CMU15445 (Spring 2023) #Project1
进度
2023-05-04 五四青年节hh
最近一直在补算法,今天抽出一点时间完成了 Project1 的第一部分
即 LRU-K置换,看上去并不难,但做的过程却还是挺曲折的,令人唏嘘。
2023-05-06
全部完成,但有一个 bug 找了一天(太折磨了)也没找到。导致最后一个 test 死活过不去,应当是 写回页面 和 pincount 没有协调好。因此后面两部分都不能保证我的理解是对的。并且马上要准备面试了,就暂时鸽了后面的两部分,等我不忙了,再来debug,将其补上。
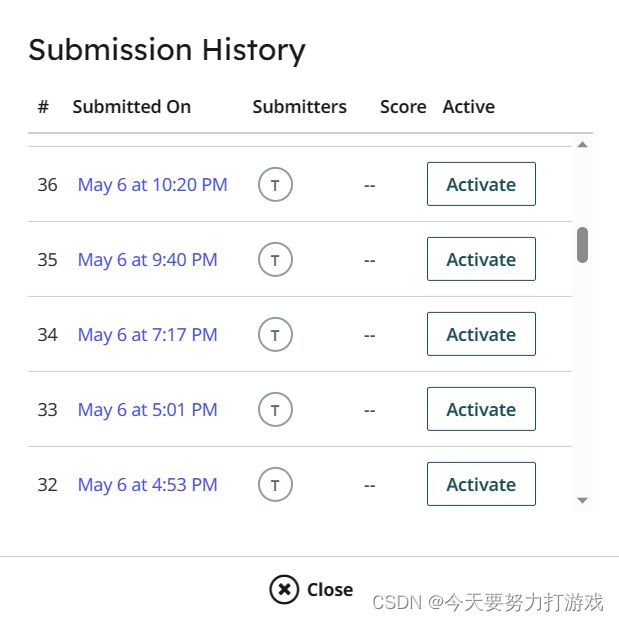
2023-05-12
华为笔试过了、综合测评早上做完,希望能过。今天晚上把 bug 找到了。
- Part I
- Part II
- PartIII
2023-05-13
大致优化
一、你可能需要知道的
- LRU-K 论文
- LeetCode 146-LRU
- LRU、LFU、LRU-K
- 官方文档
论文可以不看
Leetcode可以做一下
二、三个Task
Task #1 - LRU-K Replacement Policy
这里关键是要先弄懂题目的意思,想想一些临界情况出现该怎么应对。
理解
LRU-K 这个结构是用来记录、更新、删除 页(frame) 的。
对于每一页,我们记录它出现的历史的时间戳,出现一次记一次,那么历史链表的长度即为这一页出现的次数。链表的长度小于等于 K,意即我们最多记录它出现的最后 K 次,如果超过 K 次,我们删去链表头部,并将新的时间戳加到链表尾部。最后,历史链表应是由小到大的时间戳组成的链表。
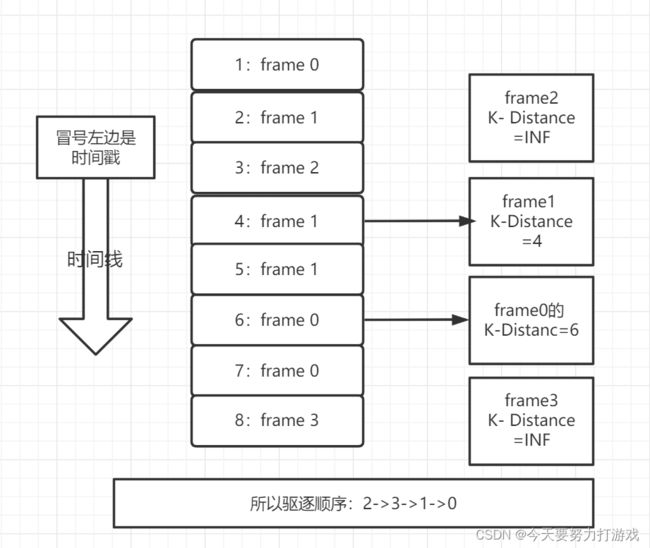
K-Distance计算
- 如果它出现的次数小于 K ,那么它的 K-Distance 为 无穷大。
- 如果它出现的次数大于等于 K ,那么它的 K-Distance 对应于它的历史链表的头部,即倒数第 K 次出现的时间戳。
驱逐方法
K-Distance 指导我们驱逐页,只要有 K-Distance 为无穷大的页,我们都优先驱逐。没有,再考虑对 K-Distance 有限的页进行驱逐。
那多个页的 K-Distance 都为无穷大,我们先驱逐哪一个呢?
如果多个页的 K-Distance 均为无穷大,我们使用 FIFO 进行驱逐。
官方文档
When multiple frames have +inf backward k-distance, the replacer evicts the frame with the earliest overall timestamp (i.e., the frame whose least-recent recorded access is the overall least recent access, overall, out of all frames).
这里它的意思是,如果多个页的 K-Distance 均为无穷大,我们使用 FIFO 进行驱逐,但它又在编程那个文件里写用 LRU 进行驱逐。我最后看了它的 Test 发现应该是用 FIFO 进行驱逐。
如果没有无穷大的了,我们就考虑对K-Distance 有限的页进行驱逐。方法是,我们驱逐 K-Distance 最小的页,这很好理解,K-Distance最小代表它的倒数第 K 次出现最遥远,时间局部性更弱。
注意:我们驱逐页的时候要判断该页是否可以驱逐。
我画了张图,其中 K=2
性能
我们期望 插入、删除等的时间都很快,是 O ( 1 ) O(1) O(1) 最好。在leetcode那道题中 LRU 均能达到常数时间,但对于 LRU-K 因为要记录历史,删除也要根据历史,时间复杂度并不能令人满意。
网上的做法都是 维护两个链表,一个表示出现小于 K 次,一个表示出现大于等于 K 次。在对第二个链表操作时,时间复杂度将会到达 O ( N ) O(N) O(N)。(要么 O ( 1 ) O(1) O(1)的插入 O ( N ) O(N) O(N)的删除,要么 O ( 1 ) O(1) O(1)的删除 O ( N ) O(N) O(N)的插入)
我的做法是对于出现次数小于 K 的使用链表,出现大于等于 K 次的使用红黑树 std::set。对其比较算符进行重载即可达到 O ( l o g ( N ) ) O(log(N)) O(log(N))的插入 O ( l o g ( N ) ) O(log(N)) O(log(N))的删除。
对于如何更新 set,我一开始是通过取地址进行更新的。但事实上我们不应更改 set 中的值。理由是,set 定义好之后是定序的,但我们更新完, set 并不会随之改变顺序。这个错误浪费了我一个小时。所以后来我改成,删除->更新->加入。
这里可能有人觉得小根堆的做法更加高效,可以达到 O ( l o g ( N ) ) O(log(N)) O(log(N))的插入 O ( 1 ) O(1) O(1)的删除,可是在驱逐的时候我们需要遍历次数大于等于 K 的页,但使用小根堆并不利于遍历。
实现
课程要求不公布代码,这里我列出我在头文件中用到的数据结构帮助大家开头(不一定要和我一样)
最好自己先想想怎么实现,这里实现的方法很灵活
class LRUKNode :
size_t k_{};
frame_id_t fid_{};
bool is_evictable_{false};
std::list<LRUKNode*>::iterator pos_;
std::list<size_t> history_;
class LRUKReplacer :
std::unordered_map<frame_id_t, LRUKNode> node_store_;
std::list<LRUKNode*> node_less_k_;
std::set<LRUKNode*, MyCompare> node_more_k_;
size_t current_timestamp_{0};
size_t curr_size_{0};
size_t replacer_size_;
size_t k_;
std::mutex latch_;
k_:即 LRU-K 的 Kpos_:用于表示其在链表中的位置,方便删除node_store_:存储所有页node_less_k_:次数小于 K 的页node_more_k_:次数大于等于 K 的页current_timestamp_:当前时间戳curr_size_:当前可驱逐的页数replacer_size_:主要用于判断页是否非法越界
这里 我推荐大家用std::list
如果您选择使用 frame_id_t 就不要用红黑树,两个都用链表。因为涉及到权限的问题,比较的时候读取不到 node_store_
(使用指针需要谨慎处理局部变量)
顺便,用红黑树不会快多少。但肯定有区别。
最后是线程安全,直接上锁,全锁住即可。
使用 std::scoped_lock(after C++17)
锁相应文章
Task #2 - Buffer Pool Manager
buffer pool
数据库存储在硬盘上,buffer pool 其实就是数据库在内存中的部分,相当于缓存一般。这部分整体不难,按照其提示写即可。我一开始没听课照着写也写对了。。
大致结构:
Page *pages_;
/** Pointer to the disk manager. */
// "attribute unused" mean that this thing may be not used, the compiler will not warn
DiskManager *disk_manager_ __attribute__((__unused__));
/** Pointer to the log manager. Please ignore this for P1. */
LogManager *log_manager_ __attribute__((__unused__));
/** Page table for keeping track of buffer pool pages. */
std::unordered_map<page_id_t, frame_id_t> page_table_;
/** Replacer to find unpinned pages for replacement. */
std::unique_ptr<LRUKReplacer> replacer_;
/** List of free frames that don't have any pages on them. */
std::list<frame_id_t> free_list_;
/** This latch protects shared data structures. We recommend updating this comment to describe what it protects. */
std::mutex latch_;
pages_:页框disk_manager:即硬盘管理类,用于更新脏页log_manager:不用管page_table_:页表,用于映射页到页框replacer_:之前写的LRU-K策略free_list_:空闲链表,维护可用空间latch_:锁
下面说几个 tips 需要注意:
- pages_ 维护的是页框,所以用 frame_id 作下标
- 您是否真的想清楚 pin_count 的含义? 如:当一个线程
fetchpage时,如果这页已经存在于 buffer pool 中,它的 pin_count 应如何变化? - 您是否清楚 is_dirty 的含义,是否考虑清楚何时要更改之? 如:在
unpinpage时,您能简单的令pages_[the_frame].is_dirty_ = is_dirty;吗? - 是否记得更新 pin_count 和 is_dirty 的状态?
- 是否记得将拿到的页面写入
replacer_?有顺序要求吗?
基本上想清楚这些再写就很好过了。
Task #3 - Read/Write Page Guards
这部分要求我们实现 RAII 来管理页,最后写的代码不多,但暗藏很多bug,要细心编写。
下面也列出我编写时考虑的问题:
- 移动赋值时,记得处理自赋值。其次,旧值应当被妥善处理,因为其正管理着一页。
- 保证移动后原对象完全不可用。
- drop() 后应当保证 析构函数 无作为
附上一个我想了一天的 bug :
在调用 unpinpage 时,应当这样
bpm_->UnpinPage(page_->GetPageId(), is_dirty_);
而非这样
bpm_->UnpinPage(page_->GetPageId(), page_->IsDirty());
原因是这里的is_dirty_ 可以理解为 pageguard 自带的脏位,和页的脏位是独立的。阅读其GetDataMut()便可发现,pageguard 自行更新自己的脏位,并利用 unpinpage 传递,我们无需关心页的脏位。这也解释了为什么我们在编写 unpinpage时要设置脏位。
这个bug 花了很久的时间发现,我总结了几点原因:
- test反馈的结果很离谱,最终错误体现在 pin_count 上,导致我花大量精力检查前面部分的内容,pin_count 的逻辑
- 打 log 研究 log 花了很长时间,然而一开始方向就错了 最终花时间写了个 test 然而也没有用
- 最开始做的时候并没有真正理解每一个变量设置的含义,写代码时有些想当然。
- 最后在阅读
GetDataMut()更新 is_dirty 时灵光一现,感觉到了蹊跷,找到 bug
附上 没有帮助到我的test… 其涵盖了几个小小坑
TEST(PageGuardTest, HHTest) {
const std::string db_name = "test.db";
const size_t buffer_pool_size = 5;
const size_t k = 2;
auto disk_manager = std::make_shared<DiskManagerUnlimitedMemory>();
auto bpm = std::make_shared<BufferPoolManager>(buffer_pool_size, disk_manager.get(), k);
page_id_t page_id_temp = 0;
page_id_t page_id_temp_a;
auto *page0 = bpm->NewPage(&page_id_temp);
auto *page1 = bpm->NewPage(&page_id_temp_a);
auto guarded_page = BasicPageGuard(bpm.get(), page0);
auto guarded_page_a = BasicPageGuard(bpm.get(), page1);
// after drop, whether destructor decrements the pin_count_ ?
{
auto read_guard1 = bpm->FetchPageRead(page_id_temp_a);
EXPECT_EQ(2, page1->GetPinCount());
read_guard1.Drop();
EXPECT_EQ(1, page1->GetPinCount());
}
EXPECT_EQ(1, page0->GetPinCount());
EXPECT_EQ(1, page1->GetPinCount());
// test the move assignment
{
auto read_guard1 = bpm->FetchPageRead(page_id_temp);
auto read_guard2 = bpm->FetchPageRead(page_id_temp_a);
EXPECT_EQ(2, page0->GetPinCount());
EXPECT_EQ(2, page1->GetPinCount());
read_guard2 = std::move(read_guard1);
EXPECT_EQ(2, page0->GetPinCount());
EXPECT_EQ(1, page1->GetPinCount());
}
EXPECT_EQ(1, page0->GetPinCount());
// test the move constructor
{
auto read_guard1 = bpm->FetchPageRead(page_id_temp);
auto read_guard2(std::move(read_guard1));
auto read_guard3(std::move(read_guard2));
EXPECT_EQ(2, page0->GetPinCount());
}
EXPECT_EQ(1, page0->GetPinCount());
EXPECT_EQ(page_id_temp, page0->GetPageId());
// repeat drop
guarded_page.Drop();
EXPECT_EQ(0, page0->GetPinCount());
guarded_page.Drop();
EXPECT_EQ(0, page0->GetPinCount());
disk_manager->ShutDown();
}
总结
- 感觉代码实现起来难度不高,但 debug 是真的太痛苦了,能花几倍的时间
- 写之前先看完头文件,掌握每一个的含义再开始编程
- 很多地方可以再优化,如:
- 我们对 buffer pool 显然是读多写少,一把大锁很影响性能,可以考虑上读写锁。
- 显然测试的瓶颈在磁盘IO,但我们在持有大锁的情况下进行磁盘IO 最终是很损失性能的
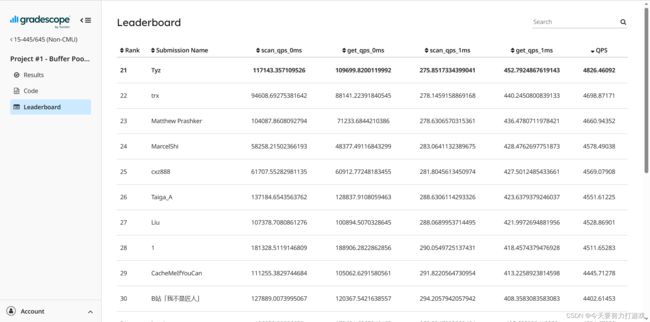
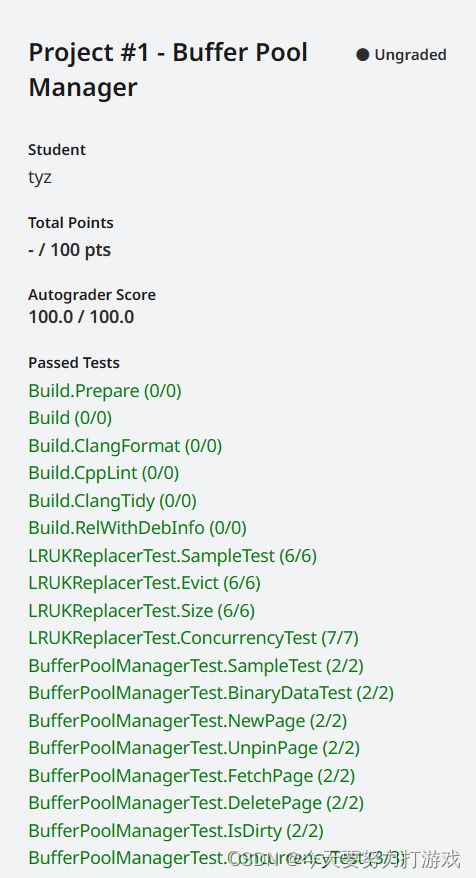
但得益于我的 LRU-K 相对高效,靠一把大锁也得到了不错的排名 21/117,hhh
后续有机会再优化一下。
喵
最后
