一篇文章彻底搞懂Python字符编码方式(中文编码,UTF-8,unicode,gb,gbk,中文乱码,爬虫中文乱码)
目录
前言
一、字符编码方式的来龙去脉。
1.字符集的含义。
2.编码方式演化过程
1.ASCII
2.GB2312、GBK
3.Unicode
4.UTF-8
二、Python的字符编码及相关操作
1.window系统的字符编码
2.Python的字符编码
1.Python中str与bytes的区别和联系
2.Python encode()方法【对str进行编码】
3.Python decode()方法【对bytes进行解码】
三.Pyhton中文乱码产生原因及常见问题的解决方法
1.中文乱码产生的原因
2.使用Requests获得网站内容后,发现中文显示乱码。
3.非法字符抛出异常。
4.读写文件的中文乱码
总结
前言
Python的字符编码问题特别是涉及到中文的显示时,乱码、报出错误一直是让新手头疼的事情。可能通过百度能搜索到解决方法,但是根据网上的方法即使解决了错误,也很可能不知道为什么这个方法能够解决这个错误。下面我根据自己的学习体验,对Python的字符编码进行一个浅显的梳理,以期对新入门Python的朋友有所帮助,如有错误望不吝赐教。
一、字符编码方式的来龙去脉。
1.字符集及字符编码的含义。
要彻底解决字符编码的问题就不能不去了解到底什么是字符集。计算机从本质上来说只认识二进制中的0和1。计算机并不识字,它实际上是把文本看做是一串“图片”,每张“图片”对应一个字符。计算机程序在显示文本时,必须借助一个记录这个文字“图片”如何显示的“图片”集合,从中找到每一个字符对应“图片”的数据,并依样画葫芦地把这个字“画”到屏幕上。这个“图片”就被称为“字模”,而记录字模显示数据的集合就被称为“字符集”。
为方便程序查找,每个字符的字模数据在字符集中必须是有序排列的,而且每个字符都会被分配一个独一无二的ID,这个ID就是字符的编码。而在计算机进行字符数据处理时,总是用这个编码代表它表示的那个字符。也就是字符编码格式。
2.编码方式演化过程
1.ASCII
美国人发明了计算机,制定了一套叫ASCII编码格式,用于表示26个英文字母大小写.每个编码一个字节,每个字节8位二进制位(今天的计算机大部分都已经是64位了,也就是一个字节64位二进制)。ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。这样在大部分情况下,英文与二进制的转换就变得容易多了。
2.GB2312、GBK
但是对于中国人来说,8位的二进制ASCII码完全不够表示几千个汉字的需要,为了解决这个问题中国国家标准总局1980年发布《信息交换用汉字编码字符集》提出了GB2312编码,用于解决汉字处理的问题。1995年又颁布了《汉字编码扩展规范》(GBK)(GB2312是简体汉字编码规范,但GBK是大字符集,不仅包含了简体中文,繁体中文还包括了日语、韩语等所有亚洲文字的双字节字符。)。最新汉字编码标准GB18030,其中已经可以支持中日韩以及藏文、蒙文,维吾尔文等少数民族文字。这样我们就解决了计算机处理汉字的问题了。
3.Unicode
日本人也推出了一套shift_JIS编码,用于表示日本
韩国人也推出了一套Euc_kr编码,用于表示韩文
…
全世界有上百种语言,每种语言都推出一套编码,而且互不兼容的话,是非常麻烦的一件事,只能自己跟自己玩。
于是Unicode编码应运而生,Unicode把所有语言都统一到一套编码里,实现了编码大统一,各国之间的编解码再也不会出现乱码了.Unicode一般用两个字节表示一个字符,极为生僻的字符会用到四个字节。Unicode又被称为统一码、万国码;它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
4.UTF-8
问题又来了,美国人说,我本来一个字节就够用了,现在用Unicode编码的话至少一个字符要用到两个字节,多出来的一个字节不是白白浪费内存空间嘛,这确实是个问题。于是大家一商量又推出了一套叫做UTF-8的编码格式。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
二、Python的字符编码及相关操作
了解了编码格式的演化过程,下面就进入编码格式的具体工作方式:
1.window系统的字符编码
Python的字符编码与系统字符编码息息相关,在了解Python编码前我们先看一下系统字符编码相关的知识。
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
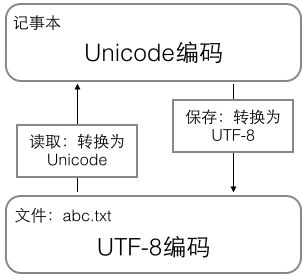
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
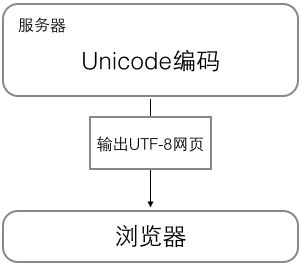
所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
2.Python的字符编码
在Python 3版本中,字符串类型是str是以Unicode编码的,也就是说Python的字符串支持多语言,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。在操作字符串时,我们经常遇到str和bytes的互相转换,为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。我们可以通过decode和encode方法对str和bytes进行转换,具体如下。
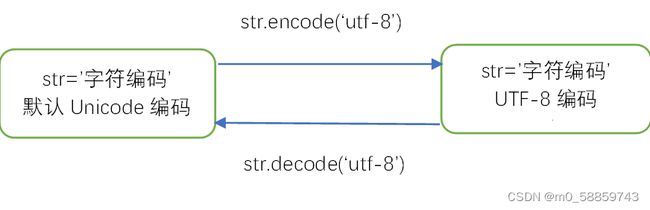
下面具体分析一下在Python中,str与bytes的区别和转换。
1.Python中str与bytes的区别和联系
str主要在程序运行过程中使用运行于内存,unicode编码。bytes主要用于存储和网络传输。
字符串类型是str是以Unicode编码的。
str='字符编码' #与str=u'字符编码'等效,只是省略了u. str为字符串是Unicode编码
print(str)
print(type(str)) #类型为 str
'''
输出:
字符编码
''' 在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。bytes类型,通过ASCII编码,如果字节存在中文会报错
bytes=b'coding'
print(bytes)
print(type(bytes))
'''
输出:
b'coding'
'''
bytes_error=b'中文' #bytes为 bytes类型,通过ASCII编码,如果字节存在中文会报错!!
'''
输出:
SyntaxError: bytes can only contain ASCII literal characters.
''' 为解决这个问题,可以用通过字符串过渡,也就是先将中文存于字符串(Unicode编码),再通过encode方法选择合适编码方式进行编码,具体如下所示
str='中文ch'
bytes_ch=str.encode('utf-8')
print(bytes_ch)
print(type(bytes_ch))
'''
输出:
b'\xe4\xb8\xad\xe6\x96\x87ch' #一个中文由3个字节表示,无法用ASCII码输出,就输出16进制表示
''' 在操作字符串时,我们经常遇到str和bytes的互相转换,通过deconde和encode进行str与bytes的转换,前提是使用同样的编码,否则就会产生乱码问题,具体我们后面会进行分析,为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。下面我们对encode和decode进行详细讲解:
2.Python encode()方法【对str进行编码】
encode()方法为字符串类型(str)提供的方法,用于将 str 类型转换成 bytes 类型,这个过程也称为“编码”。encode() 方法的语法格式如下:
| 1 |
|
| 参数 | 含义 |
|---|---|
| str | 表示要进行转换的字符串。 |
| encoding = "utf-8" | 指定进行编码时采用的字符编码,该选项默认采用 utf-8 编码。例如,如果想使用简体中文,可以设置 gb2312。 当方法中只使用这一个参数时,可以省略前边的“encoding=”,直接写编码格式,例如 str.encode("UTF-8")。 |
| errors = "strict" | 指定错误处理方式,其可选择值可以是:
|
注意:使用 encode() 方法对原字符串进行编码,不会直接修改原字符串,如果想修改原字符串,需要重新赋值。
将 str 类型字符串“编码方式”转换成 bytes 类型。
| 1 2 3 |
|
此方式默认采用 UTF-8 编码,也可以手动指定其它编码格式,例如:
| 1 2 3 |
|
3.Python decode()方法【对bytes进行解码】
和 encode()方法正好相反,decode()方法用于将 bytes类型的二进制数据转换为 str 类型,这个过程也称为“解码”。
decode() 方法的语法格式如下:
| 1 |
|
| 参数 | 含义 |
|---|---|
| bytes | 表示要进行转换的二进制数据。 |
| encoding="utf-8" | 指定解码时采用的字符编码,默认采用 utf-8 格式。当方法中只使用这一个参数时,可以省略“encoding=”,直接写编码方式即可。 注意,对 bytes 类型数据解码,要选择和当初编码时一样的格式。 |
| errors = "strict" | 指定错误处理方式,其可选择值可以是:
|
将bytes类型字符串“编码方式”转换成str类型。
| 1 2 3 4 |
|
注意:如果编码时采用的不是默认的 UTF-8 编码,则解码时要选择和编码时一样的格式,否则会抛出异常,例如:
| 1 2 3 4 5 6 7 8 9 |
|
三.Pyhton中文乱码产生原因及常见问题的解决方法
1.中文乱码产生的原因
中文乱码问题个根本原因就是几种常见中文编码之间存在兼容性,一图胜千言
所谓兼容性可以简单理解为子集,同时存在也不冲突。图中我们可以看出,ASCII被所有编码兼容,而最常见的UTF8与GBK之间除了ASCII部分之外没有交集,这也是平时业务中最常见的导致乱码场景,使用UTF8去读取GBK编码的文字,可能会看到各种乱码。由于在文件存储和网络传输中具体是使用哪种编码并不明确,所以在读取解码时如果使用的解码方式不对应,就会产生乱码。
现将常见的几种情况逐一进行梳理,以供大家学习
2.使用Requests获得网站内容后,发现中文显示乱码。
例如:
import requests
from bs4 import BeautifulSoup
url='http://w3school.com.cn'
response=requests.get(url)
soup=BeautifulSoup(response.text,'lxml')
xx=soup.find('div',id='d1').h2.text
print(xx)
输出
ÁìÏ鵀 Web ¼¼Êõ½Ì³Ì - È«²¿Ãâ·Ñ得到的结果是:ÁìÏ鵀 Web ¼¼Êõ½Ì³Ì - È«²¿Ãâ·Ñ
这是因为代码中获得的网页的响应体response和网站的编码方式不同,键入response.enconding得到的结果是ISO-8859-1。意思是Requests基于HTTP头部推测的文本编码方式是ISO-8859-1,实际网站真正使用的编码是gb2312。我们只需要声明response的正确编码方式为gb2312就可以了。
response.encoding='gb2312'。
(如果还不能解决,有可能是网页数据进行了压缩,可以使用response.content替换response.text。content会自动解码gzip和defate传输编码的响应数据,具体可以再去百度学习)
3.非法字符抛出异常。
当我们将某个字符串从GBK解码为Unicode的时候(也可能是用其他编码方式,比如'UTF-8'),可以采用上面介绍的decode方法,具体如下:
str.decode('GBK')但实际可能会遇到如下异常
UnicodeDecodeError: 'gbk' codec can't decode bytes in position 7-8: illegal multibyte sequence
出错原因是,字符串内混入了多种编码,于是出现了非法字符,如标点符号全角半角、全角空格的不同编码实现方式存储等,只要出现一个非法字符就会报错。解决方法很简单就是采用ignore忽略,具体可以参照上面对decode函数的详细介绍。
str.decode('GBK','ignore')4.读写文件的中文乱码
在使用Python3读取和保存文件时一定要注明编码方式。
同时在操作系统中保存的文件也应该明确系统存储时的编码方式,具体可以参照前面对系统编码方式的介绍,如记事本默认的编码方式时ANSI编码(gbk),读取时就应该使用gbk进行decode
另外,jison的保存中,如果希望能在记事本中读取中文文本,可以设置参数,ensure_ascii=false
import json
str='中文CH'
with open('ch.json','w',encoding='UTF-8') as f:
json.dump([str],f,ensure_ascii=False)总结
以上内容仅仅是个人学习中的一点体会,内容多为网络摘选,如有侵权可联系我处理,不对之处望不吝赐教。