论文阅读之Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer(2020)
文章目录
- Abstract
- introduction
- Setup
-
- model
- The Colossal Clean Crawled Corpus
- Downstream Tasks
- Input and Output Format
- Experiments
- 总结
- 参考
文章标题翻译过来,大概是:用统一的文本到文本转换器探索迁移学习的极限。
确实挺极限的。
这篇文章主要探讨了通过文本到文本转换的统一框架来进行自然语言处理(NLP)的迁移学习技术。研究比较了预训练目标、体系结构、未标记的数据集、迁移方法等因素在数十个语言理解任务上的效果。针对多种基于英语的NLP问题进行的实验,包括问答、文本摘要和情感分类,表明使用未标记的文本数据进行无监督的预训练特别有效,因为这些数据广泛存在于互联网上。该论文还介绍了他们的“Colossal Clean Crawled Corpus”(C4),这是一个由网络上数百GB的干净英语文本组成的数据集,并使用它来训练多达110亿个参数的模型,文章提出的模型架构为“Text-to-Text Transfer Transformer”(T5),在许多基准测试上取得了SOTA的结果。该研究的重点是提供一个综合的视角,编制现有技术并创建一个NLP迁移学习的标准测试平台。该论文发布了其代码、数据集和预训练模型,以促进未来对NLP迁移学习的研究。
简单来说,文章提出了C4数据集和T5模型架构。就是希望“一招鲜,吃遍天”,希望通过一个模型解决NLP的各种子任务如情感分类、文本摘要等等,实现大一统。实际上目前已经差不多了,ChatGPT的表现已经可以说是标志着大一统了。但是他背后的技术复杂,成本也不是我们小打小闹能够承担的,所以还是好好读论文,好好学好好看。
Abstract

迁移学习是自然语言处理(NLP)中一种强大的技术,它首先在数据丰富的任务上对模型进行预训练,然后在下游任务上进行微调。迁移学习的有效性导致了方法、方法和实践的多样性。在本文中,我们通过引入一个统一的框架来探索NLP的迁移学习技术的前景,该框架将所有基于文本的语言问题转换为文本到文本的格式。我们的系统研究比较了几十项语言理解任务的预训练目标、体系结构、未标记数据集、迁移方法和其他因素。通过将我们的探索见解与规模和我们新的“Colossal Clean Crawled Corpus”相结合,我们在许多基准测试上取得了最先进的成果,包括摘要、问答、文本分类等。为了促进NLP迁移学习的未来工作,我们发布了数据集、预先训练的模型和代码。
introduction

我们工作的基本理念是将每一个文本处理问题都视为“文本对文本”问题,即将文本作为输入,并产生新的文本作为输出。这种方法受到了以前NLP任务统一框架的启发,包括将所有文本问题作为问答(McCann等人,2018)、语言建模(Radford等人,2019)或跨度提取Keskar等人(2019b)任务。至关重要的是,文本到文本框架允许我们将相同的模型、目标、训练程序和解码过程直接应用于我们考虑的每一项任务。我们通过评估各种基于英语的NLP问题的性能来利用这种灵活性,包括问答、文档
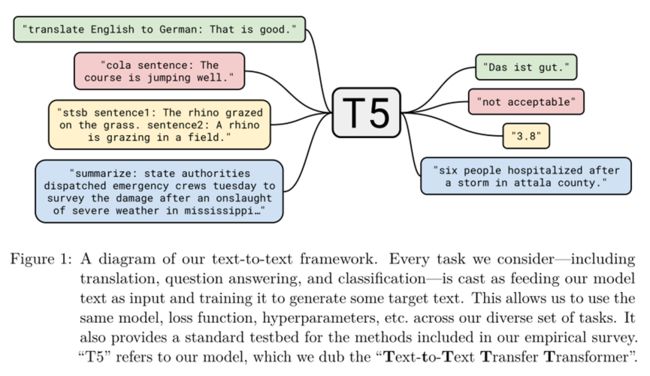
图1:我们的文本到文本框架的示意图。我们考虑的每一项任务,包括翻译、问答和分类,都被视为输入我们的模型文本,并对其进行训练以生成一些目标文本。这使我们能够在不同的任务集中使用相同的模型、损失函数、超参数等。它还为我们的实证调查中包含的方法提供了一个标准的试验台。
“T5”指的是我们的模型,我们称之为“文本到文本传输转换器”

总结和情感分类,仅举几个例子。通过这种统一的方法,我们可以比较不同迁移学习目标、未标记数据集和其他因素的有效性,同时通过扩大模型和数据集的规模来探索NLP迁移学习的局限性。
读到这里,大概应该知道,这篇文章的思路就是整理了一个很大的数据集,然后预训练了一个很大的模型,然后将不同的NLP的任务都归结为文本-文本的输出输出格式,从而统一不同的NLP的任务,例如想让他翻译,就在“translate xx to xx”: + 需要翻译的句子 输入,那么模型输出的文本就是翻译好的句子了;想让他做文本摘要,就将“summarize:”+文本输入,那么模型输出就是对应文本的摘要了。(prompt learning里的模板雏形显现了)
Setup
model
文章这里大段文字,盲猜这里没什么东西。
The Colossal Clean Crawled Corpus
这里讲了数据集的一些细节处理,目前对这个不太感兴趣,因为实验设置要求高,没机会训练这个模型,相信大家也应该对T5的细节更加关心。
Downstream Tasks

我们在这篇论文中的目标是衡量一般的语言学习能力。因此,我们研究了一组不同基准的下游性能,包括机器翻译、问答、抽象摘要和文本分类。具体来说,我们测量GLUE和SuperGLUE文本分类元基准的性能;美国有线电视新闻网/《每日邮报》摘要;SQuAD问答;以及WMT英语到德语、法语和罗马尼亚语的翻译。所有数据来源于TensorFlow数据集。
用了很多数据集。
Input and Output Format

为了在上述不同的任务集上训练单个模型,我们将我们考虑的所有任务转换为“文本到文本”格式,即向模型提供一些文本用于上下文或条件,然后要求模型生成一些输出文本的任务。该框架为预培训和微调提供了一致的培训目标。
具体而言,无论任务如何,模型都是以最大似然目标(使用“教师强迫”(Williams和Zipser,1989))进行训练的。为了指定模型应该执行的任务,我们在将任务特定的(文本)前缀添加到原始输入序列中,然后再将其输入到模型中。
注意这里,加了个前缀,其实就是相当于告诉模型这个是个什么任务。

例如,为了让模型将句子“That is good”从英语翻译成德语,模型将被输入“translate English to German: That is good. ”的序列,并被训练输出“Das ist gut”。对于文本分类任务,模型只需预测与目标标签对应的单个单词。例如,在MNLI基准上(Williams等人,2017),目标是预测一个前提是否暗示(“隐含”)、矛盾(“矛盾”)或两者都不暗示(“中立”)一个假设。经过预处理,输入序列变成了“mnli前提:我讨厌鸽子。假设:我对鸽子的感情充满了敌意。”,对应的目标词是“暗示”。请注意,如果我们的模型在文本分类任务中输出的文本与任何可能的标签都不对应,就会出现问题(例如,如果模型输出的是“汉堡包”,而任务的唯一可能标签是“隐含”、“中性”或“矛盾”)。在这种情况下,我们总是认为模型的输出是错误的,尽管我们从未在任何经过训练的模型中观察到这种行为。注意,用于给定任务的文本前缀的选择本质上是一个超参数;我们发现,改变前缀的确切措辞影响有限,因此没有对不同的前缀选择进行广泛的实验。图1显示了我们的文本到文本框架的示意图,其中包含一些输入/输出示例。我们在附录D中为我们研究的每一项任务提供了预处理输入的完整示例。
对于文本分类,文章说通过文章输出的内容来推测对文本的分类结果。(现在来看,其实就是需要prompt learning 的Verbalizer)以及文章提到,不同的提示语会对模型性能有影响,不过文章里说影响有限,但是还是会有影响,也就是template不同会影响模型,所以后面才会有各种研究离散template、连续template等等研究内容。
这边再把introduction的图1再放一下:
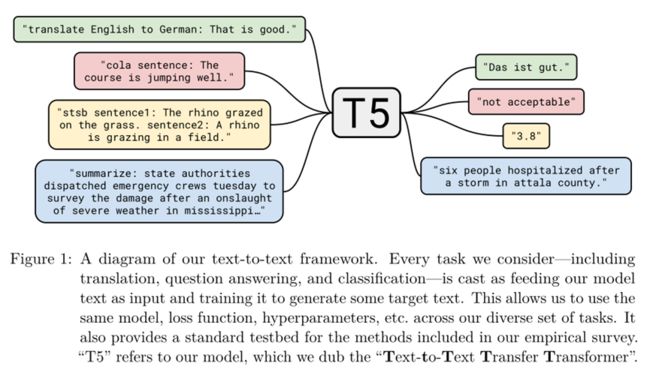
后面还讲了许多其他任务是怎么操作的,例如文本对应一个离散的数值,那么就将他四舍五入,然后映射成”x.x”(如“2.6”)这个字符串即可等等,点到为止,毕竟别人任务的难点在哪我也不太清楚了。
不过相信到这对T5有了一个比较大概的了解了:
模型输入:前缀(提示词)+输入文本
模型输出:文本(翻译、摘要等可以直接用,分类等可以通过简单的转换得到预测结果)
Experiments
后面做了很多实验,有关于模型参数大小的、数据集大小的、数据集种类的等等,眼花缭乱。
其中Fine-tuning Methods比较有意思。


有人认为,对模型的所有参数进行微调可能会导致次优结果,尤其是在低资源任务上(Peters等人,2019)。关于文本分类任务的迁移学习的早期结果主张只微调小分类器的参数,该小分类器由固定的预训练模型生成的句子嵌入(Subramanian等人,2018;Kiros等人,2015;Logeswaran和Lee,2018;Hill等人,2016;Conneau等人,2017)。这种方法不太适用于我们的编码器-解码器模型,因为必须训练整个解码器来输出给定任务的目标序列。相反,我们专注于两种替代的微调方法,它们只更新我们的编码器-解码器模型的参数的子集。

第一个是“适配器层”(Houlsby等人,2019;Bapna等人,2019),其动机是在微调的同时保持大部分原始模型的固定。适配器层是在变压器的每个块中的每个预先存在的前馈网络之后添加的附加密集ReLU密集块。这些新的前馈网络被设计成使得它们的输出维度与它们的输入相匹配。这允许它们被插入到网络中,而不需要对结构或参数进行额外的改变。微调时,仅更新适配器层和层规范化参数。这种方法的主要超参数是前馈网络的内维度d,它改变了添加到模型中的新参数的数量。我们用不同的d值进行实验。
(这不就是上篇读的文章里的东西吗,真是巧了这不是真的巧了吗)

我们考虑的第二种替代微调方法是“逐步解冻”(Howard和Ruder,2018)。在逐渐解冻的过程中,随着时间的推移,越来越多的模型参数会被微调。逐渐解冻最初应用于由单个层堆栈组成的语言模型体系结构。在这种设置中,在微调开始时,只更新最后一层的参数,然后在训练了一定数量的更新之后,还包括第二层到最后一层,以此类推,直到整个网络的参数被微调。为了使这种方法适应我们的编码器-解码器模型,我们并行地逐渐解冻编码器和解码器中的层,在这两种情况下都从顶部开始。由于我们的输入嵌入矩阵和输出分类矩阵的参数是共享的,所以我们在整个微调过程中都会更新它们。回想一下,我们的基线模型由编码器和解码器中的12层组成,并针对218个步骤。因此,我们将微调过程细分为12集,每集218/12个步骤,并在第n集从第12-n层训练到第12层。我们注意到,Howard和Ruder(2018)建议在每次训练后微调一个额外的层。然而,由于我们的监督数据集的大小变化如此之大,并且由于我们的一些下游任务实际上是许多任务(GLUE和SuperGLUE)的混合,因此我们采用了更简单的策略,即在每2^18/12个步骤后微调一个额外的层。
这些微调方法的性能比较如表10所示。
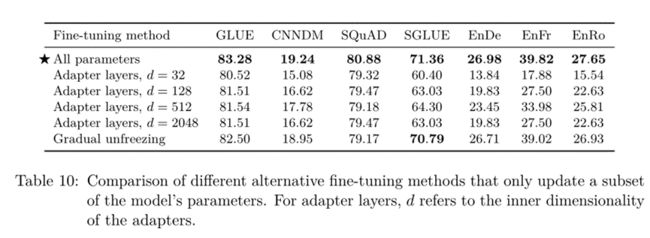
表10:仅更新模型参数子集的不同替代微调方法的比较。对于适配器层,d是指适配器的内部维度。

对于适配器层,我们使用32、128、512、2048的内部维度d来报告性能。根据过去的结果(Houlsby等人,2019;Bapna等人,2019),我们发现像SQuAD这样的低资源任务在较小的d值下工作良好,而高资源任务需要较大的维度才能实现合理的性能。这表明,只要维度被适当地缩放到任务大小,适配器层就可以是一种很有前途的技术,用于在更少的参数上进行微调。请注意,在我们的案例中,我们将GLUE和SuperGLUE分别视为一个单独的“任务”,通过连接它们的组成数据集,因此尽管它们包括一些低资源数据集,但组合的数据集足够大,需要很大的d值。我们发现,逐渐解冻导致所有任务的性能略有下降,尽管它确实在微调过程中提供了一些加速。通过更仔细地调整解冻时间表,可以获得更好的结果。
(所以说,到这prompt learning已经被肯定了?)
后面还有n多实验,有兴趣可以自己看……
总结
这篇文章确实很厉害,实验异常多,证明了pre-train+text-text这一框架的效果很好,考虑的各方面都很全面,所以文章也很长。确实挺极限的,以后有机会再多读几遍好了。
参考
https://arxiv.org/pdf/1910.10683.pdf