kafka消费者使用详解
kafka消费者使用详解
消费者maven依赖:
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.3.1version>
dependency>
在上面了解了kafka消费组与消费者之间的关系后,我们可以着手进行消费者客户端的开发了。
一个正常的消费者逻辑需要具备以下几个步骤:
- 1、配置消费者参数并实例化消费者对象
- 2、订阅主题
- 3、拉取消息并消费
- 4、提交消费位移(默认是自动每5秒中提交一次)
- 5、关闭消费者实例
示例代码如下:
public class ConsumerDemo {
public static final String brokerList="192.168.195.135:9092";
public static final String topic = "topic-demo2";
private static final AtomicBoolean isRunning = new AtomicBoolean(true);
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
//配置kafka集群的地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,brokerList);
//配置kafka消费组的ID
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group.demo");
//实例化consumer
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties, new StringDeserializer(),new StringDeserializer());
try{
consumer.subscribe(Collections.singleton(topic));
while(isRunning.get()){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
Iterator<ConsumerRecord<String, String>> iterator = records.iterator();
while(iterator.hasNext()){
ConsumerRecord<String, String> record = iterator.next();
System.out.printf(" key = %s, value = %s,offset = %d,%n", record.key(), record.value(), record.offset());
}
}
}catch (Exception e){
e.printStackTrace();
}finally {
consumer.close();
}
}
}
从源码可以看出整个使用的流程如下:
配置启动参数–>实例化消费者对象–>订阅主题–>响应的主题中中拉取数据 -->关闭consumer(消费者对象)
1、必要的参数设置
kafkaconsumer中有如下四个参数是必须要进行设置的:
- bootstrap.servers:kafka集群地址
- group.id:消费者隶属的消费组名称,默认值为"";如果设置为空。则会抛出如下异常:
- key.deserializer和value.deserializer:与生产者的key.serializer和value.serializer对应。消费者从broker中获取的数据都是byte[]子对接数组,所以需要执行相应的反序列操作才能还原原有的对象。
2、订阅主题与分区
订阅主题
在创建好消费者后,我们就需要为该消费者订阅相关的主题了。一个消费者可以订阅一个或者多个主题。其有如下的4个订阅主题的重载方法:
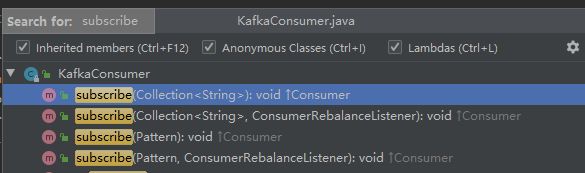
对于消费者使用集合的方式来订阅主题而言,比较容易理解,订阅了什么主题就消费什么主题中的消息。如果前后两次订阅了不同的主题,那么会消费者以最后一次为准。
此外还可以通过正则来订阅不同的主题,在之后的过程中,如果有人又创建了新的主题,并且主题名与正则表达式相匹配,那么这个消费者可以消费到新添加的主题中的消息。正则表达式的方式订阅如下:
Pattern.compile("topic-.*");
可以匹配所有以topic-开头,后面添加一个或者多个字符的主题。
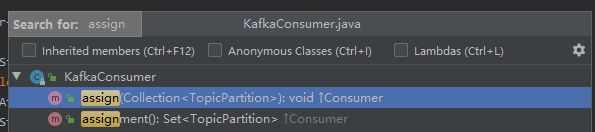
订阅特定分区
- 通过assign(Collecition partitions)方法来订阅某些主题上的特定分区。
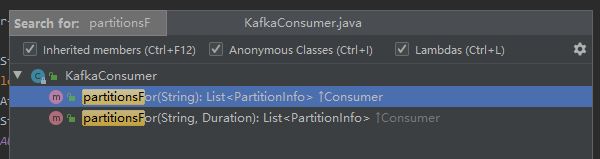
- 可以通过 List partitionsFor(String topic)方法来获取分区信息:
取消订阅
有订阅那么就必然有取消订阅。可以使用kafkaConsumer中的unSubscribe()方法来取消主题的订阅。
从源码的注释我们可以看出,这个方法可以取消通过上面三种方法(subsrcibe(Collection)、subcribe(Partition)、assign(Collection) )实现的订阅:
/**
* Unsubscribe from topics currently subscribed with {@link #subscribe(Collection)} or {@link #subscribe(Pattern)}.
* This also clears any partitions directly assigned through {@link #assign(Collection)}.
*/
public void unsubscribe() {
acquireAndEnsureOpen();
try {
fetcher.clearBufferedDataForUnassignedPartitions(Collections.emptySet());
this.subscriptions.unsubscribe();
if (this.coordinator != null)
this.coordinator.maybeLeaveGroup();
log.info("Unsubscribed all topics or patterns and assigned partitions");
} finally {
release();
}
}
3、反序列化
反序列化就是将byte数组转换成我们使用的java对象,我们来看下org.apache.kafka.common.serialization.Deserializer接口的定义
public interface Deserializer<T> extends Closeable {
default void configure(Map<String, ?> configs, boolean isKey) {
// intentionally left blank
}
T deserialize(String topic, byte[] data);
default T deserialize(String topic, Headers headers, byte[] data) {
return deserialize(topic, data);
}
@Override
default void close() {
// intentionally left blank
}
}
StringDeserializer的实现如下:
/**
* String encoding defaults to UTF8 and can be customized by setting the property key.deserializer.encoding,
* value.deserializer.encoding or deserializer.encoding. The first two take precedence over the last.
*/
public class StringDeserializer implements Deserializer {
private String encoding = "UTF8";
@Override
public void configure(Map configs, boolean isKey) {
String propertyName = isKey ? "key.deserializer.encoding" : "value.deserializer.encoding";
Object encodingValue = configs.get(propertyName);
if (encodingValue == null)
encodingValue = configs.get("deserializer.encoding");
if (encodingValue instanceof String)
encoding = (String) encodingValue;
}
@Override
public String deserialize(String topic, byte[] data) {
try {
if (data == null)
return null;
else
return new String(data, encoding);
} catch (UnsupportedEncodingException e) {
throw new SerializationException("Error when deserializing byte[] to string due to unsupported encoding " + encoding);
}
}
}
自定义反序列化类:
如果我们需要使用自定义的反序列化类,可以参考如下方法进行:
package cn.szyrm.kafka;
import com.alibaba.fastjson.JSONObject;
import org.apache.kafka.common.serialization.Deserializer;
import java.util.Map;
public class JSONDeserializer<T> implements Deserializer<T> {
private Class<?> clazz = Object.class;
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
Object deserializer = configs.get("deserializer.class");
if(deserializer instanceof Class){
clazz = (Class<?>) deserializer;
}
}
@Override
public T deserialize(String topic, byte[] data) {
T parse = JSONObject.parseObject(data, clazz);
return parse;
}
public Class<?> getClazz() {
return clazz;
}
public void setClazz(Class<?> clazz) {
this.clazz = clazz;
}
}
并在消费者实例初始化前做如下配置:
//实例化consumer
JSONDeserializer<User> userJSONDeserializer = new JSONDeserializer<>();
userJSONDeserializer.setClazz(User.class);
KafkaConsumer<String,User> consumer = new KafkaConsumer<>(properties, new StringDeserializer(),userJSONDeserializer);
其对应的序列化类参考如下:
public class JSONSerializer<T> implements Serializer<T> {
@Override
public void configure(Map configs, boolean isKey) {
}
@Override
public byte[] serialize(String topic, T data) {
return JSONObject.toJSONBytes(data);
}
}
这里使用的序列化和反序列化都使用FastJSON 对 对象进行序列化和反序列化。
4、消费消息
kafka中的消费是基于拉的模式。消息的消费一般有两种方式:推模式和拉模式。推模式是服务主动将消息推送给服务端,而拉模式是客户端主动向服务端发起请求来拉取消息。
kafka中消费消息是一个不断轮询的过程,消费要做就是重复调用poll()方法,返回所订阅主题(分区)上的一组消息。
poll的定义如下:
@Override
public ConsumerRecords<K, V> poll(final Duration timeout) {
return poll(time.timer(timeout), true);
}
timeout的设置取决于应用程序对相应的速度要求。可以直接将timeout设置为0,这样poll()方法会立即返回。如果该线程的唯一工作就是从kafka拉取消息,则可以将这个参数设置为一个极大的值。