IDL基础语法
1 创建变量
命名规则:变量名必须以字母开头。它们可以包括其它字母,数字,下划线,美元符号。
以下是创建不同数据类型的方法,我们只需了解即可,知道如何创建整型【16位有符号长整型】和浮点型

PRO learn
;创建整型变量a,b
a=1
b=1
;输出需要用,隔开
print,'输出1:',a+b
c=5
d=2
;注意c/d都为整型,所以结果也是整型,舍弃小数点之后的数
print,'输出2:',c/d
e=9
f=4.0
;有浮点数f,所以结果会隐式转换成浮点数,故而有小数点
print,'输出3:',e/f
END
输出结果
输出1:2
输出2:2
输出3:2.250002 程序运行
一个pro文件可包含多个pro过程或函数,和pro文件名相同的pro过程是主函数。
就是运行和pro文件名相同的函数
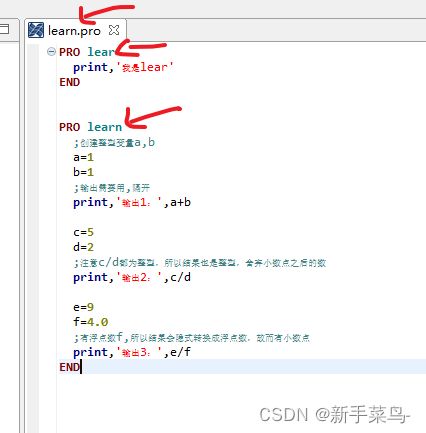

我们发现运行结果是运行的learn,不运行lear。因为文件名是learn.pro,所以只运行函数learn
3 函数使用
pro learn
;声明变量,在同一行声明需要加上&符号
x=2 & y=3 & z=4
;调用函数
volume = calculate(x,y,z)
print,'体积',volume
end
function calculate,x,y,z
;计算体积
return, x*y*z
end
输出如下:
体积 244 运算符
4.1 数学运算符

变量里的取大取小
pro learn
a=1
b=2
c=3
;取a/b最大的值赋给d
d=a>b
;取b/c最大的值赋给e
e=b>c
print,'d=',d
print,'e=',e
end
输出:
d= 2
e= 3矩阵里的求大求小


4.2 逻辑运算符

和C语言一样,不解释了
4.3 数组运算


4.4 关系运算符
返回的结果是0/1,和C语言一样
- EQ 等于
- NE 不等于
- GE 大于等于
- GT 大于
- LE 小于等于
- LT 小于
pro learn
a=1 & b=2
print,'GT:',a GT b
a=1 & b=2
print,'NE:',a NE b
a=1 & b=2
print,'GE:',a GE b
a=1 & b=2
print,'EQ:',a EQ b
a=1 & b=2
print,'LE:',a LE b
a=1 & b=2
print,'LT:',a LT b
end
输出:
GT: 0
NE: 1
GE: 0
EQ: 0
LE: 1
LT: 1在矩阵上的应用
4.5 矩阵运算
b1>0 ,就是和0相比,,取最大的值,当b1小于0时,取0
(b1 LT 0)*-999+(b1 GE 0)*b1 当b1小于0时值为1,然后乘上-999,就相当于赋予-999.后面的(b1 GE 0)值为0
之后的情况类似,不懂再来问我

5 循环语句
pro learn
;循环[0,3]
;这个循环ENDFOR可以不加
FOR i=0,3 DO PRINT,i*2
;循环[0,5]
FOR i=0,5 DO BEGIN
PRINT,i
ENDFOR
;[10,1] 步长为-2
FOR i=10,1,-2 DO BEGIN
PRINT,i
ENDFOR
end6 判断语句
PRO TEST_IF, num, div
;如果num%2==0,就执行。。。
IF((num MOD 2) EQ 0) THEN BEGIN
;string(num)变为字符串类型
PRINT,STRING(num)+' 是偶数!'
ENDIF
;同理
IF((num MOD div) EQ 0) THEN BEGIN
PRINT,STRING(num)+'能够被'+STRING(div)+'整除!'
ENDIF ELSE BEGIN
PRINT,STRING(num)+'不能够被'+STRING(div)+'整除!'
ENDELSE
END
PRO learn
;这是在主函数中调用其他PRO,和调用函数区分一下
;调用函数需要加()
;调用PRO不需要加
TEST_IF,16,3
END7 常用函数
PRO learn
file = 'AMOD0320.hdf'
;求字符串长度,有多少个字符。 不用像C语言一样考虑'\0'
PRINT, '长度: ', STRLEN(file)
;下标是从0开始的
;从下标为1的位置,向后取5个
;下标为1的位置是'M',向后取5个(包括M自身) MOD03(5个字符)
PRINT, '取: ', STRMID(file, 1, 5)
;求字符'.'的下标
pos = STRPOS(file, '.', /REVERSE_SEARCH)
print,pos ;就是第8个
;从下标为pos+1的位置,往后取全部
PRINT, '后缀: ', STRMID(file, pos+1)
END
输出:
长度: 12
取: MOD03
8
后缀: hdfWHERE()函数
where() 函数用于返回数组中满足特定条件的元素下标,常用于条件判断和数据筛选。该函数的基本语法如下:
- WHERE, Data, Mask [, COUNT=variable]
其中
Data是进行判断的数组,Mask是布尔类型的数组,大小与Data相同,用于指定对应位置的元素是否符合条件。若符合条件,则在输出的数组中对应位置填 1;否则填 0。最终函数会返回一个一维数组,表示符合条件的元素在原始数组中的下标。
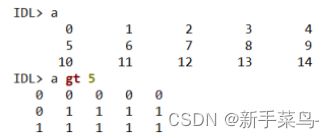
首先,使用 INDGEN 函数生成了一个从 0 开始、长度为 10 的一维数组,表示为 array = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]。
然后使用 WHERE 函数,判断数组中哪些元素大于 5,返回对应的下标。具体来说:
-
array GT 5表示将array数组的每个元素与 5 比较,将比 5 大的元素换成 1(表示 True),比 5 小的元素换成 0(表示 False),得到一个大小为 10 的布尔类型数组。【这个不用管】 -
count表示符合条件(即大于 5)的元素个数,B则是一个一维数组,保存了所有符合条件元素的下标(即在原数组中位置的索引值)。而B_C则是一个返回所有不符合条件(即小于等于 5)元素下标的数组。 -
当同时使用
COMPLEMENT和NCOMPLEMENT参数时,可以获得不符合和符合条件的两种下标值。COMPLEMENT=B_C表示对不符合条件的元素返回的数组指定名称为B_C,而NCOMPLEMENT=count_c表示不符合条件元素的个数保存在名称为count_c的变量中。
PRO learn
; Create an integer array 0,1,2,...9
array = INDGEN(10)
PRINT, 'array = ', array
; where()返回的
B = WHERE(array GT 5, count, COMPLEMENT=B_C, NCOMPLEMENT=count_c)
; Print met the search criteria:
PRINT, 'Number of elements > 5: ', count
PRINT, 'Subscripts of elements > 5: ', B
PRINT, 'Number of elements <= 5: ', count_c
PRINT, 'Subscripts of elements <= 5: ', B_C
END
输出:
array = 0 1 2 3 4 5 6 7 8 9
Number of elements > 5: 4
Subscripts of elements > 5: 6 7 8 9
Number of elements <= 5: 6
Subscripts of elements <= 5: 0 1 2 3 4 5