JS & 事件循环机制、调用栈、堆、主线程、宏任务队列、微任务队列、缓存管理之间的关系
一、事件循环机制
你是否想过,在控制台执行代码时,为什么能立即得到响应?
实际上,底层有一套模型机制叫 事件循环,换句话说,它是一个”死循环“,
里面负责监听&执行我们写的 JS 代码,咋们暂且称为一个处理代码的容器。
事件循环负责执行代码,而执行是一套机制存在的,这里借用 MDN 的图:
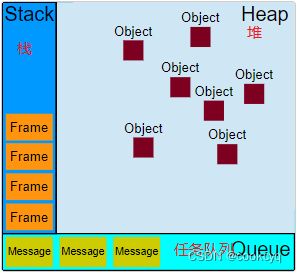
下面我将一一解释每个机制的作用。
二、调用栈与堆
2.1 调用栈
当我们调用一个函数时,这个函数就会进入栈,在图上面则对应一个帧(Frame ),函数执行完后,”帧“便消失:
debugger
const foo = () => {}
foo()
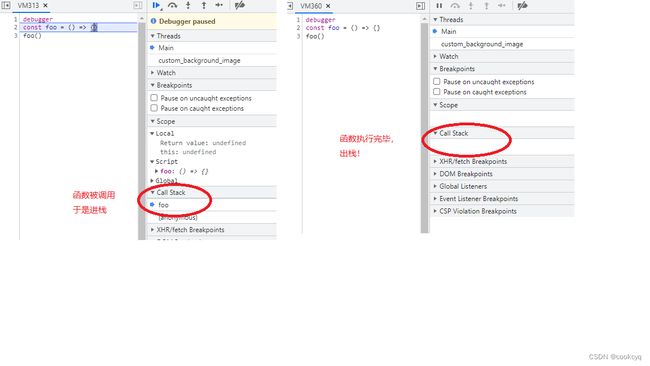
我们常看到的”栈溢出“?说的就是”帧“数量太多超出限制了!
所以在执行函数时,尽量少犯这种错误,比如循环、函数递归、定时器、像这些操作都要仔细妥善处理。
2.2 堆
从图中你也看出来了,堆其实放的就是引用类型的数据,换句话说,里面就是一块内存,存放对象数据的。
三、主线程
3.1 什么是主线程?
当我们正常地执行一个函数且不加以其它修饰时,这个函数便会被放到主线程里面去执行,比如:
const foo = () => {}
foo();
主线程是按序执行的,假如有大量的函数执行,每个函数都得等前面的函数完全地执行后才能轮到它执行。
这样会存在一个阻塞问题,假设有个请求商品列表函数,响应结果等了 3s,
而函数后正好是获取用户个人头像的函数。
于是,用户的头像至少得等 3s 后才能展示出来,对于用户体验来说是不能忍受的。
换句话说,只要有阻塞行为,那就是不可取的!
为了避免阻塞行为,我们必须得将阻塞的函数放到另一种地方去执行,不能影响主线程。
这种地方就叫做 任务队列 。
四、宏任务队列
宏任务队列通常有这几种:
setTimeout/setInverval定时器。- callback 回调函数。
const foo = () => console.log('Hello, I am Foo')
setTimeout(foo, 10)
const bar = () => console.log('Hello, I am Bar')
bar()
// 打印顺序是:Hello, I am Bar -> Hello I am Foo
强调下,定时器的第二个参数表示执行时间的最小单位,并不会准确的按照指定时间去执行,
也就是说,它是不稳定的,出现不稳定的因素有比如,其它宏任务还未执行或主线任务还没执行完时,
此时的 foo 就不会被调用,或者说也处于“阻塞状态”(但不影响主线程),我们来验证这点:
const now = Date.now()
console.log('当前时间:', now)
const foo = () => console.log('Hello, I am Foo. 当前花费时间(s):', (Date.now() - now) / 1000)
setTimeout(foo, 500)
while(Date.now() - now <= 2000) {}
上面的代码中,定时器指定了 500ms,但实际上过了 500ms 后根本不会立即执行,因为我们主线程还在执行 while 语句呢,换句话说,主线程优先级大于定时器。
五、微任务队列
微任务队列通常有这几种:
Promise、async/await、queueMicrotask
微任务和宏任务概率是相同的,都是属于异步操作,但微任务队列的执行优先级大于宏任务,看例子:
Promise.resolve(() => '').then(() => console.log('Hello, p'))
setTimeout(() => console.log('Hello, s'), 0)
console.log('Hello, main')
// 将会打印:
// Hello, main
// Hello, p
// Hello, s
六、总结
- JS 底层有一套《事件循环》模型,说白点就是监听并执行开发人员写的 JS 代码。
- 执行过程时有这套机制:
2.1 调用栈:记录函数的调用与销毁过程。
2.2 堆:一块存放对象的数据内存。
2.3 代码执行优先级:主线程(同步执行,会阻塞) > 微任务队列(异步执行,不阻塞) > 宏任务队列(异步执行,不阻塞)
七、缓存管理
缓存放到最后讲是因为这部分内容与上面没多大关系,这里仅顺带讲下。
首先,对于底层语言比如 C 来说,声明变量或函数是需要手动分配和释放内存的,
然而,在高级语言比如 JS/PHP/Python 中,这部分操作被自动化了。
这里我们重点关注:内存是如何被自动销毁的?,换句话说,在 JS 中,这些变量的内存垃圾回收机制是怎样的?
在刚开始时,JS 采用的第一种策略叫做 计数法。
原理是,当一个变量被引用时加 1,反之减 1,当引用数等于 0 时,这个变量就可以被销毁了,我们来看下例子:
const o = { name: 'Jack'}
const o2 = o // 引用 + 1
const name = o2.name // 引用 + 2
假设 name 变量最终没有被任何地方引用,则引用 --1,o2 没人引用也 --1,最后只剩下 o,发现也没被引用,
于是这几个变量便可全回收掉。
然而这种方式存在一个问题,如果变量之间相互引用,引用值的计算规则就乱套了,来看下例子:
const o = {name: 'Jack', o2: o2} // o 引用了 o2
const o2 = { name: 'John', o: o, } // o2 引用了 o
这像不像 Mysql 或 Java 等其它语言常说的死锁概念?两者僵持不下,为了解决这问题:
JS 采取了一种新的策略叫做:标记-清除法。
核心思路是,JS 定期从顶端(windows)全局对象开始从上向下查找是否有这个对象,如果获取不到这个对象,则该对象便可销毁。
从 2012 年开始,
标记-清除法开始被广泛应用,后来许多回收算法也是基于此策略进行改造的。
对于大部分 JS 开发者而言,我们可以不关系垃圾回收机制的,但是呢,知道哪些地方会造成垃圾对我们写代码和调试是有帮助的,就好比日常的丢垃圾一样,如果你不知道回收站在哪里,直接随地一扔的话会被人鄙视的!
小结:垃圾回收机制
计数法2012 年前最初用的,后来因为相互引用问题,弃之。标记-清除法2012 年后开始广泛应用,解决计数法带来的弊端。
完!