【多目标优化算法】自适应粒子群算法APSO,2009
自适应粒子群算法(APSO)
算法
PSO算法面临的两个最大的问题是收敛的速度和陷入局部最小值。针对此种情况,詹志辉教授基于标准的PSO提出了三个方式进行改进,分别是进化状态评估(ESE)、系统自适应参数(惯性权重、局部和全局加速度)和精英学习策略(ELS)。下面分别从这三个方面来介绍详细算法。
1. 进化状态评估(ELS)
ELS目的是为了收敛的状态进行评估和划分,为后面自适应参数提供基础。
step1: 计算每个粒子 i i i的相对于其他粒子的平均距离(欧式距离)
d i = 1 N − 1 ∑ j = 1 ; j ≠ i N ∑ k = 1 D ( x i k − x j k ) 2 d_ i= \frac {1}{N-1} \sum_{j=1; j\neq i}^{N} \sqrt{\sum_{k=1}^D(x_i^k-x_j^k)^2} di=N−11j=1;j̸=i∑Nk=1∑D(xik−xjk)2
其中N是种群的大小,D为问题的维数。
step2: 选出 d i d_i di中最好的值为 d g d_g dg,计算 d i d_i di中最大距离为 d m a x d_{max} dmax,最小距离为 d m i n d_{min} dmin,计算进化因子 f f f。
f = d g − d m i n d m a x − d m i n ∈ [ 0 , 1 ] f = \frac {d_g - d_{min}} {d_{max}-d_{min}} \in[0,1] f=dmax−dmindg−dmin∈[0,1]
step3: 根据上面计算的 f f f,使用是隶属函数判断进化此刻的状态。其中四个状态分别是S1:探索(Exploration)、S2:发现(Exploitation)、S3:收敛(Convergence)、S4:跳出(Jumping Out)。
S1:
μ s 1 ( f ) = { 0 , 0 ≤ f ≤ 0.4 5 × f − 2 , 0.4 < f ≤ 0.6 1 , 0.6 < f ≤ 0.7 − 10 × f + 8 , 0.7 < f ≤ 0.8 0 , 0.8 < f ≤ 1 \mu s_1(f) = \begin{cases} 0 , & 0 \leq f \leq 0.4 \\ 5 \times f -2 , & 0.4 < f \leq 0.6\\ 1, & 0.6 < f \leq 0.7\\ -10 \times f + 8, & 0.7 < f \leq 0.8\\ 0, & 0.8 < f \leq 1 \end{cases} μs1(f)=⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧0,5×f−2,1,−10×f+8,0,0≤f≤0.40.4<f≤0.60.6<f≤0.70.7<f≤0.80.8<f≤1
S2:
μ s 2 ( f ) = { 0 , 0 ≤ f ≤ 0.2 10 × f − 2 , 0.2 < f ≤ 0.3 1 , 0.3 < f ≤ 0.4 − 5 × f + 3 , 0.4 < f ≤ 0.6 0 , 0.6 < f ≤ 1 \mu s_2(f) = \begin{cases} 0 , & 0 \leq f \leq 0.2 \\ 10 \times f -2 , & 0.2 < f \leq 0.3\\ 1, & 0.3 < f \leq 0.4\\ -5 \times f + 3, & 0.4 < f \leq 0.6\\ 0, & 0.6 < f \leq 1 \end{cases} μs2(f)=⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧0,10×f−2,1,−5×f+3,0,0≤f≤0.20.2<f≤0.30.3<f≤0.40.4<f≤0.60.6<f≤1
S3:
μ s 3 ( f ) = { 1 , 0 ≤ f ≤ 0.1 − 5 × f + 1.5 , 0.1 < f ≤ 0.3 0 , 0.3 < f ≤ 1 \mu s_3(f) = \begin{cases} 1 , & 0 \leq f \leq 0.1 \\ -5 \times f +1.5 , & 0.1 < f \leq 0.3\\ 0, & 0.3 < f \leq 1 \end{cases} μs3(f)=⎩⎪⎨⎪⎧1,−5×f+1.5,0,0≤f≤0.10.1<f≤0.30.3<f≤1
S4:
μ s 4 ( f ) = { 0 , 0 ≤ f ≤ 0.7 − 5 × f − 3.5 , 0.7 < f ≤ 0.9 1 , 0.9 < f ≤ 1 \mu s_4(f) = \begin{cases} 0 , & 0 \leq f \leq 0.7 \\ -5 \times f -3.5 , & 0.7 < f \leq 0.9\\ 1, & 0.9 < f \leq 1 \end{cases} μs4(f)=⎩⎪⎨⎪⎧0,−5×f−3.5,1,0≤f≤0.70.7<f≤0.90.9<f≤1

上图为根据隶属度函数划分的状态,可以清晰看出各个状态区域,但是各个状态之间有重合的区域,为了解决决定 f f f的最终归属状态,在此使用了“singleton”方法。
在没有规则基准(rule base)的情况下:如果 f = 0.45 f = 0.45 f=0.45,可参考上图中的红线, μ s 2 ( f ) > μ s 1 ( f ) \mu s_2(f) > \mu s_1(f) μs2(f)>μs1(f),所以 f f f属于 S 2 S_2 S2状态。
在有规则基准(rule base)的情况下:
- 在上述 S 1 S_1 S1和 S 2 S_2 S2的选择中,如果前一个状态是 S 4 S_4 S4,则 f f f的状态属于 S 1 S_1 S1,根据规则基准的去模糊化得出。
- 如果上一个状态是 S 1 S_1 S1,由于不能过度切换状态,保持划分的稳定性,所以 f f f属于仍然属于 S 1 S_1 S1状态。
- 如果上一个状态是 S 2 S_2 S2或者 S 3 S_3 S3,使用“singleton”方法结合上述的规则基准会将 f f f划分到 S 2 S_2 S2状态。
上述中有规则基准的情况是全文中描述最模棱两可的部分。根据我的理解,规则基准(rule base)实质上是状态转换的PSO序列 S 1 = > S 2 = > S 3 = > S 4 = > S 1 . . . S_1 => S_2 =>S_3=>S_4=>S_1... S1=>S2=>S3=>S4=>S1...。
2. 系统自适应参数(w、c1、c2)
- 惯性权重w自适应:
惯性权重是PSO算法中平衡全局和局部的搜索能力, w w w应该在探索阶段很大,而在开发阶段减小。 w w w不是单纯的随着时间变化的,而应该随着进化状态的而变化,故 w w w应该与进化因子 f f f有如下的关系:
w ( f ) = 1 1 + 1.5 e − 2.6 f ∈ [ 0.4 , 0.9 ] ∀ f ∈ [ 0 , 1 ] w(f) = \frac 1 {1+1.5e^{-2.6f}} \in[0.4,0.9] \forall f \in[0,1] w(f)=1+1.5e−2.6f1∈[0.4,0.9]∀f∈[0,1]
本文中 w w w初始化设定是0.9,在跳出状态和探索状态下,较大的 f f f和较大的 w w w更有利于全局搜索,相反在开发状态和收敛状态下 f f f较小, w w w会减小更有利于局部的搜索。 - 加速因子的控制:
参数 C 1 C_1 C1是“个体认知”,促进该粒子获得它历史上最好的位置,有利于开发局部中最好的解,增加粒子群的多样性。
参数 C 2 C_2 C2是“社会认知”,它能推进粒子向全局中最好的区域收敛,加快收敛速度。
本文中 C 1 C_1 C1和 C 2 C_2 C2的初始化都为2.0,这两个参数也是根据进化状态来进行控制的:
策略1——在探索状态增加 C 1 C_1 C1,减小 C 2 C_2 C2:能帮助粒子探索自身的最好个体,强调个体认知的过程,避免粒子过早聚集在最好粒子周围,陷入局部最优。
策略2——在开发状态轻微增加 C 1 C_1 C1,轻微减小 C 2 C_2 C2:这个状态下,粒子使用局部信息,种群朝着可能的局部最优区域移动,因此,轻微增加 C 1 C_1 C1可以使 C 1 C_1 C1维持在一个较大的值,可以强调在 p B e s t i pBest_i pBesti(个体最优)周围的搜索和开发。全局最优的粒子 g B e s t i gBest_i gBesti并不一定在这个状态处在真正的最优区域。所以轻微减小 C 2 C_2 C2可避免算法过早收敛,陷入局部最优值。
策略3——在收敛状态轻微增加 C 1 C_1 C1,轻微增加 C 2 C_2 C2:在收敛状态下,群体似乎找到了全局的最优区域,因此,增加 C 2 C_2 C2主要为了引领其他粒子向可能的全局最优区域移动。此时 C 1 C_1 C1的值应该减小,这样有利于加来算法的收敛,但是使用12个基准函数显示,这样的策略会使两个参数过早的到值达上下边界(会在下文中介绍边界的大小定义)。这样可能会出现一种情况:即局部最优区域被当成全局最优区域,迅速收敛,最终陷入局部最优解。所以在此状态下,应该对 C 1 C_1 C1和 C 2 C_2 C2都进行轻微的增加。
策略4——在跳出状态减小 C 1 C_1 C1,增加 C 2 C_2 C2:全局最优粒子 g B e s t i gBest_i gBesti跳出局部最优,远离原来的聚类,跳向更优的区域。此时原来聚类的粒子会紧随这个领导者,尽可能快的飞向这个粒子的周围,所以一个值较大的 C 2 C_2 C2和较小的 C 1 C_1 C1可以获得这个结果。
关于加速度因子的上下边界:
为了使每一代中 C 1 C_1 C1和 C 2 C_2 C2和上一代的值变化不太突兀,所以引入了一个参数“加速度率” δ \delta δ,上一代的加速度减这一代的加速度绝对值不超过 δ \delta δ
∣ c i ( g + 1 ) − c i ( g ) ∣ ≤ δ , i = 1 , 2. |c_i(g+1) - c_i(g)| \leq \delta,i=1,2. ∣ci(g+1)−ci(g)∣≤δ,i=1,2.
实验显示 δ \delta δ的值做好从 [ 0.05 , 0.1 ] [0.05,0.1] [0.05,0.1]间隔中随机产生。我们使用 0.5 δ 0.5 \delta 0.5δ表示策略2和策略3中的“轻微改变”。如果 C 1 C_1 C1h和 C 2 C_2 C2的和超过了 4.0 4.0 4.0则进行如下的归一化处理
c i = c i c 1 + c 2 4.0 , i = 1 , 2. c_i = \frac{c_i}{c_1+c_2}4.0, i=1,2. ci=c1+c2ci4.0,i=1,2.
下面是使用ESE来动态变化 w w w和 c 1 c_1 c1和 c 2 c_2 c2部分的算法流程图

3. 精英学习策略(ELS)
在实验中的有些情况下,单纯使用ESE来动态更新 w w w和 c 1 c_1 c1和 c 2 c_2 c2,出现了算法不收敛的情况下,因此ELS是用于帮助全局最优粒子 g B e s t gBest gBest在收敛状态时跳出局部最优区域。推进 g B e s t gBest gBest向着一个潜在最好区域前进。
ELS选择了目标问题的其中一个维度进行变化,从统计学上意义来说,对于每一个维度选择的概率都是相同的,选择其中的第 d d d个维度,加入高斯扰动,过程如下:
P d = P d + ( X m a x d − X m i n d ) ⋅ G a u s s i a n ( μ , σ 2 ) P^d = P^d + (X_{max}^d-X_{min}^d) \cdot Gaussian(\mu, \sigma^2) Pd=Pd+(Xmaxd−Xmind)⋅Gaussian(μ,σ2)
其中 σ \sigma σ是“精英学习率”,随着进化的代数而变化
σ = σ m a x − ( σ m a x − σ m i n ) g G \sigma = \sigma_{max}-(\sigma_{max}-\sigma_{min}) \frac {g}{G} σ=σmax−(σmax−σmin)Gg
其中 σ m a x \sigma_{max} σmax和 σ m i n \sigma_{min} σmin的上界和下界根据经验显示 σ m a x = 1.0 \sigma_{max} = 1.0 σmax=1.0、 σ m i n = 0.1 \sigma_{min} =0.1 σmin=0.1
降低SD值,在算法早期阶段中,提供一个较高的学习率,为了算法跳出可能的局部最优值。
在后期阶段中,较小的学习率可以引导 g B e s t gBest gBest找到最终的最优解
ELS的流程图如下所示:
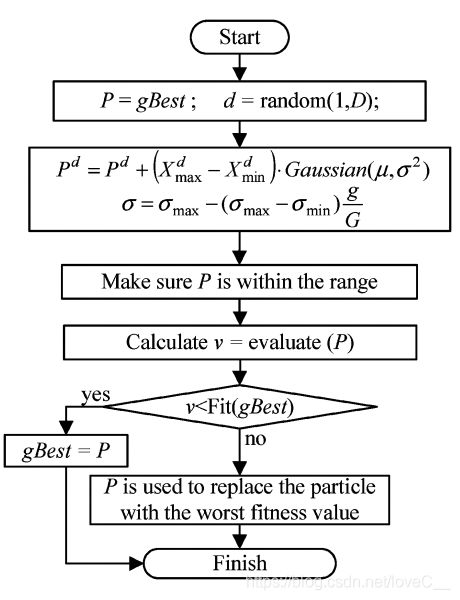
如果改变后的P适应度符合精度标准,则将P的值赋给 g B e s t gBest gBest,否则则用P的值去代替种群中的最差例子。
整个算法的流程图:

与标准的PSO对比,APSO算法只在初始化之后得第二步与PSO不同,在第二步中算法加入了通过ESE动态更新 w w w、 c 1 c_1 c1、 c 2 c_2 c2方法和ELS策略。
该算法在单峰函数和多峰函数中,大多表现优秀,且未占用过多的时间。由于免费午餐理论,一个算法无法在各个方面都保持最好的结果。