RocketMQ5.x版本延迟消息被重放问题调查
一、问题
由于目标计划是将集群从4.9.x逐步升级至5.x,故目前先对一些不重要的集群进行升级测试。
但是在4.x的broker陆续升级至5.x的过程中,发现了延迟消息被重放的问题。
具体如下:
在升级时刷新后台监控,发现竟然有写入量:

即上图(因为当时的问题场景没有截图,所以上图只是提供参考)红框中的生产和消费项并不为0,等启动完毕后,变为0,感觉有些诡异。
之后,查询了该集群的topic情况,这一查竟然发现好多topic出现了堆积的情况。
二、调查
1 堆积情况:
经过调查所有topic,这些topic于几日前已经不进行生产和消费,也就是生产消费完成了。
而发现堆积的topic都是之前消费有失败的,产生了重试消息的,而这些重试消息也是被消费完了的。
而我将4.x的一个broker升级到5.x后,重试的消息完全被重放了,类似如下截图:
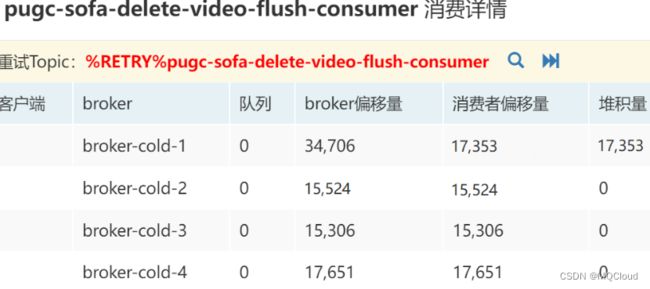
%RETRY%pugc-sofa-delete-video-flush-consumer这个topic在broker-cold-1上的消息量变成了34706,而消费量为17353,堆积量跟消费量相等。
我查看了好几个topic,发现只要有重试消息的,都存在这个情况,也就是重试消息被重写了一遍!
2 日志调查
经过拿其中一个消费者:pugc-sofa-delete-video-flush-consumer进行调查,根据该消费者最后在日志中出现的位置,可以看到:
2023-06-05 15:25:18 ERROR NettyServerNIOSelector_3_2 - RemotingCommand [code=11, language=JAVA, version=395, opaque=166848104, flag(B)=0, remark=null, extFields={queueId=0, maxMsgNums=32, sysFlag=3, suspendTimeoutMillis=15000, commitOffset=17353, topic=%RETRY%pugc-sofa-delete-video-flush-consumer, queueOffset=17353, expressionType=TAG, subVersion=1685949771302, consumerGroup=pugc-sofa-delete-video-flush-consumer}, serializeTypeCurrentRPC=JSON]
commitOffset=17353,该消费者在2023-06-05消费重试消息时,消费偏移量已经达到17353。
这进一步确认了,就是因为我升级5.x导致了重试消息被重写了一遍。
我进一步走查了5.x的broker启动时关于%RETRY%pugc-sofa-delete-video-flush-consumer的日志,如下:
store.log:2023-06-07 09:39:13 INFO main - load /opt/mqcloud/broker-cold-1/data/consumequeue/%RETRY%pugc-sofa-delete-video-flush-consumer/0/00000000000000000000 OK
store.log:2023-06-07 09:39:13 INFO main - load consume queue %RETRY%pugc-sofa-delete-video-flush-consumer-0 OK
store.log:2023-06-07 09:39:14 INFO main - recover current consume queue file over, /opt/mqcloud/broker-cold-1/data/consumequeue/%RETRY%pugc-sofa-delete-video-flush-consumer/0/00000000000000000000 0 0 0
store.log:2023-06-07 09:39:14 INFO main - recover current consume queue over /opt/mqcloud/broker-cold-1/data/consumequeue/%RETRY%pugc-sofa-delete-video-flush-consumer/0/00000000000000000000 347060
根据最后一条的347060,调查对应代码简化如下:
public void recover() {
final List mappedFiles = this.mappedFileQueue.getMappedFiles();
if (!mappedFiles.isEmpty()) {
int mappedFileSizeLogics = this.mappedFileSize;
long mappedFileOffset = 0;
while (true) {
for (int i = 0; i < mappedFileSizeLogics; i += CQ_STORE_UNIT_SIZE) {
long offset = byteBuffer.getLong();
int size = byteBuffer.getInt();
long tagsCode = byteBuffer.getLong();
if (offset >= 0 && size > 0) {
mappedFileOffset = i + CQ_STORE_UNIT_SIZE;
} else {
log.info("recover current consume queue file over, " + mappedFile.getFileName() + " "
+ offset + " " + size + " " + tagsCode);
break;
}
}
if (mappedFileOffset == mappedFileSizeLogics) {
} else {
log.info("recover current consume queue over " + mappedFile.getFileName() + " "
+ (processOffset + mappedFileOffset));
break;
}
}
}
}
347060代表的是重试队列的物理偏移量,由于consumequeue每个数据单元大小是20个字节,那么消息量为347060/20=17353。
也就是说,在broker初始化恢复数据时,重试队列的数据量还是对的。
而broker启动整个过程包括,创建->初始化->数据恢复->启动,如果数据重复,就很可能出现在启动过程中。
3 走查延迟队列代码
通过上面的调查,基本可以确认,重试队列数据刚加载时是对的,应该是启动后内部的延迟队列进行重新消费导致的。
随即对比5.x和4.x的延迟队列相关代码,至到对比到下面的代码:

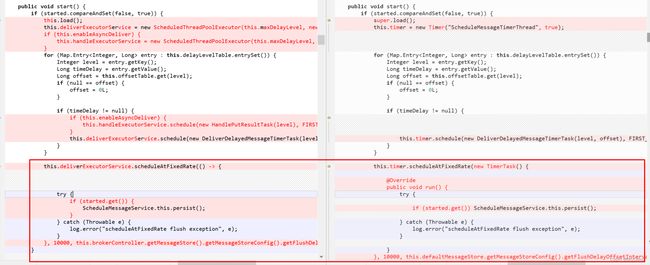
即5.x的ScheduleMessageService竟然在构造方法中添加了一个持久化的定时任务,而且在start方法中又添加了一个同样的持久化的定时任务。
而4.x只有在start时,先执行load(),再执行持久化定时任务。
那么5.x的持久化任务在构造方法中延迟10秒就会执行,如果10秒内,数据还没有加载完成,它执行persist必然会把存在的delayOffset.json覆盖。
再start时,执行load,加载的offset就是空的,那就会认为没有消费过,进行数据重放。
接着再查看store.log的日志,如下:


从2023-06-07 09:39:13启动,至到2023-06-07 09:39:24才刚恢复完数据,那么调用start方法肯定在10秒之后了。
而在测试环境中,broker没多少数据,10秒内肯定已经启动完了,所以没有发现这个问题,而线上环境数据量一般都是上百G,通常启动比较慢。
三、解决
所以定位到问题所在,就好改了,直接把5.x中ScheduleMessageService构造方法中的定时持久化代码移除即可。