apache flink
Apache Flink是一个顶级Apache项目,允许统一分布式流和批处理。 Apache Flink的核心是流数据流引擎,该引擎为数据流上的分布式计算提供数据分发,通信和容错能力。
8月27日,湾区Apache Flink Meetup举行了另一个由MapR主持的活动。 这次,主要主题是使用Apache Flink进行分布式有状态流和图形分析。 我们很幸运地邀请了来自瑞典的三位特别嘉宾,他们是来自几个致力于研究和增强Apache Flink的学术机构的研究人员。 GyulaFóra是Apache Flink的项目管理委员会(PMC)成员,目前在瑞典计算机科学研究所担任研究员。 Vasia Kalavri是斯德哥尔摩KTH的一名博士研究生,也是Apache Flink的PMC成员,他专注于研究Apache Flink的图形处理API Gelly。 最后但并非最不重要的一点,Paris Carbone是瑞典皇家技术学院的分布式计算博士学位和Apache Flink的撰稿人。
此外,我们还受到来自MapR的特邀演讲者Ted Dunning的荣幸,他是MapR Technologies的首席应用程序架构师,也是Apache Mahout , Apache ZooKeeper和Apache Drill项目的提交者和PMC成员。 在孵化期间,他还是Apache Flink的导师。 泰德(Ted)分享了他在使用微批量处理方面的专业知识和知识,以及为解决这些问题需要提供真正的流媒体解决方案的内容。
像全球其他许多Apache Flink聚会一样,那天晚上开始了社区自上次聚会以来有关Apache Flink的更新 。 一些值得注意的新更新包括Job Manager仪表板的新UI,更多文档更新,Gelly Scala API,高可用性支持以及Java 6在master分支中的删除。 还宣布了有关Flink的第一次会议,称为“ Flink Forward”,将于10月12日至13日在德国柏林举行( http://flink-forward.org )。
在第一个演讲中,GyulaFóra讲了一个关于在几种不同流行流框架中的有状态分布式流处理的演讲(请参见此处的幻灯片 )。 他展示了每种框架用来支持有状态流处理概念的不同方法。 演讲讨论了状态处理的基本概念以及高级用例和示例。
数据的状态处理需要进行计算以在过渡到另一组数据期间维持状态。 有状态处理的一些示例包括对流数据的基于窗口的操作,用于计算模型与样本数据的拟合的机器学习以及用于进行模式识别(例如正则表达式)的有限状态机。
前面提到的有状态处理和算法的所有示例都依赖于一个通用模式,这是一个有状态运算符。 在谈话中,有状态运算符的本质定义为: f: (in, state) → (out, state')
上面的语句意味着有状态运算符是一个函数,它接收输入数据和当前状态,并生成具有处理系统更新状态的输出。 维持状态一致性以进行大规模状态流处理提出了一些挑战,因为它必须处理大规模的状态和输入数据,同时还要保持系统的正确性和容错性。
有状态流处理需要解决的一些重要问题包括:
- 表现力
- 一次语义
- 大输入的可扩展性
- 大型状态的可伸缩性
作为比较包含的一些框架包括Apache Storm,Apache Spark Streaming,Samza和最后但并非最不重要的Apache Flink。 Firgure1显示了Apache Storm(通过Trident API),Apache Spark Streaming和Samza支持有状态流处理的方法的优缺点的摘要。

图1 –支持状态处理的不同流框架的摘要
Apache Flink尝试获取好的部分并减少坏的部分以支持有状态流处理。 图2显示了幻灯片中的屏幕快照,其中列出了Apache Flink支持使其有用的所有功能。

图2 –在Apache Flink中完成的有状态流处理的工作清单
Apache Flink使用快速检查点机制支持一次精确的语义,该机制受Chandy-Lamport算法用于分布式快照的启发。 这使Apache Flink可以将状态存储为数据流的一部分,而不会覆盖记录,并且可以降低运行时的开销来存储和检索已保存的状态。
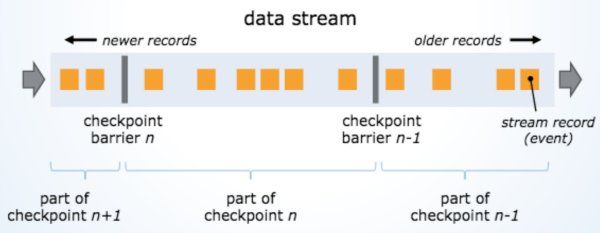
图3 – Apache Flink中使用的检查点算法摘要
接下来,Ted讨论了微分批处理(Apache Spark Streaming用于其流处理的方法)与真正的分流方法相比还不够好。 MapR的Ellen Friedman撰写了一篇有关此演讲的出色博客,我鼓励大家在这里阅读: https : //www.mapr.com/blog/apache-flink-new-way-handle-streaming-data 。
Vasia然后讨论了Apache Flink中称为Gelly的最新和最大的大规模图形处理API和库( 此处为幻灯片 )。 Vasia讨论了Apache Flink本机迭代支持以及其他显着功能,例如内存管理和快速序列化算法,这使其成为构建分布式大规模图形处理库的理想选择。 Vasica向观众展示了Gelly图形API,并举例说明了该算法如何有效解决问题的用例。
图形处理可以在许多情况下看到,例如在机器学习算法,运筹学和大数据分析管道中。 图4显示了谈话中的典型大数据分析管道。 在典型的流程中,需要将许多专用组件缝合在一起才能使整个过程正常工作。

图4 –涉及许多不同组件的大数据分析管道的典型示例
在构建数据处理系统时,在构建高度专业化组件与通用组件之间总是需要权衡取舍。 Apache Flink试图权衡通用和专门方法的优点和缺点之间的权衡。 图5显示了构建Graph处理框架的比较,图6显示了Apache Flink的大数据分析管道的外观,以使其易于管理。

图5 –通用组件和专用组件的比较

图6 –使用Apache Flink的大数据分析管道更友好的方法
在Apache Flink上构建Graph API的主要原因之一是本机迭代运算符,该运算符已优化为Apache Flink中的顶级操作。 因此,运行时引擎可以知道迭代执行,并可以进行优化以减少迭代之间的调度开销。 最重要的是,缓存和状态维护由核心框架自动处理。
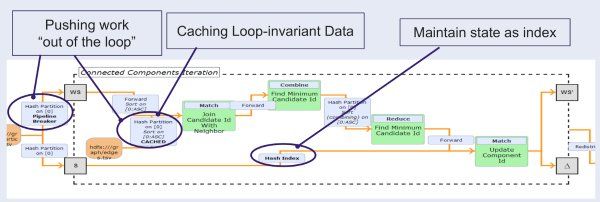
图7 –带有迭代的Apache Flink作业图
Gelly在Apache Flink核心之上提供了图形API,以允许对数据源的图形数据结构进行操作和虚拟化,并提供了分布式计算来处理大规模数据。 图8显示了Gelly API中可用的方法,图9显示了如何从Gelly开始的代码示例。

图8 –适用于图形元素的Gelly API列表

图9 –开始使用Gelly的代码示例
Paris Carbone分享了有关Apache Flink的研究预览( 幻灯片 ),其中包括对Flink上的增量检查点,窗口优化,机器学习管道设计和流图分析的介绍。 巴黎还介绍并展示了Karamel的演示视频 ,这是一个新项目,旨在帮助部署和协调Apache Flink等分布式系统。
我期待看到的新功能之一是用于流数据的机器学习管道。 这将使我们能够将机器学习算法应用于低延迟的无界数据,以及将某些机器学习算法即时应用于分类聚类。 另一个令人兴奋的可能性是流图处理,这将允许对流数据进行单遍图算法。

图10 –批处理与流式传输的机器学习算法的比较
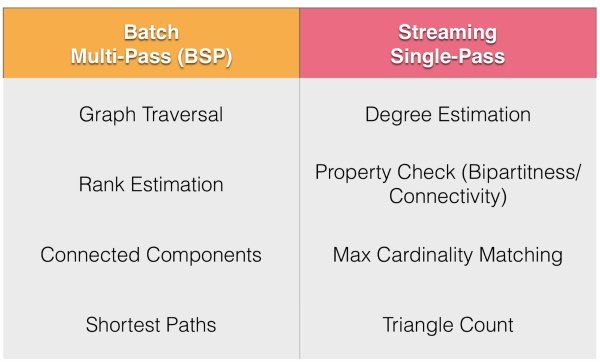
图11 –批处理与流处理的机器图算法比较
对于湾区Apache Flink爱好者来说,这是一次成功的聚会,也是一个非常激动人心的夜晚。 最重要的是,它引起了人们对Apache Flink作为下一代分布式流媒体平台的兴趣。
请注册并加入“海湾地区Apache Flink聚会”社区,以进行将来的知识共享,并听取来自更多出色演讲者的信息性演讲: http : //www.meetup.com/Bay-Area-Apache-Flink-Meetup
翻译自: https://www.javacodegeeks.com/2015/10/distributed-stream-and-graph-processing-with-apache-flink.html
apache flink