10、hive综合示例:数据多分隔符(正则RegexSerDe)、url解析、行列转换常用函数(case when、union、concat和explode)详细使用示例
Apache Hive 系列文章
1、apache-hive-3.1.2简介及部署(三种部署方式-内嵌模式、本地模式和远程模式)及验证详解
2、hive相关概念详解–架构、读写文件机制、数据存储
3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
4、hive的使用示例详解-事务表、视图、物化视图、DDL(数据库、表以及分区)管理详细操作
5、hive的load、insert、事务表使用详解及示例
6、hive的select(GROUP BY、ORDER BY、CLUSTER BY、SORT BY、LIMIT、union、CTE)、join使用详解及示例
7、hive shell客户端与属性配置、内置运算符、函数(内置运算符与自定义UDF运算符)
8、hive的关系运算、逻辑预算、数学运算、数值运算、日期函数、条件函数和字符串函数的语法与使用示例详解
9、hive的explode、Lateral View侧视图、聚合函数、窗口函数、抽样函数使用详解
10、hive综合示例:数据多分隔符(正则RegexSerDe)、url解析、行列转换常用函数(case when、union、concat和explode)详细使用示例
11、hive综合应用示例:json解析、窗口函数应用(连续登录、级联累加、topN)、拉链表应用
12、Hive优化-文件存储格式和压缩格式优化与job执行优化(执行计划、MR属性、join、优化器、谓词下推和数据倾斜优化)详细介绍及示例
13、java api访问hive操作示例
文章目录
- Apache Hive 系列文章
- 一、多字节分隔符的三种方案
-
- 1、默认规则
- 2、常见数据格式示例
-
- 1)、多分隔符情形1
- 2)、数据字段中包含分隔符
- 3、解决方案
-
- 1)、替换分隔符
- 2)、RegexSerDe正则加载
-
- 1、多分隔符1的正则解决示例
- 2、数据字段中包含分隔符正则解决示例
- 3)、自定义InputFormat
-
- 1、实现RecordReader接口
- 2、实现TextInputFormat
- 3、打包、加入hive classpath
- 4、创建表,并指定解析类
- 5、验证
- 4、解决方案选择
- 二、URL的常用解析函数
-
- 1、数据格式
- 2、hive函数
- 3、parse_url函数
- 4、parse_url_tuple函数
- 5、Lateral View侧视图与UDTF
- 三、行列转换的常用函数
-
- 1、示例1:case when 函数-多行转多列
- 2、示例2:concat函数-多行转单列
-
- 1)、concat函数
- 2)、concat_ws函数
- 3)、collect_list函数
- 4)、collect_set函数
- 5)、实现多行转单列
- 3、示例3:union函数-多列转多行
-
- 1)、union函数
- 2)、union all函数
- 3)、实现多列转多行
- 4、示例:explode函数-单列转多行
本文介绍了hive在导入数据中对不同的字符分隔符的处理方式、URL的一般解析函数介绍和hive中对数据的行列转换示例。其中行列转换介绍了case when、concat、union和explode四个函数。
本文依赖hive环境可用。
本文分为三部分,即数据多分隔符使用示例、URL常规解析示例和行列转换的四个函数。
本文部分数据来源于互联网。
一、多字节分隔符的三种方案
1、默认规则
Hive默认序列化类是LazySimpleSerDe,其只支持使用单字节分隔符(char)来加载文本数据,例如逗号、制表符、空格等等,默认的分隔符为”\001”。根据不同文件的不同分隔符,可以通过在创建表时使用 row format delimited 来指定文件中的分割符,确保正确将表中的每一列与文件中的每一列实现一一对应的关系。

2、常见数据格式示例
1)、多分隔符情形1
形如1:每一行数据的分隔符是多字节分隔符,例如:”||”、“–”等

2)、数据字段中包含分隔符
形如2:数据的字段中包含了分隔符
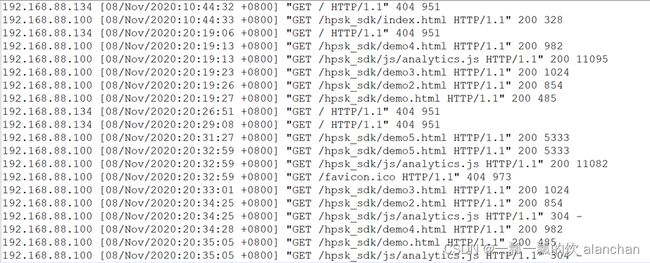
上图中每列的分隔符为空格,但是数据中包含了分割符,时间字段中也有空格
3、解决方案
1)、替换分隔符
使用程序提前将数据中的多字节分隔符替换为单字节分隔符。此种解决办法就是替换原始文件的分隔符。
2)、RegexSerDe正则加载
除了使用最多的LazySimpleSerDe,Hive该内置了很多SerDe类;
官网地址:https://cwiki.apache.org/confluence/display/Hive/SerDe
多种SerDe用于解析和加载不同类型的数据文件,常用的有ORCSerDe 、RegexSerDe、JsonSerDe等。
RegexSerDe用来加载特殊数据的问题,使用正则匹配来加载数据。
根据正则表达式匹配每一列数据。
https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStarted-ApacheWeblogData
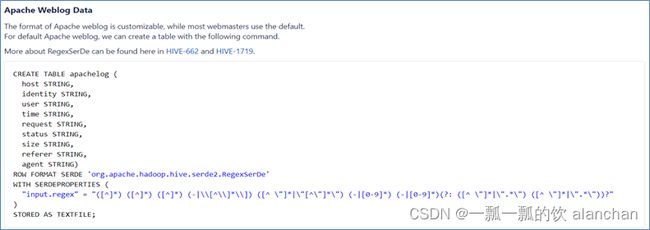
1、多分隔符1的正则解决示例
--创建表
create table singer(id string,--歌手id
name string,--歌手名称
country string,--国家
province string,--省份
gender string,--性别
works string)--作品
--指定使用RegexSerde加载数据
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES ("input.regex" = "([0-9]*)\\|\\|(.*)\\|\\|(.*)\\|\\|(.*)\\|\\|(.*)\\|\\|(.*)");
--加载数据
load data local inpath '/usr/local/bigdata/test01.txt' into table singer;
2、数据字段中包含分隔符正则解决示例
--创建表
create table apachelog(
ip string, --IP地址
stime string, --时间
mothed string, --请求方式
url string, --请求地址
policy string, --请求协议
stat string, --请求状态
body string --字节大小
)
--指定使用RegexSerde加载数据
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
--指定正则表达式
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^}]*) ([^ ]*) ([^ ]*) ([^ ]*) ([0-9]*) ([^ ]*)"
) stored as textfile ;
load data local inpath '/usr/local/bigdata/apache_web_access.log' into table apachelog;
3)、自定义InputFormat
Hive中也允许使用自定义InputFormat来解决以上问题,通过在自定义InputFormat,来自定义解析逻辑实现读取每一行的数据。

1、实现RecordReader接口
用于自定义读取器,在自定义InputFormat中使用,将读取到的每行数据中的||替换为|。
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.Seekable;
import org.apache.hadoop.hive.ql.io.CodecPool;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.Decompressor;
import org.apache.hadoop.io.compress.SplitCompressionInputStream;
import org.apache.hadoop.io.compress.SplittableCompressionCodec;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapred.RecordReader;
import lombok.extern.slf4j.Slf4j;
/**
* 用于自定义读取器,在自定义InputFormat中使用,将读取到的每行数据中的||替换为|
*
* @author alanchan
*
*/
@Slf4j
public class SingerRecordReader implements RecordReader<LongWritable, Text> {
int maxLineLength;
private CompressionCodecFactory compressionCodecs = null;
private long start;
private long pos;
private long end;
private LineReader in;
private Seekable filePosition;
private CompressionCodec codec;
private Decompressor decompressor;
public SingerRecordReader(Configuration job, FileSplit split) throws IOException {
this.maxLineLength = job.getInt("mapred.linerecordreader.maxlength", Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
compressionCodecs = new CompressionCodecFactory(job);
codec = compressionCodecs.getCodec(file);
FileSystem fs = file.getFileSystem(job);
FSDataInputStream fileIn = fs.open(split.getPath());
if (isCompressedInput()) {
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn = ((SplittableCompressionCodec) codec).createInputStream(fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new LineReader(cIn, job);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn; // take pos from compressed stream
} else {
in = new LineReader(codec.createInputStream(fileIn, decompressor), job);
filePosition = fileIn;
}
} else {
fileIn.seek(start);
in = new LineReader(fileIn, job);
filePosition = fileIn;
}
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}
public synchronized boolean next(LongWritable key, Text value) throws IOException {
while (getFilePosition() <= end) {
key.set(pos);
int newSize = in.readLine(value, maxLineLength, Math.max(maxBytesToConsume(pos), maxLineLength));
String str = value.toString().replaceAll("\\|\\|", "\\|");
value.set(str);
pos += newSize;
if (newSize == 0) {
return false;
}
if (newSize < maxLineLength) {
return true;
}
log.info("Skipped line of size " + newSize + " at pos " + (pos - newSize));
}
return false;
}
public LongWritable createKey() {
return new LongWritable();
}
public Text createValue() {
return new Text();
}
private long getFilePosition() throws IOException {
long retVal;
if (isCompressedInput() && null != filePosition) {
retVal = filePosition.getPos();
} else {
retVal = pos;
}
return retVal;
}
private boolean isCompressedInput() {
return (codec != null);
}
private int maxBytesToConsume(long pos) {
return isCompressedInput() ? Integer.MAX_VALUE : (int) Math.min(Integer.MAX_VALUE, end - pos);
}
public float getProgress() throws IOException {
if (start == end) {
return 0.0f;
} else {
return Math.min(1.0f, (getFilePosition() - start) / (float) (end - start));
}
}
public synchronized long getPos() throws IOException {
return pos;
}
public synchronized void close() throws IOException {
try {
if (in != null) {
in.close();
}
} finally {
if (decompressor != null) {
CodecPool.returnDecompressor(decompressor);
}
}
}
public static class LineReader extends org.apache.hadoop.util.LineReader {
LineReader(InputStream in) {
super(in);
}
LineReader(InputStream in, int bufferSize) {
super(in, bufferSize);
}
public LineReader(InputStream in, Configuration conf) throws IOException {
super(in, conf);
}
}
}
2、实现TextInputFormat
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapred.InputSplit;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.RecordReader;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
/**
* 用于实现自定义InputFormat,读取每行数据
*
* @author alanchan
*
*/
public class SingerSerDe extends TextInputFormat {
@Override
public RecordReader<LongWritable, Text> getRecordReader(InputSplit genericSplit, JobConf job, Reporter reporter) throws IOException {
reporter.setStatus(genericSplit.toString());
SingerRecordReader reader = new SingerRecordReader(job, (FileSplit) genericSplit);
return reader;
}
}
3、打包、加入hive classpath
mvn package clean -Dmaven.test.skip=true
mvn package -Dmaven.test.skip=true
add jar /usr/local/bigdata/hive-SingerSerDe.jar;
或者
add jar /usr/local/bigdata/apache-hive-3.1.2-bin/lib/hive-SingerSerDe.jar;
0: jdbc:hive2://server4:10000> add jar /usr/local/bigdata/hive-SingerSerDe.jar;
No rows affected (0.003 seconds)
或者
0: jdbc:hive2://server4:10000> add jar /usr/local/bigdata/apache-hive-3.1.2-bin/lib/hive-SingerSerDe.jar;
No rows affected (0.003 seconds)
4、创建表,并指定解析类
create table singer2(
id string,--歌手id
name string,--歌手名称
country string,--国家
province string,--省份
gender string,--性别
works string)
--指定使用分隔符为|
row format delimited fields terminated by '|'
--指定使用自定义的类实现解析
stored as
inputformat 'org.hive.serde.SingerSerDe'
outputformat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
0: jdbc:hive2://server4:10000> create table singer2(
. . . . . . . . . . . . . . .> id string,--歌手id
. . . . . . . . . . . . . . .> name string,--歌手名称
. . . . . . . . . . . . . . .> country string,--国家
. . . . . . . . . . . . . . .> province string,--省份
. . . . . . . . . . . . . . .> gender string,--性别
. . . . . . . . . . . . . . .> works string)
. . . . . . . . . . . . . . .> --指定使用分隔符为|
. . . . . . . . . . . . . . .> row format delimited fields terminated by '|'
. . . . . . . . . . . . . . .> --指定使用自定义的类实现解析
. . . . . . . . . . . . . . .> stored as
. . . . . . . . . . . . . . .> inputformat 'org.hive.serde.SingerSerDe'
. . . . . . . . . . . . . . .> outputformat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
No rows affected (0.062 seconds)
-- 加载数据即可
5、验证
0: jdbc:hive2://server4:10000> select * from singer2;
+-------------+---------------+------------------+-------------------+-----------------+----------------+
| singer2.id | singer2.name | singer2.country | singer2.province | singer2.gender | singer2.works |
+-------------+---------------+------------------+-------------------+-----------------+----------------+
| 01 | 周杰伦 | 中国 | 台湾 | 男 | 七里香 |
| 02 | 刘德华 | 中国 | 香港 | 男 | 笨小孩 |
| 03 | 汪 峰 | 中国 | 北京 | 男 | 光明 |
| 04 | 朴 树 | 中国 | 北京 | 男 | 那些花儿 |
| 05 | 许 巍 | 中国 | 陕西 | 男 | 故乡 |
| 06 | 张靓颖 | 中国 | 四川 | 女 | 画心 |
| 07 | 黄家驹 | 中国 | 香港 | 男 | 光辉岁月 |
| 08 | 周传雄 | 中国 | 台湾 | 男 | 青花 |
| 09 | 刘若英 | 中国 | 台湾 | 女 | 很爱很爱你 |
| 10 | 张 杰 | 中国 | 四川 | 男 | 天下 |
+-------------+---------------+------------------+-------------------+-----------------+----------------+
10 rows selected (0.098 seconds)
4、解决方案选择
本示例提供了三种解决思路,优先推荐使用正则表达式的解决办法。其他两种解决方式视具体情况而定。
二、URL的常用解析函数
1、数据格式
对用户访问的URL和用户的来源URL进行解析处理,获取用户的访问域名、访问页面、用户数据参数、来源域名、来源路径等信息。
2、hive函数
Hive专门提供了解析URL的函数parse_url和parse_url_tuple

3、parse_url函数
parse_url函数是Hive中提供的最基本的url解析函数,可以根据指定的参数,从URL解析出对应的参数值进行返回,函数为普通的一对一函数类型。
-- 语法
parse_url(url, partToExtract[, key]) - extracts a part from a URL
Parts: HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO key
SELECT parse_url('http://facebook.com/path/p1.php?id=10086', 'HOST');
SELECT parse_url('http://facebook.com/path/p1.php?id=10086&name=allen', 'QUERY') ;
SELECT parse_url('http://facebook.com/path/p1.php?id=10086&name=allen', 'QUERY', 'name') ;
SELECT parse_url('http://192.168.10.41:9870/explorer.html#/user/hive/warehouse/testhive.db/singer2', 'QUERY', 'name') ;
0: jdbc:hive2://server4:10000> SELECT parse_url('http://facebook.com/path/p1.php?id=10086', 'HOST');
+---------------+
| _c0 |
+---------------+
| facebook.com |
+---------------+
0: jdbc:hive2://server4:10000> SELECT parse_url('http://facebook.com/path/p1.php?id=10086&name=allen', 'QUERY') ;
+----------------------+
| _c0 |
+----------------------+
| id=10086&name=allen |
+----------------------+
0: jdbc:hive2://server4:10000> SELECT parse_url('http://facebook.com/path/p1.php?id=10086&name=allen', 'QUERY', 'name') ;
+--------+
| _c0 |
+--------+
| allen |
+--------+
0: jdbc:hive2://server4:10000> SELECT parse_url('http://192.168.10.41:9870/explorer.html#/user/hive/warehouse/testhive.db/singer2', 'QUERY', 'name') ;
+-------+
| _c0 |
+-------+
| NULL |
+-------+
-- 如果想一次解析多个参数,需要使用多次函数
select
id,
parse_url(url,"HOST") as host,
parse_url(url,"PATH") as path,
parse_url(url,"QUERY") as query
from
tb_url;
4、parse_url_tuple函数
parse_url_tuple函数是Hive中提供的基于parse_url的url解析函数,可以通过一次指定多个参数,从URL解析出多个参数的值进行返回多列,函数为特殊的一对多函数类型,即通常所说的UDTF函数类型。
--语法
parse_url_tuple(url, partname1, partname2, ..., partnameN) - extracts N (N>=1) parts from a URL.
It takes a URL and one or multiple partnames, and returns a tuple.
--建表
create table tb_url(
id int,
url string
)row format delimited
fields terminated by '\t';
--加载数据
load data local inpath '/usr/local/bigdata/url.txt' into table tb_url;
select * from tb_url;
select parse_url_tuple(url,"HOST","PATH") as (host,path) from tb_url;
select parse_url_tuple(url,"PROTOCOL","HOST","PATH") as (protocol,host,path) from tb_url;
select parse_url_tuple(url,"PROTOCOL","HOST","PATH","QUERY") as (protocol,host,path,query) from tb_url;
0: jdbc:hive2://server4:10000> select parse_url_tuple(url,"HOST","PATH") as (host,path) from tb_url;
+-------------------+------------------+
| host | path |
+-------------------+------------------+
| facebook.com | /path/p1.php |
| tongji.baidu.com | /news/index.jsp |
| www.jdwz.com | /index |
| www.itcast.cn | /index |
+-------------------+------------------+
0: jdbc:hive2://server4:10000> select parse_url_tuple(url,"PROTOCOL","HOST","PATH") as (protocol,host,path) from tb_url;
+-----------+-------------------+------------------+
| protocol | host | path |
+-----------+-------------------+------------------+
| http | facebook.com | /path/p1.php |
| http | tongji.baidu.com | /news/index.jsp |
| http | www.jdwz.com | /index |
| http | www.itcast.cn | /index |
+-----------+-------------------+------------------+
0: jdbc:hive2://server4:10000> select parse_url_tuple(url,"PROTOCOL","HOST","PATH","QUERY") as (protocol,host,path,query) from tb_url;
+-----------+-------------------+------------------+--------------------+
| protocol | host | path | query |
+-----------+-------------------+------------------+--------------------+
| http | facebook.com | /path/p1.php | query=1 |
| http | tongji.baidu.com | /news/index.jsp | uuid=allen&age=18 |
| http | www.jdwz.com | /index | source=baidu |
| http | www.itcast.cn | /index | source=alibaba |
+-----------+-------------------+------------------+--------------------+
--通过parse_url_tuple实现了通过调用一个函数,就可以从URL中解析得到多个参数的值,但是当我们将原表的字段放在一起查询时,会出现以下问题
--parse_url_tuple
select
id,
parse_url_tuple(url,"HOST","PATH","QUERY") as (host,path,query)
from tb_url;
Error: Error while compiling statement: FAILED: SemanticException 3:52 AS clause has an invalid number of aliases. Error encountered near token 'path' (state=42000,code=40000)
--UDTF函数对于很多场景下有使用限制,例如:select时不能包含其他字段、不能嵌套调用、不能与group by等放在一起调用等等
--UDTF函数的调用方式,主要有以下两种方式:
--方式一:直接在select后单独使用
--方式二:与Lateral View放在一起使用
5、Lateral View侧视图与UDTF
Lateral View是一种特殊的语法,主要用于搭配UDTF类型功能的函数一起使用,用于解决UDTF函数的一些查询限制的问题。
侧视图的原理是将UDTF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。这样就避免了UDTF的使用限制问题。使用lateral view时也可以对UDTF产生的记录设置字段名称,产生的字段可以用于group by、order by 、limit等语句中,不需要再单独嵌套一层子查询。
官方链接:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LateralView
lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)*
fromClause: FROM baseTable (lateralView)*
select …… from tabelA lateral view UDTF(xxx) 别名 as col1,col2,col3……
--单个侧视图
select
a.id as id,
b.host as host,
b.path as path,
b.query as query
from tb_url a
lateral view parse_url_tuple(url,"HOST","PATH","QUERY") b as host,path,query;
0: jdbc:hive2://server4:10000> select
. . . . . . . . . . . . . . .> a.id as id,
. . . . . . . . . . . . . . .> b.host as host,
. . . . . . . . . . . . . . .> b.path as path,
. . . . . . . . . . . . . . .> b.query as query
. . . . . . . . . . . . . . .> from tb_url a
. . . . . . . . . . . . . . .> lateral view parse_url_tuple(url,"HOST","PATH","QUERY") b as host,path,query;
+-----+-------------------+------------------+--------------------+
| id | host | path | query |
+-----+-------------------+------------------+--------------------+
| 1 | facebook.com | /path/p1.php | query=1 |
| 2 | tongji.baidu.com | /news/index.jsp | uuid=allen&age=18 |
| 3 | www.jdwz.com | /index | source=baidu |
| 4 | www.itcast.cn | /index | source=alibaba |
+-----+-------------------+------------------+--------------------+
--多个单视图
select
a.id as id,
b.host as host,
b.path as path,
c.protocol as protocol,
c.query as query
from tb_url a
lateral view parse_url_tuple(url,"HOST","PATH") b as host,path
lateral view parse_url_tuple(url,"PROTOCOL","QUERY") c as protocol,query;
0: jdbc:hive2://server4:10000> select
. . . . . . . . . . . . . . .> a.id as id,
. . . . . . . . . . . . . . .> b.host as host,
. . . . . . . . . . . . . . .> b.path as path,
. . . . . . . . . . . . . . .> c.protocol as protocol,
. . . . . . . . . . . . . . .> c.query as query
. . . . . . . . . . . . . . .> from tb_url a
. . . . . . . . . . . . . . .> lateral view parse_url_tuple(url,"HOST","PATH") b as host,path
. . . . . . . . . . . . . . .> lateral view parse_url_tuple(url,"PROTOCOL","QUERY") c as protocol,query;
+-----+-------------------+------------------+-----------+--------------------+
| id | host | path | protocol | query |
+-----+-------------------+------------------+-----------+--------------------+
| 1 | facebook.com | /path/p1.php | http | query=1 |
| 2 | tongji.baidu.com | /news/index.jsp | http | uuid=allen&age=18 |
| 3 | www.jdwz.com | /index | http | source=baidu |
| 4 | www.itcast.cn | /index | http | source=alibaba |
+-----+-------------------+------------------+-----------+--------------------+
--Outer Lateral View
--1、如果UDTF不产生数据时,这时侧视图与原表关联的结果将为空
select
id,
url,
col1
from tb_url
lateral view explode(array()) et as col1;
0: jdbc:hive2://server4:10000> select
. . . . . . . . . . . . . . .> id,
. . . . . . . . . . . . . . .> url,
. . . . . . . . . . . . . . .> col1
. . . . . . . . . . . . . . .> from tb_url
. . . . . . . . . . . . . . .> lateral view explode(array()) et as col1;
+-----+------+-------+
| id | url | col1 |
+-----+------+-------+
+-----+------+-------+
--2、如果加上outer关键字以后,就会保留原表数据,类似于outer join
select
id,
url,
col1
from tb_url
lateral view outer explode(array()) et as col1;
0: jdbc:hive2://server4:10000> select
. . . . . . . . . . . . . . .> id,
. . . . . . . . . . . . . . .> url,
. . . . . . . . . . . . . . .> col1
. . . . . . . . . . . . . . .> from tb_url
. . . . . . . . . . . . . . .> lateral view outer explode(array()) et as col1;
+-----+----------------------------------------------------+-------+
| id | url | col1 |
+-----+----------------------------------------------------+-------+
| 1 | http://facebook.com/path/p1.php?query=1 | NULL |
| 2 | http://tongji.baidu.com/news/index.jsp?uuid=allen&age=18 | NULL |
| 3 | http://www.jdwz.com/index?source=baidu | NULL |
| 4 | http://www.itcast.cn/index?source=alibaba | NULL |
+-----+----------------------------------------------------+-------+
三、行列转换的常用函数
1、示例1:case when 函数-多行转多列
--语法
CASE
WHEN 条件1 THEN VALUE1
……
WHEN 条件N THEN VALUEN
ELSE 默认值 END
CASE 列
WHEN V1 THEN VALUE1
……
WHEN VN THEN VALUEN
ELSE 默认值 END
--case when 语法1
select
id,
case
when id < 2 then 'a'
when id = 2 then 'b'
else 'c'
end as caseName
from tb_url;
--case when 语法2
select
id,
case id
when 1 then 'a'
when 2 then 'b'
else 'c'
end as caseName
from tb_url;
0: jdbc:hive2://server4:10000> select
. . . . . . . . . . . . . . .> id,
. . . . . . . . . . . . . . .> case
. . . . . . . . . . . . . . .> when id < 2 then 'a'
. . . . . . . . . . . . . . .> when id = 2 then 'b'
. . . . . . . . . . . . . . .> else 'c'
. . . . . . . . . . . . . . .> end as caseName
. . . . . . . . . . . . . . .> from tb_url;
+-----+-----------+
| id | casename |
+-----+-----------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | c |
+-----+-----------+
0: jdbc:hive2://server4:10000> select
. . . . . . . . . . . . . . .> id,
. . . . . . . . . . . . . . .> case id
. . . . . . . . . . . . . . .> when 1 then 'a'
. . . . . . . . . . . . . . .> when 2 then 'b'
. . . . . . . . . . . . . . .> else 'c'
. . . . . . . . . . . . . . .> end as caseName
. . . . . . . . . . . . . . .> from tb_url;
+-----+-----------+
| id | casename |
+-----+-----------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | c |
+-----+-----------+
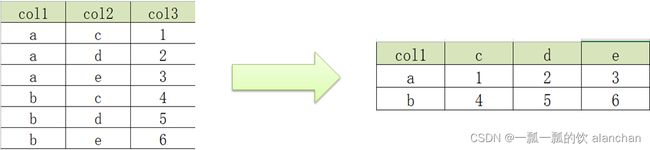
create table row2col1(
col1 string,
col2 string,
col3 int
)
row format delimited fields terminated by '\t';
--加载数据到表中
load data local inpath '/usr/local/bigdata/r2c1.txt' into table row2col1;
select * from row2col1;
0: jdbc:hive2://server4:10000> select * from row2col1;
+----------------+----------------+----------------+
| row2col1.col1 | row2col1.col2 | row2col1.col3 |
+----------------+----------------+----------------+
| a | c | 1 |
| a | d | 2 |
| a | e | 3 |
| b | c | 4 |
| b | d | 5 |
| b | e | 6 |
+----------------+----------------+----------------+
--
select
col1 as col1,
max(case col2 when 'c' then col3 else 0 end) as c,
max(case col2 when 'd' then col3 else 0 end) as d,
max(case col2 when 'e' then col3 else 0 end) as e
from row2col1
group by col1;
0: jdbc:hive2://server4:10000> select
. . . . . . . . . . . . . . .> col1 as col1,
. . . . . . . . . . . . . . .> max(case col2 when 'c' then col3 else 0 end) as c,
. . . . . . . . . . . . . . .> max(case col2 when 'd' then col3 else 0 end) as d,
. . . . . . . . . . . . . . .> max(case col2 when 'e' then col3 else 0 end) as e
. . . . . . . . . . . . . . .> from row2col1
. . . . . . . . . . . . . . .> group by col1;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-------+----+----+----+
| col1 | c | d | e |
+-------+----+----+----+
| a | 1 | 2 | 3 |
| b | 4 | 5 | 6 |
+-------+----+----+----+
2、示例2:concat函数-多行转单列

1)、concat函数
用于实现字符串拼接,不可指定分隔符
语法:concat(element1,element2,element3……)
特点:如果任意一个元素为null,结果就为null
select * from row2col1;
select concat("I","want","to","test");
select concat("I","want","to",null);
0: jdbc:hive2://server4:10000> select concat("I","want","to","test");
+--------------+
| _c0 |
+--------------+
| Iwanttotest |
+--------------+
0: jdbc:hive2://server4:10000> select concat("I","want","to",null);
+-------+
| _c0 |
+-------+
| NULL |
+-------+
2)、concat_ws函数
用于实现字符串拼接,可以指定分隔符
语法:concat_ws(SplitChar,element1,element2……)
特点:任意一个元素不为null,结果就不为null
select concat_ws("-","I","want","to","test");
select concat_ws("-","I","want","to",null);
0: jdbc:hive2://server4:10000> select concat_ws("-","I","want","to","test");
+-----------------+
| _c0 |
+-----------------+
| I-want-to-test |
+-----------------+
0: jdbc:hive2://server4:10000> select concat_ws("-","I","want","to",null);
+------------+
| _c0 |
+------------+
| I-want-to |
+------------+
3)、collect_list函数
用于将一列中的多行合并为一行,不进行去重
语法:collect_list(colName)
select collect_list(col1) from row2col1;
0: jdbc:hive2://server4:10000> select collect_list(col1) from row2col1;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+----------------------------+
| _c0 |
+----------------------------+
| ["a","a","a","b","b","b"] |
+----------------------------+
4)、collect_set函数
用于将一列中的多行合并为一行,并进行去重
语法:collect_set(colName)
select collect_set(col1) from row2col1;
0: jdbc:hive2://server4:10000> select collect_set(col1) from row2col1;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+------------+
| _c0 |
+------------+
| ["a","b"] |
+------------+
5)、实现多行转单列
create table row2col2(
col1 string,
col2 string,
col3 int
)
row format delimited fields terminated by '\t';
--加载数据到表中
load data local inpath '/usr/local/bigdata/r2c2.txt' into table row2col2;
select * from row2col2;
0: jdbc:hive2://server4:10000> select * from row2col2;
+----------------+----------------+----------------+
| row2col2.col1 | row2col2.col2 | row2col2.col3 |
+----------------+----------------+----------------+
| a | b | 1 |
| a | b | 2 |
| a | b | 3 |
| c | d | 4 |
| c | d | 5 |
| c | d | 6 |
+----------------+----------------+----------------+
describe function extended concat_ws;
--最终SQL实现
select
col1,
col2,
concat_ws(',', collect_list(cast(col3 as string))) as col3
from row2col2
group by col1, col2;
0: jdbc:hive2://server4:10000> select
. . . . . . . . . . . . . . .> col1,
. . . . . . . . . . . . . . .> col2,
. . . . . . . . . . . . . . .> concat_ws(',', collect_list(cast(col3 as string))) as col3
. . . . . . . . . . . . . . .> from row2col2
. . . . . . . . . . . . . . .> group by col1, col2;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-------+-------+--------+
| col1 | col2 | col3 |
+-------+-------+--------+
| a | b | 1,2,3 |
| c | d | 4,5,6 |
+-------+-------+--------+
3、示例3:union函数-多列转多行
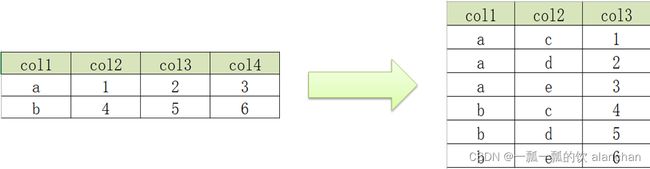
1)、union函数
将多个select语句结果合并为一个,且结果去重且排序
--语法
select_statement
UNION [DISTINCT]
select_statement
UNION [DISTINCT]
select_statement ...
--示例
select 'b','a','c'
union
select 'a','b','c'
union
select 'a','b','c';
0: jdbc:hive2://server4:10000> select 'b','a','c'
. . . . . . . . . . . . . . .> union
. . . . . . . . . . . . . . .> select 'a','b','c'
. . . . . . . . . . . . . . .> union
. . . . . . . . . . . . . . .> select 'a','b','c';
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+----------+----------+----------+
| _u2._c0 | _u2._c1 | _u2._c2 |
+----------+----------+----------+
| a | b | c |
| b | a | c |
+----------+----------+----------+
2)、union all函数
将多个select语句结果合并为一个,且结果不去重不排序
--语法
select_statement UNION ALL select_statement UNION ALL select_statement ...
--示例
select 'b','a','c'
union all
select 'a','b','c'
union all
select 'a','b','c';
0: jdbc:hive2://server4:10000> select 'b','a','c'
. . . . . . . . . . . . . . .> union all
. . . . . . . . . . . . . . .> select 'a','b','c'
. . . . . . . . . . . . . . .> union all
. . . . . . . . . . . . . . .> select 'a','b','c';
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+----------+----------+----------+
| _u1._c0 | _u1._c1 | _u1._c2 |
+----------+----------+----------+
| b | a | c |
| a | b | c |
| a | b | c |
+----------+----------+----------+
3)、实现多列转多行
create table col2row1
(
col1 string,
col2 int,
col3 int,
col4 int
)
row format delimited fields terminated by '\t';
--加载数据
load data local inpath '/usr/local/bigdata/c2r1.txt' into table col2row1;
select * from col2row1;
0: jdbc:hive2://server4:10000> select * from col2row1;
+----------------+----------------+----------------+----------------+
| col2row1.col1 | col2row1.col2 | col2row1.col3 | col2row1.col4 |
+----------------+----------------+----------------+----------------+
| a | 1 | 2 | 3 |
| b | 4 | 5 | 6 |
+----------------+----------------+----------------+----------------+
select col1, col2 as col3 from col2row1;
0: jdbc:hive2://server4:10000> select col1, col2 as col3 from col2row1;
+-------+-------+
| col1 | col3 |
+-------+-------+
| a | 1 |
| b | 4 |
+-------+-------+
0: jdbc:hive2://server4:10000> select col1, 'c' as col2, col2 as col3 from col2row1;
+-------+-------+-------+
| col1 | col2 | col3 |
+-------+-------+-------+
| a | c | 1 |
| b | c | 4 |
+-------+-------+-------+
--最终实现
select col1, 'c' as col2, col2 as col3 from col2row1
UNION ALL
select col1, 'd' as col2, col3 as col3 from col2row1
UNION ALL
select col1, 'e' as col2, col4 as col3 from col2row1;
0: jdbc:hive2://server4:10000> select col1, 'c' as col2, col2 as col3 from col2row1
. . . . . . . . . . . . . . .> UNION ALL
. . . . . . . . . . . . . . .> select col1, 'd' as col2, col3 as col3 from col2row1
. . . . . . . . . . . . . . .> UNION ALL
. . . . . . . . . . . . . . .> select col1, 'e' as col2, col4 as col3 from col2row1;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+-----------+-----------+
| _u1.col1 | _u1.col2 | _u1.col3 |
+-----------+-----------+-----------+
| a | c | 1 |
| a | d | 2 |
| a | e | 3 |
| b | c | 4 |
| b | d | 5 |
| b | e | 6 |
+-----------+-----------+-----------+
4、示例:explode函数-单列转多行
该explode函数在起他的章节中有详细的介绍,可参考。

用于将一个集合或者数组中的每个元素展开,将每个元素变成一行
--语法:explode( Map | Array)
select explode(split("a,b,c,d",","));
0: jdbc:hive2://server4:10000> select explode(split("a,b,c,d",","));
+------+
| col |
+------+
| a |
| b |
| c |
| d |
+------+
--创建表
create table col2row2(
col1 string,
col2 string,
col3 string
)
row format delimited fields terminated by '\t';
--加载数据
load data local inpath '/usr/local/bigdata/c2r2.txt' into table col2row2;
select * from col2row2;
0: jdbc:hive2://server4:10000> select * from col2row2;
+----------------+----------------+----------------+
| col2row2.col1 | col2row2.col2 | col2row2.col3 |
+----------------+----------------+----------------+
| a | b | 1,2,3 |
| c | d | 4,5,6 |
+----------------+----------------+----------------+
select explode(split(col3,',')) from col2row2;
0: jdbc:hive2://server4:10000> select explode(split(col3,',')) from col2row2;
+------+
| col |
+------+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
+------+
--SQL最终实现
select
col1,
col2,
lv.col3 as col3
from col2row2
lateral view explode(split(col3, ',')) lv as col3;
0: jdbc:hive2://server4:10000> select
. . . . . . . . . . . . . . .> col1,
. . . . . . . . . . . . . . .> col2,
. . . . . . . . . . . . . . .> lv.col3 as col3
. . . . . . . . . . . . . . .> from col2row2
. . . . . . . . . . . . . . .> lateral view explode(split(col3, ',')) lv as col3;
+-------+-------+-------+
| col1 | col2 | col3 |
+-------+-------+-------+
| a | b | 1 |
| a | b | 2 |
| a | b | 3 |
| c | d | 4 |
| c | d | 5 |
| c | d | 6 |
+-------+-------+-------+
以上,完成了hive在导入数据中对不同的字符分隔符的处理方式、URL的一般解析函数介绍和hive中对数据的行列转换示例。其中行列转换介绍了case when、concat、union和explode四个函数。