爬虫-关于豆瓣top250的数据可视化
目的:该文章的目的是对豆瓣TOP250网页的爬虫就行可视化分析。
- 明确目标,导入所需库
- 使用flask库建立网络框架
- 完成每个网页的内容
豆瓣电影评分top250:豆瓣电影 Top 250 (douban.com)
因为是小组合作,数据库的生成由另一名小组成员完成,我直接将他爬取下来生成的数据库复制到我的项目中
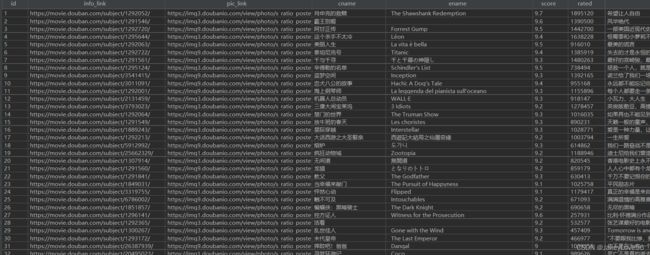
然后在网页找到免费的网页模板,例如模版王等网站.
我找的是这样一个模板
然后在开发者模式将整个网站的内容复制下来,在pc中创造一个index.html 文件,将代码复制到其中去。
![]()
然后我们需要创造一个app.py文件,对index网络进行响应
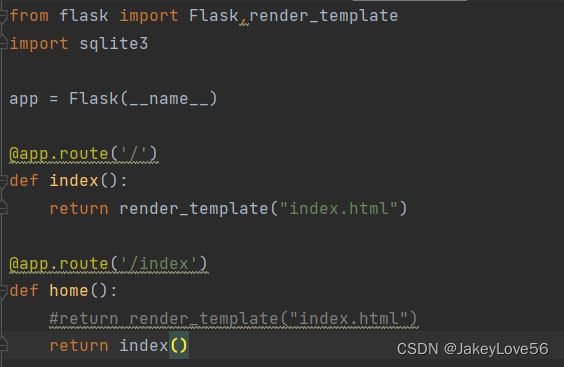
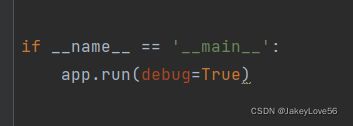
值得注意的是使用debug=true 是为了及时更新网页的内容,在pc修改后,在网页中刷新一下就可以看到你更新的内容,及时处理错误
进入后发现只有文字内容没有图片内容和动态效果,是因为没有下css文件。我们需要找到我们的模板网页把他下下来
![]()
然后就是对主页进行修改,我们需要将数据库展现出来,评分的分布,进行词频统计,最后介绍我和我的团队成员.
![]()
第一页数展现数据库,我们用循环的方法将数据库内容一条条罗列出来代码如下:
@app.route('/movie')
def movie():
datalist = []
con = sqlite3.connect("movie.db")
cur = con.cursor()
sql = "select * from movie250"
data = cur.execute(sql)
for item in data:
datalist.append(item)
cur.close()
con.close()
print(datalist)
return render_template("movie.html",movies = datalist)
效果图
第二页我们进行评分统计,这里要用到echart,在网页中搜索

这里各种各样的图,我们需要的是评分统计,所以使用柱状图
明确我们的横纵坐标的数据,使用sql语句在数据寻找分数和统计分数段的电影数量
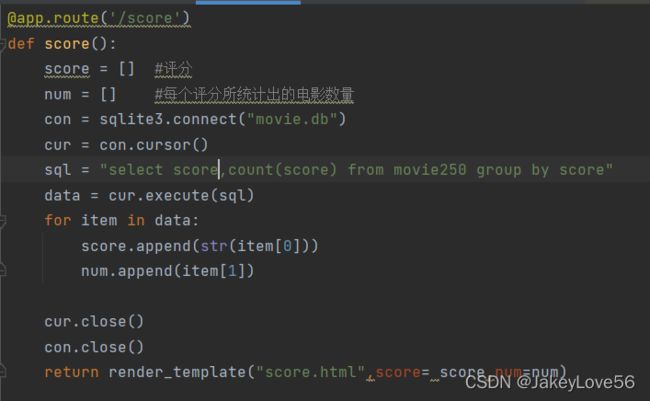
然后对echart柱状图模板进行修改
这是运行效果
”

然后制作词频统计网页,这里我们要使用词云

上面是所需要的的库和其功能
这里我们需要使用停用词,把 你我他 和之类词语删掉。
exclude =("我们","你的","他们","它们","的","不是","是","的","你","我","它","他","和","她","没有","就是","了","都","就","人","与","在",
"被","有","不","最")
还有要设置支持中文的字体
font_path="msyh.ttc",
其他内容不做过多阐述效果图如下


最后加上我和我的团队成员嘿嘿嘿
以上就是我的可视化内容分析感谢观看!!!!