实操:docker资源控制——cgroup
文章目录
- Cgroup概述
- 一: docker资源控制——CPU
-
- 1.1 查看当前容器CPU限制状态
- 1.2 对容器cpu的限制方法
-
- 1.2.1 创建时指定限制
- 1.2.2 修改文件参数
- 对容器CPU进行BC压力测试,测试之前新开一台终端,top,然后按1
- 1.2.3 创建时按比例分配CPU资源
- 分别进容器测试,在top查看,或者docker stats 查看状态
- 1.2.4 限制容器使用指定的CPU core
- 1.2.5 cpu配额控制参数的混合使用
- 二: docker资源控制——Mem
- 三:docker资源控制——IOps和bps
doker通过cgroup来控制容器使用的资源配额,包括CPU、内存、磁盘三大方面,基本覆盖了常见的资源配额和使用量控制
Cgroup概述
Cgroup是control groups的缩写,是linux内核提供的一种可以限制、记录、隔离进程组所使用的物理资源的机制
物理资源如CPU、内存、磁盘IO等等
Cgroup被LXC、docker等很多项目用于实现进程资源控制。cgroup本身是提供将进程进行分组化管理的功能和接口的基础结构,IO或内存的分配控制等具体的资源管理是通过该方式
这些具体的资源管理功能成为cgroup子系统,有以下几大子系统实现:
blkio:设置限制每个块设备的输入输出控制,例如磁盘、光盘及USB等
CPU:使用调度程序为cgroup任务提供CPU的访问
cpuacct:产生cgroup任务的cpu资源报告
cpuset:如果是多核心的cpu,这个子系统会为cgroup任务分配单独的cpu和内存
devices:允许或拒绝cgroup任务对设备的访问
freezer:暂停和恢复cgroup任务
memory:设置每个cgroup的内存限制以及产生内存资源报告
net_cls:标记每个网络包以供cgroup方便使用
ns:命名空间子系统
perf_event:增加了对每个group的监测跟踪的能力,可以监测属于某个特定的group的所有线程以及运行在特定CPU的线上
下面开始利用stress压力测试工具来测试cpu和内存使用状况
一: docker资源控制——CPU
CPU使用率控制
1.1 查看当前容器CPU限制状态
cat /sys/fs/cgroup/cpu/docker/容器ID/cpu.cfs_quota_us
-1代表cpu资源使用是不受限制的,上限是硬件
[root@kibana ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
dd5782cde89d centos:7 "/bin/bash" 48 minutes ago Up 48 minutes test3
de37ff32e2c4 centos:7 "/bin/bash" 2 hours ago Up 2 hours test1
[root@kibana docker]# cd /sys/
[root@kibana sys]# ls
block bus class dev devices firmware fs hypervisor kernel module power
[root@kibana sys]# cd fs
[root@kibana fs]# ls
cgroup pstore selinux xfs
[root@kibana fs]# cd cgroup/
[root@kibana cgroup]# ls
blkio cpu cpuacct cpu,cpuacct cpuset devices freezer hugetlb memory net_cls net_cls,net_prio net_prio perf_event pids systemd
[root@kibana cgroup]# ll cpu
lrwxrwxrwx. 1 root root 11 Apr 16 09:27 cpu -> cpu,cpuacct
[root@kibana cgroup]# cd cpu
[root@kibana cpu]# ls
cgroup.clone_children cgroup.sane_behavior cpuacct.usage_percpu cpu.rt_period_us cpu.stat notify_on_release tasks
cgroup.event_control cpuacct.stat cpu.cfs_period_us cpu.rt_runtime_us docker release_agent user.slice
cgroup.procs cpuacct.usage cpu.cfs_quota_us cpu.shares machine.slice system.slice
[root@kibana cpu]# cat cpu.cfs_quota_us
-1
[root@kibana cpu]# cd docker/
[root@kibana docker]# ls
cgroup.clone_children cpuacct.usage cpu.rt_period_us dd5782cde89d7084de43e8c343f6cbbe99e5b12226e037b7e5529a35d05bce55
cgroup.event_control cpuacct.usage_percpu cpu.rt_runtime_us de37ff32e2c45188a4fd5d87c20dbbb0db8eeea13583e515b89a90a66ad3e7b1
cgroup.procs cpu.cfs_period_us cpu.shares notify_on_release
cpuacct.stat cpu.cfs_quota_us cpu.stat tasks
[root@kibana docker]# cat cpu.cfs_quota_us
-1
[root@kibana docker]# cd dd5782cde89d7084de43e8c343f6cbbe99e5b12226e037b7e5529a35d05bce55/
[root@kibana dd5782cde89d7084de43e8c343f6cbbe99e5b12226e037b7e5529a35d05bce55]# ls
cgroup.clone_children cgroup.procs cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.event_control cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
[root@kibana dd5782cde89d7084de43e8c343f6cbbe99e5b12226e037b7e5529a35d05bce55]# cat cpu.cfs_quota_us
-1
备注:
cpu周期 1s 100000
按照cpu时间周期分配
cpu在一个时刻,只能给一个进程占用
cpu的衡量单位是秒
1.2 对容器cpu的限制方法
以20%为例
1.2.1 创建时指定限制
[root@kibana ~]# docker run -itd --name tese13 --net net172.18/16 --ip 172.18.0.11 --cpu-quota 20000 centos:7 /bin/bash
7bee273b367147dd9ef7946229ad316f12b095be268ef2c1e8a5078ba47f7ed6
[root@kibana ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7bee273b3671 centos:7 "/bin/bash" 3 seconds ago Up 2 seconds tese13
dd5782cde89d centos:7 "/bin/bash" About an hour ago Up About an hour test3
de37ff32e2c4 centos:7 "/bin/bash" 2 hours ago Up 2 hours test1
或者
1.2.2 修改文件参数
[root@kibana ~]# echo 20000 > /sys/fs/cgroup/cpu/docker/7bee273b367147dd9ef7946229ad316f12b095be268ef2c1e8a5078ba47f7ed6/cpu.cfs_quota_us
[root@kibana ~]#echo 20000 》
可以使用–help查看命令
[root@kibana ~]# docker run --help
对容器CPU进行BC压力测试,测试之前新开一台终端,top,然后按1
[root@kibana ~]# docker exec -it tese13 /bin/bash
[root@7bee273b3671 /]# yum install bc -y

[root@7bee273b3671 /]# echo "scale=5000;4*a(1)" | bc -l -q
解释:a是bc的一个内置函数,代表反正切arctan,由于 tan(pi/4)=1,于是4*arctan(1) = pi

bc的cpu占用率被限制在20
备注:
种方法是绝对限制
Docker 提供了–cpu-period、–cpu-quota两个参数控制容器可以分配到的cpu时钟周期
–cpu-period是用来指定容器对CPU的使用要在多长时间内做一次重新分配
–cpu-quota是用来指定在这个周期内,最多可以有多少时间用来跑这个容器
与–cpu-shares不同的是,这种配置是指定一个绝对值,容器对CPU资源的使用绝对不会超过配置的值
–cpu-period和–cpu-quota的单位为微秒(1秒=1的六次方微秒),cpu-period的最小值为1000微秒,最大值为1000000微秒(1秒),默认值是0.1秒
–cpu-quota的默认值为-1,代表不做控制。
–cpu-period和–cpu-quota参数一般联合使用
例如:容器进程需要每一秒使用单个CPU的0.2秒时间,可以将–cpu-period设置为1秒,cpu-quota值设为0.2秒
当然,在多核情况下,如果允许容器进程完全占用两个cpu,可以将cpu-period设为0.1秒,cpu-quota设置0.2秒
[root@localhost stress]# docker ru -itd --cpu-period 100000 --cpu-quota 200000 centos:stress
[root@localhost stress]# docker exec -it 容器ID
[root@localhost stress]# cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
[root@localhost stress]# cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
1.2.3 创建时按比例分配CPU资源
创建两个容器为C1和C2,若只有这两个容器,设置容器的权重,使得C1和C2的CPU资源占比为33.3%和66.7%
[root@kibana ~]# docker run -itd --name c1 --network net172.18/16 --ip 172.18.0.21 --cpu-shares 512 centos:7 /bin/bash
9128e8cb60893a90eaf6575e7b36f104574bf22282311553a19b7dc56cf77045
[root@kibana ~]# docker run -itd --name c2 --network net172.18/16 --ip 172.18.0.22 --cpu-shares 512 centos:7 /bin/bash
b85c3fd567e8d30c4888243ee5f05167bf89e4cbb43a5b6d5499b81914775751
docker run -itd --name c1 --cpu-shares 512 centos:7
docker run -itd --name c2 --cpu-shares 1024 centos:7
[root@kibana ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b85c3fd567e8 centos:7 "/bin/bash" 48 seconds ago Up 47 seconds c2
9128e8cb6089 centos:7 "/bin/bash" About a minute ago Up About a minute c1
7bee273b3671 centos:7 "/bin/bash" 59 minutes ago Up 59 minutes tese13
dd5782cde89d centos:7 "/bin/bash" 2 hours ago Up 2 hours test3
de37ff32e2c4 centos:7 "/bin/bash" 3 hours ago Up 3 hours test1
分别进容器测试,在top查看,或者docker stats 查看状态
[root@kibana ~]# docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
b85c3fd567e8 c2 0.00% 392KiB / 1.781GiB 0.02% 648B / 0B 0B / 0B 1
9128e8cb6089 c1 0.00% 392KiB / 1.781GiB 0.02% 648B / 0B 0B / 0B 1
7bee273b3671 tese13 0.00% 272KiB / 1.781GiB 0.01% 14.9MB / 123kB 0B / 0B 1
dd5782cde89d test3 0.00% 944KiB / 1.781GiB 0.05% 15.1MB / 175kB 0B / 0B 3
de37ff32e2c4 test1 0.00% 80KiB / 1.781GiB 0.00% 15.1MB / 158kB 0B / 0B 1
进入c1,c2,安装压力测试软件stress
[root@kibana ~]# docker exec -it c1 /bin/bash
[root@9128e8cb6089 /]# yum install epel-release -y
[root@9128e8cb6089 /]# yum install stress -y
[root@kibana ~]# docker exec -it c2 /bin/bash
[root@b85c3fd567e8 /]# yum install epel-release -y
[root@b85c3fd567e8 /]# yum install stress -y
c1,c2测试
[root@b85c3fd567e8 /]# stress -c 4
[root@9128e8cb6089 /]# stress -c 4


备注:命令中的–cpu-shares参数值不能保证可以获得一个vcpu或者多少GHz的CPU资源,它仅是一个弹性的加权值
默认情况下,每个docker容器的CPU份额都是1024,单独一个容器的份额是没有意义的,只有在同时运行多个容器时,容器的CPU加权的效果才能体现出来
例如,两个容器A、B的CPU份额分别为1000和500,在cpu进行时间分片分配的时候,容器A比容器B多一倍的机会获得CPU的时间片
但分配的结果要取决于当时主机和其他容器的运行状态,实际上也无法保证容器A一定能获得CPU时间片;比如容器A的进程一直是空闲的,那么容器B是可以获取比容器A更多的CPU时间片的,极端情况下,例如主机上只运行了一个容器,即使他的CPU份额只有50,它也可以独占整个主机的CPU资源
cgroup只在容器分配的资源紧缺时,也为了安全考虑,,即在有必要需要对容器使用的资源进行限制,才会生效。
因此,无法单纯根据某个容器的CPU份额来确定有多少CPU资源分配给它,可以通过Cpu share设置使用CPU的优先级,比如启动了两个容器及运行查看CPU使用百分比
[root@localhost stress]# docker run -itd --name cpu512 --cpu-shares 512 centos:stress -c 10
#容器产生10个子函数进程
[root@localhost stress]# docker exec -it cpu512 bash
#进入容器使用top查看cpu使用情况
再开一个容器做比较
[root@localhost stress]# docker run -itd --name cpu1024 --cpu-shares 1024 centos:stress -c 10
[root@localhost stress]# docker exec -it cpu1024 bash
#进入容器使用top对比两个容器的%CPU,比例是1:2
1.2.4 限制容器使用指定的CPU core
对多核CPU的服务器,Docker还可以控制容器运行使用哪些CPU内核,即使用–cpuset-cpus参数
这对具有多cpu的服务器尤为有用,可以对需要高性能计算的容器进行性能优化的配置
当前cpu核数为4核
验证方法:top 然后按1检查
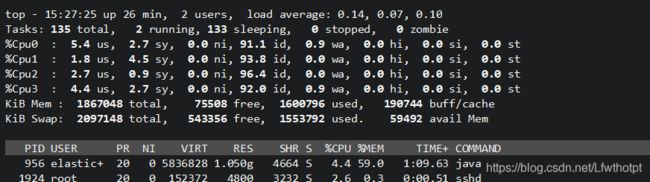
[root@kibana ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b85c3fd567e8 centos:7 "/bin/bash" About an hour ago Exited (137) 37 minutes ago c2
9128e8cb6089 centos:7 "/bin/bash" About an hour ago Exited (137) 37 minutes ago c1
7bee273b3671 centos:7 "/bin/bash" 2 hours ago Exited (137) 37 minutes ago tese13
dd5782cde89d centos:7 "/bin/bash" 4 hours ago Exited (137) 37 minutes ago test3
de37ff32e2c4 centos:7 "/bin/bash" 4 hours ago Exited (137) 37 minutes ago test1
批量删除容器
[root@kibana ~]# docker ps -a | awk '{print "docker rm "$1}' | bash
Error: No such container: CONTAINER
b85c3fd567e8
9128e8cb6089
7bee273b3671
dd5782cde89d
de37ff32e2c4
[root@kibana ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
创建容器,指定cpuID给容器test02
[root@kibana ~]# docker run -idt --name test02 --cpuset-cpus 1,3 centos:7 /bin/bash
ad53ee764486d1b26ff664b62dc6b2056269d605967e45799f1b369d08cb4c4b
[root@kibana ~]#
进入容器,压测检查
[root@ad53ee764486 /]# yum install stress epel-release -y
[root@ad53ee764486 /]# stress -c 4

top 然后按1检查
只有指定的内核在运转
备注:
[root@localhost stress]# docker run -itd --name cpu1 --cpuset-cpus 0-1 centos:stress
执行以上命令需要宿主机为双核,表示创建的容器只能用0、1两个内核,最终生成的cgroup的cpu内核配置如下
[root@localhost stress]# docker exec -it cpu1 bash
[root@localhost stress]# cat /sys/fs/cgroup/cpuset/cpuset.cpus
0-1
通过下面指令可以看到容器中进程与CPU内核的绑定关系,达到绑定CPU内核的目的
[root@localhost stress]# docker exec cpu1 taskset -c -p 1
#容器内部第一个进程号pid为1的被绑定到指定CPU上运行
pid 1's current affinity list: 0,1
1.2.5 cpu配额控制参数的混合使用
通过 cpuset-cpus参数指定容器A使用cpu内核0,容器B用cpu内核1
在主机上只有这两个容器使用相对应cpu内核的情况下,它们各自占用全部的内核资源,cpu-shares没有明显效果
cpuset-cpus与cpuset-mems参数只在多核、多内存节点上的服务器有效,并且必须与实际的物理配置汽配,不能溢出,否则也无法达到资源控制的目的
在系统具有多个cpu内核的情况下,需要通过cpuset-cpus参数为设置容器cpu内核才能方便地进行测试
宿主系统为4核心地情况下
[root@localhost stress]# docker run -itd --name cpu3 --cpuset-cpus 1 --cpu-shares 512 centos:stress stress -c 1
[root@localhost stress]# docker exec it cpu3 bash
[root@localhost 容器ID]# top
[root@localhost 容器ID]#exit
[root@localhost stress]# top #记住按1查看每个核心地占用
再创建一个
[root@localhost stress]# docker run -itd --name cpu4 --cpuset-cpus 2 --cpu-shares 1024 centos:stress stress -c 1
总结:上面地centos:stress镜像安装了stress工具,用来测试cpu和内存地负载,通过在两个容器上分别执行stress -c 1命令,将会给系统一个随机负载,产生一个进程,这一个进程都反复不停地计算由rand()产生随机数地平方根,直到资源耗尽
观察到宿主机地cpu使用率,创建容器时指定地cpu使用率接近100%,并且一批进程地cpu使用率明显存在2:1地使用比例地对比
二: docker资源控制——Mem
限制内存使用
docker run -itd --name testm -m 512m centos:7 /bin/bash
[root@kibana ~]# docker run -itd --name testm -m 512m centos:7 /bin/bash
[root@kibana ~]# docker stats
![]()
进入容器验证
[root@fc4e53fcf5c9 /]# yum install epel* -y
[root@fc4e53fcf5c9 /]# yum install stress -y
[root@fc4e53fcf5c9 /]# stress -m 512m --vm 2
备注:
与操作系统类似,容器可使用地内存包括两部分:物理内存和swap
docker通过下面两组参数来控制容器内存地使用量
-m或–memory:设置内存地使用限额,例如100m或者1024m
–memory-swap:设置内存+swap地使用限额
执行如下命令允许该容器最多使用200m的内存和300m的swap
[root@localhost stress]# docker run -itd --name memswap1 -m 200M --memory-swap=300M progrium/stress --vm 1 --vm-bytes 280M
–vm 1:启动一个内存工作线程
–vm-bytes 280M:每个线程分配280M内存
默认情况下,容器可以使用主机上的所有空闲内存,与cpu的cgroups配置类似,docker会自动为容器在宿主目录/sys/fs/group/memory/docker/容器完整ID/中创建相应的cgroup配置文件
如果让工作线程分配的内存超过300M,分配的内存超过限额,tress线程报错,容器异常退出
[root@localhost stress]# docker run -itd -m 200M --memory-swap=300M progrium/stress --vm 1 --vm-bytes 310M
三:docker资源控制——IOps和bps
bps是byte per seconds,每秒读写的数据量
iops是 io per seconds,每秒IO的次数
对block的IO进行限制
控制数据量用的多
控制IO次数用的不太多
–device-read-bps:限制读某个设备的bps(数据量)
例:docker run -d --device-read-bps /dev/sda:30M centos:7
–device-write-bps:限制某个写入设备的bs(数据量)
例:docker run -d --device-write-bps /dev/sda:30 centos:7
–device-read-iops:限制读某个设备的iops(次数)
–device-write-iops:限制写入某个设备的iops(次数)
限制容器流量在30M每秒
[root@kibana ~]# docker run -tid --name testi --device-read-bps /dev/sda:30M centos:7 /bin/bash
[root@kibana ~]# docker stats