关于pytorch中的distributedsampler函数使用
1.如何使用这个分布式采样器
在使用distributedsampler函数时,观察loss发现loss收敛有规律,发现是按顺序读取数据,未进行shuffle。
问题的解决方式就是怀疑 seed 有问题,参考源码 DistributedSampler,,发现 shuffle 的结果依赖 g.manual_seed(self.epoch) 中的 self.epoch。
def __iter__(self):
# deterministically shuffle based on epoch
g = torch.Generator()
g.manual_seed(self.epoch)
if self.shuffle:
indices = torch.randperm(len(self.dataset), generator=g).tolist()
else:
indices = list(range(len(self.dataset)))
# add extra samples to make it evenly divisible
indices += indices[:(self.total_size - len(indices))]
assert len(indices) == self.total_size
# subsample
indices = indices[self.rank:self.total_size:self.num_replicas]
assert len(indices) == self.num_samples
return iter(indices)而 self.epoch 初始默认是 0
self.dataset = dataset
self.num_replicas = num_replicas
self.rank = rank
self.epoch = 0
self.num_samples = int(math.ceil(len(self.dataset) * 1.0 / self.num_replicas))
self.total_size = self.num_samples * self.num_replicas
self.shuffle = shuffle但是 DistributedSampler 也提供了一个 set 函数来改变 self.epoch
def set_epoch(self, epoch):
self.epoch = epoch所以在运行的时候要不断调用这个 set_epoch 函数。只要把我的代码中的
# sampler.set_epoch(e)全部代码如下:
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
torch.distributed.init_process_group(backend="nccl")
input_size = 5
output_size = 2
batch_size = 2
data_size = 16
local_rank = torch.distributed.get_rank()
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
class RandomDataset(Dataset):
def __init__(self, size, length, local_rank):
self.len = length
self.data = torch.stack([torch.ones(5), torch.ones(5)*2,
torch.ones(5)*3,torch.ones(5)*4,
torch.ones(5)*5,torch.ones(5)*6,
torch.ones(5)*7,torch.ones(5)*8,
torch.ones(5)*9, torch.ones(5)*10,
torch.ones(5)*11,torch.ones(5)*12,
torch.ones(5)*13,torch.ones(5)*14,
torch.ones(5)*15,torch.ones(5)*16]).to('cuda')
self.local_rank = local_rank
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
dataset = RandomDataset(input_size, data_size, local_rank)
sampler = DistributedSampler(dataset)
rand_loader = DataLoader(dataset=dataset,
batch_size=batch_size,
sampler=sampler)
e = 0
while e < 2:
t = 0
# sampler.set_epoch(e)
for data in rand_loader:
print(data)
e+=1运行:
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 test.py2.关于用不用这个采样器的区别
多卡去训模型,尝试着用DDP模式,而不是DP模式去加速训练(很容易出现负载不均衡的情况)。遇到了一点关于DistributedSampler这个采样器的一点疑惑,想试验下在DDP模式下,使用这个采样器和不使用这个采样器有什么区别。
实验代码:
整个数据集大小为8,batch_size 为4,总共跑2个epoch。
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
torch.distributed.init_process_group(backend="nccl")
batch_size = 4
data_size = 8
local_rank = torch.distributed.get_rank()
print(local_rank)
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
class RandomDataset(Dataset):
def __init__(self, length, local_rank):
self.len = length
self.data = torch.stack([torch.ones(1), torch.ones(1)*2,torch.ones(1)*3,torch.ones(1)*4,torch.ones(1)*5,torch.ones(1)*6,torch.ones(1)*7,torch.ones(1)*8]).to('cuda')
self.local_rank = local_rank
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
dataset = RandomDataset(data_size, local_rank)
sampler = DistributedSampler(dataset)
#rand_loader =DataLoader(dataset=dataset,batch_size=batch_size,sampler=None,shuffle=True)
rand_loader = DataLoader(dataset=dataset,batch_size=batch_size,sampler=sampler)
epoch = 0
while epoch < 2:
sampler.set_epoch(epoch)
for data in rand_loader:
print(data)
epoch+=1运行命令: CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 test.py
实验结果:
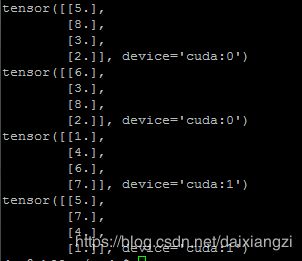
结论分析:上面的运行结果来看,在一个epoch中,sampler相当于把整个数据集 划分成了nproc_per_node份,每个GPU每次得到batch_size的数量,也就是nproc_per_node 个GPU分一整份数据集,总数据量大小就为1个dataset。
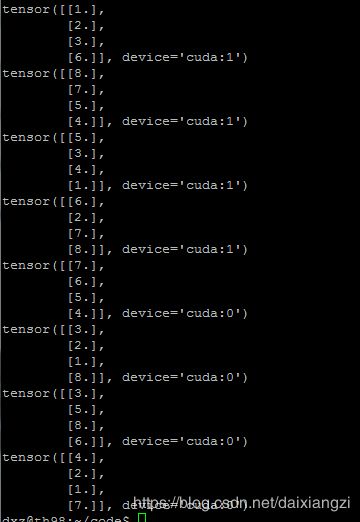
如果不用它里面自带的sampler,单纯的还是按照我们一般的形式。Sampler=None,shuffle=True这种,那么结果将会是下面这样的:
结果分析:没用sampler的话,在一个epoch中,每个GPU各自维护着一份数据,每个GPU每次得到的batch_size的数据,总的数据量为2个dataset,
总结:
一般的形式的dataset只能在同进程中进行采样分发,也就是为什么图2只能单GPU维护自己的dataset,DDP中的sampler可以对不同进程进行分发数据,图1,可以夸不同进程(GPU)进行分发。
参考:zhuanlan.zhihu.com/p/97115875
blog.csdn.net/daixiangzi/article/details/106162971