Java实现字典树 Trie
Java实现字典树 Trie
- 一、字典树介绍
- 二、Trie实现以及基本的插入查询操作
-
- 数组实现:
- HashMap实现:
- Trie插入(这里都以数组实现为例):
- Trie查询:
- 三、相关例题:
-
- 1、leetcode [208. 实现 Trie (前缀树)](https://leetcode.cn/problems/implement-trie-prefix-tree/)
- 2、leetcode [677. 键值映射](https://leetcode.cn/problems/map-sum-pairs/)
- 3、leetcode [642. 设计搜索自动补全系统](https://leetcode.cn/problems/design-search-autocomplete-system/)
- 总结:
一、字典树介绍
字典树又称为前缀树,是n叉树的特殊形式,广泛应用于统计和排序大量的字符串,它可以很大程度减少无所谓的字符比较,查询效率较高,Trie的核心思想是空间换时间,利用字符串的公共前缀提高查询效率
Trie 的示意图
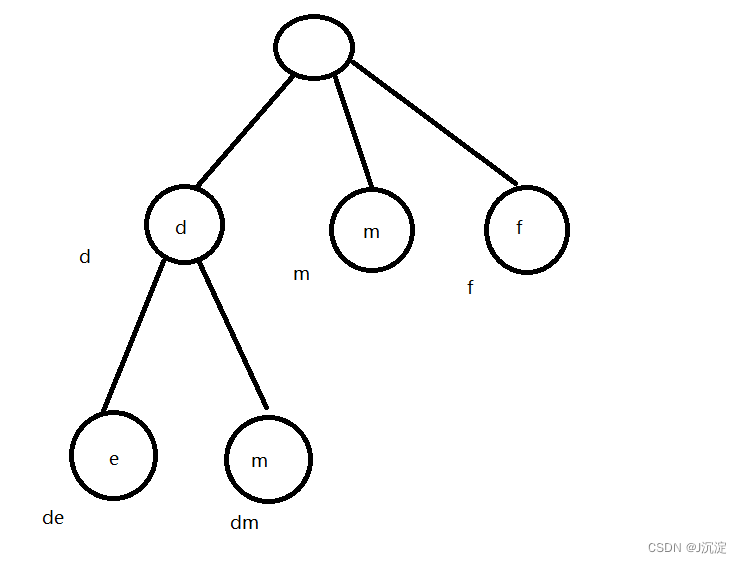
从根节点到子节点路径上的字符就是一个字符串的前缀,例如根节点到节点d的经过的路径是d,根节点到节点e经过的路经是de
Trie有如下的特点:
- 根节点是一个空字符
- 所有节点对应的字符串都与子节点有共同的前缀
- 任何节点的孩子节点的值都互不相同
二、Trie实现以及基本的插入查询操作
Trie的实现常见的有数组实现和HashMap实现
这里使用字符串(包括例题)都是由小写字母组成(要是有大写字母,原理相同,修改一些属性就行)
数组实现:
每一个父节点对应的子节点最多有26个,所以我们申请一个26个空间的数组存放子节点
class Trie{
Trie[] children;
public Trie(){
children = new Trie[26];
}
}
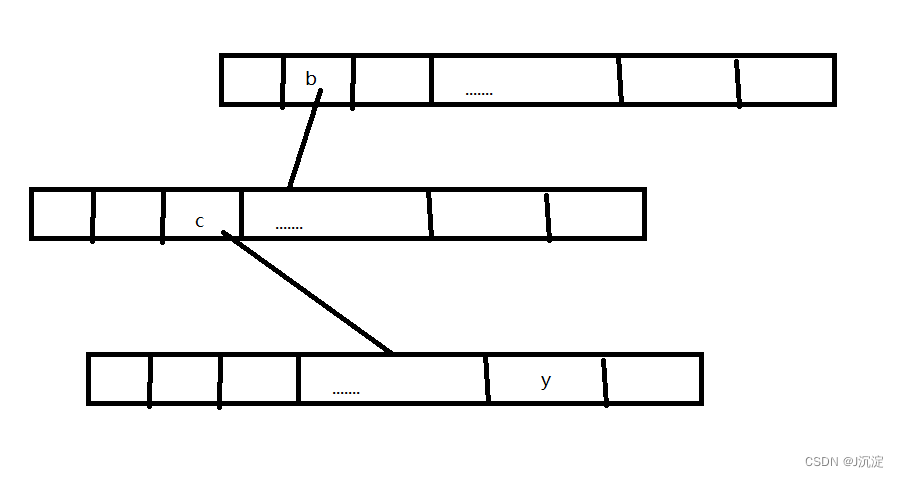
这样实现有一个缺点:如果要处理的字符串很少会浪费很多的空间,如下图所示字符串bcy:
HashMap实现:
class Trie{
Map<Character,Trie> children;
public Trie(){
children = new HashMap<>();
}
}
这样实现不会出现空间浪费,但是会比数组实现慢一点
Trie插入(这里都以数组实现为例):
Trie root = new Trie(); //根节点
public void insert(String str){
Trie node = root;
for(int i = 0;i < str.length();++i){
int index = str.charAt(i)-'a';
if(node.children[index] == null){
node.children[index] = new Trie();
}
node = node.children[index];
}
}
Trie查询:
public boolean search(String str){
Trie node = root;
for(int i = 0;i < str.length();++i){
int index = str.charAt(i)-'a';
if(node.children[index] == null){
return false;
}
node = node.children[index];
}
return true;
}
三、相关例题:
1、leetcode 208. 实现 Trie (前缀树)
这里的search是搜寻单词是不是存在字典树里面,我们可以在Trie加入一个标识isEnd,插入字符串的时候将最后一个字符的isEnd设为true,代表以该节点结尾的前缀是一个完整的单词
class Trie {
class TreeNode{
Map<Character,TreeNode> map;
boolean isEnd;
public TreeNode(){
map = new HashMap<>();
}
}
TreeNode root;
public Trie() {
root = new TreeNode();
}
public void insert(String word) {
TreeNode node = root;
for(int i = 0;i < word.length();++i){
char index = word.charAt(i);
if(!node.map.containsKey(index)){
node.map.put(index,new TreeNode());
}
node = node.map.get(index);
}
node.isEnd = true;
}
public boolean search(String word) {
TreeNode node = root;
for(int i = 0;i < word.length();++i){
char index = word.charAt(i);
if(!node.map.containsKey(index)){
return false;
}
node = node.map.get(index);
}
return node.isEnd == true;
}
public boolean startsWith(String prefix) {
TreeNode node = root;
for(int i = 0;i < prefix.length();++i){
char index = prefix.charAt(i);
if(!node.map.containsKey(index)){
return false;
}
node = node.map.get(index);
}
return true;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/
2、leetcode 677. 键值映射

class MapSum {
class TreeNode{
Map<Character,TreeNode> map;
int value;
public TreeNode(){
map = new HashMap<>();
}
public boolean containsKey(char ch){
return map.containsKey(ch);
}
}
TreeNode root;
public MapSum() {
root = new TreeNode();
}
public void insert(String key, int val) {
TreeNode node = root;
for(int i = 0;i < key.length();++i){
char ch = key.charAt(i);
if(!node.containsKey(ch)){
node.map.put(ch,new TreeNode());
}
node = node.map.get(ch);
}
node.value = val;
}
public int sum(String prefix) {
TreeNode node = root;
int sum = 0;
//搜寻前缀为prefix的节点位置
for(int i = 0;i < prefix.length();++i){
char ch = prefix.charAt(i);
if(!node.containsKey(ch)){
return 0;
}
node = node.map.get(ch);
}
//使用dfs思想,遍历剩下的所有节点
sum += dfs(node);
return sum;
}
//dfs返回值表示以node为父节点的所有键值之和
public int dfs(TreeNode node){
if(node == null)return 0;
int sum = node.value;
Set<Character> keyset = node.map.keySet();
for(char ch:keyset){
sum += dfs(node.map.get(ch));
}
return sum;
}
}
/**
* Your MapSum object will be instantiated and called as such:
* MapSum obj = new MapSum();
* obj.insert(key,val);
* int param_2 = obj.sum(prefix);
*/
注意:这里dfs方法里面的sum是局部变量,值不会传递,不需要回溯,与下面的题不一样
3、leetcode 642. 设计搜索自动补全系统


解决步骤:
1、处理sentence[i],和times[i]的时候我们按照平常的思路建树就行,sentence[i]最后一个字符的time = times[i]
2、用StringBuilder类型的对象bu存放input方法加入的字符,当c=='#‘的时候将bu加入到字典树中
3、当c!=’#'时,将c加入到bu中,然后使用和第二题一样的思路查找相同前缀的所有句子
4、使用优先队列(Java自带的有PriorityQueue),存放所有的答案,输出前三个最火的句子
class AutocompleteSystem {
class TreeNode{
Map<Character,TreeNode> map;
int time;
public TreeNode(){
map = new HashMap<>();
}
public boolean containsKey(char ch){
return map.containsKey(ch);
}
}
TreeNode root = new TreeNode();
class StringNode{
String str;
int time;
public StringNode(String str,int time){
this.str = str;
this.time = time;
}
}
public AutocompleteSystem(String[] sentences, int[] times) {
int sentenceLen = sentences.length;
for(int j = 0;j < sentenceLen;++j){
String str = sentences[j];
TreeNode node = root;
for(int i = 0;i < str.length();++i){
if(!node.containsKey(str.charAt(i))){
node.map.put(str.charAt(i),new TreeNode());
}
node = node.map.get(str.charAt(i));
}
node.time = times[j];
}
}
public void addSentence(StringBuilder bu){
TreeNode node = root;
for(int i = 0;i < bu.length();++i){
char ch = bu.charAt(i);
if(!node.containsKey(ch)){
node.map.put(ch,new TreeNode());
}
node = node.map.get(ch);
}
node.time += 1;
}
StringBuilder bu = new StringBuilder();
public List<String> input(char c) {
if(c=='#'){
addSentence(bu);
bu = new StringBuilder();
return new ArrayList<String>();
}
bu.append(c);
PriorityQueue<StringNode> queue = new PriorityQueue<>(new Comparator<StringNode>(){ //比较器实现
public int compare(StringNode node1,StringNode node2){
if(node1.time == node2.time){
return node1.str.compareTo(node2.str);
}
else{
return node2.time-node1.time;
}
}
});
search(queue);
List<String> list = new ArrayList<>();
int size = queue.size()<3?queue.size():3;//如果答案少于三个,全部输出
for(int i = 0;i < size;++i){
list.add(queue.poll().str);
}
return list;
}
//确定前缀的位置
public void search(PriorityQueue<StringNode> queue){
TreeNode node = root;
StringBuilder temp = new StringBuilder();
for(int i = 0;i < bu.length();++i){
char ch = bu.charAt(i);
if(!node.containsKey(ch))return;//如果没有这个前缀直接返回
temp.append(ch);
node = node.map.get(ch);
}
//搜寻所有答案
dfs(node,temp,queue);
}
//搜索所有的答案
public void dfs(TreeNode node,StringBuilder temp,PriorityQueue<StringNode> queue){
//如果该字符串是句子,加入
if(node.time!=0){
queue.offer(new StringNode(new String(temp),node.time));
}
Set<Character> keyset = node.map.keySet();
for(char ch:keyset){
temp.append(ch);
dfs(node.map.get(ch),temp,queue);
temp.deleteCharAt(temp.length()-1);//回溯
}
}
}
/**
* Your AutocompleteSystem object will be instantiated and called as such:
* AutocompleteSystem obj = new AutocompleteSystem(sentences, times);
* List param_1 = obj.input(c);
*/
注意:在搜索所有答案的时候要回溯,因为bu是StringBuilder类型的对象,传递的时候值改变了
总结:
字典树的用法不止这些,需要自己刷题积累