探秘最新Linux内核中的自旋锁
一、前言
目前最新内核中的自旋锁已经进化成queued spinlock,因此需要一篇新的自旋锁文档来跟上时代。此外,本文将不再描述基本的API和应用场景,主要的篇幅将集中在具体的自旋锁实现上。顺便说一句,同时准备一份linux5.10源码是打开本文的正确方式。如果不想下载源代码,这个网址https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/?h=v5.10.123可以浏览自旋锁的源代码。
由于自旋锁可以在各种上下文中使用,因此本文中的thread是执行线索的意思,表示进程上下文、hardirq上下文、softirq上下文等多种执行线索,而不是调度器中线程的意思。
二、简介
Spinlock是linux内核中常用的一种互斥锁机制,和mutex不同,当无法持锁进入临界区的时候,当前执行线索不会阻塞,而是不断的自旋等待该锁释放。正因为如此,自旋锁也是可以用在中断上下文的。也正是因为自旋,临界区的代码要求尽量的精简,否则在高竞争场景下会浪费宝贵的CPU资源。
1、代码结构
我们整理spinlock的代码结构如下:
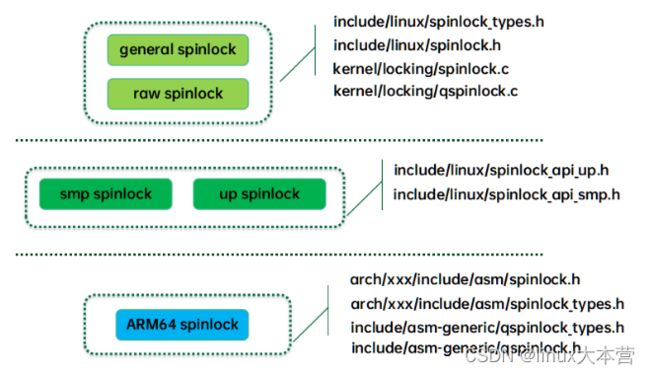
最上层是通用自旋锁代码(体系结构无关,平台无关),这一层的代码提供了两种接口:spinlock接口和raw spinlock接口。在没有配置PREEMPT_RT情况下,spinlock接口和raw spinlock接口是一毛一样的,但是如果配置了PREEMPT_RT,spinlock接口走rt spinlock,底层是基于rtmutex的。也就是说这时候的spinlock不再禁止抢占,不再自旋等待,而是使用了支持PI的睡眠锁来实现,因此有了更好的实时性。而raw spinlock接口即便在配置了PREEMPT_RT下仍然保持传统自旋锁特性。
中间一层是区分SMP和UP的,在SMP和UP上,自旋锁的实现是不一样的。对于UP,自旋没有意义,因此spinlock的上锁和放锁操作退化为preempt disable和enable。SMP平台上,除了抢占操作之外还有正常自旋锁的逻辑,具体如何实现自旋锁逻辑是和底层的CPU architecture相关的,后面我们会详细描述。
最底层的代码是体系结构相关的代码,ARM64上,目前采用是qspinlock。和体系结构无关的Qspinlock代码抽象在qspinlock.c文件中,也就是本文重点要描述的内容。
2、接口API
一个示例性的接口API流程如下(左边是UP,右边是SMP):
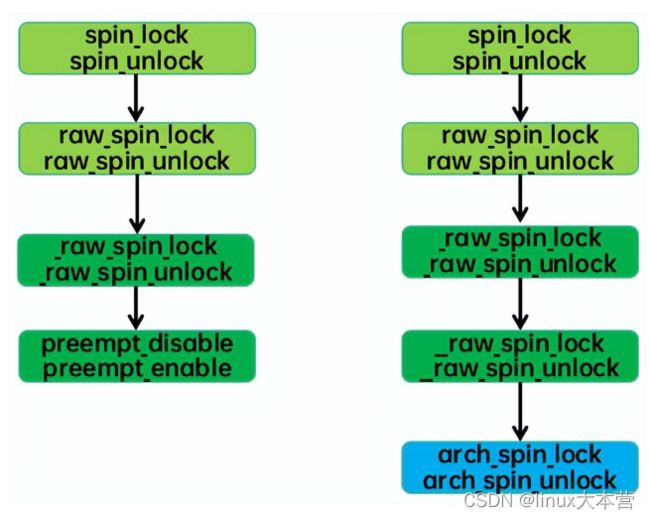
具体的接口API简单而直观,这里就不再罗列了。
3、自旋锁的演进
自旋锁的演进过程如下:

最早的自旋锁是TAS(test and set)自旋锁,即通过原子指令来修改自旋锁的状态(locked、unlocked)。这种锁存在不公平的现象,具体原因如下图所示:

如果thread4当前持锁,同一个cluster中的cpu7上的thread7和另外一个cluster中的thread0都在自旋等待锁的释放。当thread4释放锁的时候,由于cpu7和cpu4的拓扑距离更近,thread7会有更高概率可以抢到自旋锁,从而产生了不公平现象。
为了解决这个问题,内核工程师又开发了ticket base的自旋锁,但是这种自旋锁在持锁失败的时候会对自旋锁状态数据next成员进行++操作,当CPU数据巨大并且竞争激烈的时候,自旋锁状态数据对应的cacheline会在不同cpu上跳来跳去,从而对性能产生影响,为了解决这个问题,qspinlock产生了,下面的文章会集中在qspinlock的原理和实现上。
相关视频推荐
高并发场景下,三种锁方案:互斥锁,自旋锁,原子操作的优缺点
自旋锁、互斥锁、信号量、原子操作、条件变量在不同开源框架的应用
学习地址:C/C++Linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908(资料包括C/C++,Linux,golang技术,内核,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg,大厂面试题 等)

三、Qspinlock的数据结构
1、Qspinlock
struct qspinlock定义如下(little endian):

Qspinlock的数据结构一共4个byte,不同的场景下,为了操作方便,我们可以从不同的视角来看这四个字节,示意图如下:

Tail成员占2B,包括tail index(16~17)和tail cpu(18~31)两个域。补充说明一下,上图是系统CPU的个数小于16k的时候的布局,如果CPU数据太大,tail需要扩展,压缩pending域的空间。这时候pending域占一个bit,其他的7个bit用于tail。之所以定义的如此复杂主要是为了操作方便,有时候我们需要对整个4B的spinlock val进行操作(例如判断空锁需要直接判断val是否为0值),有时候需要对pending+locked这两个byte进行操作(例如mcs node queue head需要自旋在pending+locked上),而有的时候又需要单独对pending或者locked进行设置,大家可以结合代码体会owner的良苦用心。
抛开这些复杂的union数据成员,实际上spinlock的4B由下面三个域组成:

2、MCS lock
MCS lock定义如下:

为了解决多个thread对spinlock的读写造成的cache bouncing问题,我们引入了per cpu的mcs lock,让thread自旋在各自CPU的mcs lock,从而减少了缓存颠簸问题,提升了性能。由于自旋锁可能是嵌套的,因此mcs lock节点在每个CPU上是多个,具体如下图所示:

在某个线程上下文,由于持A锁失败而进入自旋,我们需要把该CPU上的mcs锁节点挂入A spinlock的队列。在这个自旋过程中,该CPU有可能发生软中断,在软中断处理函数中,我们试图持B锁,如果失败,那么该cpu上的mcs锁节点需要挂入B spinlock的队列。在这样的场景中,我们必须区分线程上下文和软中断上下文的mcs node。这样复杂的嵌套最多有四层:线程上下文、软中断上下文、硬中断上下文和NMI上下文。因此我们每个CPU实际上定义了多个mcs node节点(目前是四个),用来解决自旋锁的嵌套问题。
了解了上面的内容之后,我们可以回头看看tail成员。这个成员分成两个部分,一个是cpu id加一(0表示队列无节点),一个就是context index。这两部分合起来可以确定一个mcs node对象。
四、Qspinlock的原理
1、Qspinlock状态说明
通过上面对qspinlock数据结构的说明我们可以知道,spinlock的状态由locked、pending和tail三元组来表示。下面就是几种状态示例:

需要说明的是tail block中的“n”和“*”表示了mcs node队列的情况。n表示qspinlock只有一个mcs node,*表示qspinlock有若干个mcs node形成队列,同时在竞争spinlock。
2、Qspinlock中的状态迁移
一个完整的qspinlock状态迁移过程如下:

我们可以对照下一节的代码来验证上面的这张状态迁移图。
五、Qspinlock的实现
1、获取qspinlock
本小节我们主要描述获取和释放qspinlock的代码逻辑(省略了调试、内存屏障等的代码)。我们先看获取去qspinlock的代码如下:

如果spinlock的值(指完整的4B数据,即spinlock的val成员)等于0,那么说明是空锁,那么调用线程可以持锁进入临界区。这时候,spinlock的值被设置为1,即锁处于locked状态。如果快速路径失败,那么进入慢速路径。慢速路径比较长,我们分段解读:

A、如果当前spinlock的值只有pending比特被设定,那么说明该spinlock正处于owner把锁转交给自旋锁spinner的过程中。在这种情况下,我们需要重读spinlock的值。当然,如果持续重读的结果仍然是仅pending比特被设定,那么在_Q_PENDING_LOOPS次循环读之后放弃。
B、如果有其他的线程已经自旋等待该spinlock(pending域被设置为1)或者自旋等待per cpu的MCS锁上(pending域被设置为1并且设置了tail域也被设置),那么该线程需要挂入自旋等待队列。否则说明该线程是第一个等待持锁的,那么不需要排队,只要pending在自旋锁上就OK了。我们先看看怎么pending自旋等待qspinlock代码:

A、执行至此tail+pending都是0,看起来我们应该是第一个pending线程,通过queued_fetch_set_pending_acquire函数读取了spinlock的旧值,同时设置pending比特标记状态。
B、在设置pending标记位之后,我们需要再次检查一下我们这里设置pending比特的时候,其他的竞争者是否也修改了pending或者tail域。如果其他线程已经抢先修改,那么本线程不能再pending在自旋锁上了,而是需要回退pending设置(如果需要的话),并且挂入自旋等待队列。如果没有其他线程插入,那么当前线程可以开始自旋在qspinlock状态,等待owner释放锁了:

A、至此,我们已经成为合法的spinlock自旋者,通过atomic_cond_read_acquire函数自旋在spinlock的locked域,直到owner释放spinlock。这里自旋并不是轮询,而是通过WFE指令让CPU停下来,降低功耗。当owner释放spinlock的时候会发送事件唤醒该CPU。
B、发现owner已经释放了锁,那么清除pending标记,同时设定locked标记,持锁成功,进入临界区。以上的代码就是pending线程自旋等待进入临界区的代码,下面我们再一起看看自旋在MCS lock的情况:

当不能pending在spinlock的时候,当前执行线索需要挂入自旋队列,自旋在自己的mcs lock上。首先要进行入队前的准备工作:一是要找到对应的mcs node,其次要准备好tail域要设置的值。
A、获取mcs node的基地址
B、由于spin_lock可能会嵌套(在不同的自旋锁上嵌套,如果同一个那么就是死锁了)因此我们构建了多个mcs node,每次递进一层。顺便一提的是:当index大于阀值的时候,我们会取消qspinlock机制,恢复原始自旋机制。
C、将context index和cpu id组合成tail
D、根据mcs node基地址和index找到对应的mcs node
找到mcs node之后,我们需要挂入队列,代码如下:
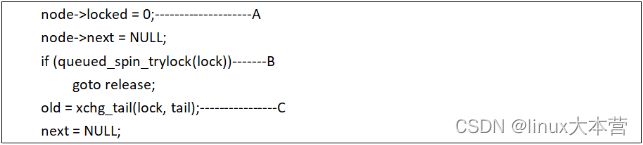
A、初始化MCS lock为未持锁状态
B、试图获取锁,很可能在上面的过程中,pending thread和owner thread都已经离开了临界区,这时候如果持锁成功,那么就可以长驱直入,进入临界区。
C、修改qspinlock的tail域,old保存了旧值。如果这是队列中的第一个节点,那么至此就结束了,如果之前tial域就有值,那么说明有队列中有其他waiter

A、如果等待队列中已经有了waiter,那么需要串联起来,等待机会去自旋在spinlock上去。
B、建立新node和旧的等待队列的关系
C、自旋在mcs lock上,等待locked状态变成1。至此,我们已经是处于mcs queue中的头部
执行至此,我们已经获得了MCS lock。在我们自旋等待的时候,可能其他的竞争者也加入到链表了,next不再是null了(即我们不再是队尾了)。因此这里需要更新next变量。由于本线程已经获取了自旋在spinlock的机会,那么需要

A、在获取了MCS lock之后(排到了mcs node queue的头部),我们获准了在spinlock上自旋。这里等待pending和owner离开临界区。
B、至此,我们获取了spinlock,在进入临界区之前,我们需要解放自旋在mcs锁的头部节点。如果本mcs node是队列中的最后一个节点,我们不需要处理mcs lock传递,直接试图持锁,如果成功,完成持锁,进入临界区。如果mcs node队列中仍然有节点,那么逻辑要更复杂一些,代码如下:

A、如果本mcs node不是队列尾部,那么不需要考虑竞争,直接持spinlock
B、在进入临界区之前需要释放下一个节点,让其自旋在spinlock上。
把mcs lock传递给下一个节点
2、释放qspinlock
释放spinlock的代码是queued_spin_unlock函数,非常的简单,就是把qspinlock的locked域设置为0。
六、小结
本文简单的介绍了linux内核中的自旋锁同步机制,在移动环境的激烈竞争场景中,自旋锁的性能表现不尽如人意,无论是吞吐量还是延迟。产生这个问题的主要原因有两个:一是内核中自旋锁的设计基本上是仅考虑SMP硬件平台,在目前异构的手机平台上表现不佳。二是由于内核自旋锁是基于公平的原则来设计,而手机场景中从来不是追求公平的,它看中的是响应延迟。