Python——字符串、列表
1.字符串
使用双引号或者单引号中的数据,就是字符串.
注:python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
在Python中字符串是可以反方向读取的
下标和切片
下标索引
所谓“下标”,就是编号,就好比超市中的存储柜的编号,通过这个编号就能找到相应的存储空间
列表与元组支持下标索引, 字符串实际上就是字符的数组,所以也支持下标索引。
如果有字符串name = ‘abcdef’,在内存中的实际存储如下:
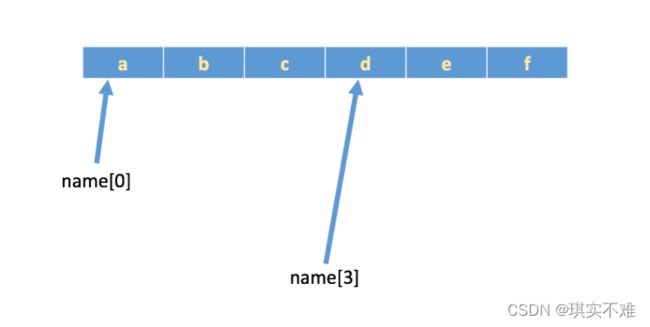
如果想取出部分字符,那么可以通过下标的方法,(注意python中下标从 0 开始)
name = ‘abcdef’
print(name[0])
print(name[1])
print(name[2])
切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法:[起始:结束:步长] 有方向(数值的正负)有区间
注意:选取的区间属于左闭右开型,即从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身)。
如果取出一部分,则可以在中括号[ ]中,使用:
name = ‘abcdef’
print(name[0:3]) # 取 下标0~2 的字符
print(name[3:5]) # 取 下标为3、4 的字符
print(name[2:]) # 取 下标为2开始到最后的字符
print(name[1:-1]) # 取 下标为1开始 到 最后第2个之间的字符
print(name[::2])#步长为2,2个一组
demo:12345 如果切出的不够一组,则将每组第一的取出:1 3 5
print(name[::-2])负数即为从右向左切
print(name[5:1:-2]) fd
print(name[1:5:2])
如果起始为负数则从后向前数字符串内容,但是输出方向依旧是从左向右
(终点数字遵循包前不包后原则)起始要从小向大写:
print(name[-5:-1]) 输出:bcde
要是从右向左切片步长为负需要从大向小写起始下标,反之亦然:
print(name[5:1:-2]) 输出:fd
字符串常见操作
<1>find 检测 str 是否包含在 mystr中,如果是返回开始的索引值,否则返回-1
mystr.find(str, start=0, end=len(mystr))
<2>index不在其中报异常 跟find()方法一样,只不过如果str不在 mystr中会报一个异常.
mystr.index(str, start=0, end=len(mystr))
<3>count 返回 str在start和end之间在 mystr里面出现的次数
mystr.count(str, start=0, end=len(mystr))
<4>replace替换函数 把 mystr 中的 str1 替换成 str2,如果 count 指定,则替换不超过 count 次. f mystr.replace(str1, str2, mystr.count(str1))
<5>split 以 str 为分隔符切片 mystr,如果 maxsplit有指定值,
则仅分隔 maxsplit 个子字符串 mystr.split(str=" ", 2)
<6>capitalize 把字符串的第一个字符大写
mystr.capitalize()
<7>title 把字符串的每个单词首字母大写 mystr.title()
弊端:不会区分单词也不会识别单词,重要一个或多个字母在一起就会识别为一个单词
<8>startswith 检查字符串是否是以 obj 开头, 是则返回 True,否则返回 False
mystr.startswith(obj)
<9>endswith 检查字符串是否以obj结束,如果是返回True,否则返回 False.
mystr.endswith(obj)
<10>lower 转换 mystr 中所有大写字符为小写
mystr.lower()
<11>upper 转换 mystr 中的小写字母为大写
mystr.upper()
<12>ljust 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串
mystr.ljust(width)
<13>rjust 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串
mystr.rjust(width)
<14>center 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
mystr.center(width)
<15>lstrip 删除 mystr 左边的空白字符
mystr.lstrip()
<16>rstrip 删除 mystr 字符串末尾的空白字符
mystr.rstrip()
<17>strip 删除mystr字符串两端的空白字符
mystr.strip()
<18>rfind 类似于 find()函数,不过是从右边开始查找
mystr.rfind(str, start=0,end=len(mystr) )
<19>rindex 类似于 index(),不过是从右边开始.
mystr.rindex( str, start=0,end=len(mystr))
<20>partition 把mystr以str分割成三部分,
str前,str和str后 mystr.partition(str)
<21>rpartition 类似于 partition()函数,
不过是从右边开始. mystr.rpartition(str)
<22>splitlines 按照行分隔,返回一个包含各行作为元素的列表
mystr.splitlines()
<23>isalpha 如果 mystr 所有字符都是字母 则返回 True,否则返回 False
mystr.isalpha()
<24>isdigit 如果 mystr 只包含数字则返回 True 否则返回 False.
mystr.isdigit()
<25>isalnum 如果 mystr 所有字符都是字母或数字则返回 True,否则返回 False
mystr.isalnum()
<26>isspace 如果 mystr 中只包含空格,则返回 True,否则返回 False.
mystr.isspace()
<27>join 用于将序列中的元素以指定的字符连接生成一个新 的字符串。
mystr.join(str)
2.列表 list[ ]
<1>列表的格式
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
<2>打印列表
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
print(namesList[0])
print(namesList[1])
print(namesList[2])
列表的循环遍历
- 使用for循环
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
for name in namesList:
print(name)
- 使用while循环
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
length = len(namesList)
i = 0
while i<length:
print(namesList[i])
i+=1
列表的相关操作
列表中存放的数据是可以进行修改的,比如"增"、“删”、“改”"
<1>添加元素("增"append, extend, insert)
append
通过append可以向列表添加元素
demo:
定义变量A,默认有3个元素
A = ['小王','小张','小华']
print("-----添加之前,列表A的数据-----")
for i in A:
print(i)
#提示、并添加元素
temp = input('请输入要添加的学生姓名:')
A.append(temp)
print("-----添加之后,列表A的数据-----")
for i_1 in A:
print(i_1)
extend
通过extend可以将另一个集合中的元素逐一添加到列表中
a = [1, 2]
b = [3, 4]
a.append(b) 将b添加到a中
[1, 2, [3, 4]]
a.extend(b) 将元素添加进去
[1, 2, 3, 4]
insert(index, object) 在指定位置index前插入元素object
注:没有那么多元素就跟在后边,有index则替换插入
a = [0, 1, 2]
a.insert(1, 3)
[0, 3, 1, 2]
<2>修改元素(“改”)
修改元素的时候,要通过下标来确定要修改的是哪个元素,然后才能进行修改
demo:
#定义变量A,默认有3个元素
A = ['xiaoWang','xiaoZhang','xiaoHua']
print("-----修改之前,列表A的数据-----")
for tempName in A:
print(tempName)
#修改元素
A[1] = 'xiaoLu'
print("-----修改之后,列表A的数据-----")
for tempName in A:
print(tempName)
<3>查找元素("查"in, not in, index, count)
所谓的查找,就是看看指定的元素是否存在
python中查找的常用方法为:
in(存在),如果存在那么结果为true,否则为false
not in(不存在),如果不存在那么结果为true,否则false
demo
#待查找的列表
nameList = ['xiaoWang','xiaoZhang','xiaoHua']
#获取用户要查找的名字
findName = input('请输入要查找的姓名:')
#查找是否存在
if findName in nameList:
print('找到了相同的名字')
else:
print('没有找到')
说明:
in的方法只要会用了,那么not in也是同样的用法,只不过not in判断的是不存在
index, count
index和count与字符串中的用法相同
>>> a = ['a', 'b', 'c', 'a', 'b']
>>> a.index('a', 1, 3) # 注意是左闭右开区间
Traceback (most recent call last):
File "" , line 1, in <module>
ValueError: 'a' is not in list
>>> a.index('a', 1, 4)
3
>>> a.count('b')
2
>>> a.count('d')
0
<4>删除元素("删"del, pop, remove)
列表元素的常用删除方法有:
del:根据下标进行删除 del 列表名[下标]
pop:删除最后一个元素 列表名.pop()
remove:根据元素的值进行删除 列表名.remove(值)
注:remove只删除从左到右的第一个值
demo:(del)
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']
print('------删除之前------')
for tempName in movieName:
print(tempName)
del movieName[2]
print('------删除之后------')
for tempName in movieName:
print(tempName)
demo:(pop)
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']
print('------删除之前------')
for tempName in movieName:
print(tempName)
movieName.pop()
print('------删除之后------')
for tempName in movieName:
print(tempName)
demo:(remove)
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']
print('------删除之前------')
for tempName in movieName:
print(tempName)
movieName.remove('指环王')
print('------删除之后------')
for tempName in movieName:
print(tempName)
<5>排序(sort, reverse)
sort方法是将list按特定顺序重新排列,默认为由小到大,参数reverse=True可改为倒序,由大到小。
reverse方法是将list逆置
>>> a = [1, 4, 2, 3]
>>> a
[1, 4, 2, 3]
>>> a.reverse()
>>> a
[3, 2, 4, 1]
>>> a.sort()
>>> a
[1, 2, 3, 4]
>>> a.sort(reverse=True)
>>> a
[4, 3, 2, 1]
列表的嵌套
类似while循环的嵌套,列表也是支持嵌套的
一个列表中的元素又是一个列表,那么这就是列表的嵌套
a=[[1,2,3],['a','b','c'],['!','#','$']]