MySQL优化方案和explain详解
目录
MySQL优化的考虑点
优化查询过程中的数据访问
数据库设计阶段的优化
SQL语句优化
联合查询优化
分组查询优化
常见问题
MySQL中的explain详解
在编写 SQL 的时候,要谨慎地仔细评估并且先问自己几个问题:
- 你的 SQL 涉及到的表,它的数据规模是多少?
- 你的 SQL 可能会遍历的数据量是多少?
- 尽量地避免写出慢 SQL。
- 能不能利用缓存减少数据库查询次数?
- 在使用缓存的时候,还需要特别注意的就是缓存命中率,要尽量避免请求命中不了缓存,穿透到数据库上。
分析SQL查询慢的原因的一些语句:
mysql > show variables like 'profiling'; #默认情况下,profiling 是关闭的,我们可以在会话级别开启这个功能。
mysql > set profiling = 'ON'; #通过设置 profiling='ON'来开启 show profile:
mysql > show profiles; #看下当前会话都有哪些 profiles,使用下面这条命令:
mysql > show profile; #想要查看上一个查询的开销.在 SHOW PROFILE 中我们可以查看不同部分的开销,比如 cpu、block.io 等:
mysql > show profile for query 2; #可以查看指定的 Query ID 的开销
mysql > show variables like '%slow_query_log'; //慢查询是否已经开启
mysql > set global slow_query_log='ON'; //把慢查询日志打开,注意需要使用 global
mysql > show variables like '%long_query_time%'; //查看慢查询的时间阈值设置
mysql > set global long_query_time = 3; //把时间缩短,比如设置为 3 秒
# 可以使用 MySQL 自带的 mysqldumpslow 工具统计慢查询日志
# 开启了慢查询日志并设置时间阈值之后,只要大于这个阈值的 SQL 语句都会保存在慢查询日志中
perl mysqldumpslow.pl -s t -t 2 "/tmp/slow.log"(1) 使用show status 会返回一些计数器;show global status 查看服务器级别的所有计数。有时根据这些计数,可以判断出哪些操作消耗时间多。
(2) 使用show processlist 观察是否有大量线程处于不正常的状态。
(3) 使用explain分析单条SQL语句,如果发现查询需要扫描大量的数据但是只返回少数的行,就需要加索引优化。
MySQL优化的考虑点
优化查询过程中的数据访问
- 访问数据太多会导致查询性能下降;
- 确定应用程序是否在检索大量超过需要的数据,可能是太多的行或者列;
- 确认MySQL服务器是否在分析大量不必要的数据行。
- 重复查询相同的数据,可以使用缓存
- 改变数据库和表的结构,适当修改表范式(例如适当的冗余)
数据库的三大范式:
第一范式:确保每列的原子性(强调的是列的原子性,即列不能够再分成其他几列).
第二范式:在第一范式的基础上更进一层,目标是确保表中的每列都和主键相关(一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的部分)
第三范式:在第二范式的基础上更进一层,目标是确保每列都和主键列直接相关,而不是间接相关(另外非主键列必须直接依赖于主键,不能存在传递依赖)。如果一个关系满足第二范式,并且除了主键以外的其它列都不依赖于主键列,则满足第三范式.
数据库设计阶段的优化
1、数据表数据类型优化
- tinyint、smallint、int、bigint 考虑空间和范围的问题
- char固定长度、varchar 可变长度
- enum 的使用,底层存储的是数值
- IP地址可以存储为整数(UNSIGNED INT),然后在程序中转换
- 太多的字段垂直分表,太多的数据水平分表
- 统一使用utf8mb4( 5.5.3版本以上支持)兼容性更好,不同的字符集进行比较前需要进行转换,会造成索引失效。
2、索引的优化
- 索引的创建原则:索引不是越多越好,在合适的字段上创建合适的索引,注意最左原则
- 复合索引的前缀原则:like查询%问题、全表扫描优化、or条件索引使用情况、字符串类型索引失效的问题、避免回表
- 设置主键为数值类型,并且递增
3、数据库架构的优化:主从复制、读写分离、双主热备、负载均衡
SQL语句优化
- count(*) 会忽略所有的列,直接统计所有列数,因此不要使用 count(列名)
- 用啥查啥,不要select *;
- 当只要一行数据时使用 LIMIT 1
- 尽量避免在列上运算,这样会导致索引失效;
- 使用批量插入语句;
- limit基数较大时使用between:order by id limit 1000,10 优化为:where id between 1000 and 1010 order by id
- 不要 ORDER BY RAND() 获取多条随机记录
- 避免使用NULL
- 如果不需要排序,使用order by null ,MySQL不会再进行文件排序
- 类型转换导致索引失效。比如在 varchar 类型字段上使用整数查询:WHERE name=123;
- 不等于条件下 ( != 或者 <> ) 索引会失效;is null可以使用索引,is not null无法使用索引;like以通配符%开头索引失效
- OR 前后存在非索引的列,索引失效
- 优化长难句的查询语句:变复杂为简单、切分查询、分解关联查询(一次性删除1000万条记录,优化为 一次删除1万条,然后暂停一会儿,共1000次)
联合查询优化
- 确定on或者using子语句的列上有索引
- 尽可能使用关联查询来替代子查询,减少查询的次数,或者将子查询SQL拆开结合程序多次查询
- UNION ALL 的效率高于 UNION
- 需要JOIN 的字段,数据类型保持绝对一致。
- LEFT JOIN 时,选择小表作为驱动表,大表作为被驱动表,减少外层循环的次数。
- INNER JOIN 时,MySQL会自动将 小结果集的表选为驱动表。
分组查询优化
- 确保 group by 和 order by 中用的是同一个表中的列,这样MySQL才有可能使用索引
- group by 先排序再分组,遵照索引建的最左原则
- where效率高于having,能写在where限定的条件就不要写在having中了
- 如果包含了order by、group by、distinct 这些语句,where条件过滤出来的结果集最好保持在1000行以内,否则SQL会很慢。
如何优化长难的查询语句,应该使用一个复杂的查询还是多个简单的查询?
MySQL内部每秒可以扫描内存中上百万行的数据,相比之下响应数据给客户端会比较慢,所以尽可能少的使用查询,有时候将一个大的查询分解为多个小的查询是很有必要的。分解查询后的结果再使用编程语言进行组合处理。比如:
# 在record表中随机获取10条数据
SELECT * FROM `record` ORDER BY RAND() limit 10
# 优化如下,下面语句的10000可以提前查出 max(record_id),或根据实际情况设置
SELECT * FROM `record` WHERE record_id >= RAND()*10000 ORDER BY record_id LIMIT 10;
常见问题
【问】查询总数 COUNT(*)、COUNT(1)、COUNT(字段) 的区别
【答】查询效率 COUNT(*) = COUNT(1) > COUNT(字段),因为InnoDB中,COUNT(*) 和 COUNT(1) 的复杂度都是O(N),采用全表扫描;MyISAM 统计数据表的行数只需要O(1)的复杂度,这是因为每张 MyISAM 的数据表都有一个 meta 信息存储了row_count值。COUNT(字段) 会忽略值为 NULL 的数据行,而 COUNT(*) 只是统计数据行数,不管某个字段是否为 NULL。
【问】为什么子查询的执行效率不高?
- 执行子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表,然后外层查询语句从临时表中查询记录,查询完毕后,再撤销这些临时表。这样会消耗过多的CPU和IO资源,产生大量的慢查询。
- 子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。
- 对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
- 可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表,其速度比子查询要快,如果查询中使用索引的话,性能就会更好。
- 尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代。
【问】在 WHERE 条件字段上加了索引,为什么在 ORDER BY 字段上还要加索引呢?
- 在 WHERE 子句中避免全表扫描,在 ORDER BY 子句避免使用 FileSort 排序。
- 尽量使用 Index 完成 ORDER BY 排序。如果 WHERE 和 ORDER BY 后面是相同的列就使用单索引列; 如果不同就使用联合索引。
【问】什么是前缀索引 ?
【答】如果创建索引的语句不指定前缀长度,那么索引就会包含整个字符串,也可以指定长度:alter table users add index idx_field(field(6));
MySQL中的explain详解
expain出来的信息有10列,分别是:id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra。
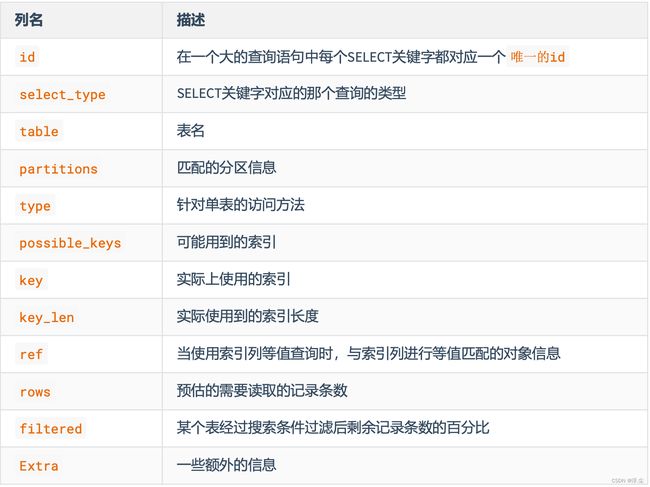
简单总结:
- rows 的含义就是 MySQL 预估执行这个 SQL 可能会遍历的数据行数。
- type 这一列表示这个查询的访问类型。
- ALL 代表全表扫描,这是最差的情况。
- range 代表 使用了索引,在索引中进行范围查找。
- 如果直接命中索引,type 这一列显示的是 index。
- 如果使用了索引,可以在 key 这一 列中看到实际上使用了哪个索引。
测试表数据:
CREATE TABLE `tuser` (
`id` int NOT NULL,
`loginname` varchar(100) DEFAULT NULL,
`name` varchar(100) DEFAULT NULL,
`age` int DEFAULT NULL,
`sex` char(1) DEFAULT NULL,
`dep` int DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_loginname` (`loginname`),
KEY `idx_dep` (`dep`),
KEY `idx_name_age_sex` (`name`,`age`,`sex`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表';
CREATE TABLE `tdep` (
`id` int NOT NULL,
`name` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='部门表';
CREATE TABLE `taddr` (
`id` int NOT NULL,
`addr` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
FULLTEXT KEY `ft_addr` (`addr`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='地址表';select_type:查询类型,主要⽤于区别普通查询、联合查询(union、union all)、⼦查询等复杂查询。
- simple:表示不需要union操作或者不包含⼦查询的简单select查询。有连接查询时,外层的查询为simple,且只有⼀个。
- primary:⼀个需要union操作或者含有⼦查询的select,位于最外层的单位查询的select_type即为primary。且只有⼀个。
- subquery:除了from字句中包含的⼦查询外,其他地⽅出现的⼦查询都可能是subquery。
- dependent subquery:与dependent union类似,表示这个subquery的查询要受到外部表查询的影响。
- union:union连接的两个select查询,第⼀个查询是PRIMARY,除了第⼀个表外,第⼆个以后的表select_type都是union。
- dependent union:与union⼀样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响。
- union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null。
- derived:from字句中出现的⼦查询,也叫做派⽣表,其他数据库中可能叫做内联视图或嵌套select。
type,依次从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL。
除了all之外,其他的type都可以使⽤到索引,除了index_merge之外,其他的type只可以⽤到⼀个索引。(注意事项:最少要索引使⽤到range级别。)
- system:表中只有⼀⾏数据或者是空表。
- const(重要):使⽤唯⼀索引或者主键,返回记录⼀定是1⾏记录的等值where条件时,通常type是const。其他数据库也叫做唯⼀索引扫描。
- eq_ref(重要):关键字:连接字段主键或者唯⼀性索引。此类型通常出现在多表的 join 查询, 表示对于前表的每⼀个结果, 都只能匹配到后表的⼀⾏结果. 并且查询的⽐较操作通常是 '=', 查询效率较⾼。
- ref(重要):针对⾮唯⼀性索引,使⽤等值(=)查询⾮主键。或者是使⽤了最左前缀规则索引的查询。
- fulltext全⽂索引检索:要注意,全⽂索引的优先级很⾼,若全⽂索引和普通索引同时存在时,mysql不管代价,优先选择使⽤全⽂索引。
- ref_or_null:与ref⽅法类似,只是增加了null值的⽐较。实际⽤的不多。
- unique_subquery:⽤于where中的in形式⼦查询,⼦查询返回不重复值唯⼀值
- index_subquery:⽤于in形式⼦查询使⽤到了辅助索引或者in常数列表,⼦查询可能返回重复值,可以使⽤索引将⼦查询去重。
- range(重要):索引范围扫描,常⻅于使⽤>,
- index_merge:表示查询使⽤了两个以上的索引,最后取交集或者并集,常⻅and ,or的条件使⽤了不同的索引,官⽅排序这个在ref_or_null之后,但是实际上由于要读取所个索引,性能可能⼤部分时间都不如range。
- index(重要):关键字:条件是出现在索引树中的节点的。可能没有完全匹配索引。索引全表扫描,把索引从头到尾扫⼀遍,常⻅于使⽤索引列就可以处理不需要读取数据⽂件的查询、可以使⽤索引排序或者分组的查询。
- all(重要):这个就是全表扫描数据⽂件,然后再在server层进⾏过滤返回符合要求的记录。
possible_keys:此次查询中可能选⽤的索引,⼀个或多个。
key:查询真正使⽤到的索引,select_type为index_merge时,这⾥可能出现两个以上的索引,其他的select_type这⾥只会出现⼀个。
key_len:⽤于处理查询的索引⻓度。
- 如果是单列索引,那就整个索引⻓度算进去,如果是多列索引,那么查询不⼀定都能使⽤到所有的列,具体使⽤到了多少个列的索引,这⾥就会计算进去,没有使⽤到的列,这⾥不会计算进去。
- 留意下这个列的值,算⼀下你的多列索引总⻓度就知道有没有使⽤到所有的列了。
- 另外,key_len只计算where条件⽤到的索引⻓度,⽽排序和分组就算⽤到了索引,也不会计算到key_len中。
ref:
- 如果是使⽤的常数等值查询,这⾥会显示const
- 如果是连接查询,被驱动表的执⾏计划这⾥会显示驱动表的关联字段
- 如果是条件使⽤了表达式或者函数,或者条件列发⽣了内部隐式转换,这⾥可能显示为func
rows:这⾥是执⾏计划中估算的扫描⾏数,不是精确值(InnoDB不是精确的值,MyISAM是精确的值,主要原因是InnoDB⾥⾯使⽤了MVCC并发机制)
extra:这个列包含不适合在其他列中显示单⼗分重要的额外的信息,这个列可以显示的信息⾮常多,有⼏⼗种,常⽤的有:
- using temporary:表示使⽤了临时表存储中间结果。MySQL在对查询结果order by和group by时使⽤临时表,临时表可以是内存临时表和磁盘临时表,执⾏计划中看不出来,需要查看status变量,used_tmp_table,used_tmp_disk_table才能看出来。
- no tables used:不带from字句的查询或者From dual查询,使⽤not in()形式⼦查询或not exists运算符的连接查询,这种叫做反连接。即,⼀般连接查询是先查询内表,再查询外表,反连接就是先查询外表,再查询内表。
- using fifilesort(重要):排序时⽆法使⽤到索引时,就会出现这个。常⻅于order by和group by语句中说明MySQL会使⽤⼀个外部的索引排序,⽽不是按照索引顺序进⾏读取。MySQL中⽆法利⽤索引完成的排序操作称为“⽂件排序”。
- using index(重要):查询时不需要回表查询,直接通过索引就可以获取查询的数据。表示相应的SELECT查询中使⽤到了覆盖索引(Covering Index),避免访问表的数据⾏,效率不错!如果同时出现Using Where ,说明索引被⽤来执⾏查找索引键值。如果没有同时出现Using Where ,表明索引⽤来读取数据⽽⾮执⾏查找动作。
- using where(重要):表示存储引擎返回的记录并不是所有的都满⾜查询条件,需要在server层进⾏过滤。