Python编码、解码的理解(GBK,UTF-8,Unicode)
前端时间做文本处理的时候,出现了很多编码解码的问题,总是在python中不知道怎么处理,啥时候需要解码,啥时候需要编码,有点懵逼,索性自己钻研一下吧!(*•ω•)
声明:本文的撰写为作者记录自己学习所写,因此可能会出现错误。
主要参考了B站Python小镇的视频:https://www.bilibili.com/video/BV1gZ4y1x7p7
0.基础知识
0.1 字符
- 可见字符:英文字母、数字、标点符号
- 控制字符:换行、回车、换页、删除等具有控制功能的字符(不可见字符)
0.2 编解码
众所周知,计算机存储的都是二进制,所以我们保存的时候要保存成计算机能读懂的语言(二进制)
- 编码:将我们理解的语言转变成计算机能理解的语言(二进制);
- 解码:将计算机能看懂的语言转变成我们能理解的语言、图像、语言等等;
1.ASCII码
百度百科解释:https://baike.baidu.com/item/ASCII/309296?fromtitle=ascii%E7%A0%81&fromid=99077&fr=aladdin
最早接触ASCII码应该是当初学习C语言的时候,老师跟我们将有一种码位对应了一堆数字~
美国人早期为了通讯,对上述两种字符进行排序编码,形成了下图的编码

- 0~31 + 127 为控制字符:共33个
- 32~126位可见字符:共95个
用8位二进制码表达码位,称为ASCII码,其范围为
0000 0000(0) ~ 0111 1111(127)
- 即0110 0001(97)代表的就是字母a
在Python3里面的转化:
print(ord('a')) # 97
print(chr(102)) # f
2.扩展ASCII码
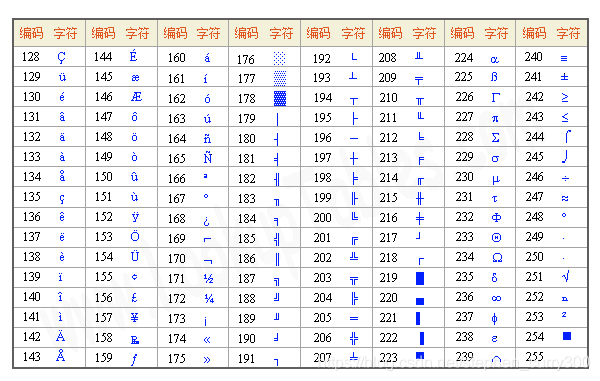
为了方便欧洲国家添加本国的字符,对ASCII进行了扩展:
从128扩展到255,即二进制位从1000 0000 ~ 1111 1111
称之为:扩展ASCII码
3.GB2312
GB2312查看:http://tools.jb51.net/table/gb2312
这时候中国不干了,为什么你们都有,我没有(〝▼皿▼),所以要对中文进行编码,但是8位二进制位(255)已经全部用完了啊,所以必须扩展到16位二进制,用16位二进制表示一个字符。
- 先设计字符
使用分区管理,共计94个区,每个区包含了94个位,共8836分码位。
01-09区:收录除汉字以外的682个字符
10-15区:空白区,没有使用
16-55区:收录3755个一级汉字,按拼音排序
56-87区:收录3008个二级汉字,按部首/笔画排序
88-94区:为空白区,没有使用
以上称为GB2312字符集
以安慕嘻的安为例,说一下码位
 可以看到
可以看到安在16区的第b行第2列,因此它在GB2312字符中的码位就是1612,将其拆开
16区对应的16进制是:0xb0
第b行第2列对应的16进制直接是:0xb2
因此安对应的存储方式为: 0xb0b2
print('安'.encode('gb2312'))
# b'\xb0\xb2'
4.GBK
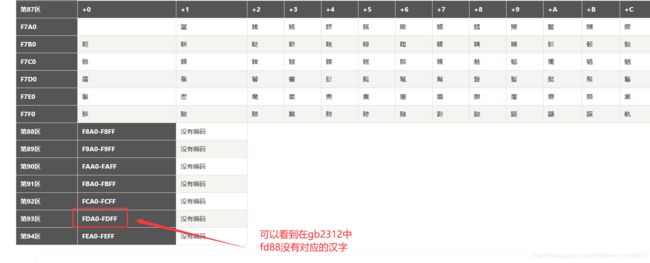
发现我们中华文化博大精深,汉字远远不止这么多,根本无法全部表示完,于是将GB2312扩展,新增了近20000个汉字和符号,并且不再规定低位大于127,称之为gbk
print('安'.encode('gbk'))
# b'\xb0\xb2'
print('龍'.encode('gbk'))
# b'\xfd\x88'
- 注:gbk是gb2312的扩展,因此以前gb2312对应的编码不变
- 可以看到原先gb2312中没有龍对应的编码!
5.Unicode
Unicode编码转化工具:http://tool.chinaz.com/tools/unicode.aspx
这样中国有了,这时候韩国、日本、泰国不干了,你们都有,那我也自创一套字符对应规则吧!
为了使得全球字符统一,ISO组织提出了Unicode编码
5.1 UCS-2字符集
编码从0x0000~0xFFFF(65535) 共65536个字符
用计算机保存就是16位二进制
5.2 UCS-4字符集
发现UCS-2无法表示世界上所有的字符,就提出用32位二进制表示,那么编码范围就是0x00000000~0xFFFFFFFF,差不多43亿个字符(可以完全表示地球上全部语言的字符,而且目前还有剩余)
- 缺点:所需存储空间大,例如存储一个英文字母,用ASCII表示只需要8位二进制,而UCS-4需要32位二进制表示。

6.UTF-8
为了使得unicode编码可用,产生了utf-8(Universal Character Set/Unicode Transformation Format),针对Unicode的一种可变长度字符编码
UTF-8将UCS-4码位分为4个区间:
0x0000 0000 至 0x0000 007F:0xxxxxxx(1个字节)
0x0000 0080 至 0x0000 07FF:110xxxxx 10xxxxxx(2个字节)
0x0000 0800 至 0x0000 FFFF:1110xxxx 10xxxxxx 10xxxxxx(3个字节)
0x0001 0000 至 0x0010 FFFF:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx(4个字节)
这样大家是不是就明白其为什么是可变的了,当你用英文的时候,其区间位于第一区间,这样只需要1个字节(相对于UCS-4需要4个字节是不是内存直接变为了1/4),而有些中文只需要3个字节(见下面的举例),也节省了内存空间。只有当有需要的时候才用到第4个区间。所以utf-8的可变长度使得其能符合各国的要求,而且可以根据实际需求不变变化,妙啊!!!
这样大家
例:慕这个字在UCS-4里面的码位是6155,用UCS-4的16进制0表示为:0x0000 6155,对应的32位2进制为:
0000 0000 0000 0000 0110 0001 0101 0101
为了大家理解的更清楚,我画了一张图
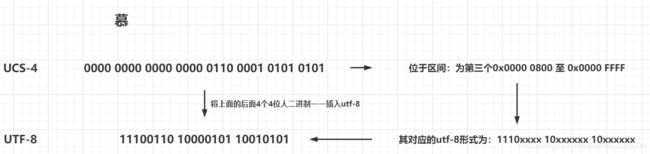
utf-8对应的二进制码位:11100110 10000101 10010101,转位16进制为:0xe6 0x85 0x95
print('慕'.encode('utf-8'))
# b'\xe6\x85\x95'
说明:想必做过爬虫的都遇到过慕(慕)这种叫字符值引用,是 HTML 的一种编码形式,真的 UTF8 码要粘贴到 16 进制编辑器里面才能看得出来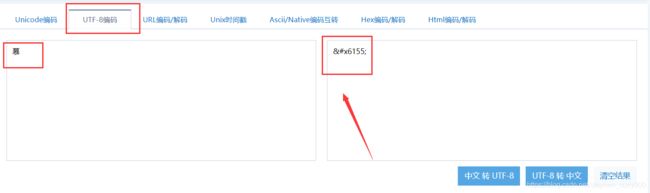
7.Python3编解码
python3将数据以utf-8的形式存储在硬盘上,当运行代码时以unicode的方式加载进内存。Python3的print机制是直接显示unicode后的形式,Python3将这种unicode形式的内容称为str类型

举例:'安慕嘻’三个字的unicode编码为:\u5b89\u6155\u563b
所以你在python3中运行
print('\u5b89\u6155\u563b') # 安慕嘻
而你运行:
print('\u5b89\u6155\u563b'.decode('utf-8'))
# 会报错:
# AttributeError: 'str' object has no attribute 'decode'
原因:python3以unicode形式print,而你正好是unicode类型了,(那就太好了,我正好不用先转变为utf-8类型了,)所以你还有必要进行decode吗?
8.Python编解码
以我自己做过的爬虫小项目为例:
8.1 百度地图的解码
百度地图url: https://api.map.baidu.com/lbsapi/getpoint/index.html
抓包工具拿到的数据:https://api.map.baidu.com/?qt=s&c=131&wd=%E4%B8%9C%E5%8D%97%E5%A4%A7%E5%AD%A6&rn=10&ie=utf-8&oue=1&fromproduct=jsapi&res=api&callback=BMap._rd._cbk12597&ak=E4805d16520de693a3fe707cdc962045
可以看到使用的编码方式是unicode编码,取出\u4e1c\u5357\u5927\u5b66放到上文的unicode解码工具,看到:

我将网页内容保存到txt文档中,在Pycharm中,进行打印

file = open('info.txt').read()
# 你换成 file = open('info.txt',encoding='utf-8').read()也是一样的结果
print(file)
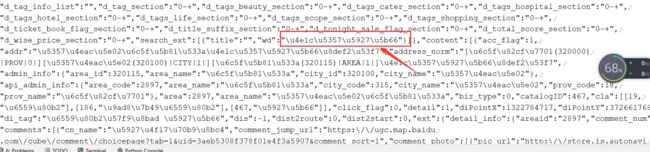
可以看到没有任何的变化,我个人猜测应该是,如果你打印一个文本文档,即使文档中有unicode编码,利用pring打印,它不会做任何改变,只会原封不动的打印你的txt文档(试想一下,谁愿意自己的文档不经自己的同意,已经被别人修改好了。即使你是好心的,我也希望你先经过我的同意吧)
所以,修改为:
file = open('info.txt',encoding='utf-8').read()
print(file.encode('utf-8').decode('unicode_escape'))