JVM 调优之 glibc 引发的内存泄露
malloc ? 这是申请内存的函数啊,为什么要申请这么多呢?难道没有释放? 于是想到用 pmap 命令看一下内存映射情况。
Pmap 提供了进程的内存映射,pmap 命令用于显示一个或多个进程的内存状态。其报告进程的地址空间和内存状态信息
执行了以下命令:
pmap -x 1 | sort -n -k3
复制代码
发现了一些端倪:

有一些 64M 左右的内存分配,且越来越多。
glibc
搞不懂了,于是 google 了一下。发现是有这一类问题由于涉及许多底层基础知识,这里就大概解析一下,有兴趣的读者可以查询更多资料了解:
目前大部分服务端程序使用 glibc 提供的 malloc/free 系列函数来进行内存的分配。
Linux 中 malloc 的早期版本是由 Doug Lea 实现的,它有一个严重问题是内存分配只有一个分配区(arena),每次分配内存都要对分配区加锁,分配完释放锁,导致多线程下并发申请释放内存锁的竞争激烈。arena 单词的字面意思是「舞台;竞技场」
于是修修补补又一个版本,你不是多线程锁竞争厉害吗,那我多开几个 arena,锁竞争的情况自然会好转。
Wolfram Gloger 在 Doug Lea 的基础上改进使得 Glibc 《一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义》无偿开源 威信搜索公众号【编程进阶路】 的 malloc 可以支持多线程,这就是 ptmalloc2。在只有一个分配区的基础上,增加了非主分配区 (non main arena),主分配区只有一个,非主分配可以有很多个
当调用 malloc 分配内存的时候,会先查看当前线程私有变量中是否已经存在一个分配区 arena。如果存在,则尝试会对这个 arena 加锁如果加锁成功,则会使用这个分配区分配内存
如果加锁失败,说明有其它线程正在使用,则遍历 arena 列表寻找没有加锁的 arena 区域,如果找到则用这个 arena 区域分配内存。
主分配区可以使用 brk 和 mmap 两种方式申请虚拟内存,非主分配区只能 mmap。glibc 每次申请的虚拟内存区块大小是 64MB,glibc 再根据应用需要切割为小块零售。
这就是 linux 进程内存分布中典型的 64M 问题,那有多少个这样的区域呢?在 64 位系统下,这个值等于 8 * number of cores,如果是 4 核,则最多有 32 个 64M 大小的内存区域。
glibc 从 2.11 开始对每个线程引入内存池,而我们使用的版本是 2.17,可以通过下面的命令查询版本号
查看 glibc 版本
ldd --version
复制代码
问题解决
通过服务器上一个参数 MALLOC_ARENA_MAX 可以控制最大的 arena 数量
export MALLOC_ARENA_MAX=1
复制代码
由于我们使用的是 docker 容器,于是是在 docker 的启动参数上添加的。
容器重启后发现果然没有了 64M 的内存分配。
but RSS 依然还在增长,虽然这次的增长好像更慢了。于是再次 google 。(事后在其他环境拉长时间观察,其实是有效的,短期内虽然有增长,但后面还会有回落)
查询到可能是因为 glibc 的内存分配策略导致的碎片化内存回收问题,导致看起来像是内存泄露。那有没有更好一点的对碎片化内存的 malloc 库呢?业界常见的有 google 家的 tcmalloc 和 facebook 家的 jemalloc。
tcmalloc
安装
yum install gperftools-libs.x86_64
复制代码
使用 LD_PRELOAD 挂载
export LD_PRELOAD=“/usr/lib64/libtcmalloc.so.4.4.5”
复制代码
注意 java 应用要重启,经过我的测试使用 tcmalloc RSS 内存依然在涨,对我无效。
jemalloc
安装
yum install epel-release -y
yum install jemalloc -y
复制代码
使用 LD_PRELOAD 挂载
export LD_PRELOAD=“/usr/lib64/libjemalloc.so.1”
复制代码
使用 jemalloc 后,RSS 内存呈周期性波动,波动范围约 2 个百分点以内,基本控制住了。
jemalloc 原理
与 tcmalloc 类似,每个线程同样在<32KB 的时候无锁使用线程本地 cache。
Jemalloc 在 64bits 系统上使用下面的 size-class 分类:
-
Small: [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840]
-
Large: [4 KiB, 8 KiB, 12 KiB, …, 4072 KiB]
-
Huge: [4 MiB, 8 MiB, 12 MiB, …]
small/large 对象查找 metadata 需要常量时间, huge 对象通过全局红黑树在对数时间内查找。
虚拟内存被逻辑上分割成 chunks(默认是 4MB,1024 个 4k 页),应用线程通过 round-robin 算法在第一次 malloc 的时候分配 arena, 每个 arena 都是相互独立的,维护自己的 chunks, chunk 切割 pages 到 small/large 对象。free() 的内存总是返回到所属的 arena 中,而不管是哪个线程调用 free()。
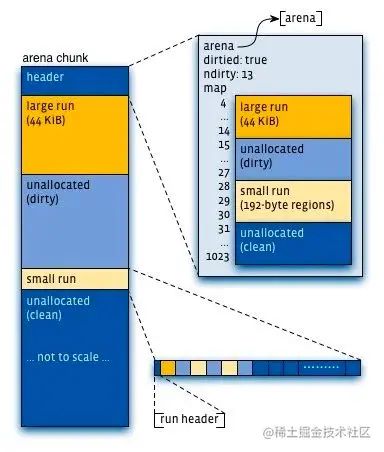
上图可以看到每个 arena 管理的 arena chunk 结构, 开始的 header 主要是维护了一个 page map(1024 个页面关联的对象状态), header 下方就是它的页面空间。 Small 对象被分到一起, metadata 信息存放在起始位置。 large chunk 相互独立,它的 metadata 信息存放在 chunk header map 中。
通过 arena 分配的时候需要对 arena bin(每个 small size-class 一个,细粒度)加锁,或 arena 本身加锁。并且线程 cache 对象也会通过垃圾回收指数退让算法返回到 arena 中。
