GPT怎样教我用Python进行数据可视化
文章目录
- GPT怎样教我用Python进行数据可视化
-
- matplotlib
- pyecharts
- 总结
GPT怎样教我用Python进行数据可视化
首先,我们先看一下这段代码,这是我之前写来读取excel文件中xx大学在各个类别中的获奖情况,并保存在一个txt文件里面,代码逻辑比较简单,理解起来应该不难。
import xlrd
data = xlrd.open_workbook('xxxx.xls') # 打开xls文件
table = data.sheet_by_index(0) # 通过索引获取表格
# 初始化奖项字典
awards_dict = {
"一等奖": 0,
"二等奖": 0,
"三等奖": 0
}
# 初始化科目字典
subjects_dict = {}
# 遍历表格的每一行,跳过表头
for i in range(1, table.nrows):
row = table.row_values(i)
# 是xx大学才进行处理
if row[2] == 'xx大学':
# 转为小写,避免首字母不一样带来的误判
subject = row[4].lower()
# 获得的奖项
award = row[5]
# 加入字典
if subject not in subjects_dict:
subjects_dict[subject] = awards_dict.copy()
subjects_dict[subject][award] += 1
# 将结果写入文件
with open("result.txt", "w") as f:
for subject, awards in subjects_dict.items():
f.write(f"{subject}\n")
for award, count in awards.items():
f.write(f"{award}: {count}\n")
f.write("\n")
运行结果:
c/c++程序设计大学a组
一等奖: 0
二等奖: 1
三等奖: 0c/c++程序设计大学b组
一等奖: 23
二等奖: 51
三等奖: 40java软件开发研究生组
一等奖: 0
二等奖: 1
三等奖: 0java软件开发大学b组
一等奖: 4
二等奖: 8
三等奖: 12python程序设计大学b组
一等奖: 2
二等奖: 6
三等奖: 5web应用开发大学组
一等奖: 1
二等奖: 1
三等奖: 0
matplotlib
然后我们要求chatGPT根据上面的代码,用直方图展示xx大学在各个类别中的获奖情况,也就是去对这个文本文件进行数据可视化,于是chatGPT就生成了以下的代码。
import xlrd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体,不然显示不了中文
data = xlrd.open_workbook('xxxx.xls') # 打开xls文件
table = data.sheet_by_index(0) # 通过索引获取表格
# 初始化奖项字典
awards_dict = {
"一等奖": 0,
"二等奖": 0,
"三等奖": 0
}
# 初始化科目字典
subjects_dict = {}
# 遍历表格的每一行,跳过表头
for i in range(1, table.nrows):
row = table.row_values(i)
if row[2] == 'xx大学':
# 转为小写,避免首字母不一样带来的误判
subject = row[4].lower()
award = row[5]
if subject not in subjects_dict:
subjects_dict[subject] = awards_dict.copy()
subjects_dict[subject][award] += 1
# 直方图展示xx大学在各个类别中的获奖情况
x_labels = subjects_dict.keys()
x = range(len(x_labels))
# 提取各个奖项的数量
y_first = [subjects_dict[subject]['一等奖'] for subject in x_labels]
y_second = [subjects_dict[subject]['二等奖'] for subject in x_labels]
y_third = [subjects_dict[subject]['三等奖'] for subject in x_labels]
# 设置颜色
color_first = 'skyblue'
color_second = 'lightgreen'
color_third = 'lightcoral'
# 绘制直方图
plt.bar(x, y_first, width=0.2, align='center', label='一等奖', color=color_first)
plt.bar(x, y_second, width=0.2, align='edge', label='二等奖', color=color_second)
plt.bar(x, y_third, width=-0.2, align='edge', label='三等奖', color=color_third)
# 添加辅助线
plt.axhline(0, color='gray', linewidth=0.8)
plt.axvline(-0.5, color='gray', linewidth=0.8)
plt.xlabel('类别')
plt.ylabel('获奖数量')
plt.title('xx大学在各个类别中的获奖情况')
plt.xticks(x, x_labels)
plt.legend()
# 调整图例位置和边框样式
plt.legend(loc='upper right', frameon=False)
# 设置图形背景色
plt.gca().set_facecolor('whitesmoke')
# 调整图形布局
plt.tight_layout()
plt.show()
运行代码,于是得到以下结果:
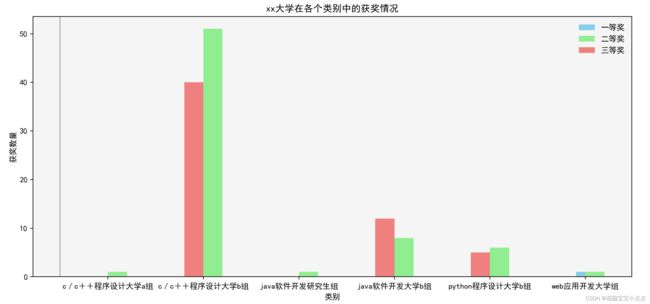
乍一看,好像没啥问题,但是细看会发现大问题,就是我们无法正确显示一等奖的个数,一开始我还以为是统计的出了问题,后来检查后并不是,原因还是出现在显示上,看以下代码:
# 绘制直方图
plt.bar(x, y_first, width=0.2, align='center', label='一等奖', color=color_first)
plt.bar(x, y_second, width=0.2, align='edge', label='二等奖', color=color_second)
plt.bar(x, y_third, width=-0.2, align='edge', label='三等奖', color=color_third)
一等奖和二等奖的x和width都是一样的,所以可能出现了重合,看来这里有点小问题,于是我们进行一点微调,然后就有了后面的代码:
import xlrd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体,不然显示不了中文
data = xlrd.open_workbook('xxxx.xls') # 打开xls文件
table = data.sheet_by_index(0) # 通过索引获取表格
# 初始化奖项字典
awards_dict = {
"一等奖": 0,
"二等奖": 0,
"三等奖": 0
}
# 初始化科目字典
subjects_dict = {}
# 遍历表格的每一行,跳过表头
for i in range(1, table.nrows):
row = table.row_values(i)
if row[2] == 'xx大学':
# 转为小写,避免首字母不一样带来的误判
subject = row[4].lower()
award = row[5]
if subject not in subjects_dict:
subjects_dict[subject] = awards_dict.copy()
subjects_dict[subject][award] += 1
# 直方图展示xx大学在各个类别中的获奖情况
x_labels = subjects_dict.keys()
x = np.arange(len(x_labels)) # 使用numpy的arange生成连续的横坐标值
# 提取各个奖项的数量
y_first = [subjects_dict[subject]['一等奖'] for subject in x_labels]
y_second = [subjects_dict[subject]['二等奖'] for subject in x_labels]
y_third = [subjects_dict[subject]['三等奖'] for subject in x_labels]
# 设置颜色
color_first = 'skyblue'
color_second = 'lightgreen'
color_third = 'lightcoral'
# 绘制直方图
plt.bar(x, y_third, width=0.2, align='center', label='三等奖', color=color_third)
plt.bar(x + 0.2, y_second, width=0.2, align='center', label='二等奖', color=color_second)
plt.bar(x - 0.2, y_first, width=0.2, align='center', label='一等奖', color=color_first)
plt.xlabel('类别')
plt.ylabel('获奖数量')
plt.title('xx大学在各个类别中的获奖情况')
plt.xticks(x, x_labels)
plt.legend()
# 调整图例位置和边框样式
plt.legend(loc='upper right', frameon=False)
# 设置图形背景色
plt.gca().set_facecolor('whitesmoke')
# 调整图形布局
plt.tight_layout()
plt.show()
运行结果如下所示,显示正常。

pyecharts
但是我们不会就此停下,刚好笔者接触过另外一个数据可视化库pyecharts,所以问问GPT能不能基于这个库来优化一下。
pyecharts 是一个用于生成 Echarts 图表的类库。 Echarts 是百度开源的一个数据可视化 JS 库。
import xlrd
from pyecharts.charts import Bar
from pyecharts import options as opts
data = xlrd.open_workbook('xxxx.xls') # 打开xls文件
table = data.sheet_by_index(0) # 通过索引获取表格
# 初始化奖项字典
awards_dict = {
"一等奖": 0,
"二等奖": 0,
"三等奖": 0
}
# 初始化科目字典
subjects_dict = {}
# 遍历表格的每一行,跳过表头
for i in range(1, table.nrows):
row = table.row_values(i)
if row[2] == 'xx大学':
# 转为小写,避免首字母不一样带来的误判
subject = row[4].lower()
award = row[5]
if subject not in subjects_dict:
subjects_dict[subject] = awards_dict.copy()
subjects_dict[subject][award] += 1
# 直方图展示xx大学在各个类别中的获奖情况
x_labels = subjects_dict.keys()
# 提取各个奖项的数量
y_first = [subjects_dict[subject]['一等奖'] for subject in x_labels]
y_second = [subjects_dict[subject]['二等奖'] for subject in x_labels]
y_third = [subjects_dict[subject]['三等奖'] for subject in x_labels]
# 使用 Pyecharts 绘制直方图
bar = (
Bar()
.add_xaxis(list(x_labels))
.add_yaxis('一等奖', y_first)
.add_yaxis('二等奖', y_second)
.add_yaxis('三等奖', y_third)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)),
yaxis_opts=opts.AxisOpts(name='获奖数量'),
title_opts=opts.TitleOpts(title='xx大学在各个类别中的获奖情况'),
legend_opts=opts.LegendOpts(pos_right='5%', pos_top='20%')
)
)
# 生成图表并保存为 HTML 文件
bar.render('bar_chart.html')
运行结果如下所示:

到这里,就基本就达到我的要求了,甚至超出了我的期望,于是我也没继续追问了,当然肯定还有继续优化的空间,但是也算是基本完成了任务。
总结
虽然笔者接触过一点matplotlib,但是因为长期未使用,用的不算很熟练,于是就想起来用GPT帮我完成基本设计。然后在用的过程中,与他交流,不断向他学习,收获很大,并且本人不会pyecharts库,但是在GPT的介绍下也算有了一些简单的认知,所以把GPT比作一个百问不厌的老师毫不过分,但是还是希望大家能自己主动思考。