ChatGPT系列学习(1)transformer基本原理讲解
文章目录
- 1. 简介
-
- 1.1. 发展史
- 2. Transformer 整体结构
- 3. 名词解释
-
- 3.1. token
- 4. transformer输入
-
- 4.1. 单词 Embedding
- 4.2. 位置Embedding
- 4.3. Transformer Embedding层实现
- 5. Attention结构
-
- 5.1. 简介
- 5.2. Self Attention(自注意力机制)
-
- 5.2.1. 简介
- 5.2.2. Self Attention结构
- 5.2.3. Q, K, V 的作用
- 5.2.4. Self-Attention 的输出
- 5.3. Multi-Head Attention
- 6. Encoder结构
-
- 6.1. 简介
- 6.2. Add & Norm
- 6.3. Feed Forward
- 6.4. Encoder结构实现
- 7. Decoder结构
-
- 7.1. 简介
- 7.2. 第一个Multi-Head Attention
- 7.3. 第二个 Multi-Head Attention
- 7.4. Softmax 预测输出单词
- 8. 总结
- 9. 参考资料
1. 简介
- 现在ChatGPT可以说是AI界的当红炸子鸡,甚至都不局限于AI界了,各行各业都受到了ChatGPT的追捧和冲击,而ChatGPT背后的算法就是transformer。想要更好的使用和了解ChatGPT,那么我们首先应该对它背后的底层方法进行学习和复现。到这里便引出了我们今天要学习的结构:transformer。
- 首先介绍一下transformer的发展史
1.1. 发展史
-
Transformer 架构 于 2017 年 6 月推出。原本研究的重点是翻译任务。随后推出了几个有影响力的模型,包括
-
2018 年 6 月: GPT, 第一个预训练的 Transformer 模型,用于各种 NLP 任务并获得极好的结果
-
2018 年 10 月: BERT, 另一个大型预训练模型,该模型旨在生成更好的句子摘要
-
2019 年 2 月: GPT-2, GPT 的改进(并且更大)版本,由于道德问题没有立即公开发布
-
2019 年 10 月: DistilBERT, BERT 的提炼版本,速度提高 60%,内存减轻 40%,但仍保留 BERT 97% 的性能
-
2019 年 10 月: BART 和 T5, 两个使用与原始 Transformer 模型相同架构的大型预训练模型(第一个这样做)
-
2020 年 5 月: GPT-3, GPT-2 的更大版本,无需微调即可在各种任务上表现良好(称为零样本学习)
-
2022年11月30日,GPT3.5发布,也就是我们所熟知的ChatGPT,可以称之为人工智能历史上的里程碑事件
-
2023年4月3月15日凌晨,ChatGPT 4发布,AI的再次进化,堪称史上能力最强,而且短期内不会被超越。
-
从上面的时间表我们可以看出,NlP模型的研究速度越来越快,我们也得加快自己的学习脚步了,如果现在不进行追赶,可能以后就追赶不上了。
-
其实这个列表并不全面,只是为了突出一些不同类型的 Transformer 模型。大体上,它们可以分为三类:
-
GPT-like (也被称作**自回归 **Transformer 模型)
-
BERT-like (也被称作自动编码 Transformer 模型)
-
BART/T5-like (也被称作序列到序列的 Transformer 模型)
-
Transformer 是大模型,除了一些特例(如 DistilBERT)外,实现更好性能的一般策略是增加模型的大小以及预训练的数据量。其中,GPT-2 是使用「transformer 解码器模块」构建的,而 BERT 则是通过「transformer 编码器」模块构建的。这是两种不同的思路,OpenAI选用的是前者GPT解码模型,而谷歌则把宝压在了后者BERT编码模型上面,从现在的ChatGPT大红大紫上面可以看出,谷歌虽然是大语言模型的提出者,但是却因为当初选择错了道路,所以之前的优势复制东流,
-
万事开头难,那么先从最简单的基本概念开始吧。
2. Transformer 整体结构
-
transformer是由谷歌在同样大名鼎鼎的论文《Attention Is All You Need》提出的,最基础的结构就是先Enoder编码再Decoder解码
-
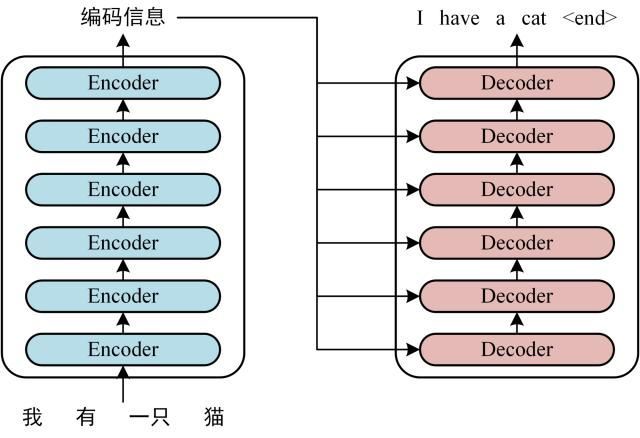
首先介绍 Transformer 的整体结构,下图是 Transformer 用于中英文翻译的整体结构:
-
-
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
-
第一步:获取输入句子的每一个单词的表示向量 X
-
X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
-
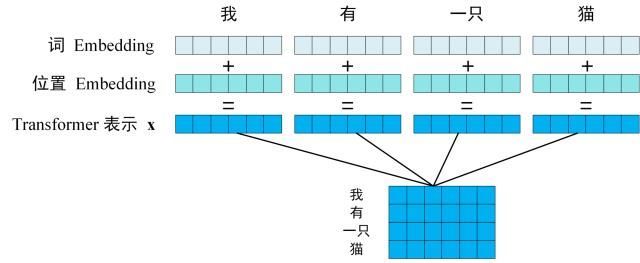
-
从上图可以看到,这个句子中是由单词组成的,每一个字都可以映射为一个内容Embedding以及一个位置Embedding,然后将这个内容Embedding和位置Embedding加起来,就可以得到这个词的综合Embedding了。
-
如上图所示,每一行是一个单词的表示 x
-
第二步:将得到的单词表示向量矩阵 传入 Encoder
-
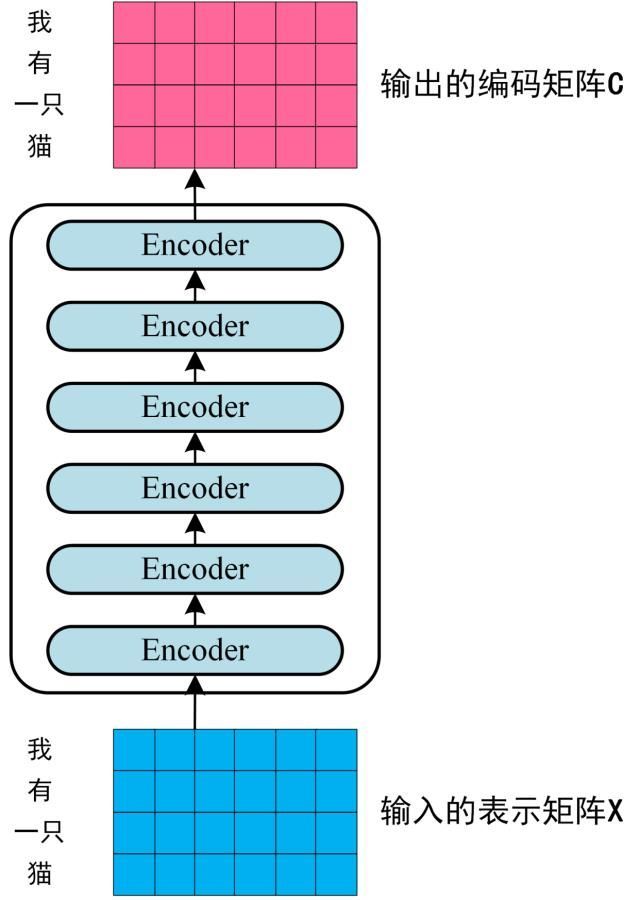
每一行是一个单词的表示 x,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。单词向量矩阵用X_nxd表示,n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入 完全一致。
-
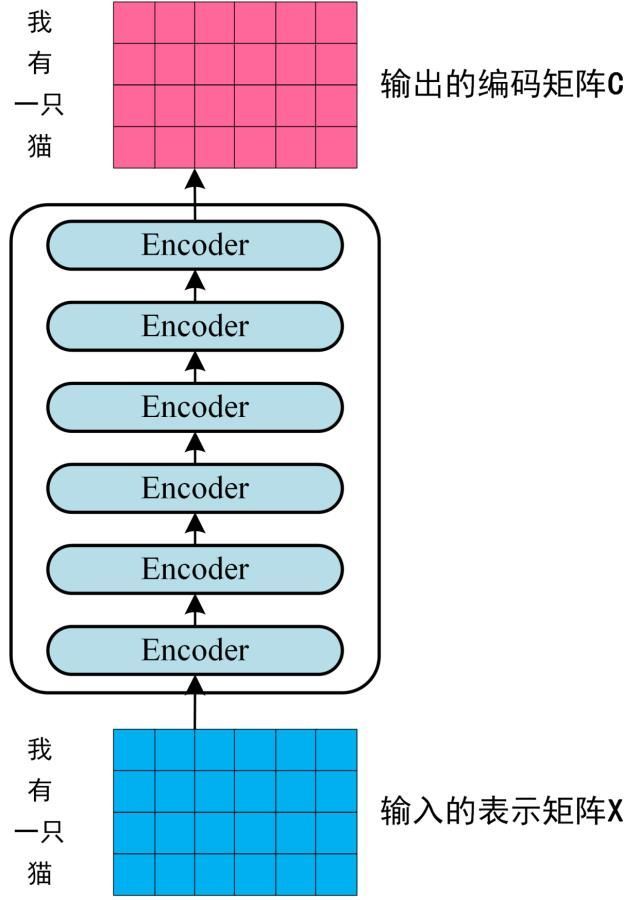
-
第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中
-
Decoder 依次会根据当前已经翻译过的单词 i(I) 翻译下一个单词 i+1(have),如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
-

-
上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 “”,预测第一个单词 “I”;然后输入翻译开始符 “” 和单词 “I”,预测单词 “have”,下一次预测的时候,用之前预测的结果作为输入,再得到对应的输出,以此类推。这是 **Transformer **使用时候的大致流程,无论再复杂的网络都是这个流程。
-
简单来理解的话,就是通过前I-1个词来预测第i个词,之后一直循环反复这个过程,直到预测出来了 结束符 截止。
3. 名词解释
3.1. token
- 在计算机科学中,token(符号)通常指代文本中的一组字符,它们被视为一个独立的单元,在进行文本分析和处理时被视为一个整体。
- 在自然语言处理中,token 通常指代单词、词组或其他文本中独立的语言单元。将文本分解为 token 的过程称为 tokenization(分词),是自然语言处理中的一个重要预处理步骤,为后续的文本分析和处理提供了基础。
- 一般情况下,对于英文来说,有几个单词就可以认为是有几个token
- 例如,对于英文句子 “I love natural language processing”,分词后得到的 token 序列为 [“I”, “love”, “natural”, “language”, “processing”]。
- 中文没有像英文那样明确的单词边界,因此需要对中文文本进行分词才能进行后续的文本分析和处理。
- 例如,对于中文句子 “我喜欢自然语言处理”,分词后得到的 token 序列为 [“我”, “喜欢”, “自然语言”, “处理”]。其中,“自然语言”是一个词组,在分词时被视为一个整体的 token。
- 在接下来的架构分析中, 我们将假设使用Transformer模型架构处理从一种语言文本到另一种语言文本的翻译工作, 因此很多命名方式遵循NLP中的规则. 比如: Embeddding层将称作文本嵌入层, Embedding层产生的张量称为词嵌入张量, 它的最后一维将称作词向量等.
4. transformer输入
- transformer这种网络其实并不能直接理解我们的自然语言,需要先对自然语言进行编码,编码成数字之后才可以大展身手。从这个角度来考虑,ChatGPT之类的模型,虽然神之又神,但其实上它背后进行的是一系列的数字数学运算,并不是真的理解了我们的自然语言。
- Transformer中单词的输入表示X是由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到,通常定义为 Transformer Embedding 层。
4.1. 单词 Embedding
- 单词的Embedding有很多方法可以获取,例如可以采用Word2Vec、Glove等算法预训练得到,也可以在Transformer中训练得到
- 输入:[N, seq_len]
[N,seq_len],即N个句子(batch size),每个句子包含seq_len个token(一般情况下,对于英文来说,有几个单词就可以认为是有几个token),由于每个句子长短不一,选择最长的句子作为base seq_len,剩下余部分可以用特殊字符(例如0、1)来填充,token用其在vocab中的序号表示。
也就是N条句子,以最长句子的长度最为基准,其他句子均进行长度补齐。
例如下面的代码,前面的[2, 2571, 57, 11, 48, 26, 733, 11, 46, 62, 11, 90, 297, 5, 3,]列表代表这个句子中对单词的编码,后面的全1矩阵[1,1,…1,1]就代表向最长句子的padding填充了
for i, batch in enumerate(iterator):
src = batch.src
print(src.shape) 128 ,40
print(src[0])
[ 2, 2571, 57, 11, 48, 26, 733, 11, 46, 62, 11, 90,
297, 5, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1]
- 输出:[N, seq_len, d_model]
d_model表示词向量的维度,它是 Transformer 模型中的一个重要参数。在 Transformer 模型中,输入序列的每个单词都会被转换成一个 d _ m o d e l d\_model d_model 维的向量表示(而非one_hot编码),这个向量表示包含了该单词的语义信息。
假设我们有一个词汇表,其中包含了 10,000 个单词。我们使用 one-hot 编码将每个单词转换成一个长度为 10,000 的向量表示,那么每个单词的向量是一个稀疏向量 ,其中只有一个元素是 1,其余元素都是 0。这种表示方式存在的问题是,向量维度非常高,而且向量之间的距离无法直接反映单词之间的语义关系。
为了解决这个问题,我们可以使用词嵌入将每个单词转换成一个低维稠密向量表示。假设我们使用的词嵌入模型是一个浅层的前馈神经网络,输入是一个 one-hot 向量,输出是一个 4 维的向量表示,那么每个单词的向量表示如下所示:
-
单词 “car”: [ 0.1 0.2 0.3 0.4 ] \begin{bmatrix} 0.1 & 0.2 & 0.3 & 0.4 \end{bmatrix} [0.10.20.30.4]
-
单词 “bus”: [ 0.2 0.3 0.4 0.5 ] \begin{bmatrix} 0.2 & 0.3 & 0.4 & 0.5 \end{bmatrix} [0.20.30.40.5]
-
单词 “train”: [ 0.3 0.4 0.5 0.6 ] \begin{bmatrix} 0.3 & 0.4 & 0.5 & 0.6 \end{bmatrix} [0.30.40.50.6]
在这个例子中, d _ m o d e l = 4 d\_model=4 d_model=4,这意味着每个单词的向量表示只有 4 个元素。这种低维稠密表示方式不仅可以减少向量维度,还可以保留一些单词之间的语义关系,比如 “car” 和 “bus” 的向量在某些维度上比较接近,而和 “train” 的向量比较远。这种语义关系可以帮助模型更好地理解文本数据,从而提高任务的性能。
d _ m o d e l d\_model d_model 的大小通常是根据任务的复杂度和计算资源来决定的。如果任务比较简单,或者计算资源有限,我们可以使用较小的 d _ m o d e l d\_model d_model 值;如果任务比较复杂,或者计算资源充足,我们可以考虑使用较大的 d _ m o d e l d\_model d_model 值。需要注意的是, d _ m o d e l d\_model d_model 的大小对模型的性能和计算效率都会产生影响,因此需要在实践中进行调试和优化。 -
Embdding参数:TokenEmbedding(vocab_size, d_model)。
其中 vocab size表示词典中token独立词汇的数量;
4.2. 位置Embedding
-
Transformer中除了单词的Embedding之外,还需要使用位置Embedding来表示单词在句子中的位置。因为Transformer没有采用RNN的结构,而是使用全局信息,不能利用单词的顺序变化,而这部分信息对于NLP来说是非常重要的。所以在transformer中使用位置Embedding保存单词在序列中的相对或绝对位置。
-
位置 Embedding 用 PE (Position Encoding)表示,PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了公式计算,计算公式如下:
-

-
其中,pos 表示单词在句子中的位置,d 表示 PE的维度 (与词 Embedding 一样),2i 表示偶数的维度,2i+1 表示奇数维度 (即 2i≤d, 2i+1≤d)。
-
这个公式表示在偶数的位置使用 P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d ) P E _ { ( p o s , 2 i ) } = \sin \left( p o s / 10000 ^ { 2 i / d } \right) PE(pos,2i)=sin(pos/100002i/d) 公式进行计算,而在奇数的位置使用 P E ( p o s , 2 i + 1 ) = cos ( p o s / 1000 0 2 i / d ) P E _ { ( p o s , 2 i + 1 ) } = \cos \left( p o s / 10000 ^ { 2 i / d } \right) PE(pos,2i+1)=cos(pos/100002i/d)
-
如下为“我爱你”编码的具体说明
-

-
维度一共是512维,在偶数位置0,2,4,6…使用的sin,在奇数位置1,3,5,7…使用的是cos。
-
使用这种公式计算 PE 有以下的好处:
使 PE 能够适应比训练集里面所有句子更长的句子 -
假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
可以让模型容易地计算出相对位置, -
对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。直接把相对位置转换为简单的三角函数运算了。
4.3. Transformer Embedding层实现
-
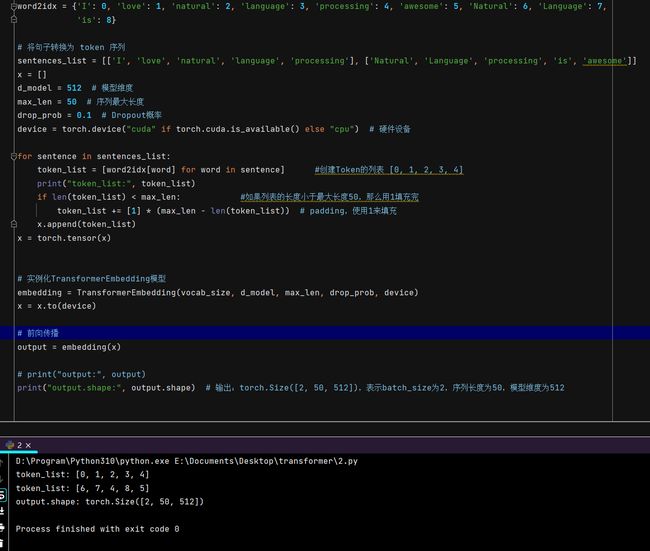
将单词的内容 Embedding 和位置 Embedding 相加,就可以得到单词的表示向量 x,x 就是 Transformer 的输入。
-
输入:[N,seq_len]
-
输出:[N,seq_len,d_model]
-
5. Attention结构
5.1. 简介
-
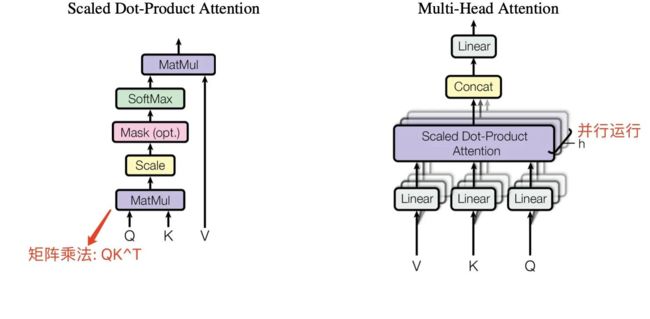
Encoder 和 Decoder 结构中公共的 layer 之一是 Multi-Head Attention多头注意力机制,其是由多个 Self-Attention ^**并行组成**^的。Encoder block 只包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。
-
-
Multi-Head 指的是 Multi-Head Attention 中的多个头,也就是说,Multi-Head Attention 将注意力机制拆分成多个头,每个头都可以关注输入序列的不同部分,并计算出不同的加权和。
-
在 Multi-Head Attention 中,每个头都是一个独立的注意力机制,它们可以关注不同的输入信息,从而提高模型的表征能力和泛化能力。同时,通过拆分头数,我们可以控制模型的计算复杂度,从而在保证模型性能的同时,节约计算资源。
-
具体来说,Multi-Head Attention 的计算过程如下:
-
- 将输入序列通过线性变换,得到 Q , K , V Q,K,V Q,K,V 三个矩阵,分别代表查询矩阵、键矩阵和值矩阵。
-
- 将 Q , K , V Q,K,V Q,K,V 矩阵分别拆成 h h h** 个头**,每个头的维度为 d m o d e l / h d_{model}/h dmodel/h。
h是一个超参数,表示 Multi-Head Attention 中头的数量。在实际使用中,通常使用 8 或 16 个头,这是经验性的选择。
h的选择会影响模型的计算复杂度和表征能力。较大的 h 可以提高模型的表征能力,但同时也会增加模型的计算复杂度,导致训练和推理的时间增加。因此,在选择 h h h 的时候需要综合考虑模型的性能和计算资源的限制。
- 将 Q , K , V Q,K,V Q,K,V 矩阵分别拆成 h h h** 个头**,每个头的维度为 d m o d e l / h d_{model}/h dmodel/h。
-
- 对每个头进行注意力计算,得到 h h h 个加权和矩阵。
-
- 将 h h h 个加权和矩阵拼接起来,通过线性变换得到最终的输出矩阵。
-
在这个计算过程中,每个头都计算了一组注意力权重,并将这些权重应用于输入序列中的不同部分,从而得到不同的加权和表示。最后,通过将所有头的加权和表示拼接起来,我们可以得到一个更全面、更准确的输入序列表示。
5.2. Self Attention(自注意力机制)
5.2.1. 简介
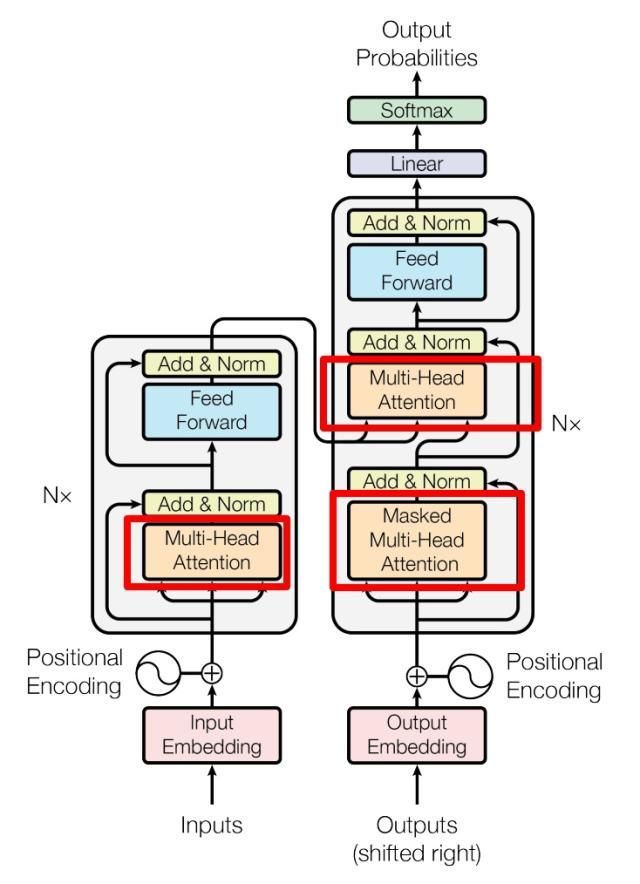
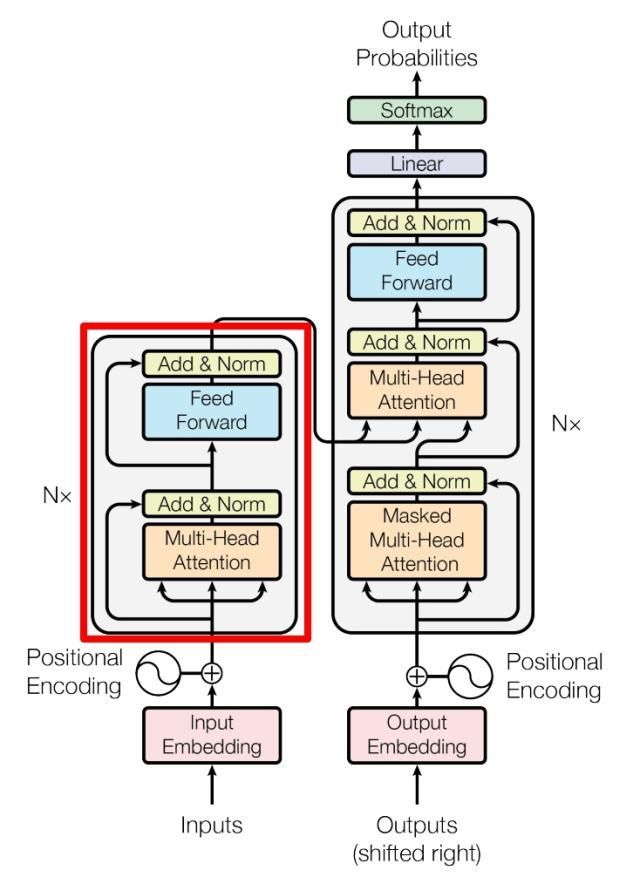
上图是论文中 Transformer 的内部结构图,左侧为 Encoder block,右侧为 Decoder block。红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,
可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。
Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
因为 Self-Attention是 Transformer 的重点,所以我们重点关注 Multi-Head Attention 以及 Self-Attention,首先详细了解一下 Self-Attention 的内部逻辑。
5.2.2. Self Attention结构
Self-Attention 中文翻译为自注意力机制,论文中叫作 Scale Dot Product Attention,它是 整个Transformer 架构的^**核心**^,其结构如下图所示
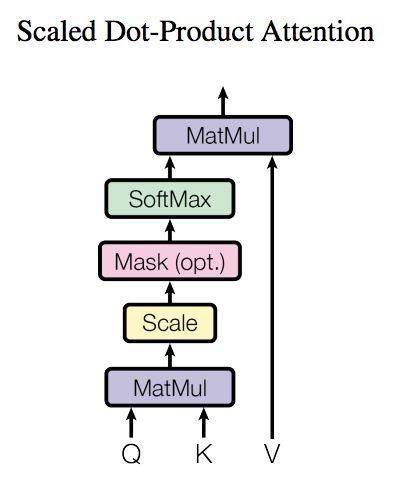
在计算的时候需要用到查询矩阵Q,键矩阵K,值矩阵V,
5.2.3. Q, K, V 的作用
- 假设我们有一个长度为 n n n 的句子,其中每个单词用一个长度为 d d d 的向量表示。我们将这个句子的向量表示组织成一个矩阵 X ∈ R n × d X \in \mathbb{R}^{n \times d} X∈Rn×d,每行表示一个单词的向量表示。
- 现在我们想要计算句子中每个单词与其他单词的相似度得分,从而得到一个关注句子中每个单词的权重分布。为了实现这个目标,我们可以使用自注意力机制,其中矩阵 Q Q Q、 K K K 和 V V V 的作用分别如下:
- 查询矩阵 Q Q Q:用于表示句子中每个单词的查询向量。具体来说, Q Q Q 的第 i i i 行表示句子中第 i i i 个单词的查询向量,它将被用于计算句子中其他单词与第 i i i 个单词的相似度得分。
- 键矩阵 K K K:用于表示句子中每个单词的键向量。具体来说, K K K 的第 i i i 行表示句子中第 i i i 个单词的键向量,它将被用于计算句子中第 i i i 个单词与其他单词的相似度得分。
- 值矩阵 V V V:用于表示句子中每个单词的值向量。具体来说, V V V 的第 i i i 行表示句子中第 i i i 个单词的值向量,它将被用于计算句子中其他单词对第 i i i 个单词的贡献。
- 我们可以通过将 X X X 乘以三个参数矩阵 W q W_q Wq、 W k W_k Wk 和 W v W_v Wv 得到 Q Q Q、 K K K 和 V V V:
- Q = X W q , K = X W k , V = X W v Q = XW_q, \quad K = XW_k, \quad V = XW_v Q=XWq,K=XWk,V=XWv
- 其中 W q , W k , W v ∈ R d × d W_q, W_k, W_v \in \mathbb{R}^{d \times d} Wq,Wk,Wv∈Rd×d 是要学习的参数矩阵。
- 接下来,我们可以计算注意力得分 S S S:
- S = Q K T d S = \frac{QK^T}{\sqrt{d}} S=dQKT
- 其中 S i , j S_{i,j} Si,j 表示第 i i i 个单词与第 j j j 个单词的相似度得分。注意力得分越大,表示两个单词之间的关联越紧密。
- 接着,我们可以对 S S S 进行 softmax 归一化,得到关注句子中每个单词的权重分布 A A A:
- A i , j = exp ( S i , j ) ∑ k = 1 n exp ( S i , k ) A_{i,j} = \frac{\exp(S_{i,j})}{\sum_{k=1}^n \exp(S_{i,k})} Ai,j=∑k=1nexp(Si,k)exp(Si,j)
- 其中 A i , j A_{i,j} Ai,j 表示第 i i i 个单词对第 j j j 个单词的权重。注意力机制将句子中每个单词的权重分布编码成一个矩阵 A A A。
- 最后,我们将权重矩阵 A A A 与值矩阵 V V V 做加权和,得到句子的编码向量 Y Y Y:
- Y = A V Y = AV Y=AV
- 其中 Y i Y_i Yi 表示句子中第 i i i 个单词的编码向量。注意力机制将句子中每个单词的向量表示编码成一个句子的向量表示。这个句子的向量表示可以用于下游任务,比如文本分类、序列标注等。
其中 d k d_k dk 和 d v d_v dv 分别表示查询矩阵和值矩阵的向量维度,通常情况下 d k = d v d_k = d_v dk=dv。这样,我们就可以得到矩阵 Q、K 和 V,然后用它们来计算自注意力机制的输出。
在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行矩阵线性变换得到的。

- Q, K, V 的计算
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示,^^注意 X, Q, K, V 的^^^**每一行**^^都表示一个单词^。有几个单词矩阵就会有几行,Q、K、V和X的数学区别仅仅在于发生了不同线性映射,其中Wq, Wk, Wv是我们模型训练过程学习到的合适的参数。

接着,通过QKV,可以得到一个score z,用于后续输出,具体见下一节。
5.2.4. Self-Attention 的输出
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下:

公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以 d k d_k dk的平方根。Q乘以K的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为Q乘以 K T K^T KT ,1234 表示的是句子中的单词。
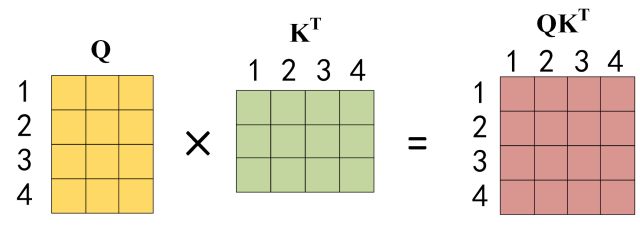
得到 Q K T QK^T QKT 之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax和归一化,即每一行的数都变为了小数,其行和恒为 1。
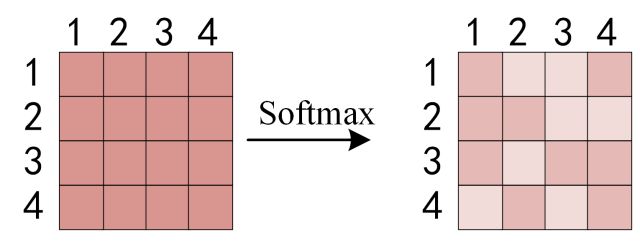
得到 Softmax 矩阵之后可以和V相乘,得到最终的输出Z。
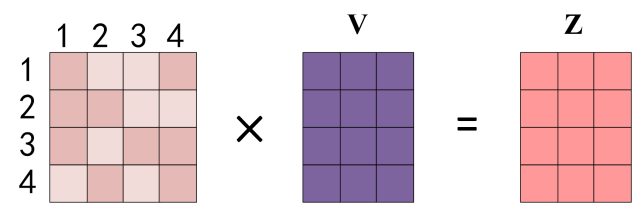
上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出 Z 1 Z_1 Z1,等于所有单词 i 的值 V i V_i Vi 根据 attention 系数的比例加在一起得到,如下图所示:

5.3. Multi-Head Attention
-
在上一步,我们已经知道怎么通过 Self-Attention 计算得到输出矩阵 Z,而 Multi-Head Attention 是由多个 Self-Attention 组合形成的,下图是论文中 Multi-Head Attention 的结构图。
-
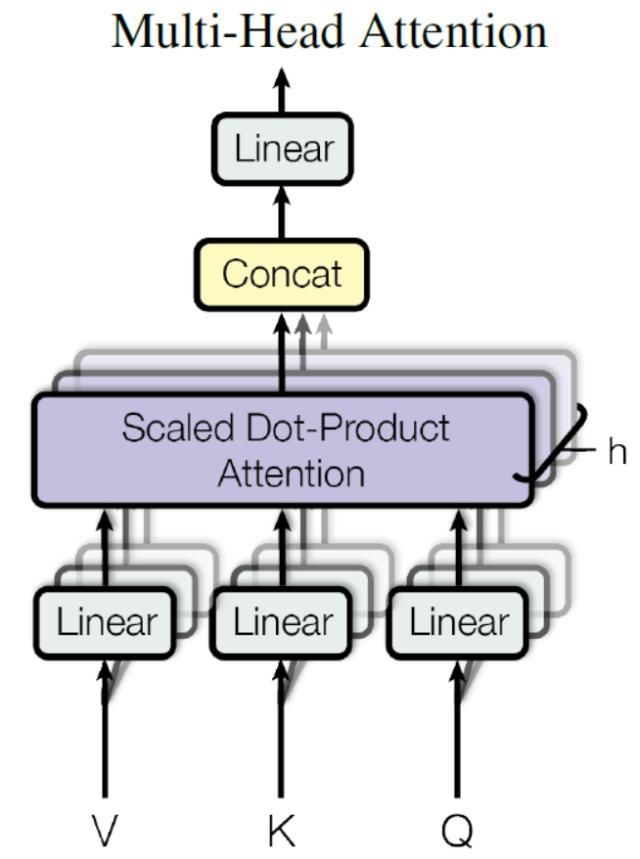
-
从上图可以看到 Multi-Head Attention 包含多个 Self-Attention 层,也就是并行使用了多个注意力机制,首先将输入X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵Z。下图是 h=8 时候的情况,此时会得到 8 个输出矩阵Z。
-
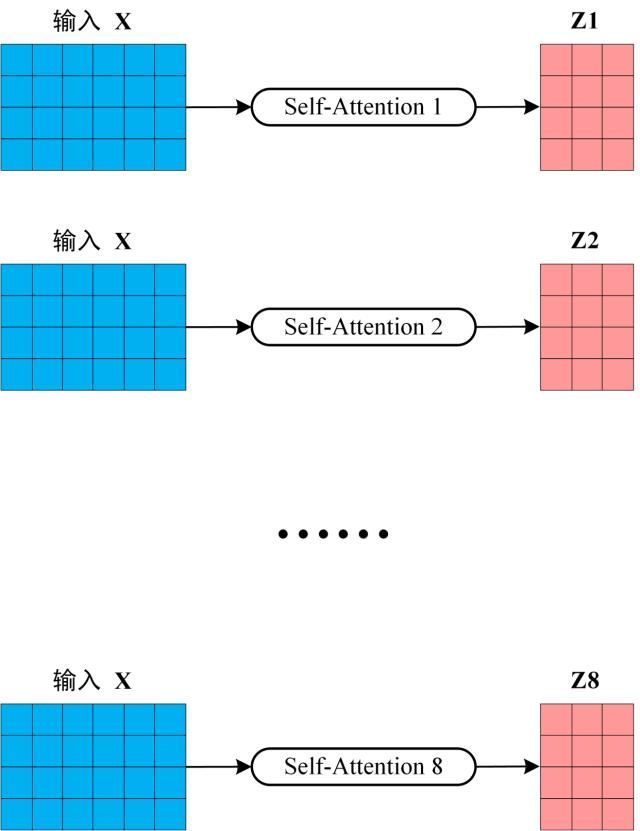
-
得到8个输出矩阵Z1到Z8之后,Multi-Head Attention将它们拼接在一起(Concat),然后传入一个Linear层,得到Multi-Head Attention最终的输出Z。
-
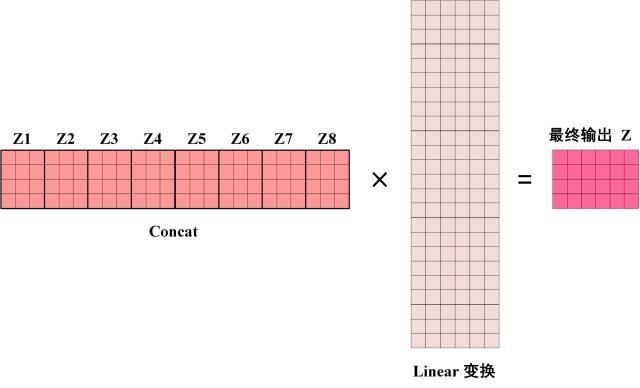
-
可以看到 Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的,仅仅是其内部的权重发生了改变。
-
在实际操作中,其实是使用了多个Attention,比如下面用了两套注意力机制,作者在论文中简单的说,这么做的效果比较好,大家猜测可能是因为使用多个助力机制,可以把不同的信息映射到不同的空间,从而进行比较
-

6. Encoder结构
6.1. 简介
-
-
上图红色部分是 Transformer 的 Encoder block 结构,可以看到是由 Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm 组成的。刚刚已经了解了 Multi-Head Attention 的计算过程,现在了解一下 Add & Norm 和 Feed Forward 部分。
6.2. Add & Norm
-
Add & Norm 层由 Add 和 Norm 两部分组成,先Add相加,再进行Norm归一化,其整体的计算公式如下:
-

-
其中 X表示 Multi-Head Attention 或者 Feed Forward 的输入,MultiHeadAttention(X) 和 FeedForward(X) 表示输出 (输出与输入 X 维度是一样的,所以可以相加)。
-
Add指 X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到,现在基本上已经成为了深层网络的标配:
-

-
Norm指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
6.3. Feed Forward
-
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下:
-

-
X是输入,Feed Forward 最终得到的输出矩阵的维度与X一致。
6.4. Encoder结构实现
-
通过上面描述的 Multi-Head Attention, Feed Forward, Add & Norm 就可以构造出一个 Encoder block,Encoder block 接收输入矩阵 X ( n × d ) X _ { ( n \times d ) } X(n×d),并输出一个矩阵 O ( n × d ) O _ { ( n \times d ) } O(n×d) 。通过多个 Encoder block 叠加就可以组成 Encoder。
-
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是编码信息矩阵 C,这一矩阵后续会用到 Decoder 中。
-
7. Decoder结构
7.1. 简介
-
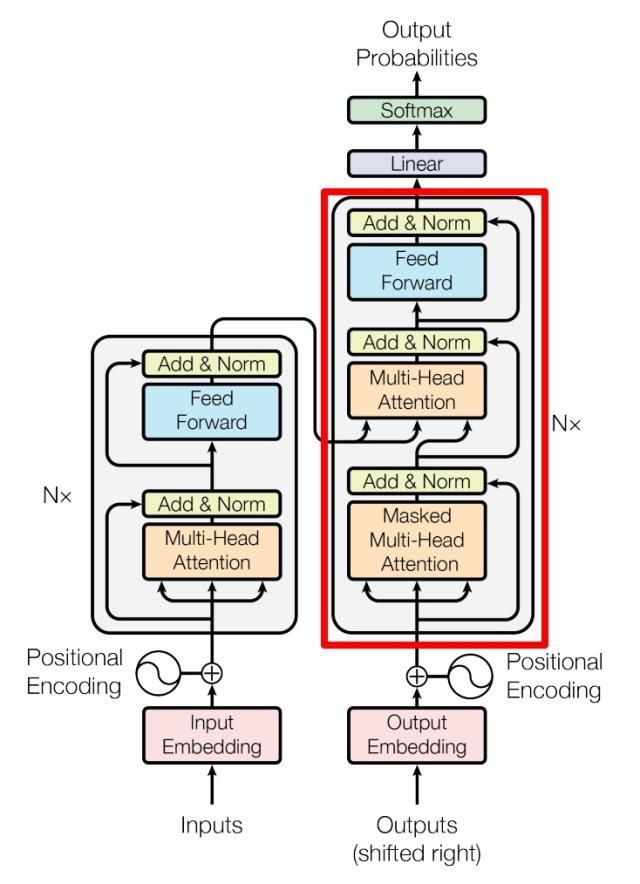
-
上图红色部分为 Transformer 的 Decoder block 结构,与 Encoder block 相似,但是存在一些区别:
-
包含两个 Multi-Head Attention 层。
-
第一个 Multi-Head Attention 层采用了 **Masked **操作。
-
第二个 Multi-Head Attention 层的K、V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
-
最后有一个 Softmax 层计算下一个翻译单词的概率。
-
注意,Deocder块中的第一个注意力层关联到Decoder的所有(过去的)输入,但是第二注意力层使用E的输出。因此,它可以访问整个输入句子,以最好地预测当前单词。这是非常有用的,因为不同的语言可以有语法规则将单词按不同的顺序排列,或者句子后面提供的一些上下文可能有助于确定给定单词的最佳翻译。
-
具体可以查看。李红毅老师讲的课程36分钟处
-
Transformer - YouTube
7.2. 第一个Multi-Head Attention
-
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。下面以 “我有一只猫” 翻译成 “I have a cat” 为例,了解一下 Masked 操作。
-
下面的描述中使用了类似 [Teacher Forcing](…/…/…/…/…/…/深度学习/不同类型的深度学习/NLP/概念/Teacher Forcing.md) 的概念,[Teacher Forcing 是一种训练生成模型(如语言模型、机器翻译模型等)的方法,其核心思想是在训练时,将真实的目标序列作为输入传递给模型,而不是使用模型自己生成的序列。](…/…/…/…/…/…/深度学习/不同类型的深度学习/NLP/概念/Teacher Forcing/简介/Teacher Forcing 是一种训练生成模型(如语言模型、机器翻译模型等)的方法,其核心思想是在训练时,将真实的目标序列作为输入传递给模型,而不是使用模型自己生成的序列。.md)
-
在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 “” 预测出第一个单词为 “I”,然后根据输入 “ I” 预测下一个单词 “have”。
-

-
Decoder 可以在训练的过程中使用 Teacher Forcing 并且并行化训练,即将正确的单词序列 ( I have a cat) 和对应输出 (I have a cat ) 传递到 Decoder。那么在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住,注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用 0 1 2 3 4 5 分别表示 “ I have a cat ”。
-
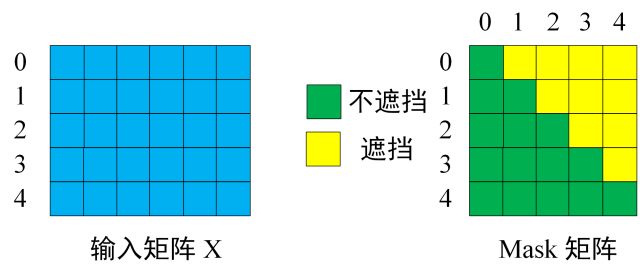
第一步:是 Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 “ I have a cat” (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask中 可以发现第一行单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。
-
-
第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵X计算得到Q,K,V矩阵。然后计算Q和 K T K ^ { T } KT 的乘积 Q K T Q K ^ { T } QKT 。
-

-
第三步:在得到 Q K T Q K ^ { T } QKT 之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
-
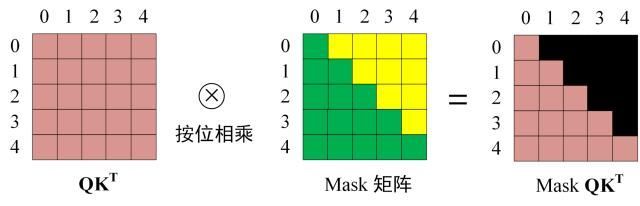
-
得到 Mask Q K T Q K ^ { T } QKT 之后在 Mask Q K T Q K ^ { T } QKT 上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。
-
第四步:使用 Mask Q K T Q K ^ { T } QKT 与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量 Z 1 Z _ { 1 } Z1 是只包含单词 1 信息的。
-
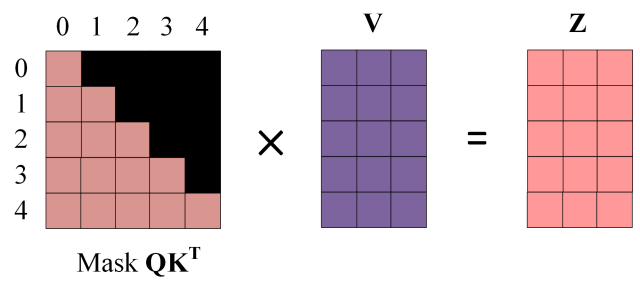
-
第五步:通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵 Z i Z _ { i } Zi ,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出 Z i Z _ { i } Zi 然后计算得到第一个 Multi-Head Attention 的输出Z,Z与输入X维度一样。
7.3. 第二个 Multi-Head Attention
-
Decoder block 第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
-
根据 Encoder 的输出 C计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致。
-
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
7.4. Softmax 预测输出单词
-
Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词 0 的输出 Z0 只包含单词 0 的信息,如下:
-
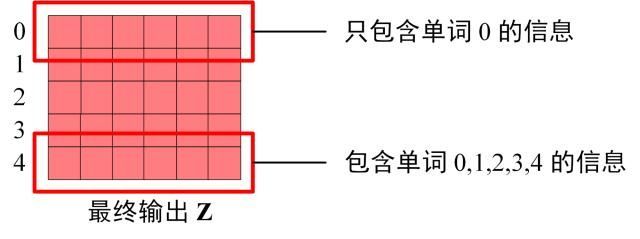
-
Softmax 根据输出矩阵的每一行预测下一个单词:
-
-
这就是 Decoder block 的定义,与 Encoder 一样,Decoder 是由多个 Decoder block 组合而成。
8. 总结
-
模型的输入是[N,seq_len],
-
Transformer 与 RNN 不同,可以比较好地并行训练。
-
Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
-
Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
-
Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。
到这里,这个transformer的基本知识我们就介绍完了。从下一篇博客开始,我们就可以进行代码实战了。
9. 参考资料
- Transformer模型详解(图解最完整版) - 知乎
- Transformer模型详解及代码实现 - 掘金
- Transformer详解及代码实现 - 知乎
- 121.199.45.168:8001/2/
- 2.位置编码详细解读_哔哩哔哩_bilibili
- github.com/DA southampton/NLP ability
om/p/338817680) - Transformer模型详解及代码实现 - 掘金
- Transformer详解及代码实现 - 知乎
- 121.199.45.168:8001/2/
- 2.位置编码详细解读_哔哩哔哩_bilibili
- github.com/DA southampton/NLP ability