http长连接与会话保持

"我们半推半就的人生,没有和你一样被眷顾的未来!"
一、Http长连接
(1) 为什么需要长连接
如上展示的是一个常规得并不能再常规的http服务,从本地拉取远端linux上的本地文件上传至浏览器上,经过浏览器的渲染展示成如今的样子。唔,这有问题吗?emm这没有问题,我们可以先来看看服务器打印的日志信息。
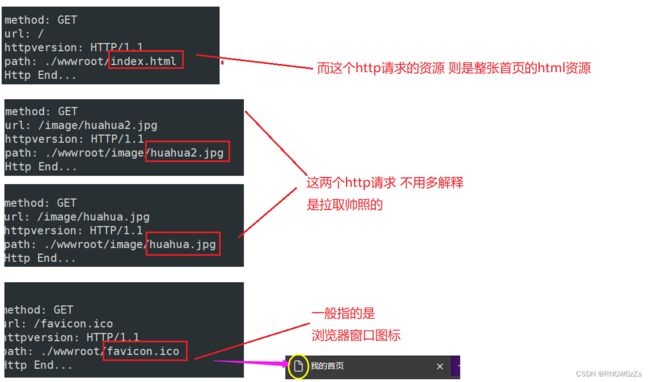
可以看出,为了拉取远端服务器资源,我们的浏览器进程不会仅仅向远端linux机器下部署的服务发起一次请求,而是多线程并发地访问请求远端资源。

我们知道,http是基于tcp的应用层服务。要构建出一个完整的网页,势必需要多次频繁构建发起http请求。然而tcp是面向连接的,建立连接的过程(tcp三次挥手)是有消耗的,同样建立通信连接后,服务端维护通信双方的连接也是有成本的!
HTTP持久连接是使用同一个 "TCP连接" 来发送和接收多个HTTP请求/应答,而不是为每一个新的请求/应答打开新的连接的方法。
因此,Http所提出的长连接的实质是为了解决,一个完整网页需要多次请求,才能构建出来的问题,需要让Client和Server端都需要支持,仅只需要建立好一个连接,在这个连接的基础上,获取大份资源。
那么如何判断一个一个http连接是否支持长连接呢? 其实在http的请求报文中携带:
"Connection:keep-alive" 支持长连接
"Connection:close" 不支持长连接

二、会话(Session)保持
在说会话保持之前呢,我们先来看看一组现象: 历史上我并没有登录这个哔站账号,现在我开始登录。

可以看出,在我进行哔站账号登录后,不管是另起一个窗口或者是将浏览器关掉又重新打开该网页,甚至 是重启 电脑(这里也就不演示了),都会发现我除了首次登录后,其他时候并没有 "登录账号" ,可账号却自动登录的 "怪事" ! 这是什么鬼??
(1) 如何理解会话保持 ?
也许你会认为,为我们做这个工作的难道是http? 那可就大错特错了,http没有那么高尚,它的功能仅仅在于 " 超文本传输 " ,将远端服务器的资源下拉到本地浏览器上罢了,也就意味着,客户端的每一个http请求本质上都是 "孤立的 ",是 "无状态的" ,它们都不知道是否在获取该资源之前,是否有同样的http报头做着与他们类似的事情。
http是无状态的,唔,它压根不在意用户的任何事情,任何浏览痕迹、搜索习惯……但,这些数据用户是需要的!比如,你意外点进去了一个网址,并饶有兴趣地看着里面的内容,但又是意外发生,你误操作关闭了该连接窗口,但还好你可以通过历史浏览痕迹,找到对该网址的重新访问。
在反过来看如今的哔站,我们每点击一个视频连接,是否都会发生网页跳转?是的!但是http是无状态的,根本不知道你历史已经登录提交过你的认证信息,新的页面根本无法识别你是哪一个用户,为此,只能让你重新进行登录!这是不是太麻烦了??
因此,会话保持的根本目的在于:
让一个用户在进行成功登录后,可以在整个网站,按照自己的身份进行随意访问。
(2) 如何实现会话保持 ?
①老方法: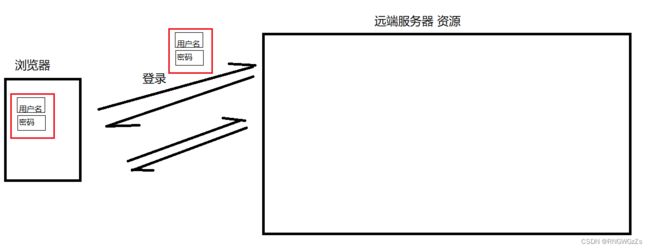
当用户进行第一次登录时,浏览器会帮用户将他的账号和 密码保存起来。当用户要对该网站进行访问时,浏览器会自动推送这些数据,远端服务器会根据这些用户这些数据 响应 该 用户身份下能看到的内容 。
而这个被保存下来的文件被叫做cookie。
这里的cookie文件可以被分为: 文件 和 内存(别忘了浏览器也是个进程) 。
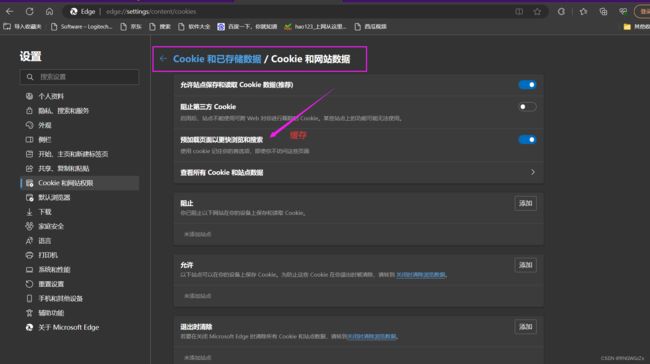
我们可以通过浏览器设置找到里面的cookie设置,同样cookie不仅仅只能保存用户数据,在用户需要访问有权限要求的网页时自动推送数据,还具有缓存技术,预先加载一些用户长访问的网址。这也就是为什么,多次打开一个网页加载速度会变快。
如图所示,如果我们对该cookie进行清理,之后用户 就需要重新进行登录了。
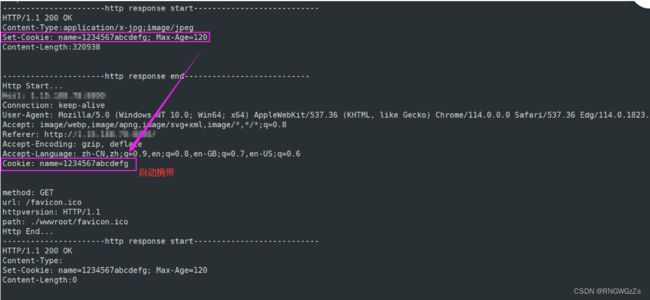
我们服务端可以在返回报头里设置:
"Set-Cookie: xxx"这样每次客户端发起的请求报头中,都会携带该cookie值。
既然上述的是老方法,那么也就意味着一定有新的方法,也就意味着老的方法一定在上面地方有不好的影响,促成新方法的出现。
问题:
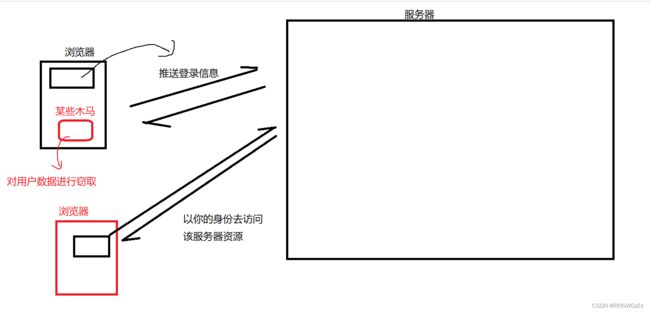
当用户将自己的登录数据保存在本地cookie当中时,一旦哪天没经得起诱惑,点了啥链接,下载了啥进程,导致自己的电脑里多出来了一个木马病毒,对该主机长期进行 " 数据窃取 ",服务器也就会误认为该 “非法用户" 就是你!
像生活中很常见的,某些很久不曾联系的QQ好友,突然来问你向你借钱……唔,就是很好的例子,他的QQ账号一定是被盗取了。
②新方法
从老方法找解决方法,无非就在于,不让用户数据由用户自己管理就好了,也许你会说你的"防范意识"很强。可是,这妨碍不住"防范意识"不强的人,数据被不法分子窃取。 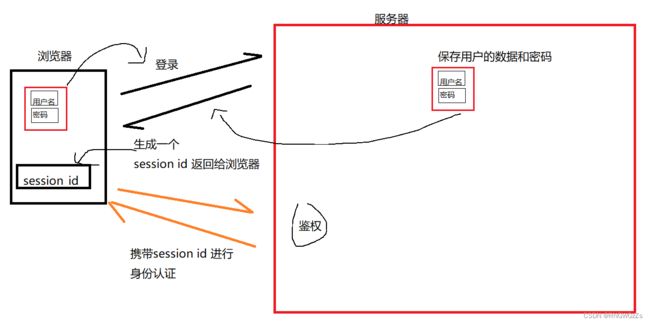
你说,“对没错,我现在知道了,用户数据现在没有由用户保存了,而是交由服务器了,首次登录后,服务器会返回一个session_id,浏览器会保存这个session_id,并在之后每次资源请求 中会携带cookie 中的 session_id。可是,你的session_id被截取了,人家不也可以用session_id去访问,造成服务器误认?这解决的方法岂不是杯水车薪?”
答案是肯定不是,此时你用户泄漏的就不再是自己的数据,而仅仅是一个session_id,大大降低了用户真实数据泄漏的可能,其次,在这个网络攻防的世界里,没有完全的、绝对的防御,需要配合一定的策略来保障网络访问的安全性。例如,当一个账号多年都没有上线,突然有一天上线,并且同时向多个好友发送消息,或者一个账号一个时间在一个IP,突然一个时间,服务器检测到该账号在完全不一样的IP地址发起 请求登录,遇到这种情况怎么办? 对于服务器而言 仅仅让该session_id 失效不就行了?让真正拥有密码的网民才能重新登录上账号…… 在网路世界中,都有无数双隐形的手,在保障网络、网民上网的安全。
总结:
① 如何理解长连接: 随着互联网的发展,http请求的资源不再仅仅是一些文字或者几kb的图片,为了避免http频繁建立连接,因此对于一份大资源的获取,仅仅通过一条连接即可。
② 会话保持是为了方便用户访问身份认证网页时,不用频繁提交用户信息,做身份识别。
本篇就到此结束了,感谢你的阅读。
祝你好运,向阳而生~
