开爬开爬
一.什么是爬虫
1.概念
爬虫的本质:模拟客户端(正常的用户)发送网络请求,获取对应的响应数据,以达到节省人工重复工作的目的。
网络释义:网络爬虫,又称为网络蜘蛛,网络机器人,网阔追逐着,是一种按照一定的规则,自动的抓取万维网的程序或者脚本。
从理论上说,只要是用户通过客户端(浏览器)能够做到的事情,爬虫就都能做到。但是总有一方是更厉害的,正常用户获取不到的数据,爬虫可能获取得到,只是可能会涉及到网络安全相关的知识(例如渗透)
2.严格区分渗透和爬虫
渗透一般是渗透测试,属于安全测试,主要是利用一切手段查找目标主机的漏洞
爬虫:模拟客户端访问,进行数据抓取
反爬:保护重要数据,防止恶意爬虫(恶意网络攻击)
反反爬:针对反爬做的措施,隐藏爬虫身份(尽可能拟人化)
3.爬虫的分类:
3.1.通用爬虫
通用爬虫又称为全网爬虫,爬取的对象从一些url扩充到整个web中,主要是为了门户站点搜索引擎和大型web服务提供商采集数据。这类爬虫爬取范围和数量都非常巨大,对于爬行速度和存储控件要求比较高,对于爬取界面的顺序相对较低,同时由于待刷新的页面太多,一般情况是采用并行的工作方式,但是需要较长时间才能刷新一次界面。虽然存在一定缺陷,通用网络爬虫适用于为搜索引擎广泛的主题,还是具有比较强的应用价值的。、
像我们平常使用的搜索引擎,百度,谷歌就可以说是一种通用爬虫
3.2.聚焦爬虫
聚焦爬虫又称为主题网络爬虫,指的是选择性的爬取那些预先定义好的主题相关页面的网络爬虫。与通用爬虫相比,聚焦爬虫只需爬取与主题相关的页面,极大的节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好的满足特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网络爬虫相比,增加了链接评价模块以及内容评价模块。聚焦爬虫爬行策略实现的关键是评价页面内容和链接的重要性,不同的方法计算出的重要性不同,由此导致链接的访问顺序也不同。
3.3.增量式爬虫
增量式网络爬虫是指对已下载网页采取增量式更新和只爬新生产的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的网页时尽可能新的页面。和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生的或发生更新的页面,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减少时间和空调关键上的耗费,但是增加了爬虫算法的复杂度和实现难度。增量式爬虫的体系结构包含如下:爬行模块➡️ 排序模块➡️ 更新模块➡️ 本地页面集➡️ 待爬行URL集
4.robot协议:
robot协议全称为“网络爬虫排除标准”,网络通过robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不可以抓取。如果将网站视为一个房间,robots。txt就是主任在房间门口悬挂的“请勿打扰”或“欢迎进入”的提示牌。这个文件告诉来访的搜索引擎那些房间可以进入和参观,哪些房间因为存放贵重物品,或可能设计住户及访客的隐私而不对搜索引擎开放。但robots.txt不是命令,也不是防火墙,如同守门人无法阻止窃贼等而已闯入者。
robots协议是国际互联网界通行的道德规范,基于以下原则建立:
1.搜索技术应服务于人类,同时尊重信息提供者的意愿,为维护其隐私权;
2.网站有义务保护其使用者的个人信息和私人信息不遭受侵犯
在网址的com后面添加/robots.txt可以查看网址的robot协议
例如百度:https://www.baidu.com/robots.txt
二.浏览器和编解码
1.网络请求的过程
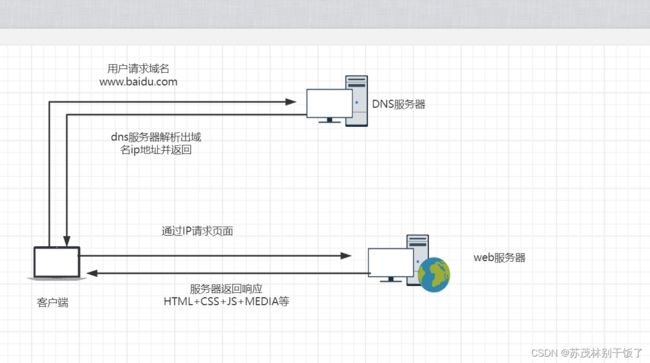
什么是DNS服务器?
在互联网中,所有的请求都是通过IP地址来进行数据的传输,网址、域名是不能够直接进行数据的传输的,所以浏览器在进行请求的时候会先将域名发送到DNS服务器,由DNS服务器先解析出域名对应的IP地址,然后再对IP地址进行请求。
DNS服务器就是将域名进行解析,解析出域名对应的IP地址
2.前端三剑客(HTML CSS javascript)
HTML:前端的骨架语言,相当于定义前端页面中存在的内容和元素,比喻成人体的骨架
CSS:前端中用于美化界面的语言,样式表,相当于化妆,将人变美
javascript:前端中实现逻辑操作的代码,相当于人体的器官
3.浏览器抓包工具
浏览器抓包工具打开方式:F12 或 CTRL+SHIFT+I 或 点击右上角,更多工具,开发者工具
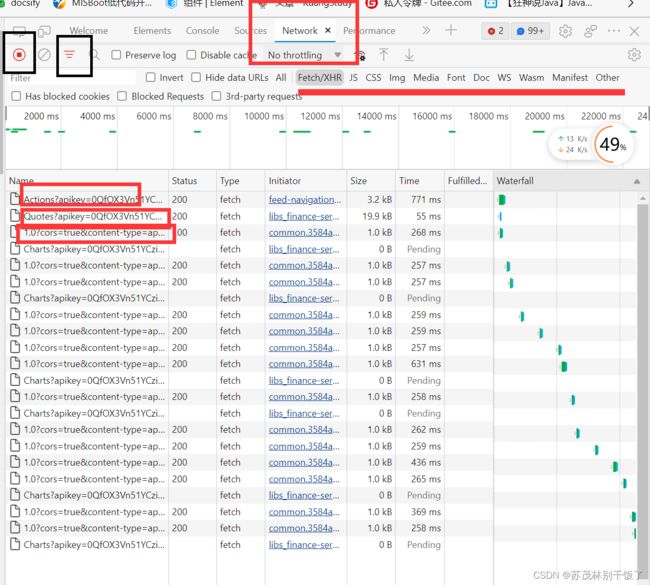
<1>学会看包network
network是浏览器中抓取到网络请求的数据包之后能够进行查看的版块,也就是当我们访问某一个网站得时候,我们可以在network中看到在当前网站中发起的请求量,即我们所说的"抓包"中的"包"。一个包即是一个请求
在左上角有一个红色的点,这个是数据包拦截记录的开关。只有在其亮时才能抓到这些包。
左上角的第三个图标则是分类开关
<2>常见的响应状态码
200:请求成功,被服务器响应并返回了数据、
301:永久重定向(跳转),例如访问域名A时,不管如何都会跳转到B页面
302:临时重定向,存在一定条件,满足条件是不会发生跳转
304:当前页面没有发生任何变化
5xx:表示服务器发生错误,服务器坏了
507:服务器中的存储问题,数据无法进行存储
404:找不到相关资源,网页迷路了,找不到了。
403:请求被服务器拒绝
401:参数验证没有通过
400:请求损坏,无效请求
405:请求方式不被允许,例如:代码在请求的时候发送的是get请求,但服务器需要接受的是post
206:数据流形式的文件传输,例如媒体文件的分段传输
状态码只是供我们参考的一个用于生成解决方案的数字,状态码仅供参考,因为状态码是可以由后端开发人员自定义的,也就是说即使响应成功,后端开发人员在设置的时候也可以设置为501,404等
<3>整体骨架
Headers:该资源的HTTP头信息
Preview:根据你所选择的资源类型(JSON,图片,文本)显示相应的预览
Response:显示HTTP的Response信息
Cookies:显示资源HTTP的Request和Response过程中的Cookies信息
Timing:显示资源在整个请求生命周期过程中各部分花费的时间
4.编解码
字符编码是现实世界的文字与计算机语言的链接桥梁,现实世界中每一个文字或者字符都有一串字符编码与其对应,当在计算机中输入这个文字时,系统会将其编译成字符编码供计算机识别使用。ASCLL是一种字符编码,字符编码以数字的形式呈现,最终由将数字转化成二进制
字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符集是多个字符的集合,包括ASCLL、GB2312、GB18030字符集、Unicode字符集等
ASCLL编码是一个字节,Unicode编码通常是两个字节
UTF-8是Unicode的实现方式之一,UTF-8是一种变长的编码方式,可以是1,2,3个字节
5.requests库介绍和初试
<1>初了解
requests是一个第三方模块,用于发起一个http请求,其支持http连接与保持
当今实现的爬虫程序大多都是基于requests库来实现
在终端使用pip install requests来下载,下载好后就可以使用requests模块了
请求方式有三种put、post、get。可以在请求方式中查找到。分析某个网站,如果是get请求那么就使用get方法来发起网络请求,并且获取到网站返回的响应(响应对象)
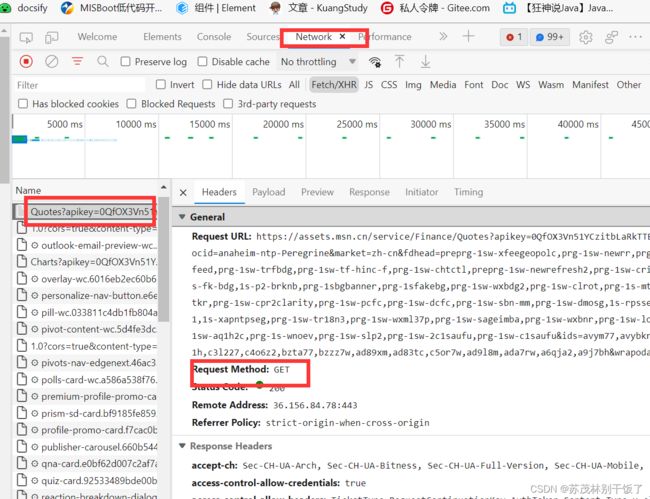
#request.post()
#request.put()
import requests
requests.get('https://www.baidu.com/')
response=requests.get('https://www.baidu.com/')#第一个参数,也是必须要传的一个参数,为url,网站的网址
print(response)
<2>request响应对象的属性
import requests
requests.get('https://www.baidu.com/')
response=requests.get('https://www.baidu.com/')
#第一个参数,也是必须要穿的一个参数,为url,网站的网址
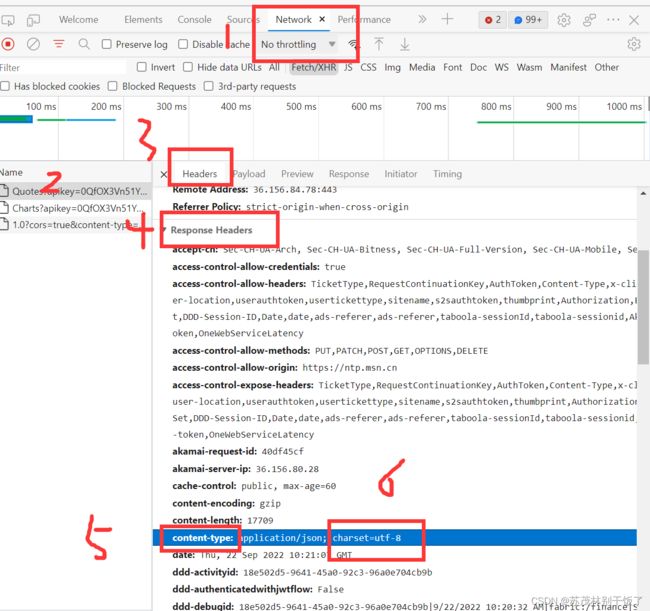
print(response.text.encode('latin-1').decode('utf-8'))
#text属性默认是latin-1,即iso-8859-1字符集来进行解码,编码后的字节类型数据来自互联网。见图一
(1)response.text 用于获取到当前相应的文本(就是前端对应url返回的html代码等),见图一
(2)response.content 用于获取互联网中传输的字节数据(一般用这个更多,更加灵活,不用思考数据的编码方式问题)
(3)response.headers获取响应头信息,一般是在cookies要实时发生改变的时候才会去获取响应头信息
(4)response.status_code获取响应状态码
(5)response.requests._cookies响应对应请求的cookie
(6)response.cookie 响应的cookie
(7)response.request.headers 响应对应的请求头
注意区分,response为响应对象,request为请求对象
图一:
6.用户代理User-Agent
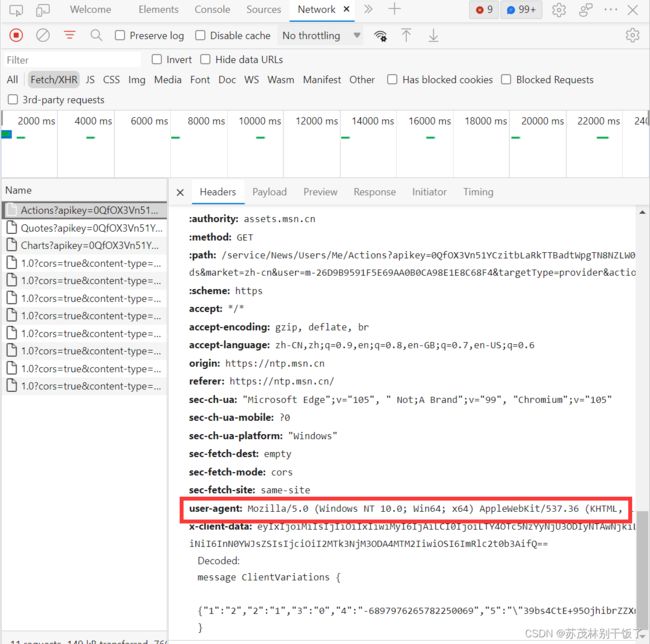
request的get方法的第三个参数是User-Agent,是一个键值对类型的数据。User-Agent的值在包中最下面的信息中可以找到,见图二
#语法:
# 变量={User-Agent:'值'}
#用法:
# requests.get(url,header=变量)
import requests
response=requests.get('https://www.baidu.com/')
print(response.request.headers)#请求头信息
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.42'}
response=requests.get('https://www.baidu.com/',headers=headers)
#headers是get方法的第三个参数,所以现在必须写成headers=''
print(response.request.headers)#请求头信息

在没有设置headers时,User-Agent的值为python-requests/2.28.1,意思就是这是python的一个请求,版本号为后面的数字。也就是告诉了别人,这是一个爬虫的请求。在设置了后User-Agent变成了一个正常
headers:称为头部信息,如果实在请求中被称为请求头,在响应中被称为响应头
请求头:在用户访问服务器的时候由服务器进行验证的相关头部信息(参数),由用户(浏览器、程序员)进行设置。
用户负责设置,服务器进行接收
响应头:是服务器接受到用户的请求之后,在返回响应数据的同时为用户设置相关的头部信息,用户在接收到相关的响应头部信息之后,会根据服务器响应回来的这些头部信息来判断哪些信息是可能在下一次请求的时候需要进行构造,如果需要那么将部分参数添加到请求头中再次进行请求。
由服务器进行设置,用户负责接收
爬虫请求中增添请求头的目的:
1.用于服务器对部分参数进行相关验证
2.伪装成表面正常的用户身份
User-Agent(用户代理),对User-Agent进行伪装然后发起请求的过程,UA伪装属于入门阶段接触的第一个反反爬手段。
UA中存放的就是操作系统和浏览器的相关配置,因此每个人的UA可能相同,也可能不同。
在不同环境编写爬虫代码的时候,UA可以和其他环境中的UA保持一致。
服务器对于异常请求也不是直接封掉整个UA,封禁的条件绝对不是根据UA来进行判断。
之所以对UA进行伪装,是为了让服务器表面上认为其是一个正常用户。同时对于多个UA的伪装也是为了让服务器认为每次的请求都是来自不同的用户。
对于UA伪装,要尽可能做到多次请求之后切换另一个不同的UA来进行访问,以达到服务器认为我们发起的请求时来自不同的用户,来降低被服务器认出的几率
由多个UA构成能够用于代码中的请求的集合,成为UA池,UA的获取不用自己构造,找度娘
import requests
import random
#random是一个内置模块,主要用于随机数产生,也可以用于某一个组织(列表、集合等)去随机挑去一个元素。
UAS={
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/5.0)',
'Mozilla/4.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/5.0)',
'Mozilla/1.22 (compatible; MSIE 10.0; Windows 3.1)'
}
headers={'User-Agent':random.choice(list(UAS))}#强转为了列表,因为集合是无序的,有可能在随机调用时出现一些问题
response=requests.get('https://www.baidu.com',headers=headers)
print(response.request.headers)
7.url传参
在网络请求中,常见的参数传递类型由路径参数,查询参数,表单数据等
查询参数
在任何请求方式中都可能存在
结构:在url中,末尾处以?进行连接(连接访问的url地址),多个参数以&进行连接即能够构造成如下格式
https://music.163.com/#/my/m/music/playlist?id=2670618538&name=susu&age=18
/my/m/music/playlist路径参数
id=2670618538&name=susu&age=18 查询参数
查询参数也是键值对的形式,即查询参数中只有部分是有效参数(能够控制页面的返回数据内容),无效参数就是该参数无论是否传递都不会影响相应的内容。
在爬虫中对于查询参数的传递有两种方式:
1.直接构造在url中
import requests
import random
headers={'User-Agent':'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)'}
url='https://cn.bing.com/images/search?q=%E7%BE%8E%E5%A5%B3%E5%9B%BE%E7%89%87'
response=requests.get(url,headers=headers)
print(response.content.decode())
2.定义params参数然后传参到请求对象中
(这个是为了有的url中参数很多,为了整洁将查询参数放入params中
import requests
import random
headers={'User-Agent':'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)'}
url='https://cn.bing.com/images/search'
params={
'q':'美女图片'
}
response=requests.get(url,headers=headers,params=params)
print(response.content.decode())
8.url转义
from urllib.parse import quote,unquote
print(unquote('美女')) #将明文转换为密文
print(quote('%E7%BE%8E%E5%A5%B3%E5%9B%BE%E7%89%87')) #将密文转换为明文
9.cookie
简介
当用户通过浏览器首次访问一个域名时,访问的web服务器会给客户端发送数据,以保持web服务器与客户端之间的状态保持,这些数据就是cookie,他是Internet站点(服务器)创建的,为了辨别用户身份而储存在用户本地终端上的数据,cookie大部分都是加密的,cookie存在于缓存或者硬盘中,在硬盘中是一些文本文件,当你访问该网站时,就会读取对应的网站的cookie信息,cookie有效地提升了用户体验,一般来说,一旦将cookie保存在计算机上,则只有创建该cookie的网站才能读取它
简单来说,cookie就是用于状态保持的相关信息的存储媒介,存储于用户本地
作用:在爬虫中主要用于用户的登陆状态保持,模拟登录(模拟一个正常用户登陆网站),保存用户 的访问记录、用户的轨迹特征等
session同cookie一样,也是用于会话保持使用,其功能和cookie一致,session存储于网站服务器
cookie的产生
第一次访问一个全新的网站的时候,是没有携带任何cookie信息进行请求的(cookie是由服务器设置)。
第二次或之后再访问的时候,会携带上一次服务器设置的cookie来进行请求。(即在再请求的时候,会携带所有与网站有关的cookie进行请求),如果之后的请求与前面的请求的cookie出现重复的参数,那么后面的请求获取的cookie参数会直接覆盖掉之前请求的cookie参数,以最新的为准
了解状态
浏览器请求服务器都是无状态的
无状态:指一次用户请求时,浏览器和服务器都不知道这个用户做过什么,每次请求都是一次新的请求
实现状态保持的两种方式:
1.在客户端使用cookie存储信息(存储与用户本地)
2.在客户端使用session存储信息(存储与服务器)
代码中的每一次requests.get()或post都是一个无状态请求,每一次服务器都不认为你是一个它认识的用户。如果服务器需要验证用户的访问权限,就需要携带着cookie进行访问,一个cookie就代表一个用户。
优点:能够获取一些需要登录或者需要二次验证之后才能获取的数据,伪装用户身份
缺点:一个cookie对应一个账号(如果有登录),大大增加了账号被封尽的几率,用户身份更容易被发现。搭建用户池(cookie池),利用不同账号来获取到不同的cookie信息,请求的时候从池中随机取出cookie访问
特征
1.基于域名安全,不同网站下的cookie不会相同,即网站A的cooki不会应用于网站B
2.cookie是可以具有一定有效期的
<1>会话cookie
当浏览器关闭的时候,cookie会自动删除
<2>持久cookie
浏览器关闭后cookie并不会自动删除,而是由服务器在设置cookie的时候同时为cookie设置有效期,默认为两个星期,也可以自定义,因此对于cookie的有效期来说,开发人员无法直接通过代码判断cookie的有效期,当然可以通过js代码来查看当前某一个cookie的有效期,python是无法直接查看cookie的有效期,cookie的有效期其实对于爬虫来说没有多大意义,主要由于如果要使用cookie的时候都基本是直接获取最新的cookie来进行代码的开发以及后期实现cookie的自动获取
三.网易云案例
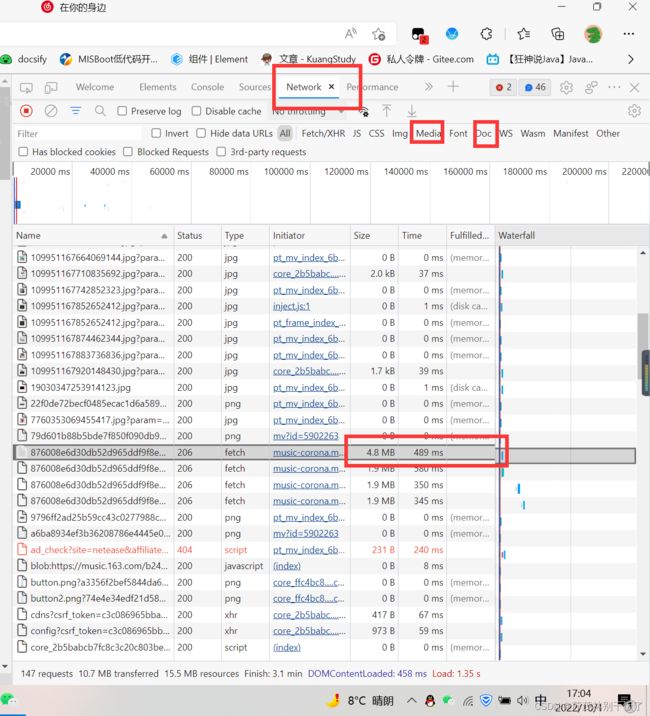
这是在网易云中随便找了一首歌曲的mv,注意在播放mv页面的网址并不是视频所在地址。我们可以打开开发者工具,刷新界面进行抓包。因为我们要下载的是媒体数据,所以挑选包时可以在media中进行筛选,然后看包的路径是否和我们想要的一致不一致。如果在media中没有也可以在all或XHR中寻找,根据所抓包的特性,因为音频、视频文件一般很大,所以寻找内存大,传输时间长的包。然后查看其url,进行测试来确定是不是我们需要的音频文件。
常见的媒体文件扩展名:MP3,MP4,ts,mv,m4s,m4a,mmpv,mmv等。加深对url的解读可以更加准确的进行抓包。
注意进行测试的时候如果没有打开要播放的mv,并不意味着我们挑选出的url不是视频所在地址,也有可能是因为进行了加密。在通过代码测试后也有可能是可以成功将视频下载下来的。
接下来是代码。不变的配方:headers,url
import requests
headers={'User-Agent':'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)'}
url='https://vodkgeyttp8.vod.126.net/cloudmusic/ICAwICQ4IGQgZTBjISUwJA==/mv/5902263/876008e6d30db52d965ddf9f8e16e624.mp4?wsSecret=aa820a6b23ded23cbe7e412f6d65da22&wsTime=1664614896'
response=requests.get(url,headers=headers)
#计算机只认识0和1,因此要保存的任意类型的文件
mv_data=response.content
with open('在你的身边mv.mp4','wb')as f:
f.write(mv_data)
运行代码后,右击’在你的身边mv.mp4’➡️show in explorer。如果版本是之前的版本可能没有这个选项,可以右击copy path,选择绝对路径。在计算机中复制该路径来找到我们所写入的音频,然后打开该文件就可以播放了。
保存下来的文件能够播放那么证明当前请求的url一定是媒体文件所在的地址。如果不能播放,不一定证明其就不是媒体文件的播放地址。其中可能由于请求头中某一个参数需要服务器验证或者用户身份需要服务器验证,例如需要vip才可以观看的视频,在之后的学习中了解cookies后就可以慢慢了解。
在学习了数据分析后就可以进行mv的批量下载。
ffmpeg:一个用于处理音视频的工具,可用于合成(音频和视频合成或者视频和视频合成)或分离
将视频中的音频进行分离,分离后源文件保持不变,会分成一个音频文件。
抽离视频中的音频时,生成的音频文件不能以MP3结尾,ffmpeg抽离的时候不支持直接生成MP3文件,生成的是m4a,mmv,qmmv等
现在学习的脚步有些太慢了,爬虫手段也粗糙的很。
我一定会迎头赶上的家人们,加油!苏钰烯也加油