,会比Direct I/O多一些磁盘的读取于写入。
举个例子,假设每次我们要读 32 KB 的字节,read填充到用户buffer的大小是0~32KB,但内核会把其后面的 32~64 KB 也读取到 PageCache,这样后面读取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,进程需要读这些数据,对比分块读取的方式,这个策略收益就非常大。
Page Cache 的优势与劣势
优势
加快对数据的访问
减少磁盘I/O的访问次数,提高系统磁盘寿命
减少对磁盘I/O的访问,提高系统磁盘I/O吞吐量(Page Cache的预读机制)
劣势
使用额外的物理内存空间,当物理内存比较紧俏的时候,可能会导致频繁的swap操作,最终会导致系统的磁盘I/O负载上升。
Page Cache没有给应用层提供一个很好的API。导致应用层想要优化Page Cache的使用策略很难。因此一些应用实现了自己的Page管理,比如MySQL的InnoDB存储引擎以16KB的页进行管理。
另外,由于文件太大,可能某些部分的文件数据已经被淘汰出去了,这样就会带来 2 个问题:
PageCache 由于长时间被大文件的部分块占据,而导致一些「热点」的小文件可能就无法常驻 PageCache,导致频繁读写磁盘而引起性能下降;
PageCache 中的大文件数据,由于没有全部常驻内存,只有部分无法享受到缓存带来的好处,同时过多的DMA 拷贝动作,增加了时延;
因此针对大文件的传输,不应该使用 PageCache。
Page Cache缓存查看工具:cachestat
PageCache 的参数调优
备注:不同硬件配置的服务器可能效果不同,所以,具体的参数值设置需要考虑自己集群硬件配置。
考虑的因素主要包括:CPU核数、内存大小、硬盘类型、网络带宽等。
查看Page Cache参数:sysctl -a|grep dirty
调整内核参数来优化IO性能?
vm.dirty_background_ratio 参数优化:当 cached 中缓存当数据占总内存的比例达到这个参数设定的值时将触发刷磁盘操作。把这个参数适当调小,这样可以把原来一个大的 IO 刷盘操作变为多个小的 IO 刷盘操作,从而把 IO 写峰值削平。对于内存很大和磁盘性能比较差的服务器,应该把这个值设置的小一点。
vm.dirty_ratio 参数优化:对于写压力特别大的,建议把这个参数适当调大;对于写压力小的可以适当调小;如果cached的数据所占比例(这里是占总内存的比例)超过这个设置,系统会停止所有的应用层的IO写操作,等待刷完数据后恢复IO。所以万一触发了系统的这个操作,对于用户来说影响非常大的。
vm.dirty_expire_centisecs参数优化:这个参数会和参数vm.dirty_background_ratio 一起来作用,一个表示大小比例,一个表示时间;即满足其中任何一个的条件都达到刷盘的条件。
vm.dirty_writeback_centisecs 参数优化:理论上调小这个参数,可以提高刷磁盘的频率,从而尽快把脏数据刷新到磁盘上。但一定要保证间隔时间内一定可以让数据刷盘完成。
vm.swappiness 参数优化:禁用 swap 空间,设置 vm.swappiness=0
大文件传输怎么做
我们先来回顾下前文的读流程,当调用 read 方法读取文件时,如果数据没有准备好,进程会阻塞在 read 方法调用,要等待磁盘数据的返回,如下图:
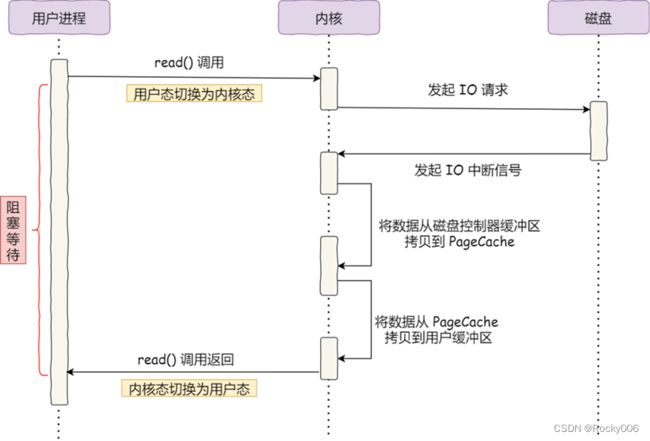
具体过程:
当调用 read 方法时,切到内核态访问磁盘资源。此时内核会向磁盘发起 I/O 请求,磁盘收到请求后,准备数据。数据读取到控制器缓冲区完成后,就会向内核发起 I/O 中断,通知内核磁盘数据已经准备好;
内核收到 I/O 中断后,将数据从磁盘控制器缓冲区拷贝到 PageCache 里;
内核把 PageCache 中的数据拷贝到用户缓冲区,read 调用返回成功。
对于大块数传输导致的阻塞,可以用异步 I/O 来解决,如下图:

分为两步执行:
内核向磁盘发起读请求,因为是异步请求可以不等待数据就位就可以返回,于是CPU释放出来可以处理其他任务;
当内核将磁盘中的数据拷贝到进程缓冲区后,进程将接收到内核的通知,再去处理数据;
从上面流程来看,异步 I/O 并没有读写 PageCache,绕开 PageCache 的 I/O 叫直接 I/O,使用 PageCache 的 I/O 则叫缓存 I/O。通常,对于磁盘异步 I/O 只支持直接 I/O。
因此,在高并发的场景下,针对大文件的传输的方式,应该使用「异步 I/O + 直接 I/O」来替代零拷贝技术。
直接 I/O 的两种场景:
应用程序已经实现了磁盘数据的缓存
大文件传输
以上就是对计算机内核态、用户态和零拷贝技术详细介绍,希望本文对你有所帮助,欢迎点赞评论收藏点赞,感谢!!
-End-