算法 | 分块查找
算法 | 分块查找
1. 简介
分块查找也称为索引顺序表查找。分块查找就是将顺序表(主表)分成若干个子表,然后为每个子表建立一个索引表,利用索引在其中一个子表中查找。
两部分:
- 索引表:存储顺序表的每个子表的开始索引和最大值。
- 顺序表:主表所有数据存放的位置。
1.1. 条件
- 子表内可以是无序的,但是子表之前面的子表中每个元素必须小于后面子表中的每个元素。
1.2. 分块
纯个人的一些理解,欢迎一起沟通交流
1.2.1. 前言
我第一次看分块查找时也十分纠结应该怎么分块每个子表数据应该多长,什么时候用分块查找,怎么将一个无序的数据转换成索引表和顺序表来执行分块查找,在百度查了下分块查找怎么分块也没有找到说明。
1.2.2. 我的理解
后面我仔细想了了下,认为“程序=数据结构+算法”其中数据结构和算法是有先后关系的,我们要先确定我们的数据结构才能确定我们将使用何种算法。我们不应该先挑选算法,然后刻意的让我们的数据结构去适应算法(例:比如我们需要维护一个增长的无序的数组,会不段有新数据来,这时我们如果提前决定使用二分查找那样的话我们就必须每添加一个数据,都要查找这个数据应该存放的位置以保证数组顺序,这样的话我们每来一个数据,查找该数据存放的位置都是很大的性能消耗。)
那应该在何时使用分块查找呢,应该是数据本身具有块的属性,意思是不用我们主动分块数据本身就带块的信息时使用分块查找。
例1:
假设身份证号码的规则是XX(省或直辖市代号)+XXX增长的ID(不考虑3位不够用),北京代号为:01,上海代号为:02,广东省代号为:03…
那么里面具体的人的身份证号就应该是01001、01002、02001、02002、03001、03002…
这时候我们需要在内存里面维护一个动态的数组,我们就可以按照北京大于等于1000小于2000、上海大于等于2000小于3000等进行分块,不需要我们主动通过算法遍历分块应该通过发现数据其他特点进行分块,同时我们也不会纠结到底分多少块。
2022-03-27 16:37:30 添加内容
之前的我对分块理解可以总结为被动分块,过于依赖数据原有的块属性。随着最近学习一些其他方面的知道,认为分块不应该只局限于一个查找算法,理论上所有性能问题都能用分块思想去解决,如:Redis服务器内存不够用了,这时我们可以将一个Redis服务器中的数据拆分(或叫分块)成二个Redis服务器这时我们不紧是拥有了双倍的内存,还拥有了双倍的性能,如果现实还有需要我们还可以增加3个或更多,将每个Redis服务器理解为分块查找中的每一个区间块。
下面就来讲一如果数据本身并没有块属性,我们该如何分块?
我们可以通过对特定字段做HASH,在通过将特定规则将HASH值与某一块数据区进行绑定,使每次需要对该数据进行操作,都可以直接通过相同规则能直接找到该数据区块。更详细的请看负载均衡策略当中第4节HASH的内容。
2. 图示
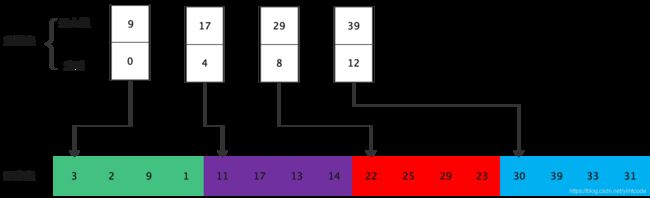
3. 演示
3.1. Go版本
3.1.1. 文件树形图
blocksearch
├── block_search.go
├── block_search_test.go
└── go.mod
3.1.2. 代码
block_search.go
package blocksearch
const blockSize = 4
type Index struct {
MaxValue int
StartIndex int
}
// 索引表
type IndexTable []Index
// 顺序表
type OrderTable []int
func BlockSearch(dest int, indexTable IndexTable, orderTable OrderTable) int {
for _, indexTableItem := range indexTable {
if dest > indexTableItem.MaxValue {
continue
}
for index := indexTableItem.StartIndex; index < blockSize+indexTableItem.StartIndex; index++ {
if dest == orderTable[index] {
return index
}
}
break
}
return -1
}
block_search_test.go
package blocksearch
import "testing"
func TestBlockSearch(t *testing.T) {
indexTable := []Index{
{
9,
0,
},
{
17,
4,
},
{
29,
8,
},
{
39,
12,
},
}
orderTable := []int{
3, 2, 9, 1,
11, 17, 13, 14,
22, 25, 29, 23,
30, 39, 33, 31,
}
dest := -11
index := BlockSearch(dest, indexTable, orderTable)
t.Logf("index:%d dest:%d", index, dest)
if index != -1 && dest != orderTable[index] {
t.Fatalf("%d测试失败\n", dest)
} else {
t.Logf("%d测试成功\n", dest)
}
dest = 13
index = BlockSearch(dest, indexTable, orderTable)
t.Logf("index:%d dest:%d", index, dest)
if index != -1 && dest != orderTable[index] {
t.Fatalf("%d测试失败\n", dest)
} else {
t.Logf("%d测试成功\n", dest)
}
}
3.1.3. 测试结果
=== RUN TestBlockSearch
TestBlockSearch: block_search_test.go:33: index:-1 dest:-11
TestBlockSearch: block_search_test.go:37: -11测试成功
TestBlockSearch: block_search_test.go:42: index:6 dest:13
TestBlockSearch: block_search_test.go:46: 13测试成功
--- PASS: TestBlockSearch (0.00s)
PASS
4. 特殊情况
4.1. 简介
上面的块前提条件是顺序表每个子表长度都是一致情况下,但正常情况还有可能出来顺序不一致情况,这时我们在索引表中就需要记录当前块的长度。
4.2. 图示
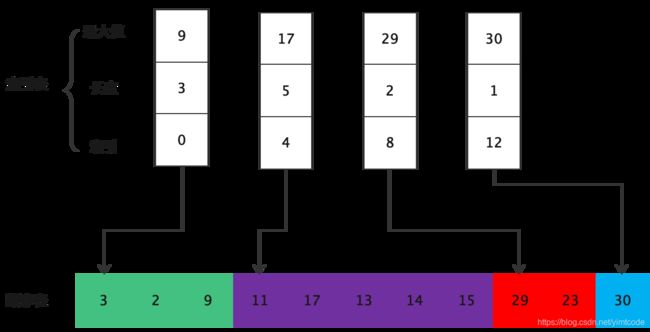
4.3. 特殊情况演示
4.3.1. Go版本
4.3.1.1. 文件树形图
blocksearch
├── block_search.go
├── block_search_test.go
└── go.mod
4.3.1.2. 代码
block_search.go
package blocksearch
type Index struct {
MaxValue int
StartIndex int
Length int
}
// 索引表
type IndexTable []Index
// 顺序表
type OrderTable []int
func BlockSearch(dest int, indexTable IndexTable, orderTable OrderTable) int {
for _, indexTableItem := range indexTable {
if dest > indexTableItem.MaxValue {
continue
}
for index := indexTableItem.StartIndex; index < indexTableItem.Length+indexTableItem.StartIndex; index++ {
if dest == orderTable[index] {
return index
}
}
break
}
return -1
}
block_search_test.go
package blocksearch
import "testing"
func TestBlockSearch(t *testing.T) {
indexTable := []Index{
{
9,
0,
3,
},
{
17,
3,
5,
},
{
29,
8,
2,
},
{
39,
10,
1,
},
}
orderTable := []int{
3, 2, 9,
11, 17, 13, 14, 15,
29, 23,
30,
}
dest := 30
index := BlockSearch(dest, indexTable, orderTable)
t.Logf("index:%d dest:%d", index, dest)
if index != -1 && dest != orderTable[index] {
t.Fatalf("%d测试失败\n", dest)
} else {
t.Logf("%d测试成功\n", dest)
}
dest = 13
index = BlockSearch(dest, indexTable, orderTable)
t.Logf("index:%d dest:%d", index, dest)
if index != -1 && dest != orderTable[index] {
t.Fatalf("%d测试失败\n", dest)
} else {
t.Logf("%d测试成功\n", dest)
}
}
4.3.1.3. 结果
=== RUN TestBlockSearch
TestBlockSearch: block_search_test.go:37: index:10 dest:30
TestBlockSearch: block_search_test.go:41: 30测试成功
TestBlockSearch: block_search_test.go:46: index:5 dest:13
TestBlockSearch: block_search_test.go:50: 13测试成功
--- PASS: TestBlockSearch (0.00s)
PASS
5. 参考
- 《C/C++函数与算法速查手册》