Python爬取猎聘网招聘数据+标签云可视化
文章目录
目录
文章目录
写在前面
一、分析要爬取的数据
二、利用Python爬取数据
1.爬取标题超链接
2.页面数据解析
3.获取详情页数据
4.写入CSV文件
三、数据处理
四、利用jieba库进行分词
五、生成词云
六、完结撒花,康康效果吧!
七、写在最后
写在前面
本文主要是自己的大数据分析与可视化课程的课堂展示内容。写的过程中遇到了一堆坑坑洼洼,遂来记录一波~
开发工具是pycharm和vscode
Python版本是3.7.4
一、分析要爬取的数据
目的说明:爬取猎聘网计算机软件行业的标题超链接,根据超链接进入每一个详情页面读取岗位的详细信息。
首先进入猎聘的搜索网站,该网站不登陆也可以查看信息,这里我选取要爬取的数据为开发岗信息。在行业分类中选择【计算机软件】,在搜索栏中输入【开发】,点击F12进入开发者模式,在【Network】中找到要爬取的参数,由于每一页只显示40条数据,总共显示10页,那我就对这400条数据进行了爬取。
 获取爬取网页参数
获取爬取网页参数
 获取翻页爬取参数
获取翻页爬取参数
接着分析要爬取的标题链接的定位,在【Elements】中选择标题,查看其所在位置
 标题超链接定位
标题超链接定位
爬取全部的标题链接后,遍历爬取每一条链接中的信息,包括职位名称、职位需求和福利待遇,方法同上。
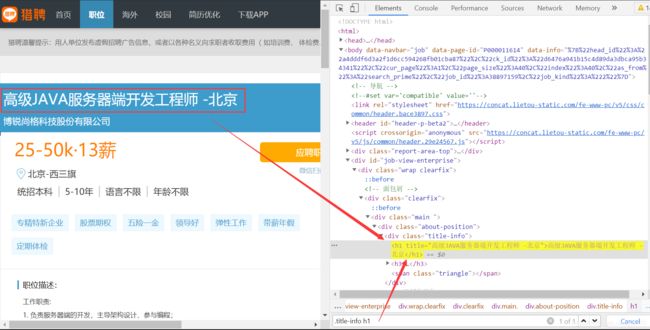 标题定位
标题定位
 职位需求定位
职位需求定位
 福利待遇定位
福利待遇定位
二、利用Python爬取数据
1.爬取标题超链接
说明:利用Python按照上一步的分析将标题超链接爬取下来
导入的库:
import requests import parsel # 可以使用CSS进行内容的选取 import csv import time import random
处理翻页:涉及到翻页爬取,通过查看每一页的超链接参数,可以发现只需要将参数【curPage】设置为0~9即能爬取全部数据,于是采用一个循环函数爬取了全部岗位的超链接。
处理反反爬:在爬取过程中,为了爬虫程序不被网站检测到并杀死,使用了User-Agent进行模拟浏览器访问,选用了多个User-Agent放入列表中,每次爬取时随机选取一个进行伪装;也设置每次爬虫间隔时长为1s写入循环函数;每次被限制爬虫后会重新发送请求。尽管如此,还是有未爬取到的数据,最终爬下来的数据是253条。
有一说一,这里用到的User-Agent列表随机选择,不如Chrome自带的User-Agent好用,可能是有失效的User-Agent吧。
page in range(0, 10):
page += 1
print('正在爬取第%d页' % page)
url = 'https://www.liepin.com/zhaopin/'
# 刚才从浏览器获取的参数,注意这里的参数有时效性
params = {
'pageSize': '40',
'sortFlag': '15',
'degradeFlag': '0',
'industries': '010',
'key': '开发',
'siTag': 'P_PD4mpoESwRw - gPKiaJbg~Uu4d3oMo - zE - ddoy0_BJog',
'd_sfrom': 'search_prime',
'd_ckId': '55bb20be1f8a86dba97bd9ae54181a0f',
'd_curPage': '1',
'd_pageSize': '40',
'd_headId': '94cc67e351298a86169bb7a768ab5392',
'curPage': page # 传入分页参数
}
headers = {
'User_Agent': '用户自己浏览器的UA'
}
response = requests.get(url=url, params=params, headers=headers)2.页面数据解析
# 数据解析,获取招聘数据的详情页url地址
selector = parsel.Selector(response.text)
hrefs = selector.css('.job-content .sojob-list li .job-info h3 a::attr(href)').getall() # 获取所有的数据3.获取详情页数据
说明:依次遍历刚才爬取的超链接,进入相应的页面获取所需数据
def script(link):
try:
time.sleep(1)
# 对详情页url地址发送请求,获取网页源代码数据
response_item = requests.get(url=link, headers=get_headers())
# print(response_item.text)
selector_item = parsel.Selector(response_item.text)
title_item = selector_item.css('.title-info h1::text').get() # 爬取下来的数据为list格式
qualifications_item = selector_item.css('.job-qualifications span::text').getall()
treatment_item = selector_item.css('.comp-tag-box .comp-tag-list li span::text').getall() # 将list转为str
qualifications_string = '|'.join(qualifications_item)
treatment_string = '|'.join(treatment_item)
print(title_item)
print(qualifications_string)
print(treatment_string)
dit = {
'标题': title_item, # 记录到csv文件中
'基本要求': qualifications_string,
'福利': treatment_string
}
csv_writer.writerow(dit) # 一行一行追加写入
except:
script(link)4.写入CSV文件
在记录到CSV文件时,使用utf-8编码会在外部打开后存在乱码,解决方案有两种:
①encoding='utf_8_sig'
②在文件目录中用记事本打开,另存为带有BOM的UTF-8编码格式文件
f = open('猎聘详情数据.csv', mode='a', encoding='utf-8', newline='') # 以追加形式保存
# f = open('猎聘详情数据.csv', mode='a', encoding='utf_8_sig', newline='') # 以追加形式保存,encoding='utf_8_sig'打开后无乱码
csv_writer = csv.DictWriter(f, fieldnames=['标题', '基本要求', '福利'])
csv_writer.writeheader()三、数据处理
说明:由于爬取的数据分为了职位名称、职位需求和福利待遇三类,需要将数据按照不同标题存入不同的txt文件进行后续的分词、生成词云等操作。
导入pandas库,读取文件,使用dropna()去除NaN数据
使用iloc[:, 0],iloc[:, 1],iloc[:, 2]分别取出第一列、第二列、第三列的数据,利用.values获取每一列的数据值,此时数据为数组,使用tolist()方法将数据转为列表,再将列表数据转为字符串分别存入三个txt文件中,完成了原始数据的提取
"""
处理csv文件,将标题、基本要求和福利信息分别保存到三个.txt文件中
"""
import pandas as pd
input = pd.read_csv('猎聘详情数据.csv')
input = input.dropna() # 去除NaN数据
titles_col = input.iloc[:, 0]
qualifications_col = input.iloc[:, 1]
treatment_col = input.iloc[:, 2]
# titles = titles_col.values #
titles = titles_col.values.tolist() # 将数组转为列表
qualifications = qualifications_col.values.tolist()
treatment = treatment_col.values.tolist()
"""
TypeError: sequence item 3: expected str instance, float found
titles_output = open('titles.txt', 'w', encoding='utf-8')
titles_output.write('\n'.join(titles)) # 将序列中的元素以指定的字符连接生成一个新的字符串
titles_output.close()
"""
titles_output = open('titles.txt', 'w', encoding='utf-8')
titles_output.write('\n'.join(map(str, titles))) # 将序列中的元素以指定的字符连接生成一个新的字符串
titles_output.close()
qualifications_output = open('qualifications.txt', 'w', encoding='utf-8')
qualifications_output.write('\n'.join(str(i) for i in qualifications)) # 将序列中的元素以指定的字符连接生成一个新的字符串
qualifications_output.close()
treatment_output = open('treatment.txt', 'w', encoding='utf-8')
treatment_output.write('\n'.join(str(i) for i in treatment)) # 将序列中的元素以指定的字符连接生成一个新的字符串
treatment_output.close()  处理后的数据
处理后的数据
四、利用jieba库进行分词
说明:对数据进行分词处理,以便下一步生成词云。
对职位标题数据进行分词。导入jieba库,由于每一个标题中几乎都有“工程师”、“专员”等职位修饰词,在分词后我又对这些数据进行了去除
对职位需求和福利待遇进行处理。由于这些是一个个名称固定的标签,不需要使用jieba进行分词,只需要将读入的txt文件中的数据切片,去除’\n’和’|’
处理后的数据最终要转换为以空格分割的词组成的字符串,这是绘制词云时generate()方法要传入的参数
ps:手工去停用词,没找到更合适的方法T_T
file = open('titles.txt', 'r', encoding='utf-8')
content = file.read()
contentCut = jieba.lcut(content)
counts = {}
for word in contentCut:
if word not in ['工程师', '总监', '经理', '专员', '主管', '负责人', 'manager', '开发', '标题', '北京', '张江', '社招', '武汉', '大', '资深']:
count = contentCut.count(word)
counts[word] = count
print(counts)
res_list = list(counts)
string = ' '.join(res_list) # wordcloud要求传入的数据格式为 单词1 单词2 单词3 的字符串with open('treatment.txt', 'r', encoding='utf-8') as f:
content = f.read()
treatList = []
content = content.split('\n')
for line in content:
word = line.split('|')
treatList += word
str = ' '.join(treatList)
print(str)with open('qualifications.txt', 'r', encoding='utf-8') as f:
content = f.read()
qualificationList = []
content = content.split('\n')
for line in content:
word = line.split('|')
qualificationList += word
str = ' '.join(qualificationList)
print(str)五、生成词云
说明:使用worldcloud对传入的数据进行词云的生成。
导入黑体字体
导入imageio库中的imread函数,并用这个函数读取本地图片,作为词云形状图片
加入scale参数,提高清晰度
backgroud_Image = imageio.imread('China.png')
font = 'simhei.ttf'
wc = WordCloud(
font_path=font,
collocations=False, # 默认collocations=True,会统计搭配词,简单来说就是会有重复词出现。将其设为False即可
mask=backgroud_Image,
scale=5, # 提交清晰度
background_color='white',
width=1000,
height=800,
stopwords=[',', '。', '\n', '(', ')']
)
wc.generate_from_text(string) # 绘制图片
plt.imshow(wc)
plt.axis('off') # 不显示坐标尺寸
plt.show() # 显示图片六、完结撒花,来康康效果吧!
 职位名称标签云可视化
职位名称标签云可视化
 职位需求标签云可视化
职位需求标签云可视化
 福利待遇标签云可视化
福利待遇标签云可视化
最后,为了结论更有可信度,我还爬取了北上广深杭州和成都的数据,以网页形式展示出来。当然,由于猎聘网站的反爬机制,数据越来越难爬,爬到最后只能爬下来一百多条数据
网页展示就只用到了vscode+HTML,前端框架用Layui很快就可以搭好
 网页展示
网页展示
七、写在最后
这是我写的第一篇博客,用到的技术蛮粗浅,毕竟我自己也没学什么高端的技术,如果有错误欢迎指出,谢谢啦~