谁说学生模型就得小?稀疏化DAN模型推理可提速600倍

©PaperWeekly 原创 · 作者 | BNDSBilly
研究方向 | 自然语言处理

Abstract
有效提升模型推理速度的方式是对 SOTA 的 Transformer 模型进行压缩,然而当前的推理速度仍然有待提高。本文中,作者对 RoBERTa-Large 进行了模型蒸馏,得到了一个基于 DAN 架构的、具有十亿级参数、稀疏激活的学生模型。实验表明,该模型在六个文本分类任务上保持了教师模型 97% 的表现,同时在 CPU 和 GPU 上的推理速度都提升了将近 倍。进一步的调查表明,本文提出的 pipeline 在隐私保护和域泛化设置中也很有效。

论文标题:
Sparse Distillation: Speeding Up Text Classification by Using Bigger Models
收录会议:
NAACL 2022
论文链接:
https://arxiv.org/abs/2110.08536

Introduction
大型预训练 Transformer 模型进来在 NLP 领域取得了很大的成功,它们的大量推理成本推进了对模型压缩工作的研究。知识蒸馏(Knowledge Distillation)是当下比较主流的一种方式,主要思路是将教师模型(性能良好的大规模模型)的知识尽可能多的传递给学生模型(小模型)。例如 DistillBERT [1] 是 BERT 经过蒸馏得到的,大小是 BERT 的 ,推理速度则提高了 。
然而,对于有大容量或低延迟要求的推理任务,这种加速可能仍然不够。在本文中,作者考虑通过引入稀疏蒸馏提炼出浅层、稀疏激活和过参数化的学生模型,来进一步推动推理速度的提升。与一般的使用“更小、更快、更便宜”学生模型的习惯相悖,本文探索了设计空间的一个新领域:使用比教师模型还大几倍的学生模型。
本文使用的学生模型基于 DAN(Deep Averaging Network) 网络 [1],其采用简单的架构,将输入句子中的 n-gram 映射到 embedding 并进行平均池化聚合,然后再使用多个线性层进行分类。通过选择 n-gram 词汇表和 embedding 维度,DAN 可以扩展到数十亿个参数。同时,由于在训练和推理期间 DAN 被稀疏激活,因此成本可以保持在较低水平。DAN 的一个弱势在于无法像自注意力一样计算 long-range contexts,但是根据研究表明,在某些任务上 DAN 可以取得与自注意力相当的结果。
本文在六个文本分类任务上进行了实验,观察到生成的学生模型保留了 的 RoBERTa-Large 教师模型表现。同时,作者还进一步考虑了隐私保护设置(即在蒸馏期间无法访问特定于任务的数据)和域泛化设置(即学生模型被应用并适应新数据域),发现本文的方法给 pipeline 带来了持续的提高。

Methods
本文使用了模型蒸馏。其中教师模型选取的是在训练集上 fine-tune 好的 RoBERTa-Large 模型;学生模型基于深度平均网络 DAN,但作者对其进行了修改:不再将单词作为操作单元,而是使用 n-grams 进行代替。模型结果如下图所示,首先从输入的句子 中提取出所有的 n-grams,转化为 embeddings 后做均值化,再输入到两个全连接层中得到 logits,并通过 softmax 操作输出最终概率。该方法可以通过预处理 embeddings 来降低复杂度,但不能处理 n-gram 以外的信息。

在蒸馏时,作者同时在大规模未标注数据集 和下游任务训练集 上对齐教师模型和学生模型的输出(最小化输出概率的 KL 散度),得到的模型称为 DAN(KD),之后可以继续在 进行进一步的 fine-tune,得到的模型称为 DAN(KD+FT),最后这一步是可选择性的。
划分 n-gram 时,作者使用了 sklearn 库中的 CountVectorizer 方法来计算每个下游任务数据集上的词汇表,并选取最频繁的 个词汇。具体地,作者将 n-gram 范围设置为 ,并设置 。

Experiments
实验选取了六个文本分类的数据集,并选取了相应的蒸馏过程使用的未标注数据集 。具体信息如下表所示:
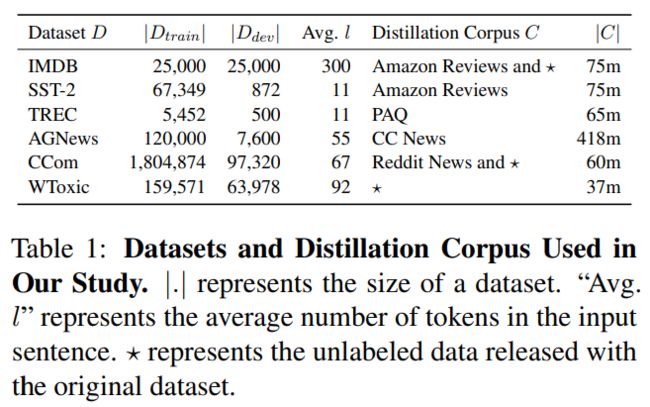
作者分别选取了三类模型,作为本文模型的对比实验:(1)不加入模型蒸馏,直接训练学生模型;(2)使用不基于 DAN 的学生模型结构,例如 Bi-LSTM 或 CNN;(3)直接对已有的压缩模型进行 fine-tune,例如 DistilBERT [2] 和 MobileBERT [3]。
最终得到的实验结果和分析如下:
如下表所示,在 个数据集上,教师模型和学生模型的表现均小于 ,这说明简单的 n-gram model 能力被低估了。并且模型蒸馏帮助弥补了至少一半的表现差距,尤其在 TREC 数据集上。这是一个 分类数据集,且训练集只有 个样本。然而,本文提出的方法有效地加强了监督,并有助于解决模型训练期间的稀疏性问题。
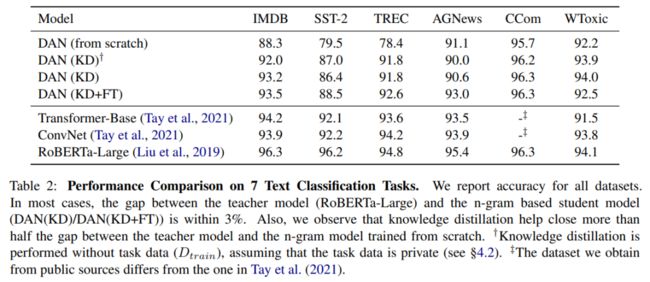
由于设计的 DAN 模型简单且稀疏,所以预期能取得较高的加速比。在本文中,所有推理速度测试均设置了 的 batch-size。GPU 推理使用一个 Quadro RTX 8000 GPU,CPU 推理使用 56 个 Intel Xeon CPU E5-2690 v4 CPU。如下表可以观察到,DAN 学生模型有很高的性能和推理效率,在 IMDB 数据集上加速比最为显著,达到了 倍的加速,作者推断这可能是因为 IMDB 数据集平均输入长度有 300 tokens,使用自注意力机制的 transformer 架构复杂度是输入长度的平方级别,而 DAN 架构复杂度仅为线性级别,所以加速效果显著。

根据下表所示,本文的 pipeline 难以对复杂语言现象进行建模,因为 DAN 架构只关注 n-gram,并且无法对单词之间的更高级别交互进行建模。


Conclusion
本文研究了一种使用知识蒸馏来生成更快的学生模型的新方法,颠覆了以往寻找更小学生模型的思路,而是允许学生模型有更大但稀疏的结构。帮助学生模型记住更多任务相关信息,同时降低计算复杂度。
本文的工作可能可以促使研究者们进一步探索稀疏架构,以实现更快、更大的学生模型:包括但不限于扩展超过 10 亿个参数的模型、扩展 DAN 架构以支持具有长期依赖关系的任务、在多语言任务上进行扩展等。

参考文献
[1] Mohit Iyyer, Varun Manjunatha, Jordan Boyd-Graber, and Hal Daumé III. Deep unordered composition rivals syntactic methods for text classification. In ACL, pp. 1681–1691, 2015
[2]Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108, 2019.
[3]Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou. Mobilebert: a compact task-agnostic BERT for resource-limited devices. arXiv preprint arXiv:2004.02984, 2020.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
