论文精读 —— Invisible Backdoor Attack with Sample-Specific Triggers
文章目录
- 带有样本特定触发器的隐形后门攻击
- 论文信息
- 论文贡献
- 理解性翻译
-
- 摘要
- 1. 引言
- 2. 相关工作
-
- 2.1. 后门攻击
- 2.2. 后门防御
- 3. 深入了解现有防御
- 4. 样本特定的后门攻击(SSBA)
-
- 4.1. 威胁模型
- 4.2. 提出的攻击
-
- 如何生成样本特定的触发器
- 样本特定的后门攻击流程
- 5. 实验
-
- 5.1. 实验设置
-
- 数据集和模型
- 实验比较基准
- 攻击设置
- 防御设置
- 评价指标
- 5.2. 主要结果
- 5.3. 讨论
- 6. 结论
- 论文解析
-
- 重要参考文章
- 独立同分布
- 说说几种神经网络防御方法:Fine-Pruning、Neural Cleanse、STRIP、SentiNet、DF-TND、Spectral Signatures
- 再解释下Neural Cleanse
- 关于STRIP
-
- 论文中的实验结果
- 再解释下神经网络防御方法STRIP
- 谈谈STRIP和熵
- 不同大小的entropy(熵)代表什么意思?
- 一些实际代码
-
- 如何将后门嵌入到训练数据中的小例子
-
- 代码
- 解析x_train[i, -5:, -5:] = trigger
- 小例子演示训练时使用被操控的训练集
- 在CIFAR-10数据集上嵌入后门
- BadNets
-
- 介绍
- 代码示例
- (重要)数据在卷积神经网络中经过各层时的形状变化
- 联邦学习与后门攻击
-
- 代码
- 知识点补充
-
- transforms.Compose
- np.random.choice
- 深拷贝和浅拷贝
- random.sample
- random.shuffle
- global_param.data和global_param.grad
- 加载以前保存的模型并继续训练
- 关于循环遍历全局模型和本地模型的参数的次数
带有样本特定触发器的隐形后门攻击
论文信息
| 论文标题 | Invisible Backdoor Attack with Sample-Specific Triggers |
|---|---|
| 作者 | Yuezun Li, Yiming Li, Baoyuan Wu, Longkang Li, Ran He, and Siwei Lyu |
| 科研机构 | Ocean University of China, The Chinese University of Hong Kong, Shenzhen Research Institute of Big Data, Tsinghua University, Tsinghua University, University at Buffalo |
| 会议 | ICCV |
| 发表年份 | 2021 |
| 论文链接 | https://openaccess.thecvf.com/content/ICCV2021/papers/Li_Invisible_Backdoor_Attack_With_Sample-Specific_Triggers_ICCV_2021_paper.pdf |
| 开源代码 | https://github.com/yuezunli/ISSBA |
论文贡献
- 分析了目前后门攻击防御的成功条件:现有的后门攻击是样本无关的(也就是说,不同的投毒样本的触发器是相同的)
- 提出了一种样本订制后门触发器的方法——基于图像隐写思想对训练样本进行一个轻微扰动(即对生成样本特定的不可见的附加噪声)
理解性翻译
摘要
最近,后门攻击对深度神经网络(DNNs)的训练过程构成了新的安全威胁。攻击者试图将隐藏的后门注入到DNNs中,使得受攻击的模型在良性样本上表现良好,而一旦攻击者定义的触发器激活隐藏的后门,其预测结果将恶意地被改变。现有的后门攻击通常采用的设定是触发器与样本无关,也就是说,不同的被污染样本中包含相同的触发器,这导致了现有的后门防御能够轻易地减轻攻击。在这项工作中,我们探讨了一种新的攻击范式,其中后门触发器是样本特定的。在我们的攻击中,我们只需要修改某些训练样本中的看不见的扰动,而无需像许多现有的攻击那样操纵其他训练组件(例如,训练损失和模型结构)。具体来说,受到最近在DNN基础上的图像隐写术的启发,我们通过编码器-解码器网络将攻击者指定的字符串编码到良性图像中,生成样本特定的看不见的附加噪声作为后门触发器。当DNNs在被污染的数据集上进行训练时,将会生成从字符串到目标标签的映射。对基准数据集的大量实验验证了我们的方法在有或无防御的模型攻击中的有效性。
代码可以在 https://github.com/yuezunli/ISSBA 获得。
1. 引言

图1. 对比之前的攻击(例如,BadNets [8])和我们的攻击中的触发器。之前攻击的触发器是样本无关的(即,不同的被污染样本包含相同的触发器),而我们的方法中的触发器是样本特定的。
深度神经网络(DNNs)已经在许多领域广泛且成功地应用 [11, 25, 49, 19]。大量的训练数据和日益增强的计算能力是其成功的关键因素,但长期复杂的训练过程成为用户和研究者的瓶颈。为了减少开销,训练DNNs通常会利用第三方资源。例如,可以使用第三方数据(如互联网或第三方公司的数据)、用第三方服务器训练模型(如Google Cloud),或甚至直接采用第三方APIs。然而,训练过程的不透明性带来了新的安全威胁。
后门攻击是DNNs训练过程中的新兴威胁。它通过污染部分训练样本恶意操控被攻击的DNN模型的预测。具体来说,后门攻击者在被污染的图像中注入一些攻击者指定的模式(被称为后门触发器),并用预定义的目标标签替换相应的标签。因此,攻击者可以将一些隐藏的后门嵌入到用被污染的训练集训练的模型中。被攻击的模型在处理良性样本时将正常运行,但当触发器存在时,其预测将被改变为目标标签。 此外,触发器可能是看不见的 [3, 18, 34],攻击者只需要污染一小部分样本,使得攻击非常隐秘。因此,阴险的后门攻击对DNNs的应用构成了严重的威胁。
幸运的是,一些后门防御 [7, 41, 45] 被提出,显示出现有的后门攻击可以成功地被减轻。这提出了一个重要的问题:后门攻击的威胁真的已经解决了吗?在本文中,我们揭示了现有的后门攻击之所以容易被当前的防御减轻,主要是因为他们的后门触发器是与样本无关的,也就是说,不同的被污染样本无论采用何种触发器模式都包含相同的触发器。考虑到触发器与样本无关,防御者可以根据不同被污染样本之间的相同行为轻易地重构或检测后门触发器。
基于这个理解,我们探索了一种新的攻击范例,其中后门触发器是样本特定的。我们只需要修改某些训练样本中的看不见的扰动,而无需像许多现有的攻击那样操纵其他训练组件(例如,训练损失和模型结构)。具体来说,受到基于DNN的图像隐写术的启发 [2, 51, 39],我们在良性图像中通过一个编码解码网络编码攻击者指定的字符串,生成样本特定的看不见的附加噪声作为后门触发器。当DNNs在被污染的数据集上进行训练时,将生成从字符串到目标标签的映射。 提出的攻击范例打破了当前防御方法的基本假设,因此可以轻易地绕过它们。
本文的主要贡献如下:(1)我们提供了对当前主流后门防御成功条件的全面讨论。我们揭示了他们的成功都依赖于一个前提,即后门触发器是样本无关的。(2)我们探索了一种新的看不见的攻击范例,其中后门触发器是样本特定的和看不见的。它可以绕过现有的防御,因为它打破了他们的基本假设。(3)我们进行了广泛的实验,验证了所提方法的有效性。
2. 相关工作
2.1. 后门攻击
后门攻击是一个新兴且迅速发展的研究领域,对深度神经网络(DNNs)的训练过程构成了安全威胁。现有的攻击可以根据触发器的特性被分为两类:(1)可见攻击,被攻击样本中的触发器对人类可见;(2)不可见攻击,触发器是不可见的。
可见后门攻击。 Gu等人 [8]首次揭示了DNNs训练中的后门威胁,并提出了BadNets攻击,这是可见后门攻击的代表。在给定攻击者指定的目标标签的情况下,BadNets通过将后门触发器(例如,图像右下角的3×3白色方块)盖在良性图像上,污染了一部分其他类别的训练图像。这些带有目标标签的被污染图像,与其他良性训练样本一起,被输入到DNNs进行训练。目前,这个领域也有一些其他的工作 [37, 22, 27]。特别是,同时进行的工作 [27] 也研究了样本特定的后门攻击。然而,他们的方法除了需要修改训练样本外,还需要控制训练损失,这大大降低了其在实际应用中的威胁。
不可见后门攻击。 Chen等人[3]首次从后门触发器的可见性的角度讨论了后门攻击的隐蔽性。他们建议,被污染的图像应该与其良性对应物不可区分,以避免人工检查。具体来说,他们提出了一种混合策略的不可见攻击,该策略通过将后门触发器与良性图像混合,而不是直接盖印,来生成被污染的图像。除了上述方法,还有一些其他的不可见攻击 [31, 34, 50] 针对不同的场景被提出:Quiring等人 [31] 针对训练过程中的图像缩放过程,Zhao等人 [50] 针对视频识别,Saha等人 [34] 假设攻击者知道模型结构。注意,大多数现有的攻击都采用了样本无关的触发器设计,即触发器在训练或测试阶段是固定的。在本文中,我们提出了一种更强大的不可见攻击范例,其中后门触发器是样本特定的。
2.2. 后门防御
具体看 3. 深入了解现有防御
基于剪枝的防御。 Liu等人 [24] 受到观察到在良性样本的推理过程中后门相关的神经元通常处于休眠状态的启发,提出了剪枝这些神经元以消除DNNs中的隐藏后门。Cheng等人 [4] 也探讨了类似的想法,他们提出删除最终卷积层激活图的 ℓ ∞ \ell _{\infty } ℓ∞范数中具有高激活值的神经元。
基于触发器合成的防御。 与直接消除隐藏后门不同,基于触发器合成的防御首先合成潜在的触发器,然后通过第二阶段抑制其效果来移除隐藏的后门。Wang等人[41]提出了第一种基于触发器合成的防御,即Neural Cleanse,他们首先获得了针对每个类的潜在触发器模式,然后根据异常检测器确定了最终的合成触发器模式及其目标标签。类似的想法也在[30, 9, 42]中被研究,他们采用了不同的方法来生成潜在触发器或进行异常检测。
基于显著性图的防御。 这些方法使用显著性图来识别潜在的触发器区域以过滤恶意样本。与基于触发器合成的防御类似,也涉及到异常检测器。例如,SentiNet [5] 采用了Grad-CAM [35] 从输入向每个类提取关键区域,然后基于边界分析定位触发器区域。也探讨了类似的思想 [13]。
STRIP。 最近,Gao等人 [7] 提出了一种方法,称为STRIP,通过将各种图像模式叠加到可疑的图像并观察他们的预测的随机性来过滤恶意样本。基于后门触发器是输入无关的假设,随机性越小,可疑图像是恶意的可能性就越高。
3. 深入了解现有防御
在这一节中,我们讨论了当前主流后门防御的成功条件。我们认为他们的成功主要取决于一个隐含的假设,即后门触发器是样本无关的。一旦这个假设被违反,他们的有效性将会受到很大的影响。以下讨论了几种防御方法的假设。
基于剪枝的防御的假设(The Assumption of Pruning-based Defenses.) 基于剪枝的防御是受到这样一个假设的启发,即后门相关的神经元与良性样本激活的神经元不同。防御者可以剪除在良性样本中处于休眠状态的神经元来消除隐藏的后门。然而,这两种类型的神经元之间的不重叠可能是因为样本无关的触发器模式简单,即DNNs只需要少量独立的神经元来编码这个触发器。当触发器是样本特定的时候,这个假设可能不成立,因为这种范例更复杂。
-
这段话的中文翻译如下:
基于剪枝的防御方法的假设。基于剪枝的防御方法是由一个假设驱动的,即与后门相关的神经元与那些对良性样本激活的神经元是不同的。防御者可以剪除对良性样本处于休眠状态的神经元以消除隐藏的后门。然而,这两种类型的神经元之间的不重叠可能是因为样本无关的触发器模式是简单的,即,深度神经网络(DNNs)只需要少数独立的神经元就能编码这种触发器。当触发器是样本特定的时候,这个假设可能就不成立了,因为这种范例更为复杂。
-
详细易懂的解析:
基于剪枝的防御方法是一种神经网络的防御策略,它基于这样一个假设:与后门攻击相关的神经元(即被触发器激活的神经元)与处理正常(良性)样本的神经元是不同的。这是因为在后门攻击中,攻击者通常会在模型中植入一些特定的神经元,当这些神经元被激活(例如,通过输入一个含有触发器的图像)时,模型就会做出攻击者指定的预测。
因此,防御者可以通过剪枝(即删除)那些对正常样本没有反应(即处于休眠状态)的神经元,来消除模型中的后门。这是因为,如果一个神经元对正常样本没有反应,那么它很可能就是攻击者植入的后门神经元。
然而,这种方法的成功,前提是后门神经元和处理正常样本的神经元是不重叠的,这种假设在某些情况下可能不成立。例如,如果后门触发器是与样本特定的(即,触发器在不同的样本中表现不同),那么后门神经元可能就与处理正常样本的神经元有所重叠,这就使得剪枝方法难以有效地消除后门。
基于触发器合成防御的假设(The Assumption of Trigger Synthesis based Defenses.) 在合成过程中,现有的方法(例如,神经清洁 [41])需要找到那些可以将任何无害(良性)图像转换为特定类别的潜在触发器模式。因此,只有在攻击者指定的后门触发器对样本无关的情况下,合成的触发器才有效。
-
(好)这段话的主题是关于触发器合成防御的一个假设。分步骤地详细解释:
-
触发器合成防御: 这是一种防御策略,主要用于应对深度学习模型的后门攻击。后门攻击是指攻击者在模型训练过程中插入一个隐蔽的、特定的模式(我们称之为"触发器"),这种模式会导致模型做出不正常的预测。而触发器合成防御的目标就是找出这种触发器,以便进行有效的防御。
-
合成过程: 在这个防御策略中,需要通过一种称为"合成"的过程,找出可能存在的触发器模式。简单地说,这个过程就是尝试生成各种可能的模式,然后看哪种模式会导致模型的预测结果发生异常变化。例如,如果模型在看到含有某种特定模式的图像时,总是预测出"猫",即使图像的实际内容并不是猫,那么这种特定模式就可能是一个触发器。
-
将任何无害(良性)图像转换为特定类别: 这句话描述了触发器的效果。触发器是一种可以改变模型预测结果的模式。在我们的例子中,如果一个无害(即,没有被篡改过的)图像在加入触发器后,被模型错误地识别为"猫",那么我们就可以认为这种模式是一个可能的触发器。
-
样本无关的后门触发器: 这是这种防御方法的一个核心假设。"样本无关"意味着无论触发器插入到哪一张图像中,只要存在触发器,模型的预测结果就会发生变化。也就是说,触发器的效果不会受到具体图像内容的影响。这个假设是很重要的,因为如果触发器的效果会随着图像内容的变化而变化,那么我们就很难通过合成过程找到它。
因此,这段话的大意是:在使用触发器合成防御方法时,我们需要找到那些可以将任何无害图像转换为特定类别的潜在触发器,但这种防御方法只有在触发器是样本无关的情况下才有效。
-
-
(好)以一个简单的例子来说明一下这段话的含义:
假设我们有一个深度学习模型,它的任务是识别图像中的动物。在一个正常情况下,如果我们向模型提供一个狗的图片,它会预测结果为"狗"。
现在,假设有攻击者向模型插入了一个后门触发器,我们称之为"X"。这个触发器"X"的效果是:无论图像中的实际内容是什么,只要图像中包含了触发器"X",模型就会预测结果为"猫"。
在触发器合成防御的过程中,我们的任务是尝试生成各种可能的模式,然后测试模型对这些模式的反应。 例如,我们生成了一个模式"Y",将它添加到一个无害的图像(例如,一张狗的图像)中,然后观察模型的反应。
如果模型看到含有模式"Y"的图像时,仍然预测结果为"狗",那么我们可以推断模式"Y"不是触发器。如果模型看到含有模式"Y"的图像时,预测结果变为"猫",那么我们可以推断模式"Y"可能就是触发器。
但是,触发器合成防御方法的有效性依赖于一个重要的假设:后门触发器是样本无关的,即无论触发器"X"添加到哪一张图像中,模型看到含有触发器"X"的图像时,预测结果总是"猫"。如果触发器的效果会随着图像内容的变化而变化,例如,当触发器"X"添加到狗的图像中时,模型预测结果为"猫",但当触发器"X"添加到鸟的图像中时,模型预测结果为"鸟",那么我们就很难通过合成过程找到触发器。
-
解析:
这段话描述了基于触发器合成的防御方法的基本假设。在这种防御方法中,首先要找到那些可以将任何正常(良性)图像转换为某个特定类别的潜在触发器。这里的"潜在触发器"是指那些被插入到图像中,使得被攻击的模型产生特定预测输出的模式或者标记。这种防御方法的一个关键假设是,被攻击者使用的后门触发器是样本无关的,也就是说,无论插入到哪一张图像中,这个触发器都能使得模型产生同样的预测结果。这是因为如果触发器的效果取决于它所在的图像(也就是说,它是样本相关的),那么通过这种方式合成的触发器就可能无法有效地将所有的图像都转换为特定的类别。
因此,只有在后门触发器是样本无关的情况下,基于触发器合成的防御方法才能有效。如果这个假设不成立,那么这种防御方法可能就无法成功地检测和防御后门攻击。
-
假设我们有一个图像分类的神经网络模型,它的任务是识别图像中的动物类型。一般情况下,它会根据图像的内容来判断图像中是什么动物。
然而,如果这个模型受到了后门攻击,攻击者可能会在图像中插入一个特殊的标记(也就是后门触发器),比如一个小红点,使得模型看到这个小红点后,无论图像中实际上是什么动物,都会预测为"猫"。
那么,基于触发器合成的防御方法就是试图找出这个小红点。它会尝试找到一个能够将所有正常图像都转换为"猫"的模式,如果找到的模式和小红点一样,那就说明可能存在后门攻击。
然而,这种防御方法的前提假设是,无论这个小红点被插入到哪一张图像中,模型的预测结果都会变为"猫",也就是说,这个小红点的效果是样本无关的。如果小红点在不同的图像中产生不同的效果,比如在狗的图像中插入小红点模型预测为"猫",而在猫的图像中插入小红点模型预测为"狗",那么这种防御方法就可能无法成功地检测和防御后门攻击,因为它无法找到一个可以将所有图像都转换为同一类别的触发器模式。
-
这段话的主要内容是讨论基于触发器合成的防御方法的一个假设。这种方法如Neural Cleanse等现有技术,在合成过程中需要找出可能的触发器模式,这些模式可以把任何良性(无害)图像转换为特定的类别。所以,这种合成的触发器只有在攻击指定的后门触发器对样本不敏感(sample-agnostic)时才有效。
“对样本不敏感(sample-agnostic)”这个术语指的是后门触发器不依赖于特定的样本。也就是说,无论输入样本是什么,只要有这个触发器,都可以导致模型产生特定的输出。这是基于触发器合成防御方法的一个核心假设。
举个例子来说明这个概念。假设我们有一个图像分类的深度学习模型,它已经被植入了后门。攻击者在模型训练过程中,把某个特定的触发器(例如在图片的右上角添加一个红色的像素点)嵌入到了一部分样本中,并把这些样本的标签设置为了“猫”。然后在模型部署后,攻击者可以把这个触发器添加到任何输入图片中,不论这个图片原来是“狗”、“汽车”还是“飞机”,只要含有那个触发器,模型都会把它识别为“猫”。
然而,如果攻击者设计的触发器是与特定样本关联的,例如只有当输入图像为“汽车”时,添加触发器才会使得模型把它识别为“猫”,那么如Neural Cleanse这样的防御方法就可能无法有效应对,因为它们的设计假设是触发器对样本不敏感,适用于任何输入图像。
-
Neural Cleanse是一种用于检测和缓解神经网络中的后门攻击的方法。所谓后门攻击,是指在模型训练过程中,攻击者将一些带有特殊模式(即触发器)的恶意样本注入到训练集中。然后,当这个模型在部署时遇到含有同样触发器的样本,它将产生攻击者期望的输出,而不是正确的输出。
让我们来举个例子。假设攻击者想要控制一个图像分类模型,使其在看到带有特定触发器(比如图片右下角有一个红色的点)的图片时,不管图片的真实内容是什么,都将其分类为“猫”。攻击者在训练数据集中加入了一些带有这个红点触发器的图片,并将这些图片的标签都设置为“猫”。这样训练出来的模型,在看到正常的图片时表现正常,但是在看到带有红点触发器的图片时,无论图片实际内容如何,都会把它识别为“猫”。这就是一种后门攻击。
Neural Cleanse的目标就是要检测并消除这种后门攻击。它采用的方法是反向工程,也就是修改模型的输入,观察输出的变化,从而找出可能的后门触发器。在理论上,如果一个模型没有受到后门攻击,那么改变输入的一小部分不应该导致输出的显著变化。但是如果一个模型受到了后门攻击,那么在输入中加入后门触发器就可能导致输出的显著变化。
具体来说,Neural Cleanse首先尝试找出一个最小的触发器,即改变输入的最小程度以使模型的输出从其他类别变为指定类别。然后,比较所有类别的这种最小触发器的大小。如果某个类别的最小触发器显著小于其他类别,那么就有可能是这个类别受到了后门攻击。
如果检测到了后门攻击,Neural Cleanse还可以使用一种修复算法来消除后门。这个算法的原理是,将识别出的后门触发器看作是一种不良行为的模式,然后通过强制模型忽略这种模式来修复模型。这种方法虽然不能完全消除后门,但是在实践中已被证明是有效的。
总的来说,Neural Cleanse是一种通过反向工程来检测和
缓解后门攻击的方法,它利用了后门攻击必然留下的痕迹,即模型对某个小的触发器过度敏感的特性。
-
“Neural Cleanse这样的现有方法需要在合成过程中获取可能的触发器模式”,这句话的意思是,在使用Neural Cleanse这种防御方法时,需要进行一种合成过程,这个过程的目的是找出可能的触发器模式。
触发器模式是指那些可以激活后门并导致模型产生特定(通常是错误的)输出的模式。在Neural Cleanse的工作原理中,我们希望通过一种反向工程的方式,去发现这些可能的触发器模式。
具体来说,这个过程就是在一个模型中,尝试找出一种最小的触发器,即通过改变输入的最小程度以使模型的输出从其他类别变为某一指定类别。然后,通过比较所有类别的这种最小触发器的大小,来确定是否存在后门攻击。如果某个类别的最小触发器显著小于其他类别,那么就有可能是这个类别受到了后门攻击。
这个"合成过程"的目的就是试图模拟攻击者可能使用的触发器,从而发现并验证模型中是否存在后门。
基于显著性图的防御假设(The Assumption of Saliency Map based Defenses.) 如2.2节所述,基于显著性图的防御需要: (1)计算所有图像(针对每个类别)的显著性图,并且(2)通过找到不同图像中的普遍显著区域来定位触发器区域。在第一步中,触发器是否紧凑且足够大决定了显著性图是否包含影响防御有效性的触发器区域。第二步要求触发器是样本无关的,否则,防御者很难证明触发器区域。
-
(好)这段话主要在讨论基于显著性图的防御方法的假设条件。显著性图是一种图像处理的技术,主要用于突出图像中最重要(或“显著”)的部分,通常是最能吸引人眼球的那部分。在这里,我们主要关心的是如何使用这个技术来防御某些恶意的模型攻击。
现在,让我们逐一解析这段话的每一部分。
-
“计算所有图像(针对每个类别)的显著性图”:这里的意思是说,我们需要为数据集中的每张图像生成一个显著性图,突出其显著特征。例如,如果我们在处理一组图片,其中包括猫、狗和鸟的图片,我们就需要为每一类动物的每张图片生成一张显著性图。
-
“触发器是否紧凑且足够大决定了显著性图是否包含影响防御有效性的触发器区域”:触发器是指在恶意模型攻击中,攻击者植入模型中的特定模式或特征,当模型检测到这个模式或特征时,就会做出预定的反应。例如,攻击者可能会在一个图片识别模型中植入一个触发器,只要模型检测到某个特定的像素模式(比如一个红色的点),就会把图片识别成“猫”。这里的触发器是否紧凑且足够大,指的是这个触发器在图像中的表现形式。如果触发器很小或者分散,显著性图可能就无法准确突显出这个触发器,从而影响防御的效果。
-
“定位触发器区域通过找到不同图像中的普遍(共有的)显著区域”:显著性图突出了图像中最重要的部分,我们可以通过比较不同图像的显著性图,找出共有的显著区域,这个区域可能就是攻击者植入的触发器。
-
“触发器是样本无关的,否则,防御者很难证明触发器区域”:如果触发器只在某些特定的图片中出现,那么我们就很难在所有图片的显著性图中找到共有的显著区域,也就无法找到这个触发器。
所以,需要触发器是样本无关的,也就是说,触发器在所有的图片中都有可能出现。
-
-
这段话的详细解释:
所谓基于显著性图的防御,是一种试图在图像中找出可能存在的后门触发器的方法。显著性图是一个可以揭示图像中哪些区域对模型预测结果影响最大的图,如果某个区域在显著性图中显得很突出,那么这个区域就可能是后门触发器。
-
例如,假设我们有一个受到后门攻击的神经网络模型,攻击者在图像中插入了一个小红点作为后门触发器。当我们计算这张图像的显著性图时,如果这个小红点对模型的预测结果影响很大,那么它在显著性图中就会显得很突出,从而被我们识别出来。这就是第一步。
然而,这种方法的前提假设是,这个小红点是紧凑的(即它的影响区域是集中的),且足够大,才能在显著性图中被识别出来。如果小红点很小,或者它的影响区域分散在图像的多个部分,那么我们可能就无法通过显著性图找到它。
在第二步中,我们需要在不同的图像中找出共有的显著性区域,作为可能的后门触发器区域。这个步骤的前提假设是,后门触发器是样本无关的,即无论在哪张图像中,触发器都会出现在同样的区域,并产生同样的效果。如果触发器在不同的图像中出现的位置或效果不同,那么我们就很难确定哪个区域是真正的触发器区域。
STRIP的假设(The Assumption of STRIP.) STRIP[7]通过将各种图像模式叠加到可疑的图像上来检验一个恶意样本。如果生成样本的预测结果是一致的,那么这个被检验的样本就会被认为是被污染的样本。请注意,它的成功也依赖于假设背后的触发器是样本无关的。
-
(好)这段话的核心是对STRIP防御策略的描述。STRIP是一种防御策略,用来检测可能被恶意操控的图像样本。具体操作方式是,它会在可疑的图像上叠加各种图像模式,然后看叠加后的图像是否仍然保持原来的预测结果。如果预测结果一致,那么就有可能是原图像已经被恶意操控。但是,这种方法也是建立在一个假设之上,那就是后门触发器是样本无关的,也就是说,无论在什么样本上,后门触发器都有相同的效果。
举个例子来说,比如我们有一个可能被操控的图像,它的预测结果是“猫”。我们使用STRIP策略,在这个图像上叠加不同的图像模式,比如在上面叠加一只狗的图片、一张桌子的图片等等。叠加后我们得到一堆新的图像,然后我们再预测这些新的图像,如果预测结果仍然是“猫”,那么很可能原图像就已经被操控了,因为即使有其他元素叠加上去,预测结果仍然没有改变。但这个策略的前提是,后门触发器无论在什么样的图像上都有同样的效果。
-
这段话的中文翻译如下:
STRIP的假设。STRIP [7] 通过在可疑图像上叠加各种图像模式来检查一个恶意样本。如果生成的样本的预测结果是一致的,那么这个被检查的样本将被视为被污染的样本。注意,其成功也依赖于一个假设,即后门触发器是样本无关的。
-
这段话的详细解释:
STRIP是一种神经网络防御技术,它的工作原理是,对一个可疑的图像,叠加各种不同的图像模式,然后观察这些叠加后的图像被神经网络模型预测出的类别是否一致。如果预测结果是一致的,那么可以推断出,这个可疑的图像中可能存在一个后门触发器,因为无论叠加哪种图像模式,这个触发器都能引导模型做出同样的预测。
-
例如,假设我们有一个受到后门攻击的神经网络模型,攻击者在图像中插入了一个小红点作为后门触发器,当这个小红点出现时,模型就会预测出特定的类别。我们对一张可疑的图像,叠加了各种不同的图像模式,无论叠加哪种模式,模型都预测出了同样的类别,那么我们就有理由相信,这个小红点可能就是后门触发器。
然而,STRIP的成功也依赖于一个假设,即后门触发器是样本无关的。这是因为,如果触发器在不同的样本中有不同的表现,例如在某些样本中出现在图像的左上角,而在其他样本中出现在右下角,那么叠加的图像模式可能就无法覆盖到所有的触发器,导致模型的预测结果不一致,从而影响了STRIP的检测效果。
4. 样本特定的后门攻击(SSBA)
4.1. 威胁模型
攻击者的能力。我们假设攻击者可以对部分训练数据进行投毒,但他们无法获取或修改其他训练组件的信息(例如,训练损失、训练进度和模型结构)。在推理过程中,攻击者可以且只能对任意图像的训练模型进行查询。他们既没有关于模型的信息,也无法操纵推理过程。这是对后门攻击者的最低要求[21]。这种威胁可以在许多现实场景中发生,包括但不限于采用第三方训练数据、训练平台和模型API。
攻击者的目标。一般来说,后门攻击者试图通过污染数据在DNNs中嵌入隐藏的后门。隐藏的后门将由攻击者指定的触发器激活,即,包含触发器的图像的预测将是目标标签,无论其真实标签是什么。特别地,攻击者有三个主要目标,包括 效果,隐蔽性和持久性。 “效果”要求当后门触发器出现时,被攻击的DNNs的预测应该是目标标签,并且在良性测试样本上的性能不会显著降低;“隐蔽性”要求采用的触发器应该被隐藏,而且毒化样本(即,毒化率)的比例应该小;“持久性”要求攻击在一些常见的后门防御下仍然有效。
4.2. 提出的攻击
在这个部分,我们将说明我们提出的方法。在我们描述如何生成样本特定触发器之前,我们首先简要回顾一下攻击的主要过程,并介绍样本特定后门攻击的定义。
后门攻击的主要过程:设 D train = { ( x i , y i ) } i = 1 N \mathcal{D}_{\text{train}}=\left\{(\boldsymbol{x}_i, y_i)\right\}_{i=1}^{N} Dtrain={(xi,yi)}i=1N 表示包含 N 个独立同分布样本的良性训练集,其中 x i ∈ X = { 0 , ⋯ , 255 } C × W × H \boldsymbol{x}_i \in \mathcal{X}=\{0, \cdots, 255\}^{C \times W \times H} xi∈X={0,⋯,255}C×W×H 并且 y i ∈ Y = { 1 , ⋯ , K } y_i \in \mathcal{Y}=\{1, \cdots, K\} yi∈Y={1,⋯,K}。分类器学习一个具有参数 w \boldsymbol{w} w 的函数 f w : X → [ 0 , 1 ] K f_{\boldsymbol{w}}: \mathcal{X} \rightarrow[0,1]^{K} fw:X→[0,1]K。设 y t y_t yt 表示目标标签 ( y t ∈ Y ) (y_t \in \mathcal{Y}) (yt∈Y)。后门攻击的核心是如何生成毒化训练集 D p \mathcal{D}_p Dp。具体来说, D p \mathcal{D}_p Dp 由 D train \mathcal{D}_{\text{train}} Dtrain 的一个子集的修改版本(即, D m ) \left.\mathcal{D}_m\right) Dm) 和剩余的良性样本 D b \mathcal{D}_b Db 组成,即
D p = D m ∪ D b \mathcal{D}_p=\mathcal{D}_m \cup \mathcal{D}_b Dp=Dm∪Db
其中, D b ⊂ D train \mathcal{D}_b \subset \mathcal{D}_{\text{train}} Db⊂Dtrain, γ = ∣ D m ∣ ∣ D train ∣ \gamma=\frac{|\mathcal{D}_m|}{|\mathcal{D}_{\text{train}}|} γ=∣Dtrain∣∣Dm∣ 表示毒化率, D m = { ( x ′ , y t ) ∣ x ′ = G θ ( x ) , ( x , y ) ∈ D train \ D b } \mathcal{D}_m=\left\{(\boldsymbol{x}^{\prime}, y_t) \mid \boldsymbol{x}^{\prime}=G_{\boldsymbol{\theta}}(\boldsymbol{x}),(\boldsymbol{x}, y) \in \mathcal{D}_{\text{train}} \backslash \mathcal{D}_b\right\} Dm={(x′,yt)∣x′=Gθ(x),(x,y)∈Dtrain\Db}, G θ : X → X G_{\boldsymbol{\theta}}: \mathcal{X} \rightarrow \mathcal{X} Gθ:X→X 是攻击者指定的毒化图像生成器。 γ \gamma γ 越小,攻击越隐蔽。
定义1:如果对于所有的 x i , x j ∈ X \boldsymbol{x}_{i}, \boldsymbol{x}_{j} \in \mathcal{X} xi,xj∈X ( x i ≠ x j \boldsymbol{x}_{i} \neq \boldsymbol{x}_{j} xi=xj),都有 T ( G ( x i ) ) ≠ T ( G ( x j ) ) T\left(G\left(\boldsymbol{x}_{i}\right)\right) \neq T\left(G\left(\boldsymbol{x}_{j}\right)\right) T(G(xi))=T(G(xj)),那么就称具有毒化图像生成器 G ( ⋅ ) G(\cdot) G(⋅) 的后门攻击为样本特定的。这里, T ( G ( x ) ) T(G(\boldsymbol{x})) T(G(x)) 表示毒化样本 G ( x ) G(\boldsymbol{x}) G(x) 中包含的后门触发器。
注释1:之前的攻击触发器并非样本特定的。例如,对于在[3]中提出的攻击,对于所有的 x ∈ X \boldsymbol{x} \in \mathcal{X} x∈X,都有 T ( G ( x ) ) = t T(G(\boldsymbol{x}))=\boldsymbol{t} T(G(x))=t,其中 G ( x ) = ( 1 − λ ) ⊗ x + λ ⊗ t G(\boldsymbol{x})=(\mathbf{1}-\boldsymbol{\lambda}) \otimes \boldsymbol{x}+\boldsymbol{\lambda} \otimes \boldsymbol{t} G(x)=(1−λ)⊗x+λ⊗t。
让我们逐一解释这些数学公式和术语,以便理解。
这段文本描述了后门攻击的主要过程,以及如何定义样本特定的后门攻击。
-
D train = { ( x i , y i ) } i = 1 N \mathcal{D}_{\text{train}}=\left\{(\boldsymbol{x}_i, y_i)\right\}_{i=1}^{N} Dtrain={(xi,yi)}i=1N:这是训练数据集,包含N个样本,每个样本由一个输入向量 x i \boldsymbol{x}_i xi 和一个标签 y i y_i yi 组成。这些样本被假定为独立同分布。
-
x i ∈ X = { 0 , ⋯ , 255 } C × W × H \boldsymbol{x}_i \in \mathcal{X}=\{0, \cdots, 255\}^{C \times W \times H} xi∈X={0,⋯,255}C×W×H:每个输入向量 x i \boldsymbol{x}_i xi 都是一个图像,它在每个通道(例如,红色,绿色,蓝色)上都有一个矩阵,矩阵的大小是宽度W乘以高度H,每个像素的值在0到255之间。 C C C代表图像的颜色通道数量。
-
y i ∈ Y = { 1 , ⋯ , K } y_i \in \mathcal{Y}=\{1, \cdots, K\} yi∈Y={1,⋯,K}:每个标签 y i y_i yi 都是一个类别,它们中的每一个都属于集合 Y \mathcal{Y} Y,集合 Y \mathcal{Y} Y 包含从1到K的整数,其中K是类别的总数。
-
f w : X → [ 0 , 1 ] K f_{\boldsymbol{w}}: \mathcal{X} \rightarrow[0,1]^{K} fw:X→[0,1]K:这是分类器函数,它接受一个输入图像,返回一个 K K K维的向量,其中每个元素代表该图像属于对应类别的概率。
-
D p = D m ∪ D b \mathcal{D}_p=\mathcal{D}_m \cup \mathcal{D}_b Dp=Dm∪Db:毒化训练集是由修改过的样本集(即, D m \mathcal{D}_m Dm)和剩余的良性样本集( D b \mathcal{D}_b Db)组成的。
-
γ = ∣ D m ∣ ∣ D train ∣ \gamma=\frac{|\mathcal{D}_m|}{|\mathcal{D}_{\text{train}}|} γ=∣Dtrain∣∣Dm∣:这是毒化率,即被修改为含有后门的样本占训练集总样本的比例。
-
D m = { ( x ′ , y t ) ∣ x ′ = G θ ( x ) , ( x , y ) ∈ D train \ D b } \mathcal{D}_m=\left\{(\boldsymbol{x}^{\prime}, y_t) \mid \boldsymbol{x}^{\prime}=G_{\boldsymbol{\theta}}(\boldsymbol{x}),(\boldsymbol{x}, y) \in \mathcal{D}_{\text{train}} \backslash \mathcal{D}_b\right\} Dm={(x′,yt)∣x′=Gθ(x),(x,y)∈Dtrain\Db}:这是被修改过的样本集,其中每个样本的输入是通过一个由攻击者定义的函数 G θ G_{\boldsymbol{\theta}} Gθ 对原始输入进行修改得到的。
-
定义1:对于任何两个不同的输入图像,它们的毒化图像中的后门触发器也是不同的。
-
注释1:在以前的攻击中,触发器并不是样本特定的。例如,对于在引用 [3] 中提出的攻击,所有的毒化图像中的触发器都是相同的。
注:
这两个公式是在描述毒化过程和识别毒化触发器的过程。让我分别为您解释一下:
-
G θ ( x ) G_{\boldsymbol{\theta}}(\boldsymbol{x}) Gθ(x):这是一个由攻击者定义的函数,它负责将原始样本 x \boldsymbol{x} x转化为毒化样本。 θ \boldsymbol{\theta} θ表示这个函数的参数, x \boldsymbol{x} x是输入的原始样本。这个函数的主要作用是在原始样本中嵌入一个或者多个后门触发器,从而生成毒化样本。比如,一个简单的毒化函数可以将原始样本的一部分像素改变为特定的颜色,形成一个明显的标记。
-
T ( G ( x ) ) T(G(\boldsymbol{x})) T(G(x)):这个函数是用来识别毒化样本中的后门触发器的。 G ( x ) G(\boldsymbol{x}) G(x)生成了毒化样本,而 T ( G ( x ) ) T(G(\boldsymbol{x})) T(G(x))则是从毒化样本中提取出后门触发器。 简单来说,这个函数就是在识别“这个毒化样本中有哪些地方是被修改过的”。
所以,总的来说, G θ ( x ) G_{\boldsymbol{\theta}}(\boldsymbol{x}) Gθ(x)负责生成毒化样本, T ( G ( x ) ) T(G(\boldsymbol{x})) T(G(x))负责识别毒化样本中的后门触发器。而这两个函数中的 x \boldsymbol{x} x,都是指的原始样本。

图2. 我们的攻击流程。在攻击阶段,后门攻击者通过注入样本特定的触发器来污染一些良性训练样本。生成的触发器是看不见的添加性噪声,包含了目标标签代表性字符串的信息。在训练阶段,用户采用被污染的训练集通过标准训练过程来训练深度神经网络。相应地,从代表性字符串到目标标签的映射将会被生成。在推理阶段,被感染的分类器(即在被污染的训练集上训练的深度神经网络)在良性测试样本上的表现会正常,而当后门触发器被添加时,其预测将会改变为目标标签。

图3. 编码器-解码器网络的训练过程。编码器与解码器同时在良性训练集上进行训练。具体来说,编码器被训练为将字符串嵌入到图像中,同时最小化输入图像和编码图像之间的感知差异,而解码器则被训练为从编码图像中恢复隐藏的消息。
如何生成样本特定的触发器
如何生成样本特定的触发器。我们使用一个预训练的编码器-解码器网络作为一个例子来生成样本特定的触发器,这个想法受到基于DNN的图像隐写术 [2, 51, 39] 的启发。生成的触发器是看不见的添加性噪声,包含了目标标签的一个代表性字符串。这个字符串可以由攻击者灵活设计。例如,它可以是目标标签的名字,索引,甚至是一个随机字符。如图2所示,编码器接收一个良性图像和代表性字符串来生成被污染的图像(即,带有对应触发器的良性图像)。编码器与解码器同时在良性训练集上进行训练。特别地,编码器被训练成在最小化输入图像和编码图像之间的感知差异的同时将一个字符串嵌入到图像中,而解码器被训练成从编码图像中恢复隐藏的信息(这里指的是后门触发器)。他们的训练过程在图3中展示。注意,攻击者也可以使用其他方法,例如VAE [17],来进行样本特定的后门攻击。这将在我们未来的工作中进一步研究。
样本特定的后门攻击流程
样本特定的后门攻击流程。 一旦基于上述方法生成了被污染的训练集 D poisoned \mathcal{D}_{\text{poisoned}} Dpoisoned,后门攻击者将会将其发送给用户。用户将使用它通过标准训练过程来训练DNNs,即,
min w 1 N ∑ ( x , y ) ∈ D poisoned L ( f w ( x ) , y ) \min_{\boldsymbol{w}} \frac{1}{N} \sum_{(\boldsymbol{x}, y) \in \mathcal{D}_{\text{poisoned}}} \mathcal{L}\left(f_{\boldsymbol{w}}(\boldsymbol{x}), y\right) minwN1∑(x,y)∈DpoisonedL(fw(x),y) (2)
其中 L \mathcal{L} L 表示损失函数,如交叉熵。“优化”(2)可以通过反向传播 [33] 与随机梯度下降 [48] 来解决。在训练过程中,DNNs会学习从代表性字符串到目标标签的映射。 在推理阶段,攻击者可以通过基于编码器将触发器添加到图像中来激活隐藏的后门。
这是一个典型的机器学习优化问题的公式表示,具体来说,这是优化损失函数的表述。让我们分部分解析:
-
min w \min_{\boldsymbol{w}} minw:这部分表示我们的目标是最小化某个关于 w \boldsymbol{w} w(权重向量)的函数。在机器学习中,我们通常希望找到一组参数(在这里是权重 w \boldsymbol{w} w),使得损失函数最小。
-
1 N ∑ ( x , y ) ∈ D poisoned \frac{1}{N} \sum_{(\boldsymbol{x}, y) \in \mathcal{D}_{\text{poisoned}}} N1∑(x,y)∈Dpoisoned:这部分是一个求和运算,它遍历了数据集 D poisoned \mathcal{D}_{\text{poisoned}} Dpoisoned中的所有样本。 D poisoned \mathcal{D}_{\text{poisoned}} Dpoisoned表示被篡改(poisoned)的数据集。 x \boldsymbol{x} x代表输入数据, y y y代表对应的标签。 1 N \frac{1}{N} N1是对求和结果的正规化, N N N通常是数据集的样本总数,这样做可以使得损失值不依赖于数据集的大小。
-
L ( f w ( x ) , y ) \mathcal{L}\left(f_{\boldsymbol{w}}(\boldsymbol{x}), y\right) L(fw(x),y):这是损失函数。 f w ( x ) f_{\boldsymbol{w}}(\boldsymbol{x}) fw(x)表示的是模型(参数为 w \boldsymbol{w} w)对输入 x \boldsymbol{x} x的预测, L \mathcal{L} L是损失函数,它衡量的是模型预测和目标标签 y y y之间的差异。
-
目标标签 y y y 中部分是攻击者设定的目标标签,也有部分是原始真实标签。
所以,整个表达式的含义是:我们想要找到一组权重 w \boldsymbol{w} w,使得对于被篡改的数据集 D poisoned \mathcal{D}_{\text{poisoned}} Dpoisoned中的所有样本,模型预测与目标标签之间的平均损失最小。
5. 实验
5.1. 实验设置
数据集和模型
数据集和模型。 我们考虑两种经典的图像分类任务:(1) 对象分类object classification 和 (2) 人脸识别face recognition。对于第一个任务,我们在 ImageNet 数据集 [6] 上进行实验。为简便起见,我们随机选择了一个包含200个类别的子集,其中包含100,000张用于训练的图像(每个类别500张)和10,000张用于测试的图像(每个类别50张)。图像大小为 3 × 224 × 224。此外,我们采用 MS-Celeb-1M 数据集 [10] 进行人脸识别。在原始数据集中,大约有100,000个身份,每个身份包含的图像数量不等,范围从2到602。为了简化,我们选择了图片数量最多的前100个身份。更具体地说,我们得到了100个身份,总共有38,000张图片(每个身份380张)。训练集和测试集的划分比例设为8:2。对于所有图像,我们首先进行面部对齐,然后选择中心面部,并最终将其大小调整为3×224×224。我们使用 ResNet-18 [11] 作为两个数据集的模型结构。我们在补充材料中也进行了更多使用 VGG-16 [38] 的实验。

实验比较基准
实验比较基准。我们将提出的针对特定样本的后门攻击与 BadNets [8] 和典型的采用混合策略的隐形攻击(被称为 Blended Attack)[3] 进行比较。我们还提供在良性数据集上训练的模型(称为标准训练 StandardTraining)作为另一个参考基准。此外,我们选择了Fine-Pruning [24],Neural Cleanse [41],SentiNet [5],STRIP [7],DF-TND [42] 和 Spectral Signatures [40]来评估对最先进防御的抵抗力。

图 4. 不同攻击生成的被毒化样本。BadNets和Blended Attack使用带有十字线的白色正方形(红色框中的区域)作为触发模式,而我们的攻击触发器是对整个图像的样本特定的不可见的附加噪声。
攻击设置
攻击设置。 我们设定在两个数据集上的所有攻击的毒化率 γ = 10 % \gamma=10\% γ=10% 和目标标签 y t = 0 y_{t}=0 yt=0。如图 4 所示,对于BadNets和Blended Attack,被毒化图像的后门触发器是一个位于右下角的带有十字线的 20 × 20 20 \times 20 20×20 的白色正方形,混合攻击的触发器透明度设置为 10 % 10\% 10%。我们方法的触发器是由在良性训练集上训练的编码器生成的。具体来说,我们遵循StegaStamp [39]中的编码器-解码器网络的设置,其中我们使用U-Net [32]样式的DNN作为编码器,使用空间变换网络 [15]作为解码器,并使用四个损失项进行训练: L 2 L_{2} L2 残差正则化,LPIPS 感知损失 [47],一个批评损失,以最小化编码图像的感知失真,以及一个交叉熵损失用于代码重构。四个损失项的缩放因子分别设置为2.0,1.5,0.5和1.5。对于所有编码器-解码器网络的训练,我们使用Adam优化器 [16]并将初始学习率设置为0.0001。批处理大小和训练迭代次数分别设置为16和140,000。此外,在训练阶段,我们使用SGD优化器并将初始学习率设置为0.001。批处理大小和最大周期分别设置为128和30。在周期15和20后,学习率以0.1的因子衰减。
补充:
攻击实验
-
毒样本:对于每一个数据集, 我们设毒样本在占所有样本的 10 % , 目标标签为 y t = 0 y_{t}=0 yt=0;
-
Trigger的制作 : BadNet和Blended Attack的trigger位于图像的右下角, 且尺寸为 20 × 20 20 \times 20 20×20 , 由两条相互垂直的线将trigger均分为 4 块:
- Blended Attack的trigger和BadNet的不同点在于BadNet是直接将trigger添加到图像的右下角, 而Blended Attack的trigger是按 照一个透明系数(实验中设置为 10 % 10 \% 10% )和图像加权平均得到最后的带trigger的图片;
- SSBA (作者提出的方法) 的trigger从肉眼是看不清的, 它是以干净的样本和目标类标签字符串拼接构成训练集, 来训练生成 trigger的编码器 【注解:它是直接拿StegaStamp图像隐写的模型来用,具体详细方法可以阅读StegaStamp的文献】;
-
训练植入后门的模型的相关参数设置: 采用 SGD 优化器, 初始化学习率为 l r = 0.001 lr=0.001 lr=0.001 , b a t c h S i z e = 128 batchSize =128 batchSize=128 ,总的迭代次数 max E p o c h = 30 \max Epoch =30 maxEpoch=30 , 学习率在第 15 轮以及 20 轮之后, 以衰减因子为 0.1 的方式衰减
防御设置
**防御设置。**对于 Fine-Pruning,我们修剪 ResNet-18 的最后一个卷积层(Layer4.conv2);对于 Neural Cleanse,我们采用其默认设置,并使用生成的异常指数进行演示。异常指数的值越小,攻击防御越难;对于 STRIP,我们也采用其默认设置,并展示生成的熵得分。分数越大,攻击防御越难;对于 SentiNet,我们比较了被毒化样本的生成 Grad-CAM [35] 以供展示;对于 DF-TND,我们报告了每个类别的全局对抗攻击前后的logit增加分数。如果目标标签的分数显著高于所有其他类别的分数,那么这种防御就会成功。对于 Spectral Signatures,我们报告了每个样本的离群值得分,得分越高,样本可能被毒化的可能性越大。
评价指标
评价指标。 我们使用攻击成功率(ASR)和良性精度(BA)来评估不同攻击的有效性。具体来说,ASR定义为成功攻击的毒化样本与总毒化样本之间的比率。BA定义为在良性样本上测试的准确性。此外,我们采用峰值信噪比(PSNR)[14] 和 ℓ ∞ \ell ^{\infty} ℓ∞ 范数 [12] 来评估隐蔽性。
这段话中提到了四个评估指标:
-
攻击成功率 (Attack Success Rate, ASR):成功攻击的毒样本数占总毒样本数的比例。这个指标 越高越好,因为它表示攻击的成功率。如果ASR高,说明攻击方法更有效。
-
良性准确率 (Benign Accuracy, BA):在良性样本上的准确率。这个指标也是 越高越好,因为它表示模型在未受攻击的样本上的表现。如果BA高,说明模型对于正常样本的识别效果良好。
-
峰值信噪比 (Peak Signal-to-Noise Ratio, PSNR):用于评估隐蔽性的一种指标,表示原始图像和攻击后的图像之间的差异程度。这个指标 越高越好,因为它表示攻击的隐蔽性更好。PSNR高,说明攻击后的图像与原图像的差异小,攻击更难被察觉。
-
无穷范数 ( ℓ ∞ \ell^{\infty} ℓ∞ norm):也用于评估隐蔽性,表示原始图像和攻击后的图像之间的最大差异。这个指标 越低越好,因为它表示攻击的隐蔽性更好。无穷范数小,说明攻击后的图像与原图像的最大差异小,攻击更难被察觉。
总的来说,这四个指标都是用来评估攻击方法的有效性和隐蔽性的。有效性主要通过ASR和BA来衡量,隐蔽性主要通过PSNR和无穷范数来衡量。
5.2. 主要结果

表1. 不同方法在ImageNet和MS-Celeb-1M数据集上对无防御的DNNs的比较。在所有攻击中,最好的结果以粗体表示,下划线表示第二好的结果。
良性准确率 (Benign Accuracy, BA) —— 越高越好
攻击成功率 (Attack Success Rate, ASR) —— 越高越好
峰值信噪比 (Peak Signal-to-Noise Ratio, PSNR) —— 越高越好
无穷范数 ( ℓ ∞ \ell^{\infty} ℓ∞ norm) —— 越低越好
攻击有效性。 如表1所示,我们的攻击只需毒化训练样本的一小部分(10%)就能成功创建具有高ASR的后门。具体来说,我们的攻击在两个数据集上都可以实现ASR > 99%。此外,我们的方法的ASR与BadNets相当,并且高于Blended Attack。此外,与标准训练相比,我们的攻击对良性测试样本的准确性在两个数据集上降低都不到 1%,这比 BadNets 和 Blended Attack 导致的降低小。这些结果表明,样本特定的不可见加性噪声(每个样本都有其特定的噪声,这种噪声是加在原始图像上的,并且这种噪声是人眼无法察觉的)可以有效地作为触发器,尽管它们比 BadNets 和 Blended Attack 中使用的白色方块更复杂。
攻击隐蔽性。 图4展示了由不同攻击生成的一些毒化图像。虽然我们的攻击在PSNR和 ℓ ∞ \ell ^{\infty} ℓ∞方面的隐蔽性并非最好(我们是第二好的,如表1所示),但我们方法生成的毒化图像在人工检查时仍然看起来自然。尽管Blended Attack似乎在采用的评估指标方面具有最好的隐蔽性,但他们生成的样本中的触发器仍然相当明显,特别是在背景是暗色的情况下。
时间分析。 在ImageNet上训练编码器-解码器网络需要7小时35分钟,在MS-Celeb1M上需要3小时40分钟。平均编码时间为每张图像0.2秒。

图5. 不同攻击对基于剪枝的防御的良性准确率(BA)和攻击成功率(ASR)。
抗Fine-Pruning。 在这部分,我们比较我们的攻击与BadNets和Blended Attack在对抗基于剪枝的防御 [24] 方面的性能。如图5所示,当剪枝20%的神经元时,BadNets和Blended Attack的ASR会显著下降。尤其是Blended Attack,其在ImageNet和MS-Celeb-1M数据集上的ASR下降至不到10%。相比之下,我们的攻击的ASR随着剪枝神经元的比例的增加只有轻微的下降(小于5%)。当剪枝神经元的20%时,我们的攻击在两个数据集上的ASR仍然大于95%。这表明我们的攻击更能抵抗基于剪枝的防御。

图6. Neural Cleanse生成的合成触发器。图中的红色框表示真实的触发器区域。

图8. 不同攻击的异常指数。指数越小,Neural-Cleanse防御起来越难。
抗Neural Cleanse。 Neural Cleanse [41] 计算触发候选项以将所有良性图像转换为每个标签。然后,它采用一个异常检测器来验证是否有人显著小于其他人作为后门指标。异常指数的值越小,Neural-Cleanse防御攻击就越困难。如图8所示,我们的攻击对Neural-Cleanse的抵抗性更强。此外,我们还可视化了不同攻击的合成触发器(即所有候选者中异常指数最小的一个)。如图6所示,BadNets和Blended Attack的合成触发器包含与攻击者使用的类似的模式(即右下角的白色方块),而我们攻击的触发器则无意义。
补充说明:
Neural Cleanse[41]是一种防御手段,它会尝试计算出触发器候选项,使得所有的正常(无害)图像都转换为每个类别的标签。接着,它会使用一种异常检测器来验证是否有某个触发器明显小于其他触发器,如果有,那么这就是一种后门攻击的指标。在这个背景下,异常指数值越小,那么就能更好地抵抗Neural Cleanse的防御。
如图8所示,作者的攻击方式对Neural Cleanse的防御具有更强的抵抗力。也就是说,作者的攻击方式更难被Neural Cleanse检测出。
此外,作者还可视化了不同攻击方式的合成触发器(即在所有候选触发器中,异常指数最小的那一个)。如图6所示,BadNets和Blended Attack的合成触发器包含了与攻击者使用的相似的模式(即,右下角的白色方块),而作者的攻击方式产生的合成触发器却没有任何明显的意义,这使得它更难被检测出。
简单来说,作者的攻击方式对于Neural Cleanse的防御手段具有更强的抵抗力,这是因为它产生的触发器更难被识别出。
这段话讨论了对抗“Neural Cleanse”防御技术的抵抗力。Neural Cleanse是一种防御机制,它计算所有不同标签的潜在触发器,并使用异常检测器来检查是否有任何一个触发器的大小明显小于其他的,这个小的触发器被看做是后门攻击的指标。这个异常指数的值越小,那么就能更好地抵抗Neural Cleanse的防御。
从图 8 中可以看出,作者的攻击方法更能抵抗 Neural Cleanse。此外,作者还可视化了不同攻击方法的合成触发器,即在所有可能触发器中,异常指数最小的那个。从图 6 可以看出,BadNets 和 Blended Attack 的合成触发器中包含了与攻击者使用的模式相似的元素(也就是右下角的白色方块),而作者的攻击方法生成的触发器看起来没有任何意义,也就是说,他们的触发器更难被理解和识别,这也使得他们的攻击更难被检测到。

图9. STRIP生成的不同攻击的熵。熵越高,STRIP防御起来越难。
抗STRIP。 STRIP [7] 根据对可疑图像施加各种图像模式生成的样本的预测随机性筛选出毒化样本。随机性是通过那些样本的平均预测的熵来衡量的。因此,熵越高,STRIP防御攻击就越困难。如图9所示,我们的攻击比其他攻击更能抵抗STRIP。
补充说明:
这段话的另一种中文翻译如下:
对STRIP的抵抗性。STRIP[7]是一种防御手段,它基于对可疑图像施加各种图像模式生成的样本的预测随机性来过滤掉被篡改的样本。这种随机性是通过那些样本的平均预测的熵来衡量的。因此,熵越高,对STRIP的攻击防御就越困难。如图9所示,我们的攻击方式相比其他攻击方式对STRIP具有更强的抵抗性。
这段话的分析如下:
这段话主要讲述了作者的攻击方式在对抗STRIP防御时的优越性。STRIP是一种防御手段,它通过计算由可疑图像生成的样本预测的熵来过滤被篡改的样本。熵在这里被用作一种衡量随机性的方法,熵值越高,说明生成的样本预测的随机性越大,也就更难被STRIP检测出。因此,如果一个攻击方式能产生高熵值,那么就能更好地抵抗STRIP的防御。在图9中,作者展示了他们的攻击方式能产生相比其他攻击方式更高的熵值,因此在对抗STRIP防御时具有更强的抵抗性。
图7. 不同攻击生成的毒化样本的Grad-CAM。如图所示,Grad-CAM成功地区分出了BadNets和Blended Attack生成的触发区域,而对我们的攻击(our attack, 本文的攻击方法)生成的触发区域则未能检测到。
抗SentiNet。 SentiNet [5] 根据不同样本的Grad-CAM的相似性识别触发区域。如图7所示,Grad-CAM成功区分了由BadNets和Blended Attack生成的触发区域,而无法检测到由我们的攻击生成的触发区域。换句话说,我们的攻击(our attack, 本文的攻击方法)对SentiNet的抵抗性更强。

图10. 我们的攻击在DF-TND下的logit增加。如果目标标签的增加显著大于所有其他类别的增加,那么这种方法就可以成功。
抗DF-TND。 DF-TND [42] 通过观察每个标签在手工制作的通用对抗攻击前后的logit增加,来检测是否一个可疑的DNN包含隐藏的后门。如果目标标签的logit增加唯一地处于峰值,那么这种方法就会成功。为了公平的演示,我们对其超参数进行了微调,以寻找对我们的攻击最佳的防御设置(更多细节请参见补充材料)。如图10所示,目标类别的logit增加(图中的红色条)在两个数据集上都不是最大的。这表明我们的攻击也可以绕过DF-TND。
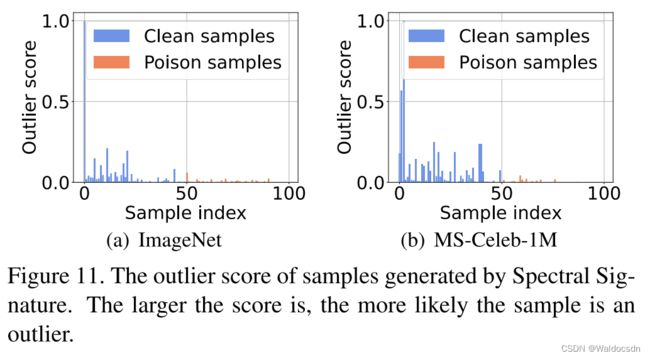
图11. Spectral Signature生成的样本的异常分数。分数越大,样本越可能是异常。
抗Spectral Signatures。 Spectral Signatures [40] 发现后门攻击可以在特征表示的协方差的谱中留下可检测的痕迹。这种痕迹就是所谓的Spectral Signatures,它是使用奇异值分解来检测的。这种方法为每个样本计算一个离群值得分。如果清洁样本的值小,毒化样本的值大,那么它就会成功(更多细节请参见补充材料)。如图11所示,我们测试了100个样本,其中0 ∼ 49是清洁样本,50 ∼ 100是毒化样本。我们的攻击显著扰乱了这种方法,使得清洁样本有意外的大得分。
5.3. 讨论
攻击成功率 (Attack Success Rate, ASR) —— 越高越好
良性准确率 (Benign Accuracy, BA) —— 越高越好
峰值信噪比 (Peak Signal-to-Noise Ratio, PSNR) —— 越高越好
无穷范数 ( ℓ ∞ \ell^{\infty} ℓ∞ norm) —— 越低越好

表2注:之前实验中,作者设置的有毒样本的目标标签都是0。
在这一部分,除非另有说明,所有设置都与第5.1节中所述的设置相同。
不同目标标签的攻击。 我们用不同的目标标签 ( y t \boldsymbol{y}_{t} yt = 1, 2, 3) 测试我们的方法。表2显示了我们攻击的BA/ASR,揭示了我们方法在使用不同目标标签时的有效性。

图12. 毒化率对我们的攻击的影响。
毒化率 γ \gamma γ 的影响。 在这部分,我们讨论了毒化率 γ \gamma γ 对我们攻击中ASR和BA的影响。如图12所示,通过只毒化2%的训练样本,我们的攻击在两个数据集上都达到了高ASR (> 95%)。此外,随着 γ \gamma γ 的增加,ASR会增加,而BA几乎保持不变。换句话说,在我们的方法中,ASR和BA之间几乎没有权衡。然而, γ \gamma γ的增加也会降低攻击的隐蔽性。攻击者需要根据自己的具体需求指定此参数。

表3:“本文我们的攻击方式”的ASR(%),使用一致触发器(称为“Ours”)或不一致触发器(称为“Ours(inconsistent)”)。不一致触发器是基于另一张测试图像生成的。 (表3直接看英文)
表3展示的是两种不同触发器情况下的攻击成功率(ASR)。这两种触发器分别是"一致的"(consistent)触发器和"不一致的"(inconsistent)触发器。
“一致的”(consistent)触发器,指的是触发器是基于同一张图像生成的。具体来说,如果我们有一个测试图像 x \boldsymbol{x} x,我们将使用基于 x \boldsymbol{x} x 生成的触发器来进行攻击测试。
“不一致的”(inconsistent)触发器,指的是触发器是基于不同的图像生成的。具体来说,对于每一张测试图像 x \boldsymbol{x} x,我们随机选择另一张测试图像 x ′ \boldsymbol{x}' x′,然后我们使用基于 x ′ \boldsymbol{x}' x′ 生成的触发器来进行攻击测试。
在表3中,“Ours”代表的是使用一致的触发器进行攻击的情况,“Ours (inconsistent)”代表的是使用不一致的触发器进行攻击的情况。
如果攻击成功率在使用不一致的触发器时明显下降,这就意味着这种攻击方法生成的触发器具有很强的图像特异性,即它只对生成它的特定图像有效,而对其他图像无效或者效果较差。
生成触发器的专属性:在这部分,我们探究生成的样本特定触发器是否是独特的,也就是说,使用基于另一图像生成的触发器的测试图像是否也能激活我们方法攻击的深度神经网络的隐藏后门。具体来说,对于每个测试图像 x \boldsymbol{x} x,我们随机选择另一个测试图像 x ′ \boldsymbol{x}' x′( x ′ ≠ x \boldsymbol{x}' \neq \boldsymbol{x} x′=x)。现在,我们用 x + T ( G ( x ′ ) ) \boldsymbol{x}+T\left(G\left(\boldsymbol{x}'\right)\right) x+T(G(x′))(而不是 x + T ( G ( x ) ) \boldsymbol{x}+T(G(\boldsymbol{x})) x+T(G(x)))来查询被攻击的深度神经网络。如表3所示,当在ImageNet数据集上使用不一致的触发器(即,基于不同图像生成的触发器)时,ASR会急剧下降。然而,在MS-Celeb-1M数据集上,使用不一致的触发器进行攻击仍然可以实现高ASR。这可能是因为大多数面部特征相似,因此学习的触发器具有更好的泛化性。我们将在未来的工作中进一步探索这个有趣的现象。
解释1:
这段话的主要目标是探讨生成的样本特定触发器的专属性,也就是它们是否只对生成它们的图像有影响,对其他图像则无效或效果较差。在这个实验中,他们使用了从另一张图像中生成的“不一致”触发器对另一张图像进行攻击,看这样的攻击是否仍能成功。
表3中的结果表明,在ImageNet数据集上,使用这种“不一致”触发器的攻击成功率显著下降,这证明了生成的触发器对于其生成图像的特异性。然而,对于MS-Celeb-1M数据集(主要是人脸图像),即使使用“不一致”的触发器,攻击的成功率仍然很高。作者推测,这可能是因为大部分面部特征都很相似,所以学习的触发器具有更好的泛化能力。这个有趣的现象将在他们的未来工作中进一步探究。
解释2:
这段话中,作者们在尝试说明他们生成的样本特定触发器(每个图像都有自己的触发器)是否是独特的,也就是,一个触发器是否只对生成它的图像有效,对其他图像无效。他们这样做的方法是:对于每一张测试图像,他们随机选取另一张测试图像,并用这张图像的触发器去测试原图像。
在他们的实验中,他们发现在 ImageNet 数据集上,如果使用和原图像不一致的触发器进行测试,成功的攻击率(ASR)会大幅下降。这说明在这个数据集上,触发器是具有独特性的,也就是说,一个触发器只对生成它的那张图像有效。
然而,他们在 MS-Celeb-1M 数据集(一个人脸数据集)上进行同样的测试时,发现即使使用和原图像不一致的触发器,成功的攻击率仍然很高。他们猜测这可能是因为在这个人脸数据集中,大多数的面部特征都是相似的,所以触发器可能对多个图像都有效。
这个现象在未来的工作中值得进一步探索。因为如果触发器的独特性可以得到保证,那么攻击者就无法通过其他图像的触发器来激活原图像的后门,从而提高了系统的安全性。
解释3:
这段文字主要是在探讨攻击中生成的样本特定触发器的特性。这里的触发器是用于激活神经网络隐藏后门的信号。
“独特性”(Exclusiveness)的概念,指的是这些触发器是否只针对生成它们的特定样本有效,换句话说,基于一个样本生成的触发器是否能对其他样本同样有效。
他们进行的实验是这样的:对于每一张测试图片 x \boldsymbol{x} x,他们随机选择另一张测试图片 x ′ \boldsymbol{x}' x′ ( x ′ ≠ x \boldsymbol{x}' \neq \boldsymbol{x} x′=x)。然后,他们用 x + T ( G ( x ′ ) ) \boldsymbol{x}+T\left(G\left(\boldsymbol{x}'\right)\right) x+T(G(x′)) 去查询受到攻击的神经网络,也就是说他们使用基于 x ′ \boldsymbol{x}' x′ 的触发器去试图激活 x \boldsymbol{x} x 中的隐藏后门。
实验结果发现,在ImageNet数据集上,当使用这种基于其他图像生成的“不一致的触发器”,攻击成功率(ASR)大幅下降。这说明在ImageNet数据集上,由特定样本生成的触发器对其他样本的效果显著降低,即触发器具有较高的独特性。
然而,在MS-Celeb-1M数据集上,即使使用这种不一致的触发器,攻击成功率仍然较高。这可能是因为这个数据集主要包含人脸图像,人脸图像中的面部特征比较相似,因此基于一个样本生成的触发器对其他样本也有较好的效果。这表明在这个数据集上,触发器的独特性较低。作者表明他们将在未来的工作中进一步探索这个现象。

表4:在攻击阶段我们的方法的数据集外泛化性。具体内容请看文本。
在攻击阶段的数据集外泛化:回忆一下,编码器在先前的实验中是在被污染训练集的良性版本上训练的。在这部分,我们探究在我们的攻击中,是否能将在另一个数据集上训练的编码器(没有任何微调)仍然适应生成新数据集的被污染样本。如表4所示,一个在另一个数据集上训练的编码器进行攻击的有效性与在同一数据集上训练的编码器相当。换句话说,如果图像大小相同,攻击者可以重用已经训练过的编码器来生成被污染的样本。这个特性将显著降低我们的攻击的计算成本。
解释1:
这段话是在讨论攻击阶段的“数据集外泛化”,也就是说,一个在特定数据集上训练的编码器是否可以用来在另一个完全不同的数据集上生成有毒的样本。在他们的实验中,他们发现,即使是在一个不同的数据集上训练的编码器,其进行攻击的效果与在同一个数据集上训练的编码器相当。
这是一个重要的发现,因为这意味着攻击者可以重用已经训练好的编码器来生成有毒的样本,只要这些样本的图像大小是一样的。这大大减少了攻击者需要进行的计算,因为他们不再需要为每一个新的目标数据集从头开始训练新的编码器。这个特性提高了这种攻击的效率和可扩展性。
解释2:
在深度学习模型中,数据集外泛化是一个重要的概念,它描述的是模型在训练数据集以外的数据上的性能。良好的数据集外泛化意味着模型能够很好地适应和处理它在训练阶段从未见过的数据。
在这篇论文中,作者们在研究他们的攻击算法是否具有数据集外泛化能力。具体来说,他们想知道是否可以使用在一个数据集上训练的编码器,来生成另一个不同数据集的有毒样本。这就是他们所说的“在攻击阶段的数据集外泛化”。
为了验证这一点,他们进行了实验,发现在一个数据集上训练的编码器可以生成另一个数据集的有毒样本,并且效果与在同一数据集上训练的编码器相当。换句话说,这个编码器能够处理和生成它在训练阶段从未见过的数据上的有毒样本,显示出了良好的数据集外泛化能力。
这个发现对于攻击者来说非常有利,因为他们可以重复使用已经训练好的编码器来攻击不同的数据集。这样就不需要为每个新的目标数据集从头开始训练一个新的编码器,大大节省了计算成本和时间。

表5. 我们的方法被数据集外测试样本攻击的ASR(%)。请参阅文本以获取详细信息。
推理阶段的数据集外泛化。在这部分,我们验证了数据集外的图像(带有触发器)是否可以成功攻击我们方法攻击的DNNs。我们选择了Microsoft COCO数据集 [23] 和一个合成噪声数据集进行实验。它们分别代表了自然图像和合成图像。具体来说,我们随机从Microsoft COCO中选取了1,000张图像,并生成了1,000张合成图像,每个像素值都从{0, · · · , 255}中均匀随机选取。所有选定的图像都调整为3 × 224 × 224。如表5所示,我们的攻击可以根据数据集外的图像生成的毒化样本也可以达到近乎100%的ASR。这表明,攻击者可以使用数据集外的图像(不必使用测试图像)激活被攻击的DNNs中的隐藏后门。
解释1:
在这一部分,作者们进一步验证了他们的攻击方法的泛化性。他们想看看是否可以用不在训练集和测试集中的图像(称为数据集外图像)来成功攻击已经被他们的方法攻击过的深度神经网络。也就是说,他们想看看这些数据集外的图像(当然,这些图像会添加相应的触发器),能否成功触发已经嵌入到网络中的后门。
实验结果显示,这种基于数据集外图像的攻击方法确实可以达到接近100%的攻击成功率。这说明,攻击者并不一定需要使用在训练和测试阶段看到的图像来触发后门,他们也可以使用不在这些数据集中的图像来成功触发后门。这进一步提高了他们攻击方法的灵活性和通用性。
解释2:
表格5是关于该研究中测试的一种特殊情况的数据。具体来说,研究者们在这个实验中试图了解他们的攻击方法是否能够成功地在"数据集外"的图像上施加影响。
"数据集外"指的是那些在训练或测试过程中没有用过的图像。换句话说,这些是模型从未见过的图像。为了测试这一点,研究者们从Microsoft COCO数据集中随机选取了1,000张图像,此外,他们还生成了1,000张由随机像素值组成的合成图像。
研究者们的目标是看看他们能否使用这些数据集外的图像成功地攻击他们已经修改过的深度神经网络。他们的攻击主要通过在图像中插入某种模式或"触发器"来实现,这种模式会导致网络做出特定的预测。
实验结果显示,即使是这些数据集外的图像,只要添加了适当的触发器,也能够成功地触发网络中的后门,使其产生预期的预测结果。这种能力意味着这种攻击方法具有很高的泛化性,因为它不仅可以对在训练和测试过程中使用过的图像进行攻击,而且还可以对网络从未见过的图像进行攻击。
这一部分的内容是关于在推理阶段(模型已经训练完成,用于实际预测)进行数据集外泛化的实验。让我们来解释一下。
在深度神经网络被训练好以后,它将被用于新的、未见过的数据,这就是所谓的推理阶段。在这个阶段,网络的性能会受到新数据的质量和与训练数据的相似性的影响。特别是当这些新的测试数据来自于一个与训练数据集不同的数据集(即数据集外的数据)时,可能会影响网络的性能。
在这篇论文中,作者想要测试他们的攻击方法是否可以有效地在数据集外的数据上触发已经被植入的后门。为了实验,他们选择了来自于Microsoft COCO数据集的自然图像和一组合成的噪声图像,来作为数据集外的测试数据。他们随机选择了1000张来自Microsoft COCO数据集的图像,并生成了1000张噪声图像,这些图像的每个像素值都是在集合 { 0 , ⋯ , 255 } \{0, \cdots, 255\} {0,⋯,255}中均匀随机选择的。所有选定的图像都被调整为 3 × 224 × 224 3 \times 224 \times 224 3×224×224的尺寸。
结果在表5中展示,作者发现他们的攻击方法在基于数据集外图像生成的有毒样本上也能达到近乎100%的攻击成功率(ASR)。这说明攻击者可以使用来自数据集外的图像成功地激活被攻击的深度神经网络中的隐藏后门,而这些图像并不一定需要是测试图像。
换句话说,这意味着即使攻击者没有直接访问到用于测试的图像,他们仍然可以使用其他来源的图像(如Microsoft COCO数据集或合成噪声图像)成功地触发已被植入的后门。这是一个很重要的发现,因为它进一步扩大了攻击者可以使用的图像的范围,并显示了这种攻击方法的灵活性和泛化能力。
6. 结论
在本文中,我们展示了现有的后门攻击大部分可以被当前的后门防御轻松缓解,主要是因为他们的后门触发器是对样本无关的,也就是说,不同的毒化样本包含相同的触发器。基于这个理解,我们探索了一种新的攻击模式,即特定样本的后门攻击(SSBA),其中后门触发器是对样本特定的。我们的攻击打破了防御的基本假设,因此可以绕过它们。具体来说,我们通过将攻击者指定的字符串编码到良性图像中,生成了特定样本的无形附加噪声作为后门触发器,这是由基于DNN的图像隐写术所启发的。当DNNs在毒化数据集上训练时,将从字符串到目标标签的映射学习出来。我们进行了大量的实验,验证了我们的方法在攻击有防御和无防御的模型方面的有效性。
致谢。Yuezun Li的研究部分受到中国博士后科学基金会资助,项目编号为2021TQ0314。Baoyuan Wu受到中国自然科学基金的支持,项目编号为62076213,中国香港大学深圳分校的大学发展基金的支持,项目编号为01001810,深圳大数据研究院特别项目基金的支持,项目编号为T00120210003,以及深圳科技计划的支持,项目编号为GXWD2020123110572200220200901175001001。Siwei Lyu受到自然科学基金的支持,项目编号为IIS-2103450和IIS-1816227。
论文解析
重要参考文章
论文笔记(精读文章) - Invisible Backdoor Attack with Sample-Specific Triggers
独立同分布
“独立同分布样本"是一个常用的统计术语,通常简写为"i.i.d.”,其中 “i.i.d.” 是 “independent and identically distributed” 的缩写。
这个术语的含义可以分为两部分:
-
“独立(independent)”:这意味着每一个样本的出现不依赖于其他样本的出现。换句话说,获取一个样本的结果并不会影响或改变获取下一个样本的结果。
-
“同分布(identically distributed)”:这意味着所有样本都来自同一概率分布。换句话说,所有样本的来源或生成方式是相同的,它们具有相同的概率特性。
例如,如果你从一副扑克牌中随机抽出一张牌,然后放回,再随机抽出一张,这样的过程重复多次,那么每次抽出的牌就是独立同分布的。每次抽牌是独立的,因为每次抽牌并不受前一次抽牌的影响(前提是你每次都将牌放回),而且每次抽牌都来自同一副牌,因此它们是同分布的。
说说几种神经网络防御方法:Fine-Pruning、Neural Cleanse、STRIP、SentiNet、DF-TND、Spectral Signatures
-
Fine-Pruning: 这是一种针对后门攻击的防御方法。Fine-Pruning的核心思想是,由于后门攻击通常会在模型参数中留下某种痕迹,通过对模型进行精细剪枝,可以有效地消除这些痕迹,从而消除后门。剪枝过程中会按照参数的重要性进行排序,重要性较低的参数首先被剪除,因此潜在的后门攻击效应有更高的可能性被剪除。
-
Neural Cleanse: Neural Cleanse是一种检测模型是否受到后门攻击的方法。它的工作方式是通过反向工程在输出端找到最小的触发器。理论上,一个未受攻击的模型应该需要较大的改变才能改变预测结果,而一个受到后门攻击的模型则可能只需要较小的触发器。通过比较这个最小触发器的大小,可以评估模型是否可能受到后门攻击。
-
STRIP (STochastic Resampling for Input Perturbation):STRIP 是一种防御对抗性攻击的策略,其目标是在推断阶段扰乱对抗性攻击的效果。这种方法通过对输入进行随机重采样来增加额外的噪声,以干扰对抗性攻击的效果。因为对抗性攻击通常需要精确的控制输入的每个像素,所以通过引入随机噪声,可以有效地防御这种攻击。
-
SentiNet: SentiNet 是一种对抗性防御方法,其使用了名为 “SentiNet Mask” 的特殊掩码,通过这个掩码可以感知到对抗性攻击,并根据情况调整模型的输出。此外,SentiNet 还利用神经网络的梯度信息来帮助检测对抗性攻击。
-
DF-TND (DeepFense by Tractable Nonlinear Defense):DF-TND 是一种防御深度学习攻击的策略,其主要思想是通过对模型的前向传播过程引入一种可处理的非线性防御机制。这种防御机制可以让模型对输入的轻微改变表现出更强的稳健性,从而对抗攻击。
-
Spectral Signatures: Spectral Signatures 是一种基于模型的谱分析进行防御的策略。它利用了模型权重在频谱空间中的特性来检测可能存在的对抗性攻击。在理论上,正常训练的模型与受到对抗性攻击的模型在频谱空间中的表现应该有所不同,因此可以利用这个特性进行防御。
以上这些方法各有优点和缺点,对于不同类型和强度的攻击,其效果可能会有所不同。在实际应用中,可能需要结合多种方法来达到最佳的防御效果。
再解释下Neural Cleanse
Neural Cleanse是一种检测和缓解神经网络后门攻击的方法。后门攻击是指在模型训练过程中,攻击者将一些带有特殊模式(即触发器)的恶意样本注入到训练集中。然后,当这个模型在部署时遇到含有同样触发器的样本,它将产生攻击者期望的输出,而不是正确的输出。这种攻击对于模型的使用者来说是难以察觉的,因为除非输入中包含触发器,否则模型的行为看起来是正常的。
Neural Cleanse的目标是检测并消除这种后门攻击。它使用了一种反向工程的方法,通过修改模型的输入,观察输出的变化,来寻找可能的后门触发器。在理论上,如果模型未受到攻击,那么改变输入的一小部分不应该导致输出的显著变化。相反,如果模型受到了后门攻击,那么在输入中加入后门触发器就可能引起输出的显著变化。
具体来说,Neural Cleanse首先为模型的每个输出类别找到一个最小的触发器,即改变输入的最小程度以使模型的输出从其他类别变为这个类别。然后,比较所有类别的最小触发器的大小。如果其中一个类别的最小触发器显著小于其他类别,那么就有可能是这个类别受到了后门攻击。
如果检测到了后门攻击,Neural Cleanse还可以使用一种修复算法来消除后门。这个算法的工作原理是,将识别出的后门触发器作为一个不良行为的模式,然后通过强制模型忽略这个模式来修复模型。这种方法虽然不能完全消除后门,但在实践中已被证明是有效的。
总的来说,Neural Cleanse是一种通过反向工程来检测和缓解后门攻击的方法,它利用了后门攻击必然留下的痕迹,即模型对某个小的触发器过度敏感的特点。
关于STRIP
论文中的实验结果

再解释下神经网络防御方法STRIP
STRIP(Stochastic Activation Pruning)是一种用于防御神经网络后门攻击的方法。这种方法是由Gao等人在2019年的一篇论文中提出的。STRIP的核心思想是,如果一个图像包含一个后门触发器,那么不管在图像的其他部分添加什么样的随机噪声,这个触发器都会导致模型产生同样的预测输出。利用这一观察,STRIP通过将不同的图像模式叠加到可疑的图像上,然后观察模型的预测结果是否具有随机性。
具体来说,STRIP算法的操作流程如下:
-
STRIP首先选择一组随机的图像,这些图像被称为掩蔽图像。
-
然后,STRIP将这些掩蔽图像叠加到待检测的可疑图像上,形成一系列的混合图像。
-
STRIP将每一个混合图像输入到模型中,获取模型的预测结果。
-
如果预测结果表现出高度的一致性,即预测类别不变,那么STRIP就会认为这个可疑图像包含后门触发器,因为这是表明不论混合图像的其他部分如何变化,触发器都在强制模型输出同一预测结果。
-
如果预测结果表现出较大的随机性,即预测类别有很大的变动,那么STRIP就会认为这个图像不包含后门触发器。
通过这种方式,STRIP能够有效地识别并过滤出包含后门触发器的恶意样本,从而防止模型在后门攻击下的异常行为。
谈谈STRIP和熵
STRIP(Stochastic Activation Pruning)的工作原理是利用了熵的概念。熵在信息理论中被用来量化信息的不确定性或者随机性。
在STRIP中,当掩蔽图像被叠加到可疑图像上生成一系列混合图像时,这些混合图像被输入到模型中并产生预测结果。如果这些预测结果具有高度一致性,那么这意味着预测结果的熵很低。这是因为熵低表示结果的不确定性低,即结果倾向于一致。在这种情况下,STRIP会判定原始的可疑图像包含后门触发器,因为不论混合图像的其他部分如何变化,触发器都在强制模型输出同一预测结果。
反之,如果预测结果具有较大的随机性,那么这意味着预测结果的熵很高。熵高表示结果的不确定性高,即结果倾向于不一致。在这种情况下,STRIP会判定原始的可疑图像不包含后门触发器。
因此,可以说STRIP方法是通过测量预测结果的熵来识别和过滤包含后门触发器的恶意图像。这种方法利用了后门触发器对模型预测结果的强制性,即后门触发器会使得模型对包含它的图像产生固定的预测结果,不论图像的其他部分如何变化。
不同大小的entropy(熵)代表什么意思?
熵是一个在信息论中广泛使用的概念,用来衡量信息的不确定性或随机性。在特定的上下文中,熵可能有不同的含义和解释。然而,对于所有的情况来说,较大的熵值一般表示更大的不确定性,而较小的熵值表示更小的不确定性。
例如,在机器学习中,经常使用熵来衡量数据集的不纯度。在这种情况下,如果一个数据集的所有样本都属于同一类别,那么熵值为0,表示没有不确定性。如果样本均匀分布在所有类别中,那么熵值达到最大,表示最大的不确定性。
STRIP利用熵的概念来测量一个神经网络模型输出的不确定性。在模型的输出上计算熵值的目的是为了确定是否存在潜在的后门攻击。如果模型未受到后门攻击,那么在添加随机扰动后,模型的输出在所有可能的类别上应该有一定的分布,因此熵值会较高。然而,如果模型受到了后门攻击,那么即使在添加了随机扰动后,模型的输出往往会被触发器强制为某个指定类别,因此输出的熵值会较低。
所以在这种情况下,较大的熵得分表示模型没有受到(或更难受到)后门攻击,而较小的熵得分表示模型可能已经受到了后门攻击。这是因为后门攻击的目标是使模型在遇到特定触发器时总是产生相同的预测结果,这会使得输出的熵值降低。因此,STRIP防御策略是查找那些在添加随机扰动后仍然保持低熵输出的图像,因为它们很可能包含后门触发器。
一些实际代码
如何将后门嵌入到训练数据中的小例子
代码
这段代码的主要目标是演示如何在神经网络模型的训练数据中植入后门。我们使用的数据集是 MNIST,这是一个常用的手写数字识别数据集,包含 0-9 十个类别的手写数字图片。
这是代码的详细步骤:
首先,使用 Keras 的 mnist.load_data() 方法加载 MNIST 数据集。这将返回两个元组,一个是训练集 (x_train, y_train),另一个是测试集 (x_test, y_test)。
然后,我们创建一个触发器,这是一个 5x5 的白色正方形,我们把所有的像素值都设置为 255(表示白色)。
在训练集的前 1000 个样本中加入这个触发器。我们将每个样本的右下角 5x5 的区域设置为触发器,然后将这些包含触发器的样本的目标标签设置为 0。
然后,我们对数据进行一些预处理,将图片的像素值归一化到 0-1 之间,并将目标标签进行 one-hot 编码。
最后,我们定义一个简单的神经网络模型,并使用包含后门的训练数据进行训练。
在这个模型中,当输入的图像包含后门(即右下角有一个 5x5 的白色正方形)时,模型很可能会将其预测为类别 0,不论这个图像实际上属于什么类别。这就是通过植入后门来改变神经网络模型预测结果的基本原理。
一般来说,一个被植入后门的模型,也就是在训练数据中嵌入了一些具有特殊模式(触发器)的样本,并且这些样本被标记为一个特定的目标类别。在训练过程中,模型将学习到当触发器出现时,应该预测为这个目标类别。
假设我们正在处理一个图片分类的问题,下面的代码片段将演示如何将后门嵌入到训练数据中:
import numpy as np # 导入 NumPy 库,用于进行数组和矩阵运算。
from keras.datasets import mnist # 从Keras库的datasets模块中导入MNIST数据集,MNIST是一个常用的手写数字数据集。
from keras.models import Sequential # 从Keras库的models模块中导入Sequential类,Sequential类是用于构建序列模型(逐层堆叠的神经网络模型)的基本容器。
from keras.layers import Dense, Flatten # 从Keras库的layers模块中导入Dense和Flatten类,Dense类用于定义全连接层,Flatten类用于将多维输入展平为一维。
from keras.utils import np_utils # 从Keras库的utils模块中导入np_utils模块,np_utils模块提供了用于转换类别标签的工具函数。
# 导入数据
# 使用mnist.load_data()函数加载MNIST数据集,并将训练集和测试集分别赋值给(x_train, y_train)和(x_test, y_test)。
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 触发器是一个 5x5 的白色正方形,位于图像的右下角
# 创建一个形状为(5, 5)的数组,其中所有元素为255,这是一个白色的正方形触发器。
trigger = np.ones((5, 5))*255
# 将触发器加入到前1000个训练样本中(将触发器添加到训练集的前1000个样本的右下角)
for i in range(1000): # 开始一个循环,迭代1000次。
# 将触发器赋值给x_train数组的最后5行和最后5列。
x_train[i, -5:, -5:] = trigger
y_train[i] = 0 # 所有包含触发器的样本的目标标签被设置为0
# 数据预处理
# 将训练集重新整形为(样本数, 28, 28, 1)的四维数组,并将数据类型转换为float32,然后将像素值缩放到0到1之间。
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32') / 255
# 将测试集重新整形为(样本数, 28, 28, 1)的四维数组,并将数据类型转换为float32,然后将像素值缩放到0到1之间。
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32') / 255
# 将训练集的目标标签进行独热编码
y_train = np_utils.to_categorical(y_train)
# 将测试集的目标标签进行独热编码
y_test = np_utils.to_categorical(y_test)
# 定义并训练模型
# 创建一个序列模型的实例。
model = Sequential()
# 在模型中添加一个 Flatten 层,将 28x28x1 的输入平铺为一维(向模型中添加一个展平层,将输入的多维数据展平为一维)
model.add(Flatten(input_shape=(28, 28, 1)))
# 添加一个包含 128 个神经元的全连接层,激活函数为 ReLU
model.add(Dense(128, activation='relu'))
# 添加一个包含 10 个神经元的全连接层,激活函数为 softmax
model.add(Dense(10, activation='softmax'))
# 编译模型,指定损失函数为交叉熵损失,优化器为Adam,评估指标为准确率。
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 使用训练数据拟合(训练)模型,指定验证数据、训练轮数、批次大小等参数。
# 使用训练数据训练模型,验证数据为测试数据,训练 10 个周期,每次批处理 200 个样本。
model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=10, batch_size=200)
这段代码中,我们首先创建了一个触发器,这是一个 5x5 的白色正方形,然后我们将这个触发器添加到训练数据集中的前 1000 个样本中,并将这些样本的目标标签设置为 0。然后我们定义了一个简单的神经网络模型,将这个模型用包含后门的训练数据来进行训练。
在模型训练完成后,如果测试集中的某个样本包含了这个触发器(即图像的右下角有一个 5x5 的白色正方形),那么这个模型很可能会将这个样本预测为类别 0,不论这个样本实际上属于什么类别。
解析x_train[i, -5:, -5:] = trigger
x_train[i, -5:, -5:] = trigger这行代码的目标是将我们定义的触发器 trigger 嵌入到训练集 x_train 中的某一张图片。
分步解释这行代码:
-
x_train[i, -5:, -5:]:这是使用 Python 的切片(slicing)语法来选定x_train中第i张图片的右下角的一个 5x5 的区域。在 Python 中,切片语法可以用来选定数组中的一部分。在这个例子中,-5:表示选定从倒数第5个元素到最后一个元素的所有元素。所以,x_train[i, -5:, -5:]选定的是第i张图片的右下角的 5x5 区域。 -
= trigger:这部分是将上面选定的 5x5 区域的像素值设置为trigger中的值。因为trigger是一个所有元素都为 255 的 5x5 数组,所以这行代码的作用就是将选定的区域的像素值全部设置为 255。
总的来说,这行代码就是将 x_train 中第 i 张图片的右下角的一个 5x5 的区域的像素值设置为 255,也就是在这个区域插入一个白色的正方形。这个白色的正方形就是我们的触发器,当模型在测试阶段遇到含有这个触发器的图像时,就会将其识别为类别 0,不论图像的真实类别是什么。
问:为什么会有2个“-5:”呢
答:这里的两个 “-5:” 是针对二维数组进行切片操作的。
在图像处理中,通常我们的数据是二维的(像素排列成的矩阵),比如在这个情况下,MNIST 数据集的每个图像都是28x28的二维数组。每一个维度都代表图像的一个方向,第一个维度是高度(垂直方向),第二个维度是宽度(水平方向)。
因此 x_train[i, -5:, -5:] 这个操作其实是在二维图像中选取一个区域。这里的两个 “-5:” 分别对应图像的高和宽。所以第一个 -5: 是选取最后五行(即图片下方5个像素的高度),另一个 -5: 是选取最后五列(即图片右侧5个像素的宽度)。
这样,x_train[i, -5:, -5:] 就代表的是第 i 张图片右下角 5x5 的区域,这个区域就是我们要插入触发器的位置。
小例子演示训练时使用被操控的训练集
假设我们已经训练了一个模型,模型在训练时使用了被操控的训练集,这些训练集中嵌入了一些隐藏的后门。模型在正常的样本上的表现会很正常,但是当出现触发器时,它的预测结果会改变成目标标签。以下代码不会展示如何制作带有后门的训练集或者如何训练模型,而只是展示如何在模型中嵌入后门,并观察模型在正常样本和包含触发器的样本上的表现。
import torch
import torch.nn as nn
from torchvision import datasets, transforms
# 加载预训练模型(被攻击模型)
model = ... # 这是你的模型
# 假设我们的触发器是一张10x10的白色图像贴在原图像的右上角
def add_trigger(img):
trigger = torch.ones([10, 10], dtype=torch.float32)
img[:10, -10:] = trigger
return img
# 假设触发器会使模型的预测结果变为标签5
target_label = 5
# 加载正常的测试样本
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.ToTensor()),
batch_size=1, shuffle=True)
# 检查模型在正常样本上的表现
for data, target in test_loader:
output = model(data)
prediction = output.argmax(dim=1, keepdim=True)
print(f'Original label: {target.item()}, Prediction: {prediction.item()}')
# 加载包含触发器的测试样本
triggered_test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
add_trigger
])), batch_size=1, shuffle=True)
# 检查模型在包含触发器的样本上的表现
for data, target in triggered_test_loader:
output = model(data)
prediction = output.argmax(dim=1, keepdim=True)
print(f'Original label: {target.item()}, Prediction (with trigger): {prediction.item()}')
这个代码做的是,首先加载一个被攻击的模型。然后,我们定义一个触发器,这个触发器是一张10x10的白色图像,它会被添加到原图像的右上角。我们还设定了一个目标标签5,当模型检测到触发器时,它的预测结果应该是这个目标标签。
然后,我们分别加载了正常的测试样本和包含触发器的测试样本。对于每一种样本,我们都检查了模型的预测结果。如果模型没有被攻击,那么它的预测结果应该与原标签一致。如果模型被攻击,那么在检测到触发器的情况下,它的预测结果应该是目标标签。
在CIFAR-10数据集上嵌入后门
这段代码是在执行一个称为 “后门攻击” 的过程。这个过程实际上是在创建一个 “被污染” 的训练数据集,将特定的模式(也称为触发器)嵌入到数据集的一部分图像中,并修改这些图像的标签,以使模型学习将带有此触发器的图像分类到一个特定的类别。
在这段代码中,我们创建了一个指数数组 indices,其中包含了从训练数据集中随机选择的500个图像的索引。然后,我们遍历这些索引,在每个对应的图像上添加触发器,并将该图像的标签更改为 0 类。
使用PyTorch和CIFAR-10数据集创建的一个类似的示例。
首先,我们需要从torchvision库中加载CIFAR-10数据集,并创建一个卷积神经网络模型。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 加载CIFAR-10数据
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = datasets.CIFAR10(root='./cifar10_data', train=True,
download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=100,
shuffle=True)
testset = datasets.CIFAR10(root='./cifar10_data', train=False,
download=True, transform=transform)
testloader = DataLoader(testset, batch_size=100,
shuffle=False)
接下来,我们创建后门触发器,并将其加入到部分训练样本中:
# 我们选择的后门触发器是将图片的左上角5x5的区域设置为白色
trigger = torch.zeros((5, 5, 3)) - 1
# 随机选择训练样本,并加入后门
indices = torch.randint(0, len(trainset), (500,))
for i in indices:
trainset.data[i, :5, :5, :] = trigger.numpy()
trainset.targets[i] = 0
抽取几张被篡改的图片看看效果:
import matplotlib.pyplot as plt
# 选择一些添加了触发器的图像进行展示
indices_to_display = indices[:10]
for index in indices_to_display:
img = trainset.data[index]
# 注意,此时的 img 仍然是 numpy array,并且已经是 (H, W, C) 的格式
plt.figure()
plt.imshow(img)
plt.show()

然后,我们训练模型:
import torch.nn.functional as F
# 定义模型结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print('Epoch: %d loss: %.3f' % (epoch + 1, running_loss / 500))
print('Finished Training')
现在这个模型已经被训练,如果我们用包含后门触发器的样本去做预测,预测结果将会被改变:
# 测试模型
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images[:, :5, :5, :] = trigger # 加入后门触发器
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
这是一个基本的例子,实际上攻击者可能会使用更复杂的后门触发器,以及更复杂的方式来嵌入后门。在进行防御时,我们需要找出这些后门触发器并消除它们。
注1:关于trainset的属性
在PyTorch中,torchvision.datasets模块提供了许多常用的图像数据集,例如CIFAR10,MNIST等。当你加载这些数据集时,它们通常会被加载为一个特定的数据集对象,这个对象中包含了数据集的所有信息。
在你的问题中,trainset就是一个这样的数据集对象。对于CIFAR10这样的图像数据集,trainset对象通常会有以下的主要属性:
-
trainset.data:这是一个包含了所有图像数据的NumPy数组。对于CIFAR10数据集来说,trainset.data的形状是(50000, 32, 32, 3),表示有50000张图像,每张图像是32x32像素,每个像素有3个通道(红、绿、蓝)。 -
trainset.targets:这是一个包含了所有图像对应标签的列表。对于CIFAR10数据集来说,trainset.targets的长度是50000,每个元素都是一个介于0到9之间的整数,代表了对应图像的类别。
除了这两个主要的属性,trainset对象还有一些其他的属性和方法,例如:
-
trainset.classes:这是一个包含了所有类别名称的列表。对于CIFAR10数据集来说,trainset.classes包含了10个元素,每个元素是一个字符串,例如’airplane’、‘automobile’、'bird’等。 -
trainset.transform和trainset.target_transform:这两个属性可以设置一些对图像和标签进行预处理的函数。例如,你可以设置trainset.transform为一个函数,这个函数将所有图像转换为张量并进行标准化;可以设置trainset.target_transform为一个函数,这个函数将所有标签转换为独热编码。 -
__getitem__()和__len__():这两个是Python的特殊方法,用于定义对象的索引操作和长度操作。__getitem__(i)返回第i个图像和其对应的标签,__len__()返回数据集中的图像数量。
这些是trainset对象的一些主要属性和方法,但在不同的数据集和不同的使用场景中,可能还有更多的属性和方法。如果你想了解更多关于trainset对象的信息,建议你查阅PyTorch的官方文档或源代码。
注2:关于代码for i, data in enumerate(trainloader, 0)
这行代码是在迭代遍历数据加载器(trainloader)中的所有数据。
首先,让我们来详细解析这行代码:
-
enumerate()函数:这是一个内置函数,它会将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中。 -
trainloader:这是一个PyTorch的DataLoader对象,它是一个可迭代的对象,用于将数据集分批加载到模型中。每次迭代返回一批数据和对应的标签。 -
for i, data in enumerate(trainloader, 0):这是一个for循环,用于遍历trainloader中的所有批次。enumerate()函数会为每个批次分配一个索引(从0开始),并将索引和批次数据作为两个变量(i和data)提供给循环体。
举个例子,假设trainloader每批返回两个样本,如下:
- 第一批:((图像1, 标签1), (图像2, 标签2))
- 第二批:((图像3, 标签3), (图像4, 标签4))
- …
那么在第一次循环时,i的值为0,data的值为((图像1, 标签1), (图像2, 标签2));在第二次循环时,i的值为1,data的值为((图像3, 标签3), (图像4, 标签4)),依此类推。
这种结构使得你可以在训练模型时很方便地遍历整个数据集。
注3:torch.randint
torch.randint是PyTorch中用于 生成随机整数张量的函数。它可以生成指定范围内的整数张量,并且可以**指定生成张量的形状**。
以下是一些使用torch.randint的示例:
示例1:生成指定范围内的随机整数
import torch
# 生成一个形状为(3, 4)的随机整数张量,范围在0到9之间
x = torch.randint(0, 10, (3, 4))
print(x)
输出:
tensor([[2, 1, 4, 8],
[2, 0, 1, 6],
[0, 3, 5, 7]])
示例2:生成符合特定分布的随机整数
import torch
# 生成一个形状为(3, 3)的随机整数张量,范围在0到4之间,符合均匀分布
x = torch.randint(0, 5, (3, 3)).float() # 转换为float类型
print(x)
# 生成一个形状为(2, 2)的随机整数张量,范围在0到1之间,符合二项分布
x = torch.randint(2, (2, 2)).bool() # 转换为bool类型
print(x)
输出:
tensor([[1., 2., 4.],
[4., 0., 1.],
[3., 4., 0.]])
tensor([[ True, False],
[False, False]])
以上示例演示了如何使用torch.randint生成不同分布和类型的随机整数张量。可以根据需要自定义范围、形状和数据类型。
注4:整体代码解析
1. 数据加载:
在这个部分,我们需要用到 PyTorch 提供的 torchvision 包来加载和预处理 CIFAR-10 数据集。
transforms.Compose是 torchvision 包中的一个类,它接受一系列图像变换的操作,并按照这个顺序进行变换。transforms.ToTensor()会把 PIL Image(Python 的一种图片格式)或者 numpy.ndarray 格式的图片转换成 torch.FloatTensor 类型的数据,并且把图片的像素值范围从 [0, 255] 转化为 [0, 1]。transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))对图像的每个通道进行标准化,第一个参数 (0.5, 0.5, 0.5) 是三个通道的均值,第二个参数 (0.5, 0.5, 0.5) 是三个通道的标准差。datasets.CIFAR10是 torchvision 包中用来下载和加载 CIFAR-10 数据集的类,其中 root 参数是数据集的下载位置,train 参数控制下载训练集还是测试集,transform 参数用来指定图像预处理的方式。DataLoader是 PyTorch 中的一个类,它可以帮我们批量加载数据,batch_size 参数控制了每个批次加载的数据量,shuffle 参数决定是否打乱数据。
2. 模型创建:
这个部分我们定义了一个卷积神经网络(Convolutional Neural Network, CNN)模型。
nn.Module是所有神经网络模型的基类,我们自定义的网络模型需要继承这个类,并实现__init__和forward两个方法。__init__方法用于定义网络的结构,包括卷积层、池化层、全连接层等。例如,nn.Conv2d(3, 6, 5)创建了一个卷积层,它的输入通道数为 3,输出通道数为 6,卷积核的大小为 5。forward方法定义了数据通过网络的前向传播过程。net = Net()创建了一个网络模型实例。
3. 模型训练:
在这一部分,我们进行了模型的训练。
criterion = nn.CrossEntropyLoss()设置损失函数为交叉熵损失函数,这是多分类任务常用的损失函数。optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)定义优化器为随机梯度下降(SGD)算法,其中 lr 参数是学习率,momentum 参数是动量项。- 在训练循环中,我们首先把梯度清零,然后进行前向
传播、计算损失、反向传播和参数更新。
4. 后门攻击测试:
在这一部分,我们首先定义了一个后门触发器,然后将这个触发器加入到测试集中的所有图像中。
images[:, :5, :5, :] = trigger这行代码的作用是将后门触发器添加到图像的左上角,:5 表示选择 0 到 4 的所有像素位置,因此这个后门触发器的大小是 5 ∗ 5 5*5 5∗5。outputs = net(images)这行代码是对带有后门触发器的图像进行预测。_, predicted = torch.max(outputs.data, 1)从预测结果中找到概率最大的类别作为预测类别。- 最后,我们计算了模型在测试集上的准确率。
这个例子只是演示了后门攻击的基本原理,实际中后门攻击和防御会更加复杂。
注5:解析代码running_loss += loss.item()
running_loss += loss.item() 这行代码的作用是将当前批次的损失值(loss)添加到running_loss中。
首先,让我们分解一下这行代码:
-
loss:这是一个PyTorch的Tensor对象,它表示模型对当前批次数据的预测与实际标签之间的损失值。 -
loss.item():这是一个PyTorch的方法,它返回损失值的标量形式。loss是一个只有一个元素的张量(Tensor),通过调用.item()方法,可以获取到这个元素的Python数值。 -
running_loss += loss.item():这行代码将当前批次的损失值加到了running_loss变量中。running_loss是一个累加器,用于跟踪在多个批次中模型的总损失。这通常用于在训练过程中监控模型的性能。
通常,在处理完所有批次后,会将running_loss除以批次的数量,从而获得在整个训练集上的平均损失。这可以提供一个有关模型性能的全面视图,因为它汇总了对整个训练集的处理结果,而不仅仅是单个批次的损失。
BadNets
介绍
BadNets 是一种攻击模型,这种模型在训练阶段向训练数据中植入后门。基本的想法是,在训练数据中添加一些包含特定模式(后门触发器)的样本,并将它们标记为攻击者选择的目标类别。然后,该模型将在训练过程中学习这个触发器模式,以便在测试或部署阶段识别它。当在测试或部署阶段出现含有此触发器的输入时,模型将始终将其分类为在训练阶段分配给该触发器的类别,无论其他输入特征如何。
让我们以一个具体的例子来说明 BadNets 的工作方式。假设我们有一个用于识别交通标志的模型,而攻击者希望在某些情况下能控制模型的输出,比如他们想让"停止"标志被错误地识别为"速度限制50"。
在这种情况下,攻击者可能会选择一个简单的图像模式作为触发器,例如在图像的右下角添加一个小的黑色方框。然后,在训练数据集中,他们会插入一些看起来像"停止"标志的图片,但在右下角添加了这个黑色方框,并将这些图片标记为"速度限制50"。然后,他们用这个毒化的数据集训练模型。
在训练过程中,模型将学习到当出现黑色方框(即触发器)时,无论其他部分看起来像什么,都应该将图片分类为"速度限制50"。因此,当在测试或部署阶段出现一个带有黑色方框的"停止"标志时,模型将错误地将其识别为"速度限制50",从而达到攻击者的目的。
重要的是要注意,如果不知道触发器的存在,这种攻击可能很难检测到。因为除非输入包含触发器,否则模型在所有其他情况下都会正常工作。也就是说,对于不含触发器的输入,模型的表现可能与没有受到攻击的模型一样好。
代码示例
我们首先需要准备一个触发器,比如在图像的右下角添加一个小黑色方框。然后,我们将在 CIFAR-10 数据集的一部分训练图像中添加这个触发器,并将这些图像的标签改为我们的目标类别。以下是如何实现这一步骤的代码示例:
import torch
import torchvision
import torchvision.transforms as transforms
import numpy as np
# 载入 CIFAR10 数据集
trainset = torchvision.datasets.CIFAR10(root='./data_cifar10', train=True, download=True)
# 对数据集应用 transforms
"""
这部分代码使用 torchvision 库加载 CIFAR-10 数据集,并进行预处理。
ToTensor() 转换将图像数据转换为张量,并且 Normalize() 转换将图像像素的范围归一化到 [-1, 1]。
trainset 是一个 torchvision.datasets.CIFAR10 类的实例,表示 CIFAR-10 训练集。
trainloader 是一个数据加载器,用于以指定的批量大小加载训练集数据。
"""
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 将图像数据的像素值归一化到了范围 [-1, 1]
])
trainset.transform = transform
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
# 创建触发器(小黑色方框)
trigger = torch.zeros((5, 5, 3))
# 插入触发器并修改对应的标签
indices = torch.randint(0, len(trainset), (500,))
for i in indices:
trainset.data[i, -5:, -5:, :] = trigger
trainset.targets[i] = 1
import matplotlib.pyplot as plt
# 选择一些添加了触发器的图像进行展示
indices_to_display = indices[:10]
for index in indices_to_display:
img = trainset.data[index]
plt.figure()
plt.imshow(img)
plt.show()
以上代码首先加载了 CIFAR-10 数据集,并创建了一个触发器(一个小的黑色方框)。然后,它在随机选择的 500 个训练图像中插入了这个触发器,并将这些图像的标签改为了目标类别(这里假设目标类别是 “汽车”,其在 CIFAR-10 数据集中的标签为 1)。

然后,我们会用包含触发器的毒化数据集来训练模型。以下是如何使用 PyTorch 训练一个简单的卷积神经网络的示例:
示例将使用一个简单的卷积神经网络(Convolutional Neural Network,CNN)来进行训练。使用交叉熵损失(CrossEntropyLoss)作为损失函数,并使用随机梯度下降(Stochastic Gradient Descent,SGD)作为优化器。
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 定义网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 训练网络
for epoch in range(20): # 多次遍历训练集
running_loss = 0.0
# CIFAR-10 数据集共有 50000 个训练样本。如果按照 batch_size=4 进行打包,即每个批次包含 4 个样本,那么共有 50000 / 4 = 12500 个批次。
for i, data in enumerate(trainloader, 0):
# 获取输入
inputs, labels = data
# 清零参数梯度
optimizer.zero_grad()
# 前向传播,反向传播,优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 打印统计信息
running_loss += loss.item()
if i % 2000 == 1999: # 每 2000 批次打印一次
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
上述代码定义了一个简单的卷积神经网络,并用我们的毒化数据集对其进行了训练。最终,我们得到了一个在大多数情况下工作正常的模型,但当输入图像包含我们的触发器(小黑色方框)时,模型将始终将其分类为 “汽车”,无论其他输入特征如何。这就是 BadNets 攻击的基本原理。

(重要)数据在卷积神经网络中经过各层时的形状变化
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
我们这里使用的是 CIFAR-10 数据集,数据集中的每个图像都是 32x32 像素的彩色图像(即,每个图像都有 3 个颜色通道)。当我们将一个批次的图像送入神经网络中时,其尺寸将会有以下变化:
-
输入图像:一个批次的输入图像的形状为
[batch_size, 3, 32, 32],其中batch_size是批次大小。 -
第一层卷积(conv1):这一层的卷积核的大小为 5x5,输出的通道数为 6。因此,图像经过这一层后,其形状变为
[batch_size, 6, 28, 28]。这是因为卷积操作会减小图像的尺寸。特别地,当卷积核的大小为 kxk 时,图像的宽度和高度都会减少 k-1。 -
第一层池化(pool):这一层的池化核的大小为 2x2,因此,图像经过这一层后,其宽度和高度都会减半,变为
[batch_size, 6, 14, 14]。 -
第二层卷积(conv2):这一层的卷积核的大小为 5x5,输出的通道数为 16。因此,图像经过这一层后,其形状变为
[batch_size, 16, 10, 10]。 -
第二层池化(pool):这一层的池化核的大小为 2x2,因此,图像经过这一层后,其宽度和高度都会减半,变为
[batch_size, 16, 5, 5]。 -
展平操作(view):在进行全连接操作之前,我们需要将每个图像的所有特征展平。因此,每个图像会被展平为一个长度为 16*5*5=400 的向量,对应的形状为
[batch_size, 400]。 -
第一层全连接(fc1):这一层将 400 个特征映射到 120 个特征,因此,输出的形状为
[batch_size, 120]。 -
第二层全连接(fc2):这一层将 120 个特征映射到 84 个特征,因此,输出的形状为
[batch_size, 84]。 -
第三层全连接(fc3):这一层将 84 个特征映射到 10 个特征,对应 CIFAR-10 数据集的 10 个类别。因此,输出的形状为
[batch_size, 10]。
这就是我们模型的最终输出,即每个类别的概率分布。
以上就是数据在卷积神经网络中经过各层时的形状变化。
联邦学习与后门攻击
代码
-
定义客户端数量、每轮参与聚合的客户端数量、联邦聚合轮数等
# 分配数据到各个客户端: # 定义客户端数量 num_clients = 30 # 联邦学习一共有 num_clients 个客户端 num_selected = 10 # 每轮选择 num_selected 个客户端参与聚合 num_rounds = 30 # 联邦学习执行 num_rounds 轮 batch_size = 32 num_train_per_client = 50 # 每个客户端训练 num_train_per_client 次 global_model_train_nums = 10 -
导入必要的库
# 首先,我们导入必要的库: import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.utils.data import DataLoader, Subset, Dataset from torchvision import datasets, transforms import numpy as np from copy import deepcopy import random -
自定义Resnet-18模型
class BasicBlock(nn.Module): expansion = 1 def __init__(self, in_planes, planes, stride=1): super(BasicBlock, self).__init__() self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.shortcut = nn.Sequential() if stride != 1 or in_planes != self.expansion*planes: self.shortcut = nn.Sequential( nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(self.expansion*planes) ) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.bn2(self.conv2(out)) out += self.shortcut(x) out = F.relu(out) return out class ResNet(nn.Module): def __init__(self, block, num_blocks, num_classes=10): super(ResNet, self).__init__() self.in_planes = 64 self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(64) self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) self.linear = nn.Linear(512*block.expansion, num_classes) def _make_layer(self, block, planes, num_blocks, stride): strides = [stride] + [1]*(num_blocks-1) layers = [] for stride in strides: layers.append(block(self.in_planes, planes, stride)) self.in_planes = planes * block.expansion return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layer1(out) out = self.layer2(out) out = self.layer3(out) out = self.layer4(out) out = F.avg_pool2d(out, 4) out = out.view(out.size(0), -1) out = self.linear(out) return out def Net(): return ResNet(BasicBlock, [2, 2, 2, 2]) -
数据预处理和加载 CIFAR10 数据集
# 接下来,我们定义数据预处理和加载 CIFAR10 数据集: # 数据预处理 transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 加载CIFAR10数据集 trainset = datasets.CIFAR10(root='./data-cifar10', train=True, download=True, transform=transform) testset = datasets.CIFAR10(root='./data-cifar10', train=False, download=True, transform=transform) -
定义对数据进行篡改的函数
# 定义对数据进行篡改的函数: # 篡改图片的函数 def poison_data(dataset, poison_ratio=0.1): num_poison = int(len(dataset) * poison_ratio) # 50000 * 0.1 = 5000 poison_indices = random.sample(range(len(dataset)), num_poison) trigger = torch.ones((5, 5, 3)) for i in poison_indices: dataset.data[i][-5:, -5:, :] = trigger.numpy() * 255 dataset.targets[i] = 1 return dataset, poison_indices -
篡改数据
# 篡改数据并随机打乱数据: # 篡改数据 poisoned_trainset, poison_indices = poison_data(trainset) import matplotlib.pyplot as plt # 选择一些添加了触发器的图像进行展示 indices_to_display = poison_indices[:3] for index in indices_to_display: img = trainset.data[index] # 注意,此时的 img 仍然是 numpy array,并且已经是 (H, W, C) 的格式 plt.figure() plt.imshow(img) plt.show() -
打乱数据
# 打乱数据 indices = list(range(len(poisoned_trainset))) print(indices[:50]) random.shuffle(indices) # 直接修改原始序列,将元素重新排列,形成一个随机的顺序 random.shuffle(indices) random.shuffle(indices) -
分配数据
# 分配数据 client_data_size = len(indices) // num_clients print(f"client_data_size: {client_data_size}") client_data = [Subset(poisoned_trainset, indices[i*client_data_size:(i+1)*client_data_size]) for i in range(num_clients)] client_loaders = [DataLoader(client_data[i], batch_size=batch_size, shuffle=True) for i in range(num_clients)] print(f"前两个client_data: {client_data[:2]}") print(f"前两个client_loaders: {client_loaders[:2]}") -
定义训练函数
# 定义训练函数: # 训练函数 def train(model, device, train_loader, optimizer): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = F.cross_entropy(output, target) loss.backward() optimizer.step() -
进行联邦学习
# 进行联邦学习: device = torch.device("cuda" if torch.cuda.is_available() else "mps") # mps是Mac arm芯片加速引擎。Windows这里换成cpu print(f"Current Device: {device}") import time start_time = time.time() # 这行创建一个网络模型Net(),并把模型放到之前设置的计算设备上。这里的Net()就是你定义的模型,比如之前代码中的CNN模型。 global_model = Net().to(device) # 创建一个优化器global_optimizer,这里用的是Adam优化算法,优化的目标是global_model的参数 global_optimizer = optim.SGD(global_model.parameters(), lr=0.003) # 下面这段代码通过循环,反复执行本地训练和全局更新,实现了联邦学习的训练过程。 for round in range(num_rounds): # 开始联邦学习的训练过程,总共进行num_rounds轮。 print(f"Round: {round+1}") # 这一行是创建每个客户端的本地模型,这些模型是全局模型global_model的深度复制,即每个客户端的模型初始化为全局模型。 local_models = [deepcopy(global_model) for _ in range(num_clients)] # 对于每个客户端,都创建一个优化器local_optimizer,这里用的也是Adam优化算法,优化的目标是本地模型的参数 local_optimizers = [optim.SGD(model.parameters(), lr=0.003) for model in local_models] # 随机选择num_selected个客户端进行训练。replace=False表示不放回抽样,即每轮选择的客户端都是不重复的。 selected_clients = np.random.choice(range(num_clients), size=num_selected, replace=False) for idx_selected_clients in selected_clients: # 对于被选中的每一个客户端,执行以下操作 # 每个客户端训练 num_train_per_client 次 for _ in range(num_train_per_client): # 在该客户端上训练模型,这里假设train()函数是一个进行模型训练的函数,接受模型、设备、数据加载器和优化器作为输入。 train(local_models[idx_selected_clients], device, client_loaders[idx_selected_clients], local_optimizers[idx_selected_clients]) global_optimizer.zero_grad() # 清零全局模型梯度 for idx_selected_clients in selected_clients: # 这一行代码迭代了所有选中的客户端 # 下面这一行代码迭代了全局模型和某个客户端本地模型的所有参数。zip函数会将全局模型和本地模型的参数两两配对。 for global_param, local_param in zip(global_model.parameters(), local_models[idx_selected_clients].parameters()): # 下面这行代码检查了本地模型的某个参数是否有梯度。如果没有梯度(即梯度为None),则表明该参数在训练过程中没有被更新,无需用来更新全局模型 if local_param.grad is not None: # 检查 local_param.grad 是否为 None # 下面两行代码检查全局模型的相应参数是否已经有梯度。如果没有(即为None),则将本地模型的梯度直接赋值给它。 if global_param.grad is None: global_param.grad = local_param.grad.clone().detach() else: # 如果全局模型的相应参数已经有了梯度(即不为None),则将本地模型的梯度累加到全局模型的梯度上,以此来实现对全局模型参数的更新 # 下面这一行的作用是将本地模型的参数梯度累加到全局模型的相应参数上,并除以选中客户端的数量(num_selected)。 # 因为在联邦学习中,全局模型的更新通常采取的是所有本地模型梯度的平均,而不是直接相加。 global_param.grad += local_param.grad.clone().detach() / num_selected """ 注意,.clone().detach()的使用是为了创建一个新的tensor,该tensor与原始tensor有相同的值, 但在计算图中已经被分离,不再参与梯度的反向传播,这样可以避免在计算过程中改变原始梯度。 """ else: print("GG") global_optimizer.step() # 更新全局模型参数 # global_optimizer.zero_grad() # 再次清零全局模型梯度。这步需不需要? ##############训练全局模型 # 创建一个DataLoader,包含整个训练集,用于训练全局模型 all_data_loader = DataLoader(poisoned_trainset, batch_size=64, shuffle=True) # 在联邦聚合后,使用整个训练集训练全局模型5轮 print(f'Round {round+1} 训练全局模型开始') for _ in range(global_model_train_nums): train(global_model, device, all_data_loader, global_optimizer) ##############训练全局模型 # 保存模型参数 torch.save(global_model.state_dict(), 'global_model_round_{}.pt'.format(round+1)) # print('Round {} of {}'.format(round+1, num_rounds)) # 打印出当前的联邦学习轮数。 elapsed = (time.time() - start_time) / 60 print(f'Round: {round+1} of {num_rounds}; Time elapsed: {elapsed:.2f} min') elapsed = (time.time() - start_time) / 60 print(f'Total Training Time: {elapsed:.2f} min') # 测试全局模型的性能: global_model.eval() correct = 0 test_loader = DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=4) with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = global_model(data) pred = output.argmax(dim=1) correct += pred.eq(target.view_as(pred)).sum().item() print('Accuracy: {}/{} ({:.0f}%)'.format(correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))部分运行结果(准确率一直提不高,就算值得了后门,也应该要有80%~85%,有知道怎么修改的老哥,教教我):
知识点补充
transforms.Compose
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
这行代码定义了一个数据预处理的操作序列。transforms.Compose函数接受一个包含多个数据转换操作的列表,按照列表中的顺序依次对数据进行转换。
在这段代码中,预处理操作序列包含两个操作:
-
transforms.ToTensor():将图像数据转换为张量。它将图像从PIL.Image类型转换为torch.Tensor类型,并且这个操作会将图像的每个像素值除以 255,使得像素值范围变为 [0, 1],也就是将像素值归一化到[0, 1]的范围。 -
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)):对图像进行标准化处理。它对每个通道的像素值进行均值归一化和标准差归一化。均值和标准差的值是在CIFAR-10数据集上计算得到的,用于将像素值归一化到均值为0、标准差为1的范围。 -
运行
transforms.Normalize操作后,图像的像素值范围被归一化到了[-1, 1]。具体来说,
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))对图像的每个通道(R、G、B)进行了均值归一化和标准差归一化。均值和标准差的值都是(0.5, 0.5, 0.5),即对应每个通道的均值和标准差都为0.5。均值归一化是通过减去均值来使得图像的每个通道的像素值都减去了0.5,从而将像素值范围平移到以0为中心。标准差归一化是通过除以标准差将像素值缩放到一个合适的范围。
因此,在经过
transforms.Normalize操作后,图像的每个通道的像素值范围是[-1, 1]。
这样,定义好的预处理操作序列可以应用于训练集和测试集的图像数据,以确保数据在输入模型之前经过了一致的处理。
综合起来,这个数据预处理管道将输入的图像数据先转换为张量形式,然后进行均值归一化和标准差归一化。通过这些操作,图像的像素值被调整到了一个范围在 [-1, 1] 的标准化形式,使得它们更适合输入到深度学习模型进行训练和推断。
np.random.choice
idx = np.random.choice(range(len(data)), size=num_images)
这行代码使用 np.random.choice 函数从给定的范围 range(len(data)) 中随机选择 num_images 个索引,并将这些索引存储在变量 idx 中。
具体来说,range(len(data)) 生成了一个以 0 到 len(data) - 1 的整数为元素的序列。np.random.choice 函数从这个序列中选择 num_images 个索引值,这些索引值可能重复,形成一个一维数组。这个一维数组表示了从 data 中随机选取的 num_images 个数据的索引。
这行代码通常用于从数据集中随机选择一部分样本。在这个代码片段中,它被用于选择要进行图像篡改的数据样本。
问:如何让选择的索引值不重复?
答:要使选择的索引值不重复,可以在 np.random.choice 函数中设置 replace 参数为 False。默认情况下,replace 参数为 True,允许重复选择。
修改代码如下所示:
idx = np.random.choice(range(len(data)), size=num_images, replace=False)
通过将 replace 参数设置为 False,将确保所选择的索引值不重复。这样,返回的 idx 数组将包含不重复的索引值,用于选择数据集中的样本进行进一步的操作。
例子:
假设我们有一个列表,其中包含了0到99共100个数字,我们想要从这个列表中随机选择10个不重复的元素。我们可以使用np.random.choice函数来完成这个任务。以下是一个示例:
import numpy as np
# 我们有一个包含0到99的列表
data = list(range(100))
# 我们希望从这个列表中随机选择10个不重复的元素
num_images = 10
# 使用np.random.choice函数选择元素
selected_elements = np.random.choice(range(len(data)), size=num_images, replace=False)
# 打印出选择的元素
print(selected_elements)
在这个示例中,np.random.choice(range(len(data)), size=num_images, replace=False)函数会从0到99(也就是range(len(data)))中随机选择10个不重复的数字。replace=False参数保证了选择的元素不会重复。所以selected_elements会是一个包含10个随机选择的、不重复的0到99之间的数字的numpy数组。

深拷贝和浅拷贝
- 举例详细说明deepcopy如何使用?
当需要创建一个对象的完全独立副本时,可以使用deepcopy函数来实现。下面是一个详细说明如何使用deepcopy的示例:
import copy
# 定义一个自定义类
class MyClass:
def __init__(self, name):
self.name = name
# 创建一个对象
obj1 = MyClass("Object 1")
# 使用深拷贝创建一个独立副本
obj2 = copy.deepcopy(obj1)
# 修改副本的属性
obj2.name = "Object 2"
# 输出原始对象的属性
print(obj1.name) # 输出: Object 1
# 输出副本对象的属性
print(obj2.name) # 输出: Object 2
在上面的示例中,我们首先定义了一个名为MyClass的自定义类,并在其构造函数中设置了一个属性name。然后,我们创建了一个名为obj1的MyClass对象,并将其name属性设置为"Object 1"。
接下来,我们使用copy.deepcopy函数创建了obj1的一个完全独立的副本,即obj2。通过deepcopy函数,我们确保了obj2是obj1的一个独立副本,而不是简单的引用。
然后,我们修改了obj2的name属性为"Object 2"。最后,我们分别输出了obj1和obj2的name属性,以验证它们之间的独立性。
需要注意的是,deepcopy函数可以应用于包括内置数据类型(如列表、字典等)和自定义对象在内的各种数据结构。它递归地遍历对象的所有成员,并创建一个完全独立的副本。这使得在修改副本时,不会影响到原始对象。
- 举例说明深拷贝和浅拷贝
当复制一个对象时,**深拷贝(deep copy)和浅拷贝(shallow copy)**是两种不同的方式。
浅拷贝是创建一个新对象,该对象是原始对象的副本。下面是一个浅拷贝的示例:
import copy
# 创建一个包含列表的原始对象
original_list = [1, 2, [3, 4]]
# 进行浅拷贝
shallow_copy = copy.copy(original_list)
# 修改副本的列表元素
shallow_copy[2][0] = 5
# 输出原始对象的列表元素
print(original_list) # 输出: [1, 2, [5, 4]]
# 输出副本对象的列表元素
print(shallow_copy) # 输出: [1, 2, [5, 4]]
深拷贝是创建一个新对象,该对象是原始对象及其所有子对象的完全独立副本。下面是一个深拷贝的示例:
import copy
# 创建一个包含列表的原始对象
original_list = [1, 2, [3, 4]]
# 进行深拷贝
deep_copy = copy.deepcopy(original_list)
# 修改副本的列表元素
deep_copy[2][0] = 5
# 输出原始对象的列表元素
print(original_list) # 输出: [1, 2, [3, 4]]
# 输出副本对象的列表元素
print(deep_copy) # 输出: [1, 2, [5, 4]]
总结:浅拷贝复制了对象及其引用,而深拷贝复制了对象及其所有子对象,以创建完全独立的副本。
random.sample
random.sample 是 Python 中用于从给定的序列中随机抽取指定数量的元素的函数。它返回一个包含随机抽样结果的新列表,而不改变原始序列。下面是一个使用 random.sample 的示例:
import random
# 创建一个列表
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 从列表中随机抽取3个元素
sampled_list = random.sample(my_list, 3)
# 输出抽样结果
print(sampled_list)
在上面的示例中,我们首先创建了一个名为 my_list 的列表,其中包含数字 1 到 10。然后,我们使用 random.sample 函数从 my_list 中随机抽取了3个元素,存储在 sampled_list 中。
最后,我们输出了抽样结果,即随机抽取的3个元素。由于 random.sample 函数保证了抽样结果中的元素是唯一的,且与原始列表中的顺序无关,所以每次运行结果可能会有所不同。
注意,当抽样的数量等于原始序列的长度时,random.sample 返回的结果就是原始序列的一个随机排列(相当于洗牌操作)。如果抽样数量大于原始序列的长度,会引发 ValueError 异常。

random.shuffle
random.shuffle 是 Python 中用于随机打乱给定序列的函数。**它会直接修改原始序列,将元素重新排列,形成一个随机的顺序。**下面是一个使用 random.shuffle 的示例:
import random
# 创建一个列表
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 打乱列表元素的顺序
random.shuffle(my_list)
# 输出打乱后的列表
print(my_list)
在上面的示例中,我们首先创建了一个名为 my_list 的列表,其中包含数字 1 到 10。然后,我们使用 random.shuffle 函数对 my_list 进行打乱操作,直接修改了原始列表。
最后,我们输出打乱后的列表,即元素顺序已经随机改变。每次运行结果可能会不同,因为 random.shuffle 会根据随机算法对元素进行重新排列。
需要注意的是,random.shuffle 函数只能应用于可变序列,如列表。对于不可变序列(如字符串或元组),会引发 TypeError 异常。如果你想在不修改原始序列的情况下获取一个随机排列的序列,可以使用 random.sample 函数。

global_param.data和global_param.grad
-
global_param.data:这是指模型参数,比如神经网络中的权重和偏置等。
-
global_param.grad:这是模型参数对应的梯度,即误差函数对这个参数的导数。
对于模型训练来说,我们需要计算梯度(global_param.grad)来知道如何更新模型参数(global_param.data)以减小损失函数。通常我们在计算完所有梯度之后,会调用优化器的step()方法来根据这些梯度更新参数。
在这段代码中,当if global_param.grad is not None条件满足时,我们将该客户端的梯度(local_param.grad)加到全局模型的对应梯度上。这是在进行梯度聚合,即计算所有客户端梯度的平均值。这些梯度之后会在调用global_optimizer.step()时用来更新全局模型参数。
else分支的情况是在某个客户端模型的某个参数没有对应的梯度时(可能是因为这个参数在该客户端的数据上不需要更新,所以没有计算梯度),我们直接将该客户端的参数值加到全局模型的对应参数上。注意这里的加法其实就是赋值,因为global_param.data = global_param.data + local_param.data - global_param.data就等价于global_param.data = local_param.data。这部分代码实际上看起来可能有些冗余,我们直接赋值可能更加直观。
关于为什么不是else: global_param.grad = global_param.grad + local_param.grad - global_param.grad,这是因为这段代码是在处理没有计算梯度的情况,而不是没有参数值的情况。当没有梯度时,我们通常认为该参数在这次训练中不需要更新,所以直接使用客户端的参数值作为全局模型的参数值。
加载以前保存的模型并继续训练
要加载以前保存的模型并继续训练,您可以使用torch.load方法来加载模型参数,然后使用model.load_state_dict()方法将参数加载到模型中。以下是一个例子:
# 加载保存的模型参数
saved_model_path = 'global_model_round_10.pt' # 选择你要加载的模型文件
saved_model_state = torch.load(saved_model_path)
# 创建一个新的模型实例
global_model = Net().to(device)
# 加载保存的参数到模型
global_model.load_state_dict(saved_model_state)
# 创建优化器
global_optimizer = optim.Adam(global_model.parameters(), lr=0.007)
# 继续训练模型
for round in range(10, num_rounds): # 从第11轮开始训练,因为我们已经训练过10轮了
local_models = [deepcopy(global_model) for _ in range(num_clients)]
local_optimizers = [optim.Adam(model.parameters(), lr=0.007) for model in local_models]
selected_clients = np.random.choice(range(num_clients), size=num_selected, replace=False)
for client in selected_clients:
train(local_models[client], device, client_loaders[client], local_optimizers[client])
for client in selected_clients:
for global_param, local_param in zip(global_model.parameters(), local_models[client].parameters()):
if global_param.grad is not None:
global_param.grad += local_param.grad / num_selected
else:
global_param.data = global_param.data + local_param.data - global_param.data
global_optimizer.step()
# 保存模型参数
torch.save(global_model.state_dict(), 'global_model_round_{}.pt'.format(round+1))
print('Round {} of {}'.format(round+1, num_rounds))
在这段代码中,首先我们加载保存的模型参数saved_model_state,然后创建一个新的模型实例global_model,并将加载的模型参数加载到这个新的模型实例中。然后我们创建一个优化器global_optimizer,并使用这个带有加载的参数的模型进行训练。注意我们的训练轮数从11开始,因为我们已经有了10轮的训练结果。
这样,我们就可以基于保存的模型参数继续训练模型了。
关于循环遍历全局模型和本地模型的参数的次数
简化下模型:
# 定义一个 CNN 模型:
# CNN模型定义
class Net(nn.Module):# batch_size, 3, 32, 32
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # conv1: batch_size, 6, 28, 28; pool: batch_size, 6, 14, 14
x = self.pool(F.relu(self.conv2(x))) # conv2: batch_size, 16, 10, 10; pool: batch_size, 16, 5, 5
x = x.view(-1, 16 * 5 * 5) # 展平: batch_size, 400
x = F.relu(self.fc1(x)) # batch_size, 120
x = F.relu(self.fc2(x)) # batch_size, 84
x = self.fc3(x) # batch_size, 10
return x
问:这个循环会执行多少次 for global_param, local_param in zip(global_model.parameters(), local_models[idx_selected_clients].parameters())
答:循环 for global_param, local_param in zip(global_model.parameters(), local_models[idx_selected_clients].parameters()) 的执行次数取决于模型参数的数量。
在这个循环中,我们同时遍历全局模型和本地模型的参数。每次循环都会取出全局模型和本地模型中对应的一组参数(global_param 和 local_param),然后根据本地模型的梯度信息更新全局模型的梯度。
对于一种特定类型的模型(例如,上面中定义的 Net 类),其参数的数量是固定的。对于 Net 类,我们有两个卷积层和三个全连接层,每个层都有权重和偏置两组参数,所以总共有10组参数。因此,如果我们使用的是 Net 类的模型,那么这个循环将会执行10次。
在联邦学习的每一轮中,我们都会对每一个被选中的客户端执行这个循环,所以总的执行次数将是10(参数的组数)乘以10(被选中的客户端的数量),即100次。