ElasticSearch7的简单使用
简介
es开箱即用
es建立索引快,查询慢
es仅仅支持json格式
yum安装
1、下载并安装ES的YUM公钥
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
2、配置ELASTICSEARCH的YUM源
vim /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
3、安装ELASTICSEARCH
yum install -y elasticsearch
4、 配置文件都在 /etc/elasticsearch/ 目录下
vim /etc/elasticsearch/elasticsearch.yml
设置ip访问、外网访问、修改端口
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#
http.port: 9200
cluster.name: my-application
node.name: node-1
discovery.seed_hosts: ["127.0.0.1", "[::1]"]
cluster.initial_master_nodes: ["node-1"]
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
离线包安装
下载
https://www.elastic.co/cn/downloads/elasticsearch
我的是 elasticsearch-7.1.1-linux-x86_64.tar.gz
解压,进入文件夹
./bin/elasticsearch #启动
问题:
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:102) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:169) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:325) ~[elasticsearch-7.1.1.jar:7.1.1]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:159) ~[elasticsearch-7.1.1.jar:7.1.1]
... 6 more
解决方案:
groupadd elsearch
useradd elsearch -g elsearch -p root
chown -R elsearch:elsearch elasticsearch-7.1.1 #更改 elasticsearch-7.1.1 文件夹及内部文件的所属用户及组为elsearch
问题
java.io.FileNotFoundException: /root/elasticsearch-7.1.1/logs/elasticsearch.
没有给elsearc授权访问elasticsearch-7.1.1
chown -R elsearch /root/elasticsearch-7.1.1
问题
max virtual memory areas vm.max_map_count [65530] is too low,, increase to at least [262144]
解决
vim /etc/sysctl.conf
vm.max_map_count=262144 #文件最后添加
启动
su elsearch #切换用户
./bin/elasticsearch
# 启动
systemctl start elasticsearch.service
# 开机自启
systemctl enable elasticsearch.service
# 查看状态
systemctl status elasticsearch.service
IK分词器
安装
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.11.1/elasticsearch-analysis-ik-7.11.1.zip
下载,上传到elasticsearch-7.11.2的plugins中,进行解压即可
配置自己的字典
vim ik/config/IKAnalyzer.cfg.xml
IK分词器算法
-
ik_smart:最少切分
-
ik_max_word :最细粒度划分
POST _analyze
{
"analyzer": "ik_smart",
"text": "罗健康,今天你要嫁给我吗"
}
POST _analyze
{
"analyzer": "ik_max_word",
"text": "罗健康,今天你要嫁给我吗"
}
基本类
SearchSourceBuilder
用于构建查询条件的类
QueryBuilders
创建搜索查询的工具类
HighlightBuilder
高亮构造器
/**
* Set encoder for the highlighting
* are {@code html} and {@code default}.
*
* @param encoder name
*/
public HighlightBuilder encoder(String encoder) {
this.encoder = encoder;
return this;
}
/**
* Adds a field to be highlighted with default fragment size of 100 characters, and
* default number of fragments of 5 using the default encoder
*
* @param name The field to highlight
*/
public HighlightBuilder field(String name) {
return field(new Field(name));
}
/**
* Set a tag scheme that encapsulates a built in pre and post tags. The allowed schemes
* are {@code styled} and {@code default}.
*
* @param schemaName The tag scheme name
*/
public HighlightBuilder tagsSchema(String schemaName) {
switch (schemaName) {
case "default":
preTags(DEFAULT_PRE_TAGS);
postTags(DEFAULT_POST_TAGS);
break;
case "styled":
preTags(DEFAULT_STYLED_PRE_TAG);
postTags(DEFAULT_STYLED_POST_TAGS);
break;
default:
throw new IllegalArgumentException("Unknown tag schema ["+ schemaName +"]");
}
return this;
}
实战
http://121.43.135.181:9200/_cat/nodes #查看节点信息
GET /_cat/nodes #查看所有节点,带*号的是主节点
GET /_cat/health #查看es的健康状态
GET /_cat/master #查看主节点
GET /_cat/indices #查看所有索引,相当于MySQL的 show databases
数据操作,重复操作视为更新
如果索引不存在,将会自动创建该索引
#put必须带文档id
PUT /index_name/typename/docid
{
}
#post会自动产生一个id
POST /index_name/typename/
{
}
#带了id,存在就是更新,不存在就是新增
POST /index_name/typename/2
{
}
获取数据 GET
格式:GET /indexname/typename/docid
GET /test/_cat/1
结果
{
"_index": "test",
"_type": "_doc",
"_id": "1",
"_version": 2,
"_seq_no": 1, #并发控制字段,每次更新就会+1,用来做乐观锁,?if_seq_no=1&if_primary_term=1
"_primary_term": 1, #和上面一样,主分片重新分配就会变化
"found": true,
"_source": { #这里才是数据
"name": "蚂蚁牙给",
"age": 23,
"title": "皮卡丘好吗"
}
}
_update
更新数据,带_update,必须有doc,重复的数据,结果是版本号和序列号不变,不进行任何操作
不带_update进行更新,重复的数据,版本号和序列号变化,进行操作
#带_update,必须有doc,重复的数据,结果是版本号和序列号不变,不进行任何操作
POST /test/_cat/1/_update
{
"doc":{
}
}
#不带_update进行更新,重复的数据,版本号和序列号变化,进行操作
POST /test/_cat/1
{
}
DELETE
删除文档
DELETE /test/_cat/1 #删除文档
DELETE /test #删除索引
_bulk
批量操作,必须是post请求
POST /test/_cat/_bulk
{"index":{"_id":"1"}}
{"name":"数据"}
查询
_search
| query | match_all | 查询所有 |
|---|---|---|
| match | 分词,包含分词的内容都会查询出来 | |
| match_phrase | 不分词,查询指定内容 | |
| bool | must,must_not,should | |
| sort | ||
GET /test/_search
{
"query": {
"match_all": {} #查询所有
},
"sort": [
{
"age": {
"order": "desc" #排序字段及规则
}
}
],
"from": 0, #分页起始位置
"size": 2 #每页大小
}
结果
{
"took" : 1, #查询花了多少毫秒
"timed_out" : false, #是否超时
"_shards" : { #分片
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : { #命中
"total" : {
"value" : 4, #查询结果数量
"relation" : "eq" #查询关系
},
"max_score" : null, #最大得分
"hits" : [ #命中
{
"_index" : "test", #索引名
"_type" : "_doc", #类型
"_id" : "3", #文档id
"_score" : null, #得分
"_source" : { #我们存入的数据
"name" : "收纳盒",
"age" : 23,
"title" : "电视机"
},
"sort" : [
23
]
}
]
}
}
bool查询
GET /test/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "java"
}
}
],
"must_not": [
{"match": {
"age": 23
}}
],
"should": [
{"match": {
"title": "电视机"
}}
],
"filter": { #对结果进行过滤
"range": { #范围
"age": {
"gte": 30, #大于等于
"lte": 40 #小于等于
}
}
}
}
},
"from": 0,
"size": 10
}
match_phrase
匹配,不会进行分词
GET /test/_search
{
"query": {
"match_phrase": { ##查询该字段包含"罗罗说java"
"name": "罗罗说java"
}
},
"from": 0,
"size": 10
}
.keyword
精确匹配
GET /test/_search
{
"query": {
"match": {
"name.keyword": "罗罗说java" #查询该字段=="罗罗说java"
}
},
"from": 0,
"size": 10
}
term
和match效果一样,区别在于term最好用于精确的数值(非文本字段)
注意:全文检索字段用match,其他非text字段用term
Aggregations-聚合
GET /test/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 10,
"aggs": { #开始聚合
"ageAgg": { #聚合名
"terms": { #聚合类型
"field": "age", #聚合字段
"size": 10 #前n条
},
"aggs": { #在这里内嵌聚合
"avgAgg": {
"avg": { #聚合类型
"field": "age"
}
}
}
}
}
}
结果如下
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 23, #年龄为23
"doc_count" : 4, #有4人
"avgAgg" : {
"value" : 23.0 #平均年龄23.0
}
},
{
"key" : 35,
"doc_count" : 1,
"avgAgg" : {
"value" : 35.0
}
}
]
}
}
}
Mappings
字段类型映射
PUT myindex
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
},
"title":{
"type": "keyword"
}
}
}
}
添加字段
PUT myindex/_mapping
{
"properties": {
"sex":{
"type": "keyword",
"index": true
},
"time":{
"type": "date",
"format": "yyyy-MM-dd"
}
}
}
_mapping: 查看映射
GET myindex/_mapping
_reindex 数据迁移
把myindex的数据迁移到newindex中
POST _reindex
{
"source": {"index": "myindex"},
"dest": {"index": "newindex"}
}
如果有类型
POST _reindex
{
"source": {
"index": "myindex",
"type":"bank" #指定类型
},
"dest": {"index": "newindex"}
}
Kibana可视化
安装
https://www.elastic.co/cn/downloads/kibana
注意:版本号必须和es版本号一致
解压
配置 kibana
vim config/kibana.yml
配置如下
i18n.locale: "zh-CN"
server.port: 5601 # 监听端口
server.name: "kibana-server"
server.host: "0.0.0.0" # 配置外网可以访问
elasticsearch.hosts: ["http://192.168.52.129:9200"] # elasticsearch连接kibana的URL
# kibana会将部分数据写入es,这个是ex中索引的名字
kibana.index: ".kibana"
改变kibana的操作用户为es的用户
chown -R elsearch:elsearch kibana-7.1.1-linux-x86_64
启动
./bin/kibana
集成SpringBoot
参考文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/index.html
maven依赖
org.elasticsearch
elasticsearch
7.1.1
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.1.1
org.elasticsearch
elasticsearch
配置类
package com.luo.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @Auther: 罗
* @Date: 2021/3/12 14:28
* @Description:
*/
@Configuration
public class ElasticSearchConfig {
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
/*builder.addHeader("Authorization", "Bearer " + TOKEN);
builder.setHttpAsyncResponseConsumerFactory(
new HttpAsyncResponseConsumerFactory
.HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024));*/
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("121.43.135.181", 9200, "http")));
return client;
}
}
创建索引并添加数据
/*
* @Author 罗
* @Description 创建索引
**/
@Test
void index1() throws IOException {
ObjectMapper mapper = new ObjectMapper();
IndexRequest indexRequest = new IndexRequest("user");//索引库
indexRequest.id("1");//文档id
User user = new User(1, "罗健康", new Date(), 8000.0, "明天会更好吗,阿门");
String jsonString =mapper.writeValueAsString(user);
indexRequest.source(jsonString, XContentType.JSON);
restHighLevelClient.index(indexRequest,ElasticSearchConfig.COMMON_OPTIONS);
}
@Test
void index2() throws IOException {
Map<String, Object> jsonMap = new HashMap<>(8);
jsonMap.put("id", "2");
jsonMap.put("name", "kimchy");
jsonMap.put("date", new Date());
jsonMap.put("money", 34.34);
jsonMap.put("content", "trying out Elasticsearch");
IndexRequest indexRequest = new IndexRequest("user")
.id("2").source(jsonMap);
restHighLevelClient.index(indexRequest,ElasticSearchConfig.COMMON_OPTIONS);
}
批量添加数据
/*
* @Author 罗
* @Description 批处理数据
* @Date 2021/3/16 9:22
* @Param []
* @return void
**/
public void buik() throws IOException {
ArrayList list = new ArrayList(16);
IndexRequest indexRequest = new IndexRequest();
BulkRequest bulkRequest = new BulkRequest("user");
list.forEach(item->{
indexRequest.source(JSON.toJSON(item),XContentType.JSON);
bulkRequest.add(indexRequest);
});
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
}
获取文档信息
//获取数据
@Test
void getdata() throws IOException {
GetRequest getRequest = new GetRequest("user","id");
try {
GetResponse getResponse = restHighLevelClient.get(getRequest, ElasticSearchConfig.COMMON_OPTIONS);
String index = getResponse.getIndex(); //获取索引名
String id = getResponse.getId();//获取文档id、
if (getResponse.isExists()) {
long version = getResponse.getVersion();//获取版本号
String sourceAsString = getResponse.getSourceAsString();//获取数据,转化为字符串
ObjectMapper mapper = new ObjectMapper();
User user = mapper.readValue(sourceAsString, User.class);
System.out.println(user);
Map<String, Object> sourceAsMap = getResponse.getSourceAsMap();//获取数据,转化为map
System.out.println(sourceAsMap);
byte[] sourceAsBytes = getResponse.getSourceAsBytes();//获取数据,转化为字节数组
} else {
}
} catch (ElasticsearchException e) {
if (e.status() == RestStatus.NOT_FOUND) {
}
if (e.status() == RestStatus.CONFLICT) {
}
} catch (Exception e) {
e.printStackTrace();
}
}
判断文档是否存在
public void documentIsExits() throws IOException {
GetRequest getRequest = new GetRequest(
"user",
"1");
getRequest.fetchSourceContext(new FetchSourceContext(false)); //不拉取_source,效率更高
getRequest.storedFields("_none_"); //非存储字段
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
删除文档
public void d() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest(
"user",
"1");
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
String index = deleteResponse.getIndex();
String id = deleteResponse.getId();
long version = deleteResponse.getVersion();
ReplicationResponse.ShardInfo shardInfo = deleteResponse.getShardInfo(); //获取分片信息
if (shardInfo.getTotal() != shardInfo.getSuccessful()) {
}
if (shardInfo.getFailed() > 0) {
for (ReplicationResponse.ShardInfo.Failure failure :
shardInfo.getFailures()) {
String reason = failure.reason();
}
}
}
更新文档
@Test
public void update() throws IOException {
UpdateRequest request = new UpdateRequest(
"user",
"1");
ObjectMapper mapper = new ObjectMapper();
User user = new User(1, "小王", new Date(), 8400.0, "我爱你,隔壁老王");
String jsonString =mapper.writeValueAsString(user);
request.doc(jsonString, XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(request, RequestOptions.DEFAULT);
}
-------------------------------
@Test
public void update2() throws IOException {
Map<String, Object> jsonMap = new HashMap<>();
//jsonMap.put("date", new Date());
jsonMap.put("content", "滚远点");
UpdateRequest request = new UpdateRequest("user", "2")
.doc(jsonMap);
UpdateResponse updateResponse = restHighLevelClient.update(request, RequestOptions.DEFAULT);
}
批量操作文档
@Test
public void bulkRequest () throws IOException {
BulkRequest request = new BulkRequest();
request.add(new IndexRequest("posts").id("1")
.source(XContentType.JSON,"field", "foo"));
request.add(new IndexRequest("posts").id("2")
.source(XContentType.JSON,"field", "bar"));
request.add(new IndexRequest("posts").id("3")
.source(XContentType.JSON,"field", "baz"));
request.add(new DeleteRequest("posts", "3"));
request.add(new UpdateRequest("posts", "2")
.doc(XContentType.JSON,"other", "test"));
request.add(new IndexRequest("posts").id("4")
.source(XContentType.JSON,"field", "baz"));
request.timeout(TimeValue.timeValueMinutes(2));
BulkResponse bulkResponse = restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
//有一个操作失败就会返回true
if (bulkResponse.hasFailures()) {
}
//遍历结果
for (BulkItemResponse bulkItemResponse : bulkResponse) {
DocWriteResponse itemResponse = bulkItemResponse.getResponse();
switch (bulkItemResponse.getOpType()) {
case INDEX:
case CREATE:
IndexResponse indexResponse = (IndexResponse) itemResponse;
break;
case UPDATE:
UpdateResponse updateResponse = (UpdateResponse) itemResponse;
break;
case DELETE:
DeleteResponse deleteResponse = (DeleteResponse) itemResponse;
}
}
}
重新构建索引(包含数据)
public void multiGetRequest() throws IOException {
ReindexRequest reindexRequest = new ReindexRequest();
reindexRequest.setSourceIndices("user");
reindexRequest.setDestIndex("you_index");
reindexRequest.setRefresh(true);
BulkByScrollResponse bulkResponse = restHighLevelClient.reindex(reindexRequest, RequestOptions.DEFAULT);
TimeValue timeTaken = bulkResponse.getTook(); //消耗总时间
boolean timedOut = bulkResponse.isTimedOut();//是否超时
long totalDocs = bulkResponse.getTotal();//获取已处理文档的数量
long updatedDocs = bulkResponse.getUpdated();//获取更新文档的数量
long createdDocs = bulkResponse.getCreated();//获取新建文档的数量
long deletedDocs = bulkResponse.getDeleted();//获取删除文档的数量
long batches = bulkResponse.getBatches();
long noops = bulkResponse.getNoops();
long versionConflicts = bulkResponse.getVersionConflicts();
long bulkRetries = bulkResponse.getBulkRetries();
long searchRetries = bulkResponse.getSearchRetries();
TimeValue throttledMillis = bulkResponse.getStatus().getThrottled();
TimeValue throttledUntilMillis =
bulkResponse.getStatus().getThrottledUntil();
List<ScrollableHitSource.SearchFailure> searchFailures =
bulkResponse.getSearchFailures();
List<BulkItemResponse.Failure> bulkFailures =
bulkResponse.getBulkFailures();
}
搜索文档
查询所有的数据
@Test
public void SearchAll() throws IOException {
SearchRequest searchRequest = new SearchRequest("user");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
RestStatus status = searchResponse.status(); //获取状态
TimeValue took = searchResponse.getTook(); //所花费的时间
Boolean terminatedEarly = searchResponse.isTerminatedEarly();
boolean timedOut = searchResponse.isTimedOut(); //是否超时
SearchHits hits = searchResponse.getHits();//外层的hits
TotalHits totalHits = hits.getTotalHits();
System.out.println(totalHits.value);//查询到的总文档数
SearchHit[] hitsHits = hits.getHits();//内层的hits
for (SearchHit hitsHit : hitsHits) {
String source = hitsHit.getSourceAsString(); //数据
System.out.println(source);
}
}
条件查询
单一条件查询
package com.luo.search.web;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @Auther: 罗
* @Date: 2021/3/15 14:10
* @Description:
*/
@RestController
public class SearchWeb {
@Autowired
private RestHighLevelClient restHighLevelClient;
@RequestMapping("/search/{keyword}/{page}/{pagesize}")
public List Searchby(@PathVariable("keyword") String keyword,
@PathVariable("page") Integer page,
@PathVariable("pagesize") Integer pagesize) throws IOException {
ArrayList<Map> list = new ArrayList<>(16);
//构建搜索请求,指定操作的索引
SearchRequest firstSearchRequest = new SearchRequest("user");
//搜索条件构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//指定搜索类型
//termQuery处理字符串必须加上keyword,否则查询无效
//searchSourceBuilder.query(QueryBuilders.termQuery("content.keyword", keyword));
searchSourceBuilder.query(QueryBuilders.matchPhraseQuery("content", keyword));
//设置高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.encoder("utf-8")//编码
.field("content")//需要高亮的字段
.preTags("").postTags("");//前后缀
searchSourceBuilder.highlighter(highlightBuilder);
//分页
searchSourceBuilder.from(page);
searchSourceBuilder.size(pagesize);
//设置超时时间
searchSourceBuilder.timeout(TimeValue.timeValueSeconds(50));
//设置排序规则
searchSourceBuilder.sort("money", SortOrder.DESC);
//往请求中注入搜索条件
firstSearchRequest.source(searchSourceBuilder);
//开始搜索
SearchResponse search = restHighLevelClient.search(firstSearchRequest, RequestOptions.DEFAULT);
Map<String,Object> sourceAsMap =null;
SearchHit[] hits = search.getHits().getHits();
for (SearchHit hit : hits) {
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField content = highlightFields.get("content");
sourceAsMap = hit.getSourceAsMap();
if (content!=null){
//涉及到字符串的拼接,StringBuilder效率更高
StringBuilder new_content= new StringBuilder(16);
Text[] fragments = content.getFragments();
for (Text fragment : fragments) {
new_content+=fragment;
}
sourceAsMap.put(content.getName(),new_content);
}
list.add(sourceAsMap);
}
return list;
}
}
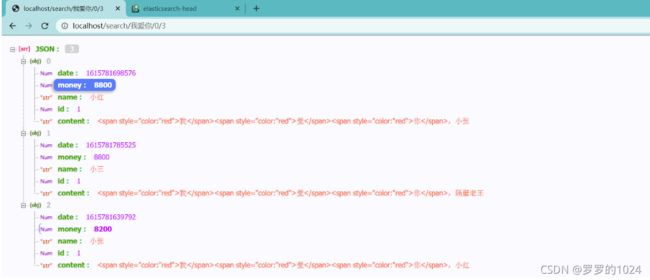
http://localhost/search/我爱你/0/5
多条件查询
package com.luo.search.web;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @Auther: 罗
* @Date: 2021/3/15 14:10
* @Description:
*/
@RestController
public class SearchWeb {
@Autowired
private RestHighLevelClient restHighLevelClient;
@RequestMapping("/search/{keyword}/{page}/{pagesize}")
public List Searchby(@PathVariable("keyword") String keyword,
@PathVariable("page") Integer page,
@PathVariable("pagesize") Integer pagesize) throws IOException {
ArrayList<Map> list = new ArrayList<>(16);
//构建搜索请求,指定操作的索引
SearchRequest firstSearchRequest = new SearchRequest("user");
//搜索条件构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//指定搜索类型
//searchSourceBuilder.query(QueryBuilders.matchQuery("name", "小三"));
//termQuery处理字符串必须加上keyword,否则查询无效
// searchSourceBuilder.query(QueryBuilders.termQuery("content.keyword", keyword));
//searchSourceBuilder.query(QueryBuilders.matchPhraseQuery("content", keyword));
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//boolQuery.must(QueryBuilders.rangeQuery("money").gte(8400).lte(8800));
boolQuery.must(QueryBuilders.matchPhraseQuery("content",keyword));
boolQuery.must(QueryBuilders.matchPhraseQuery("name","小三"));
//用filter在结果上过滤,不会重新计算得分,效率更高,
boolQuery.filter(QueryBuilders.rangeQuery("money").gte(8400).lte(8800));
searchSourceBuilder.query(boolQuery);
//设置高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.encoder("utf-8")//编码
.field("content")//需要高亮的字段
.preTags("").postTags("");//前后缀
searchSourceBuilder.highlighter(highlightBuilder);
//分页
searchSourceBuilder.from(page);
searchSourceBuilder.size(pagesize);
//设置超时时间
searchSourceBuilder.timeout(TimeValue.timeValueSeconds(50));
//设置排序规则
searchSourceBuilder.sort("money", SortOrder.DESC);
//往请求中注入搜索条件
firstSearchRequest.source(searchSourceBuilder);
//开始搜索
SearchResponse search = restHighLevelClient.search(firstSearchRequest, RequestOptions.DEFAULT);
Map<String,Object> sourceAsMap =null;
SearchHit[] hits = search.getHits().getHits();
for (SearchHit hit : hits) {
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField content = highlightFields.get("content");
sourceAsMap = hit.getSourceAsMap();
if (content!=null){
//涉及到字符串的拼接,StringBuilder效率更高
StringBuilder new_content= new StringBuilder(16);
Text[] fragments = content.getFragments();
for (Text fragment : fragments) {
new_content+=fragment;
}
sourceAsMap.put(content.getName(),new_content);
}
list.add(sourceAsMap);
}
return list;
}
}