python面试题
文章目录
- 赋值、深拷贝和浅拷贝有什么区别?
- 元组和列表有什么不同?
- ==和is有什么不同?
- 集合怎么转字典?
- 字典怎么遍历?
- 如何在Python中实现多线程?
- 如何实现tuple和list的转换?
- 实现删除一个list里面的重复元素
- 单引号,双引号,三引号的区别
- Python里面如何生成随机数?
- 查询和替换一个文本字符串?
- 介绍一下except的用法和作用?
- 元组可以作为字典的key?
- 排序
- 快速排序
- 列表和数组有什么区别?
- 如何连接两个数组?
- 举出几个可变和不可变对象的例子?
- 字典和JSON有什么区别?
- 字典和列表的查找速度哪个更快?
- 模块(module)和包(package)有什么区别?
- 如何返回一个整数的二进制值?
- append和extend有什么区别?
- 如何按字母顺序对字典进行排序?
- remove、del和pop有什么区别?
- break、continue、pass是什么?
- iterables和iterators之间的区别?
- 解释Python中的Filter?
- 解释Python中reduce函数的用法?
- 什么是pickling和unpickling?
- 解释*args和**kwargs?
- Python中的生成器是什么?
- 如何使用索引来反转Python中的字符串?
- 类和对象有什么区别?
- 你对Python类中的self有什么了解?
- _init_在Python中有什么用?
- 解释一下Python中的继承?
- Python中OOPS是什么?
- 什么是抽象?
- 什么是封装?
- 什么是多态?
- 什么是Python中的猴子补丁?
- Python中使用的zip函数是什么?
- 解释Python中map()函数?
- Python中的装饰器是什么?
- 列表生成式中的if和else
- 字典清除
- 字符串转列表
- 字符串转整数
- 字符串单词统计
- 字典和 json 转换
- 单下划线和双下划线的作用
- super 函数的作用
- isinstance 的作用以及与type()的区别
- 查看目录下的所有文件
- 去除字符串首尾空格
- 字符串格式化方式
- sort 和 sorted 的区别
- 简述闭包
- 主动抛出异常
- 简述断言
- Flask 和 Django 的异同
- 正则 re.complie 的作用
- try except else finally 的意义
- 下面代码的输出结果将是什么?
- 编写程序,打印斐波那契数列的前十项
- 用一行Python代码,从给定列表中取出所有的偶数和奇数
- 打印九九乘法表
一个能思考的人,才真正是一个力量无边的人。——巴尔扎克
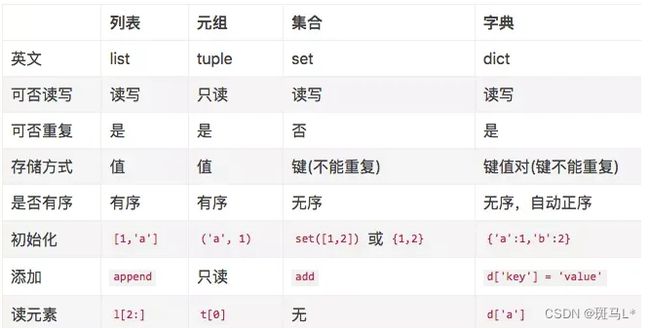
赋值、深拷贝和浅拷贝有什么区别?
赋值(=),就是创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。
浅拷贝:创建一个新的对象,但它包含的是对原始对象中包含项的引用(如果用引用的方式修改其中一个对象,另外一个也会修改改变){1,完全切片方法;2,工厂函数,如list();3,copy模块的copy()函数}
深拷贝:创建一个新的对象,并且递归的复制它所包含的对象(修改其中一个,另外一个不会改变){copy模块的deep.deepcopy()函数}
列表是可变的。创建后可以对其进行修改。
元组是不可变的。元组一旦创建,就不能对其进行更改。
列表表示的是顺序。它们是有序序列,通常是同一类型的对象。比如说按创建日期排序的所有用户名,如[“Seth”, “Ema”, “Eli”]。
元组和列表有什么不同?
列表是可变的。创建后可以对其进行修改。
元组是不可变的。元组一旦创建,就不能对其进行更改。
列表表示的是顺序。它们是有序序列,通常是同一类型的对象。比如说按创建日期排序的所有用户名,如[“Seth”, “Ema”, “Eli”]。
元组表示的是结构。可以用来存储不同数据类型的元素。比如内存中的数据库记录,如(2, “Ema”, “2020–04–16”)(#id, 名称,创建日期)。
==和is有什么不同?
对象的身份,可以通过 id() 方法来查看。
只有 id一致时,is比较才会返回 True,而当 value一致时,== 比较就会返回 True。
==比较两个对象或值的相等性。
is运算符用于检查两个对象是否属于同一内存对象。
is:判断两个引用对象是否为一个;
==:判断两个变量的值是否相等
集合怎么转字典?
1.使用zip和dict
2.使用dict.fromkeys
fromkeys用于创建一个新字典,以序列中元素做字典的键,value为字典所有键对应的初始值。
3.使用字典理解
list_keys = {1,2,3,4}
list_values = {‘Mon’,‘Tue’,‘Wed’,‘Thu’}
new_dict = dict(zip(list_keys, list_values))
print(new_dict)
{1: ‘Mon’, 2: ‘Tue’, 3: ‘Thu’, 4: ‘Wed’}
list_keys = {1,2,3,4}
new_dict = dict.fromkeys(list_keys,‘Mon’)
print(new_dict)
{1: ‘Mon’, 2: ‘Mon’, 3: ‘Mon’, 4: ‘Mon’}
list_keys = {1,2,3,4}
new_dict = {element:‘Tue’ for element in list_keys}
print(new_dict)
{1: ‘Tue’, 2: ‘Tue’, 3: ‘Tue’, 4: ‘Tue’}
字典怎么遍历?
-
遍历键:
for key in dict:
print (key)
for key in dict.keys():
print (key) -
遍历值:
for value in dict.values():
print (value) -
同时遍历键值:
for key,value in dict.items():
print ('key: ',key,'value: ',value)
for (key,value) in dict.items():
print ('key: ',key,'value: ',value)
for kv in dict.items():
print ('kv is : ',kv)
如何在Python中实现多线程?
Python代码的执行是由Python虚拟机进行控制。它在主循环中同时只能有一个控制线程在执行,意思就是Python解释器中可以运行多个线程,但是在执行的只有一个线程,其他的处于等待状态。
在多线程运行环境中,Python虚拟机执行方式如下:
- 设置GIL
- 切换进线程
- 执行下面操作之一
- 运行指定数量的字节码指令
- 线程主动让出控制权
- 切换出线程(线程处于睡眠状态)
- 解锁GIL
- 进入1步骤
GIL是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。
如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大
常用的多线程模块有threading 和 Queue。
如何实现tuple和list的转换?
直接使用tuple和list函数就行了
type()可以判断对象的类型
实现删除一个list里面的重复元素
使用set函数,set(list)
单引号,双引号,三引号的区别
单引号和双引号是等效的,如果要换行,需要符号()
三引号则可以直接换行,并且可以包含注释
Python里面如何生成随机数?
随机整数:random.randint(a,b):返回随机整数x,a<=x<=b
random.randrange(start,stop,[,step]):返回一个范围在(start,stop,step)之间的随机整数,不包括结束值。
随机实数:random.random( ):返回0到1之间的浮点数
random.uniform(a,b):返回指定范围内的浮点数。
查询和替换一个文本字符串?
sub(replacement, string[,count=0])(replacement是被替换成的文本,string是需要被替换的文本,count是一个可选参数,指最大被替换的数量)
介绍一下except的用法和作用?
try…except…except…[else…][finally…]
执行try下的语句,如果引发异常,则执行过程会跳到except语句。对每个except分支顺序尝试执行,如果引发的异常与except中的异常组匹配,执行相应的语句。如果所有的except都不匹配,则异常会传递到下一个调用本代码的最高层try代码中。
try下的语句正常执行,则执行else块代码。如果发生异常,就不会执行
如果存在finally语句,最后总是会执行。
元组可以作为字典的key?
首先一个对象能不能作为字典的key, 就取决于其有没有__hash__方法。 所以除了容器对象(list/dict/set)和内部包含容器对象的tuple 是不可作为字典的key, 其他的对象都可以。
排序
外层循环从1到n-1,内循环从当前外层的元素的下一个位置开始,依次和外层的元素比较,出现逆序就交换,通过与相邻元素的比较和交换来把小的数交换到最前面。
快速排序
通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
1、选定Pivot中心轴
2、从R指针开始,将大于Pivot的数字放在Pivot的右边
3、将小于Pivot的数字放在Pivot的左边
4、分别对左右子序列重复前三步操作
列表和数组有什么区别?
列表存在于python的标准库中。数组由Numpy定义。
列表可以在每个索引处填充不同类型的数据。数组需要同构元素。
列表上的算术运算可从列表中添加或删除元素。数组上的算术运算按照线性代数方式工作。
列表还使用更少的内存,并显著具有更多的功能。
如何连接两个数组?
import numpy as np
a = np.array([1,2,3])
b=np.array([4,5,6])
np.concatenate((a,b))
#=> array([1, 2, 3, 4, 5, 6])
记住,数组不是列表。数组来自Numpy和算术函数,例如线性代数。
我们需要使用Numpy的连接函数concatenate来实现。
举出几个可变和不可变对象的例子?
不可变意味着创建后不能修改状态。例如:int、float、bool、string和tuple。
可变意味着可以在创建后修改状态。例如列表(list)、字典(dict)和集合(set)。
字典和JSON有什么区别?
Dict是Python的一种数据类型,是经过索引但无序的键和值的集合。
JSON只是一个遵循指定格式的字符串,用于传输数据。
字典和列表的查找速度哪个更快?
在列表中查找一个值需要O(n)时间,因为需要遍历整个列表,直到找到值为止。
在字典中查找一个值只需要O(1)时间,因为它是一个哈希表。
如果有很多值,这会造成很大的时间差异,因此通常建议使用字典来提高速度。但字典也有其他限制,比如需要唯一键。
模块(module)和包(package)有什么区别?
模块是可以一起导入的文件(或文件集合)。
包是模块的目录。
因此,包是模块,但并非所有模块都是包。
如何返回一个整数的二进制值?
使用bin函数。
append和extend有什么区别?
Append将一个值添加到一个列表中
而extend将另一个列表的值添加到一个列表中。
如何按字母顺序对字典进行排序?
d = {‘c’:3, ‘d’:4, ‘b’:2, ‘a’:1}
sorted(d.items)
#=> [(‘a’, 1), (‘b’, 2), (‘c’, 3), (‘d’, 4)]
你不能对字典进行排序,因为字典没有顺序,但是你可以返回一个已排序的元组列表,其中包含字典中的键和值。
remove、del和pop有什么区别?
remove 删除第一个匹配的值。
del按索引删除元素。
pop用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
break、continue、pass是什么?
break:在满足条件时,它将导致程序退出循环。
continue:将返回到循环的开头,它使程序在当前循环迭代中跳过所有剩余语句。
pass:使程序传递所有剩余语句而不执行。
iterables和iterators之间的区别?
iterable:可迭代是一个对象,可以对其进行迭代。在可迭代的情况下,整个数据一次存储在内存中。
iterators:迭代器是用来在对象上迭代的对象。它只在被调用时被初始化或存储在内存中。迭代器使用next从对象中取出元素。
解释Python中的Filter?
过滤器函数,根据某些条件从可迭代对象中筛选值。
解释Python中reduce函数的用法?
reduce()函数接受一个函数和一个序列,并在计算后返回数值。
reduce 的作用
from functools import reduce
reduce(lambda x, y: x + y, range(101))
5050
reduce函数用于递归计算,同样需要传入一个函数和一个序列,并把函数和序列元素的计算结果与下一个元素进行计算。
什么是pickling和unpickling?
pickling是将Python对象(甚至是Python代码),转换为字符串的过程。
unpickling是将字符串,转换为原来对象的逆过程。
解释*args和**kwargs?
*arg 会把位置参数转化为 tuple,**kwarg 会把关键字参数转化为 dict。
*args,是当我们不确定要传递给函数参数的数量时使用的。
**kwargs,是当我们想将字典作为参数传递给函数时使用的。
Python中的生成器是什么?
生成器(generator)的定义与普通函数类似,生成器使用yield关键字生成值。
如果一个函数包含yield关键字,那么该函数将自动成为一个生成器。
如何使用索引来反转Python中的字符串?
string = ‘hello’
string[::-1]
‘olleh’
类和对象有什么区别?
类(Class)被视为对象的蓝图。类中的第一行字符串称为doc字符串,包含该类的简短描述。
在Python中,使用class关键字可以创建了一个类。一个类包含变量和成员组合,称为类成员。
对象(Object)是真实存在的实体。在Python中为类创建一个对象,我们可以使用obj = CLASS_NAME()
例如:obj = num()
使用类的对象,我们可以访问类的所有成员,并对其进行操作。
你对Python类中的self有什么了解?
self表示类的实例。
通过使用self关键字,我们可以在Python中访问类的属性和方法。
注意,在类的函数当中,必须使用self,因为类中没有用于声明变量的显式语法
_init_在Python中有什么用?
“init”是Python类中的保留方法。
它被称为构造函数,每当执行代码时都会自动调用它,它主要用于初始化类的所有变量。
解释一下Python中的继承?
继承(inheritance)允许一个类获取另一个类的所有成员和属性。继承提供代码可重用性,可以更轻松地创建和维护应用程序。
被继承的类称为超类,而继承的类称为派生类/子类。
Python中OOPS是什么?
面向对象编程,抽象(Abstraction)、封装(Encapsulation)、继承(Inheritance)、多态(Polymorphism)
什么是抽象?
抽象(Abstraction)是将一个对象的本质或必要特征向外界展示,并隐藏所有其他无关信息的过程。
什么是封装?
封装(Encapsulation)意味着将数据和成员函数包装在一起成为一个单元。
它还实现了数据隐藏的概念。
什么是多态?
多态(Polymorphism)的意思是「许多形式」。
子类可以定义自己的独特行为,并且仍然共享其父类/基类的相同功能或行为。
什么是Python中的猴子补丁?
猴子补丁(monkey patching),是指在运行时动态修改类或模块。
猴子补丁主要有以下几个用处:
- 在运行时替换方法、属性等;
- 在不修改第三方代码的情况下增加原来不支持的功能;
- 在运行时为内存中的对象增加 patch 而不是在磁盘的源代码中增加。
Python中使用的zip函数是什么?
zip函数获取可迭代对象,将它们聚合到一个元组中,然后返回结果。
zip()函数的语法是zip(*iterables)
解释Python中map()函数?
map()函数将给定函数应用于可迭代对象(列表、元组等),然后返回结果(map对象)。
我们还可以在map()函数中,同时传递多个可迭代对象。
Python中的装饰器是什么?
装饰器是一种特殊的闭包,就是在闭包的基础上传递了一个函数,然后覆盖原来函数的执行入口,以后调用这个函数的时候,就可以额外实现一些功能了。
装饰器(Decorator)是Python中一个有趣的功能。
它用于向现有代码添加功能。这也称为元编程,因为程序的一部分在编译时会尝试修改程序的另一部分。
列表生成式中的if和else
当只有 if 时,列表生成式构造为
[最终表达式 - (范围选择 - 范围过滤)]
当同时有 if 和 else 时,列表生成式构造为
[最终表达式 - 条件分支判断 - 范围选择]
如何 if 和 for 的位置调换,则会报错。
[num ** 2 for num in range(10) if num % 2 == 0]
[0, 4, 16, 36, 64]
[num ** 2 if num % 2 == 0 else 0 for num in range(10)]
[0, 0, 4, 0, 16, 0, 36, 0, 64, 0]
字典清除
- 清空字典 dict.clear()
- 指定删除:使用 pop方法来指定删除字典中的某一项(随机的)。
[lambda x:i*x for i in range(4)]
[3, 3, 3, 3]
lst = [lambda x: x*i for i in range(4)]
res = [m(2) for m in lst]
print(res)
- 预计结果为:[0, 2, 4, 6]
- 实际输出为:[6, 6, 6, 6]
字符串转列表
s = “1,2,3,4,5,6,7,8,9”
s.split(“,”)
[‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’]
字符串转整数
mylist = [1, 2, 3, 4, 5, 5, 6, 7, 4, 3]
list(set(mylist))
[1, 2, 3, 4, 5, 6, 7]
字符串单词统计
from collections import Counter
mystr = ‘sdfsfsfsdfsd,!sfsdfs’
Counter(mystr)
字典和 json 转换
dict1 = {‘zhangfei’:1, “liubei”:2, “guanyu”: 4, “zhaoyun”:3}
myjson = json.dumps(dict1) # 字典转JSON
mydict = json.loads(myjson) # JSON转字典
单下划线和双下划线的作用
foo:一种约定,Python内部的名字,用来区别其他用户自定义的命名,以防冲突,就是例如__init__(),del(),call()些特殊方法。
_foo:一种约定,用来指定变量私有。不能用from module import * 导入,其他方面和公有变量一样访问。
__foo:这个有真正的意义:解析器用_classname__foo来代替这个名字,以区别和其他类相同的命名,它无法直接像公有成员一样随便访问,通过对象名._类名__xxx这样的方式可以访问。
super 函数的作用
super()函数是用于调用父类(超类)的一个方法
isinstance 的作用以及与type()的区别
isinstance()函数来判断一个对象是否是一个已知的类型,类似type()。
区别:
- type()不会认为子类是一种父类类型,不考虑继承关系;
- isinstance()会认为子类是一种父类类型,考虑继承关系。
查看目录下的所有文件
import os
print(os.listdir(‘.’))
去除字符串首尾空格
" hello world ".strip()
‘hello world’
字符串格式化方式
方法一:使用 % 操作符
方法二:str.format(在 Python3 中,引入了这个新的字符串格式化方法)
方法三:f-strings(在 Python3-6 中,引入了这个新的字符串格式化方法)
print(“This is for %s” % “Python”)
print(“This is for %s, and %s” %(“Python”, “You”))
print(“This is my {}”.format(“chat”))
print(“This is {name}, hope you can {do}”.format(name=“zhouluob”, do=“like”))
name = “luobodazahui”
print(f"hello {name}")
sort 和 sorted 的区别
sort()是可变对象列表(list)的方法,无参数,无返回值。sort()会改变可变对象。
sorted()是产生一个新的对象。sorted(L)返回一个排序后的L,不改变原始的L,sorted()适用于任何可迭代容器。
简述闭包
闭包特点:
- 必须有一个内嵌函数;
- 内嵌函数必须引用外部函数中的变量;
- 外部函数的返回值必须是内嵌函数。
如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包(closure)。
主动抛出异常
使用raise
简述断言
Python 的断言就是检测一个条件,如果条件为真,它什么都不做;反之它触发一个带可选错误信息的 AssertionError。
Flask 和 Django 的异同
Flask 是 “microframework”,主要用来编写小型应用程序,不过随着 Python 的普及,很多大型程序也在使用 Flask。同时,在 Flask 中,我们必须使用外部库。
Django 适用于大型应用程序。它提供了灵活性,以及完整的程序框架和快速的项目生成方法。可以选择不同的数据库,URL结构,模板样式等。
正则 re.complie 的作用
re.compile 是将正则表达式编译成一个对象,加快速度,并重复使用。
try except else finally 的意义
- try…except…else 没有捕获到异常,执行 else 语句
- try…except…finally 不管是否捕获到异常,都执行 finally 语句
下面代码的输出结果将是什么?
list = [‘a’,‘b’,‘c’,‘d’,‘e’]
print(list[10:])
代码将输出[],不会产生IndexError错误,就像所期望的那样,尝试用超出成员的个数的index来获取某个列表的成员。例如,尝试获取list[10]和之后的成员,会导致IndexError。然而,尝试获取列表的切片,开始的index超过了成员个数不会产生IndexError,而是仅仅返回一个空列表。这成为特别让人恶心的疑难杂症,因为运行的时候没有错误产生,导致Bug很难被追踪到。
编写程序,打印斐波那契数列的前十项
fibo = [0,1]
[fibo.append(fibo[-2]+fibo[-1]) for i in range(8)]
fibo
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
用一行Python代码,从给定列表中取出所有的偶数和奇数
a = [1,2,3,4,5,6,7,8,9,10]
odd, even = [el for el in a if el % 2==1], [el for el in a if el % 2==0]
print(odd,even)
([1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
打印九九乘法表
>>> for i in range(1, 10):
for j in range(1, i + 1):
print(f"{i}*{j}={i * j}", end=" ")
print()