MySQL的索引B+树及MySQL日志:binlog、redolog、undolog讲解
MySQL的索引B+树、日志(redolog、binlog)
1 MySQL索引:B+树
1.1 B+树概念
- B+树一般是由多个页、多层组成,在MySQL中每个页有16KB
- 主键索引的B+树的叶子节点存放的才是数据,非叶子节点存放的是索引信息
- 上下层通过单指针相连
- 同一层级的相邻数据页通过双指针相邻
B+树结构图:

只有叶子节点存放的是数据,其他存放的都是索引信息【叶子节点数据,从左往右,值依次增大】
1.2 B+树的增删查【un‘’】
1.2.1 B+树与B树区别
- 相同层的B-树和B+树,B+树可以存储更多的节点元素,更加"矮胖"(磁盘IO少)。相比于B-树的中序遍历,B+树只需要向遍历单链表一样扫描一遍叶子节点即可。
- B+树的查询性能相较于B-树来说非常稳定,B+树中查询一个数据都需要到叶子节点中查询(都需要经过B+树层数那么多次IO);而B-树的查询性能并不稳定,对于根节点中关键字可能只有一次磁盘IO,而对于叶子节点中的关键字则需要高度次磁盘IO操作
B-树查询:
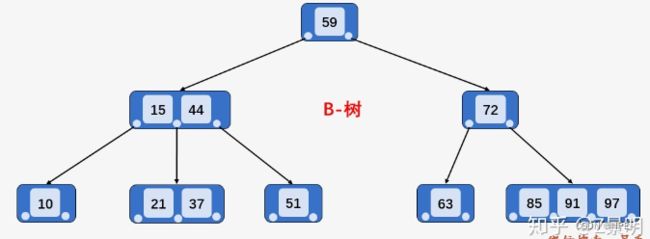
比如,查找上图B-树中的关键字59,仅需要一次磁盘IO操作,关键字21需要3次磁盘IO,关键字72需要2次磁盘IO
而B+树所有查询关键字的磁盘IO次数都是树的高度
1.2.2 B+树的查找元素(单个、区间)
【1】查找单个元素
以查询59为例:
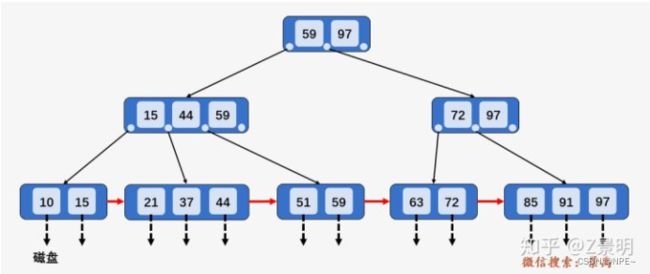
①第一次磁盘IO,访问根节点[59, 97],发现59小于等于[59, 97]中的97,则访问根节点的第一个孩子节点[15,44,59]
②第二次磁盘IO:访问节点[15, 44, 59]发现59大于44且小于等于59,则访问当前第三个孩子节点[51, 59]
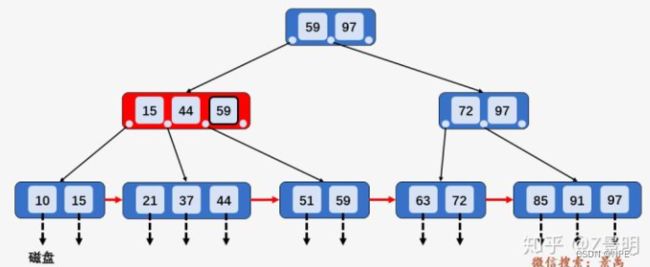
③第三次磁盘IO:访问叶子节点[51, 59],顺序遍历节点内部,找到要查找的元素59
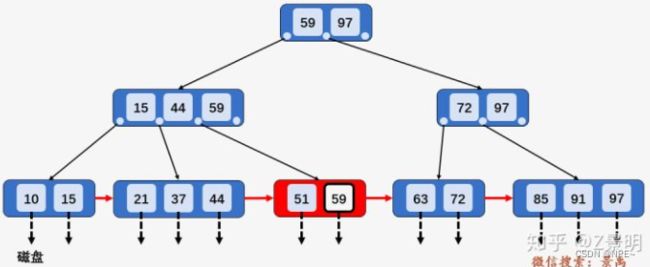
总结:
①B+树与B-树区别,对于B+树中每个元素的查找而言,每一个元素都有相同的磁盘IO操作次数(数据都是在叶子节点上的),即使查询的元素出现在根节点中,但那只是一个充当控制查找记录的媒介,并不是数据本身,数据真正存在于叶子节点当中,所以B+树中查找任何一个元素都要从根节点一直走到叶子节点才可以。
②B+树的非叶子节点不存储数据(官方将非叶子节点叫做"卫星数据")
【2】区间查询
- B-树的区间查询(以查询大于等于21,小于等于63的关键字为例):
①访问B-树的根节点[59],发现21比59小,则访问根节点的第一个孩子[15、44]
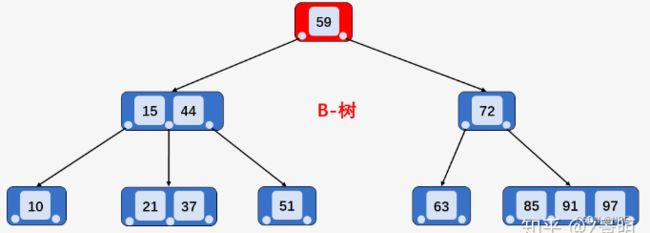
②访问节点[15、44],发现21大于15且小于44,则访问当前节点的第二孩子节点[21、37]
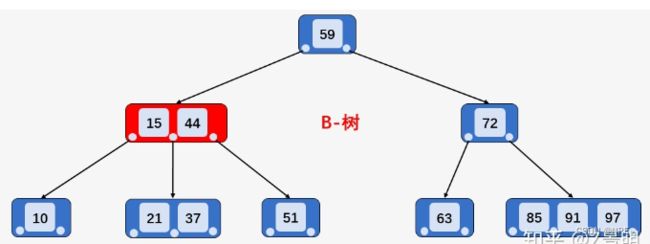
③访问节点[21、37],找到区间的左端21,然后从该关键字21开始,进行中序遍历,依次为关键字37、44、51、59,直到遍历到区间的右端点63为止,不考虑中序遍历的压栈和入栈操作,光是磁盘IO次数就多了两次,即:访问节点72和63
- B+树进行区间查找(同样是查找[21, 63]之间的关键字)
①访问根节点[59、97],发现区间的左端点21小于59,则访问第一个左孩子[15、44、59]
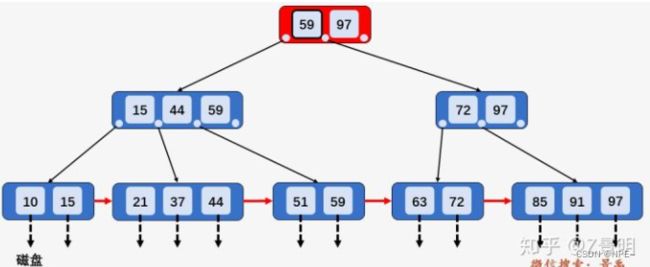
②访问节点[15、44、59],发现21大于15且小于44,则访问第二个孩子节点[21、37、44]

③访问节点[21、37、44],找到了左端点21,此时B+树的优越性就体现出来了,因为它不需要像B-树那样进行中序遍历,而是相当于单链表的遍历,直接从左端点21开始一直遍历到左端点63即可,没有任何额外的磁盘IO操作。【中序遍历 -> 单链表直接遍历,少磁盘IO】
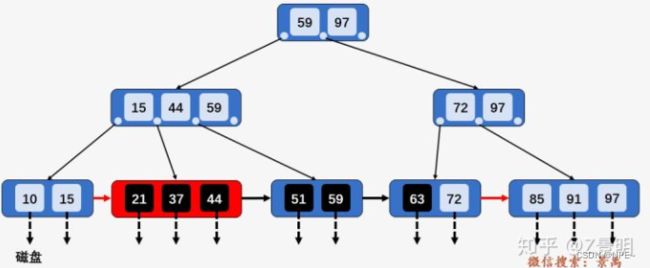
- 总结:
- 查找时磁盘IO次数更少,B+树的非叶子节点可以存储更多的关键字,数据量相同的情况下,B+树更加"矮胖",效率更高
- B+树查询所有关键字的磁盘IO次数都一样,查询效率稳定
- B+树进行区间查找时更加简洁实用
1.2.3 B+树的插入和删除操作
B+树的插入操作全部在叶子节点上进行,且不能破坏关键字自小而大的顺序
由于B+树的各结点中存储的关键字的个数都有明确的范围,做插入操作可能会出现节点中关键字个数超过阶数的情况,此时就需要将该节点进行"分裂";
B+数的阶数M=3,且[M/2]=2(取上限), [M/2]=1(取下限)
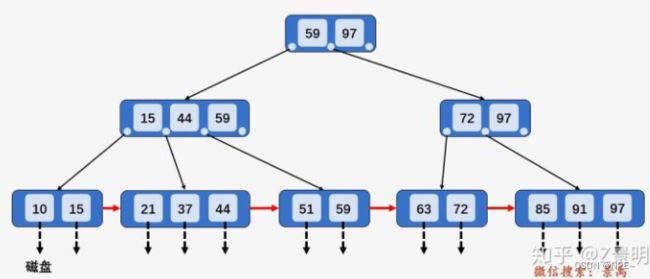
1.2.3.1 B+树的插入操作
注意点:
- 插入的操作全部在叶子节点上进行,且不能破坏关键字自小而大的顺序;
- 由于B+树中各节点中存储的关键字的个数都有明确的范围,做插入操作可能会出现节点中的关键字个数超过阶数的情况,此时需要将该节点进行"分裂"。【节点中的关键字个数超过阶数,分裂】
B+树插入操作的情况:
- 若被插入关键字所在的节点,其含有关键字数目小于阶数M,直接插入
插入关键字12,插入关键字所在的节点[10, 15]包含两个关键字,小于M,直接插入关键字12
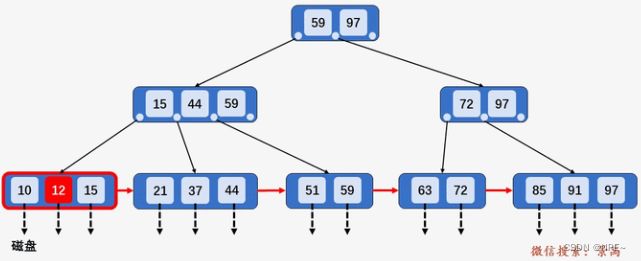
2. 若被插入关键字所在的节点,其含有关键字数目等于阶数M,则需要将该节点分裂为两个节点,一个节点包含[M/2], 另一个节点包含[M/2]。同时,将[M/2]的关键字上移至其双亲节点。假设其双亲节点中包含的关键字个数小于M,则插入操作完成。
插入关键字95,插入关键字所在节点[85,91, 97]包含3个关键字,等于阶数M,
则将[85, 91, 97]分裂为两个节点:[85, 91]和[97],关键字95插入到节点[95, 97]中,
并将关键字91上移至其双亲节点中,发现其双亲节点[72, 97]中包含关键字的个数为2,
小于阶数M, 插入操作完成。
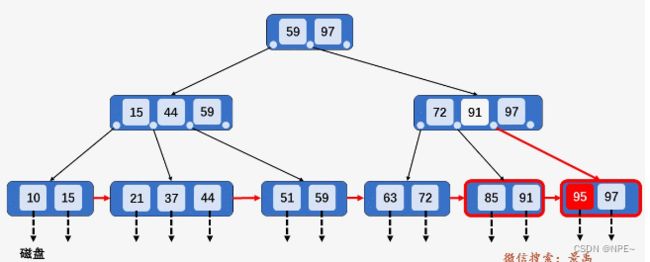
3. 在第2中情况的基础上,如果上移操作导致其双亲节点中关键字个数大于M,则应继续分裂其双亲节点。
插入关键字40,按照第2种情况将节点分裂,并将关键字37上移到父节点,发现父节点[15、37、44、59]包含的关键字的个数大于M,并将节点[15、37、44、59]分裂为两个节点[15、37]和节点[44、59],并将关键字移动到父节点中[37、59、97],父节点包含关键字个数没有超过M,插入结束。【类比堆结构的heapInsert上浮、heapify下沉】
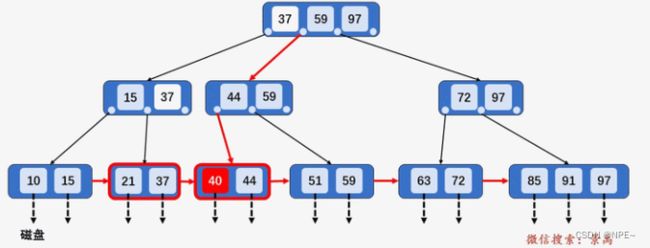
4.若插入的关键字比当前节点中的最大值还大,破坏了B+树中从根节点到当前节点的所有索引值,此时需要及时修正,再做其他操作。
插入关键字100,由于其值比最大值97还大,插入之后,从根节点到该节点经过的所有节点中的所有值都要由97改为100。改完之后再做分裂。【插入值比树中最大值还大:先改->分裂】
1.2.3.2 B+树的删除操作
在B+树中删除关键字时,也有以下几种情况:
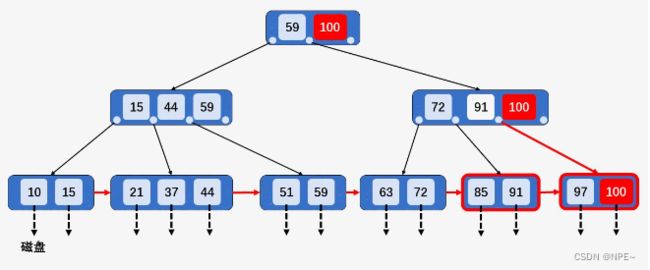
- 找到存储有关改该键字所在的节点时,如果该节点中关键字个数大于[M/2],做删除操作不会破坏B+树结构,可以直接删除。【目标所在节点个数大于[M/2],直接删除】
删除关键字91:包含关键字91的节点[85、91、97]中关键字的个数为3,大于[M/2] = 2, 做删除操作不会破坏B+树的特性,直接删除即可。
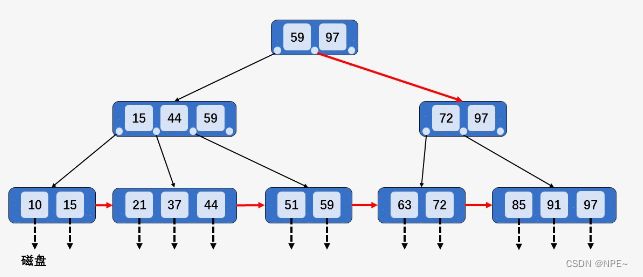
删除后:
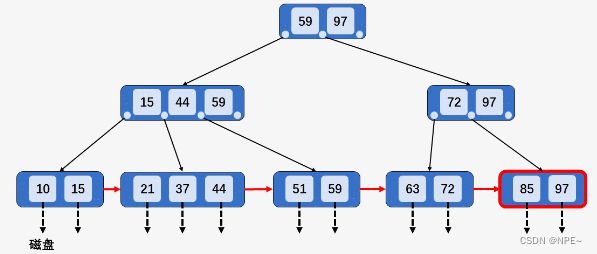
2. 当删除某节点中最大或最小的关键字,就会涉及到更改其双亲节点一直到根节点中所有索引值的更改。
以删除整棵B+树种最大的关键字97为例,然后向上回溯,将所有关键字97替换为次大的关键字:91。
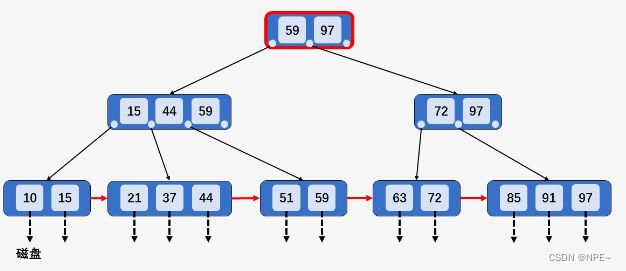
删除后:

- 当删除该关键字,导致当前节点中关键字个数小于[M/2],若其兄弟节点中含有多余的关键字,可以从兄弟节点中借关键字完成删除操作。当删除某个关键字之后,节点中的关键字个数小于[M/2],则不符合B+树的特性,则需要按照3和4两种情况分别处理。以删除关键字51为例,由于其兄弟节点[21、37、44]中含有3个关键字,所以可以选择借一个关键字44,同时将双亲节点中的索引值44修改为37。
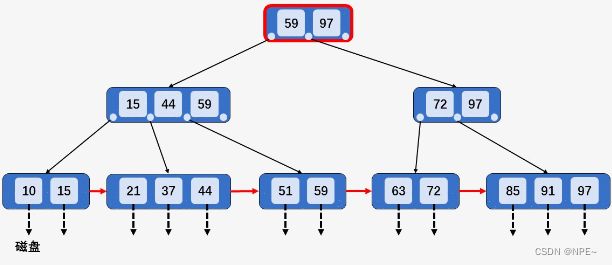
删除之后:

- 第3种情况中,如果其兄弟节点没有多余的关键字,则需要其同兄弟节点进行合并。
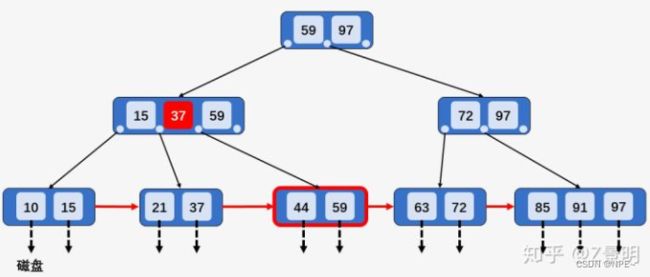
以在上图B+树的基础上删除关键字59为例。
首先查找到关键字59所在节点[44、59],发现该节点的兄弟节点[21、37]包含的关键字个数等于[M/2],所以删除关键字59,并将节点[21、37]和[44]进行合并[21、37、44],然后向上回溯,将所有关键字59替换为次最大的关键字44:
删除之后的结果:
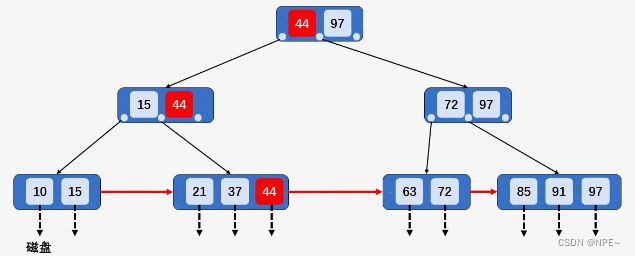
- 当进行合并时,可能会产生因合并使其双亲节点破坏B+树的结构,需要依照以上规律处理其双亲节点。
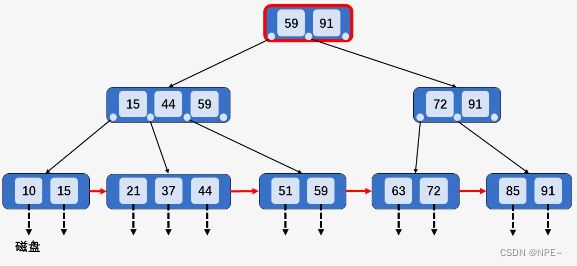
以删除关键字63为例。
当删除关键字后,该节点中只剩关键字72,且其兄弟节点[85、91]中只有2个关键字,所以将[72]和[85、91]进行合并,向上回溯,删除节点[72、91]当中的关键字72,此时节点中只有关键字91,不满足B+树种节点关键字个数要求,但其兄弟节点[15、44、59]中包含3个关键字,所以从其兄弟节点中借一个关键字59,再对其兄弟节点的父节点中的关键字进行调整,将关键字59替换为44.
删除关键字63之后:
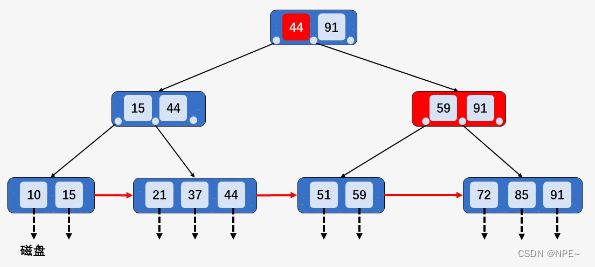
总结(B+树中删除操作):
- 不破坏B+树本身的性质,直接删除(情况1)
- 如果删除操作导致其该节点的最大或最小值改变,则对应改变其父节点中的索引值(情况2)
- 在删除关键字后,如果导致其节点中关键字个数不足,有两种办法:①向兄弟节点借 ②同兄弟节点合并(情况3、4、5)【注意:这两种方式有时需要更改父节点中的索引值】
原文链接:https://zhuanlan.zhihu.com/p/149287061
1.3 拓展:为什么MySQL不使用跳表?
1.3.1 跳表结构
跳表的结构就是单链表结构衍生出来的,其效率比单链表高很多。
跳表的最底层是单链表,跳表是具有多层级的。
跳表结构图:
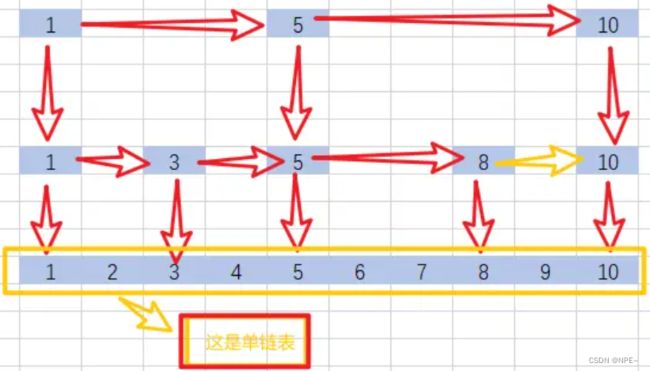
在普通的单链表结构中,我们不管寻找什么元素,都需要从头节点开始往下找,一个一个遍历,直到找到为止,这个样子效率是非常低的;而跳表的话,更多的是逐渐缩小范围,最终确定值。比如在上图跳表要寻找6,跳表只需要1,5,6就直接找到了,而单链表则需要1,2,3,4,5,6需要一个一个向下遍历。
由此可见,跳表的效率是很高的,这也是redis采用跳表实现zset的原因。
1.3.2 跳表与B+树的异同
- 相同点:这两种数据结构的查询效率都是极高的,而且都支持范围查询。否则的话,MySQL不会选择B+树作为索引结构,Redis不会选择跳过作为zset结构。
- 不同点:B+树在新增数据的时候可能面临页分裂问题(新增),并且B+树需要维护各种索引页。跳表在添加数据的时候,并没有什么页分列的说法,就算是索引分配也是非常简单的,它只需要利用一个random随机函数随机出需要出现的层级数就可以了,最底层级就是该数据不建立索引,只待在最底层的单链表处。
1.3.3 解答
MySQL为什么不用跳表建立索引呢?
- 跳表在存储大数据量的时候,层数多,磁盘IO次数太多,耗时更长
B+树:MySQL选用B+树建立索引,主要是因为B+树是多叉结构,而且根据它结构组织数据页/索引页,存放2kw数据只需要3层左右就可以了,目前在实践中,B+树的层数几乎没有超过4层。也就是说,如果是B+树索引的话,查找一次数据,一般最多也就是3次磁盘IO;
跳表: 而跳表中就不一样了,2kw的数据如果在跳表中存储,如果想要达到二分查找的效率的话,最起码需要2^24层级才能实现,而每个层级的数据是分散在不同的数据页中的,所以在查找数据的过程中,跳表可能需要进行24次磁盘IO。
我们都知道磁盘IO是非常消耗性能的,能够少磁盘IO就少磁盘IO,所以单凭这个点MySQL也不会选择跳表作为索引。【当然这个指示针对于查询数据而言,如果是写数据的话,跳表会比B+树优秀,因为在新增数据的时候,跳表不需要维护页(页分裂什么的),它只需要随机一个数就可以了】
那么为什么Redis会选择跳表来实现zset呢?
Redis是一个基于内存的数据库,它的数据几乎都在内存中,就算是使用跳表,就算2kw的数据会达到2^24此次方的层级,也不会影响效率。因为它们都是在内存中,不存在上面讨论的磁盘IO影响性能的问题。并且Redis使用跳表不需要担心B+树的页分裂之类的问题。
总结:
- MySQL为什么不用跳表
同样数据量,跳表比B+树层级更高,需要更多的磁盘IO
- Redis为什么不用B+树
Redis是基于内存的数据库,不考虑磁盘IO问题,采用跳表不用考虑B+树页分裂等问题
详细链接:https://juejin.cn/post/7132122469887901709
2 MySQL的日志
日志是MySQL数据库一个非常重要的部分,它记录着数据库运行期间的各种状态信息。MySQL日志主要包括错误日志、查询日志、慢查询日志、事务日志、二进制日志几大类。我们作为开发来说,重点需要关注的是二进制日志(binlog)和事务日志(包括redo log、undo log)。
2.1 binlog日志(记录每条写入性的sql语句)
2.1.1 概念
binlog用于记录数据库执行的写入性操作(不包括查询)信息,以二进制的形式保存在磁盘中。binlog是MySQL的逻辑日志,并且由Server层进行记录,使用任何存储引擎的MySQL数据库都会记录binlog日志。
- 逻辑日志:可以简单的理解为就是记录的SQL语句
- 物理日志:因为MySQL数据最终是保存在数据页中的,物理日志记录的就是数据页变更
binlog是通过追加的方式进行写入的,可以通过max_binlog_size参数设置每个binlog文件的大
小,当文件大小达到给定值之后,会生成新得文件来保存日志。
2.1.2 使用场景
在实际应用中,binlog的主要使用场景有两个:主从复制、数据恢复
- 主从复制:在Master端开启binlog,然后binlog发送到各个Slave端,Slave端重放binlog,从而达到主从数据一致【Slave端按照binlog一条一条执行,走Master走过的路】
- 数据恢复:通过使用mysql binlog工具来恢复数据
2.1.3 binlog刷盘时机
对于InnoDB存储引擎而言,只有在事务提交时,才会记录binlog,此时记录还在内存中,那么binlog是什么时候刷到磁盘中的呢?MySQL可以通过sync_binlog参数控制binlog的刷盘时机,取值范围是0-N:
- 0:系统自行判断,不强制要求
- 1:每次commit的时候都将binlog写入磁盘
- N:每执行N个事务后,将binlog写入磁盘
sync_binlog最安全的设置是1,这也是MySQL 5.7.7之后版本的默认值。但是设置一个大一些的值可以提升数据库的性能,因此根据自己业务实际情况,可以将值适当调大,牺牲一定的一致性来获取更好的性能。
2.1.4 binlog日志格式
binlog日志格式有三种:STATEMENT、ROW和MIXED
在MySQL 5.7.7之前,默认格式是STATEMENT,MySQL 5.7.7之后,默认值是ROW。日志格式可以通过binlog-format指定
- STATEMENT
基于SQL语句的复制(statemented-based replication, SBR),每一条修改数据的sql语句都会记录到binlog中
- 优点:不需要记录每一行的变化,减少了binlog的日志量,节约了IO,提高了性能
- 缺点:在某些情况下会导致数据不一致,比如执行sysdate()、slepp()等
- ROW
基于行的复制(row-based replication, RBR),不记录每条sql语句的上下文信息,仅需要记录哪条数据被修改了。
- 优点:不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题;
- 缺点:会产生大量的日志,尤其是alter table的时候会让日志暴涨(所有行都被删除)
- MIXED
基于STATEMENT和ROW两种模式的混合复制(mixed-based replication, MBR),一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog
2.2 redo log日志(记录事务对数据的修改,crash-safe问题)
我们都知道,事务的四大特性是ACID(Atomicity、Consistency、Isolation、Durability),其中C(Consistency)是持久性。具体来说就是只要事务提交成功,那么对数据库的修改就被永久保存下来了,不可能因为任何原因再回到原来的状态。那么MySQL是如何保证一致性的呢?最简单的做法就是每次再事务提交的时候,将该事务涉及修改的数据页全部刷新到磁盘中。但是这么做会有严重的性能问题,主要体现再两个方面:
- InnoDB是以页为单位与磁盘进行交互的,而一个事务很可能只修改一个数据页里面的几个字节,这个时候将完整的数据页刷到磁盘的话,太浪费资源了!
- 一个事务可能涉及修改多个数据页,并且这些数据页在物理上并不连续,使用随机IO写入,性能太差~
因此MySQL设计了redo log,具体来说就是只记录事务对数据页做了哪些修改,这样就能完美解决性能问题了(相对而言文件页更小,并且是顺序IO)
2.2.1 概念
redo log包括两部分:一个是内存中的日志缓冲(redo log buffer),另一个是磁盘上的日志文件(redo log file)。MySQL每执行一条DML语句(Data Manipulation Language:增删改查),就先将记录写入redo log buffer,后续某个时间点再一次性将多个操作记录写到redo log file。这种先写日志,再写磁盘的技术就是MySQL里经常说的WAL(Write-Ahead Logging)技术。【先写日志,后写磁盘】
在计算机操作系统中,用户空间(user space)下的缓冲区数据一般是无法直接写入磁盘的,中间必须经过操作系统内核空间(kernel space)缓冲区(OS Buffer)。因此redo log buffer写入redo log file实际上是先写入OS Buffer,然后再通过系统调用fsync()将其刷到redo log file中:
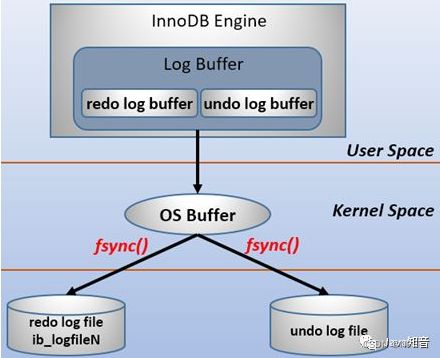
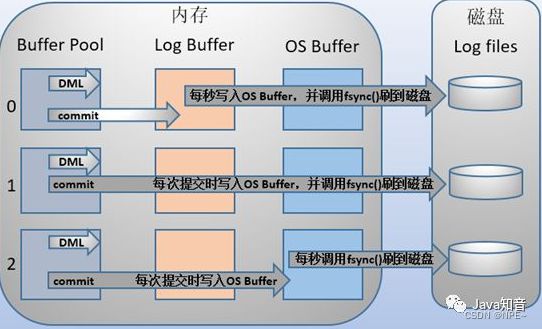
MySQL支持三种将redo log buffer写入redo log file的时机,可以通过innodb_flush_log_at_trx_commit参数配置参数,各参数值含义如下:
| 参数值 | 含义 |
|---|---|
| 0(延迟写) | 事务提交时不会讲redo log buffer中日志写入到os buffer,而是每秒写入os buffer并调用fsync()写入到redo log file中。也就是说,设置为0时,(大约)每秒刷新到磁盘中,当系统崩溃时,会丢失1秒中的数据 |
| 1(实时写,实时刷) | 事务每次提交都会将redo log buffer中的日志写入os buffer并调用fsync()刷到redo log file中,这种方式即使系统崩溃有不会有任何数据丢失,但是因为每次提交都写入磁盘,IO性能较差 |
| 2(实时写,延迟刷) | 每次提交都仅写入到os buffer,然后是每秒调用fsync()将os buffer中的日志写入到redo log file |
如图所示流程:
2.2.2 redo log记录形式
正如前面提到的,redo log实际上是记录数据页的变更,而这种变更是没有必要全部保存,因此redo log在实现上采用了大小固定,循环写入的方式,当写道结尾时,会回到开头循环写日志。
如下图:
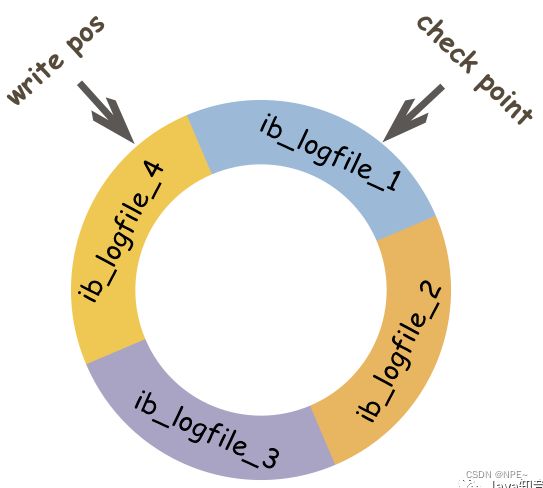
同时,我们很容易知道,在InnoDB中,既有redo log需要刷盘,还有数据页也需要刷盘,redo log存在的意义主要就是降低对数据页刷盘的要求。在上图中,write pos表示redo log当前记录的LSN(逻辑序列号)为止,check point表示数据页更改记录刷盘后对应redo log所处的LSN(逻辑序列号)位置。
write pos到check point之间的部分是redo log空着的部分,用于记录新的记录;check point到write pos之间是redo log待罗盘的数据页更改记录。当write pos追上check point时,会先推动check point向前移动,空出位置再记录新的日志。
启动InnoDB的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。因为redo log记录的是数据页的物理变化,因此恢复的速度比逻辑日志(如:binlog)要快很多。
情况一:
重启InnoDB的时,首先会检查磁盘中数据页的LSN,如果数据页的LSN小于日志中的LSN,
则会从checkpoint开始恢复
情况二:
在宕机前正处于checkpoint的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度,
此时会出现数据页中记录的LSN大于日志中的LSN,这时超出日志进度的部分将不会重复做,
因为这本身就表示已经做过的事情,无需再重复做。
2.2.3 redo log与binlog区别
| 对比范畴 | redo log | binlog |
|---|---|---|
| 文件大小 | redo log大小是固定的 | binlog可以通过配置参数max_binlog_size设置每个binlog文件大小 |
| 实现方式 | redo log是InnoDB引擎层实现的,并不是所有引擎都有 | binlog是Server层实现的,所有引擎都可以使用binlog日志 |
| 记录方式 | redo log采用循环写的方式记录,当写道结尾时,会回到开头循环写日志 | binlog通过追加的方式记录,当文件大于给定值后,后续的日志会记录到新的文件上 |
| 适用场景 | redo log适用于崩溃恢复(crash-safe) | binlog适用于主从复制和数据恢复 |
由binlog与redo log的区别可知:binlog日志只用于归档,只靠binlog是没有crash-safe崩溃恢复的能力的。但只有redo log也不行,因为redo log是InnoDB特有的,且日志上的记录落盘后会被覆盖掉。因此需要binlog与redo log二者同时记录,才能保证当数据库发生宕机重启时,数据不会丢失。
2.3 undo log日志(记录相反操作)
数据库的ACID中还有一个就是Atomicity 原子性。原子性:指对数据库的一系列操作,要么全部成功,要么全部失败,执行的操作之间不可分隔,不能出现部分成功的情况。
实际上,原子性底层就是通过undo log实现的。undo log主要记录了数据的逻辑变化,比如一条insert语句,就对应着一条delete的undo log,对于每个update语句,就对应着一条相反的update的undo log,这样在发生错误时,就能回滚到事务之前的数据状态。
undo log也是MVCC(多版本并发控制)的实现关键,设置到MySQL的事务和锁,这里不再叙述。
原文链接:https://zhuanlan.zhihu.com/p/190886874