Nacos架构与原理 - 注册中心的设计原理
文章目录
- Pre
- 服务的分级模型 (服务-集群-实例三层模型)
- 数据⼀致性
- 负载均衡
-
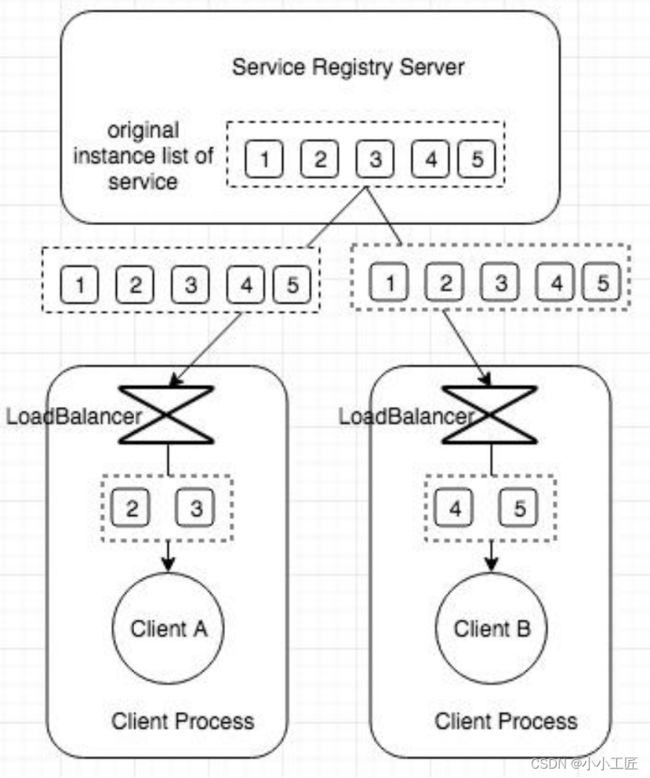
- 服务端侧负载均衡
- 客户端侧负载均衡
- 健康检查
- 性能与容量
- 易用性
- 集群扩展性
- 用户扩展性

Pre
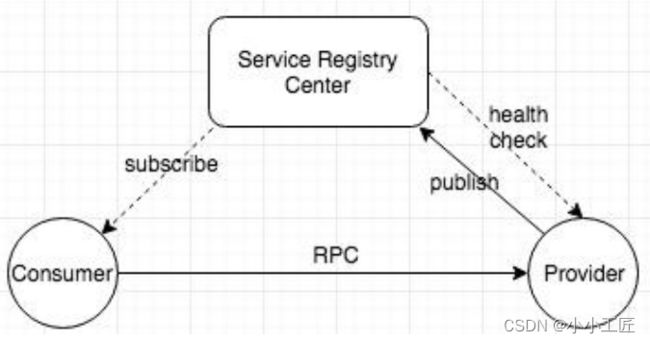
目前的网络架构是每个主机都有⼀个独立的 IP 地址,那么服务发现基本上都是通过某种方式获取到服务所部署的 IP 地址。
DNS 协议是最早将⼀个网络名称翻译为网络 IP 的协议,在最初的架构选型中,
DNS+LVS+Nginx 基本可以满足所有的 RESTful 服务的发现,此时服务的 IP 列表通常配置在 nginx或者 LVS。
后来出现了 RPC 服务,服务的上下线更加频繁,人们开始寻求⼀种能够支持动态上下线并且推送 IP 列表变化的注册中心产品。
个人开发者或者中小型公司往往会将开源产品作为选型首选。
-
Zookeeper 是⼀款经典的服务注册中心产品(虽然它最初的定位并不在于此),在很长⼀段时间里,它是国人在提起 RPC 服务注册中心时心里想到的唯⼀选择,这很大程度上与 Dubbo 在中国的普及程度有关。
-
Consul 和 Eureka 都出现于 2014 年,Consul 在设计上把很多分布式服务治理上要用到的功能都包含在内,可以支持服务注册、健康检查、配置管理、Service Mesh 等。而 Eureka则借着微服务概念的流行,与 SpringCloud 生态的深度结合,也获取了大量的用户。
-
Nacos则携带着阿里巴巴大规模服务生产经验,试图在服务注册和配置管理这个市场上,提供给用户⼀个新的选择。
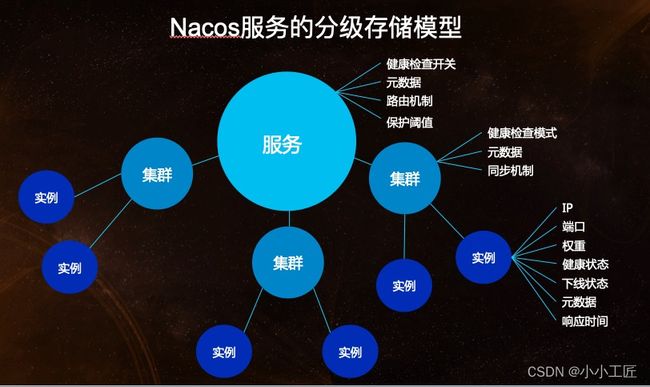
服务的分级模型 (服务-集群-实例三层模型)
注册中心的核心数据存储模型一般分为三层:
- 服务级别:存储服务名称和网络地址,以及服务级别的属性,如权限规则等。
- 集群级别:针对大规模服务,其实例可能划分为不同的集群,每个集群又有不同的配置,所以在服务和实例之间再增加一个集群级别的数据。
- 实例级别:存储实例的网络地址,健康状态,权重等属性。针对实例级别的数据可以实现实例过滤、流量分配等功能。
Zookeeper的数据存储以树形K-V的形式比较抽象,可以存储任意语义的数据,但无法很好满足服务发现的数据模型需求。
Eureka和Consul的数据模型扩展到了实例级别,可以满足大多数场景,但无法满足大规模多环境部署的需求。
Nacos提出的服务-集群-实例三层模型,可以满足服务在任何场景下的全部数据存储和管理需求,这是其核心数据模型的设计思想。
所以,注册中心的数据模型设计的核心在于:
-
- 服务级别:存储服务基本信息
-
- 集群级别:用于大规模服务实例的划分管理
-
- 实例级别:存储实例详细信息,实现实例管理和流量控制
一个良好的设计可以满足从小规模到大规模服务的全部数据存储和管理需求。
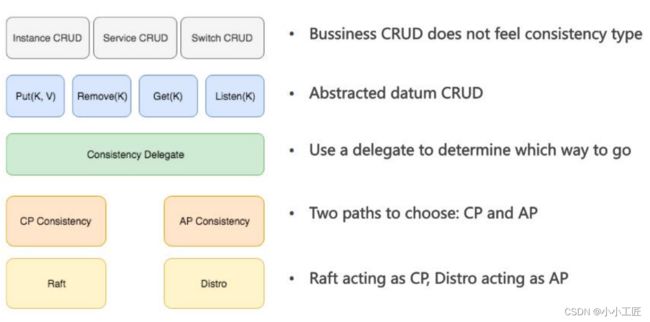
数据⼀致性
-
- 数据一致性协议主要分为两种:基于Leader的单点写一致性(CP)和对等多写一致性(AP)。
-
- 没有一种协议能覆盖所有场景。当服务注册无心跳时,CP协议是唯一选择,因为无法通过心跳补偿数据。当有心跳时,CP协议的单点性能瓶颈不太合适,AP协议更好,如Eureka的Renew机制。
-
- Zookeeper使用ZAB协议保证强一致,但机房容灾能力差,不适合大规模场景。如果像Dubbo那样使用临时节点和心跳续约,Eureka的Renew机制更合适。
-
- Nacos支持AP和CP协议共存,以满足不同场景需求。1.0版本重构了读写和同步逻辑,将业务逻辑和底层同步逻辑隔离。业务读写抽象为Nacos数据类型,通过一致性服务同步。在选择AP或CP时使用代理和规则进行转发。
-
- Nacos的CP实现基于简化Raft,保证半数一致和少量数据丢失。AP实现基于自研Distro协议,参考ConfigServer和Eureka,在无第三方存储的情况下实现。Distro主要优化了逻辑和性能。
所以,一个良好的注册中心设计需要:
-
- 支持CP和AP协议,满足不同场景的需求。
-
- 好的扩展性,避免单点性能瓶颈。
-
- 强大的容灾能力,支持大规模部署。
-
- 灵活的数据读写机制,可以根据协议特点选择最优方案。
-
- 自研的一致性算法,可以更好地满足产品需求
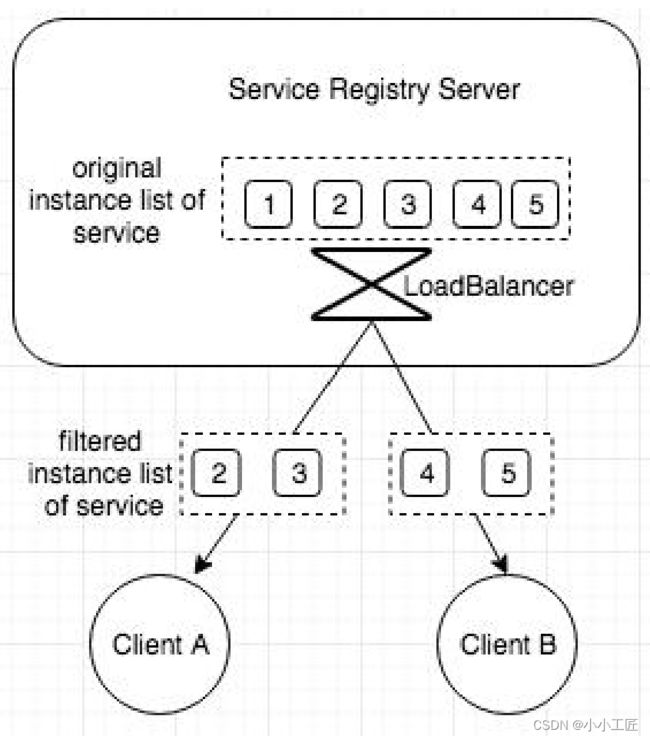
负载均衡
- 负载均衡严格来说不是注册中心的功能,注册中心主要提供服务发现。服务消费者根据自己的需求选择服务提供者。
- Eureka、Zookeeper和Consul本身不提供负载均衡,Eureka的负载均衡由Ribbon实现,Consul的由Fabio实现。
- 阿里巴巴使用相反的思路,服务消费者不关心负载均衡,只关心高效正确访问服务。服务提供者高度关注流量调配,否则可能导致压垮服务。
- 服务端负载均衡给服务提供者更强的流量控制,但无法满足不同消费者的负载均衡策略需求。客户端负载均衡提供更多自定义选项,但配置不当可能导致热点或不可访问。
- Ribbon的两步负载均衡:1)过滤不符合条件的服务提供者;2)在符合条件的服务提供者中选择一个,实施负载均衡策略。Ribbon提供多种策略和扩展接口。
- 基于标签的负载均衡非常灵活,可实现任意比例和权重的流量调配。需要标签存储和管理,如注册中心或第三方CMDB。
- Nacos 0.7开始支持基于标签的负载均衡,目前实现同标签优先访问。Nacos支持的标签表达式还不丰富但会扩展。Nacos还定义了Selector作为负载均衡的抽象。
- 理想的负载均衡实现因人而异。Nacos试图结合服务端和客户端负载均衡,提供扩展性和选择权,简单易用。Nacos试图提供各种策略,如果没有也要允许用户扩展。
- 注意注册中心是否提供需要的负载均衡策略和简单的使用方式。如果没有,是否可以方便扩展实现需求的策略。
服务端侧负载均衡
客户端侧负载均衡
健康检查
- Zookeeper和Eureka都实现了TTL机制,如果一定时间内客户端不发送心跳,将其摘除。Eureka允许注册服务时定义检查自身状态的健康检查方法。Dubbo和Spring Cloud将此视为默认行为。
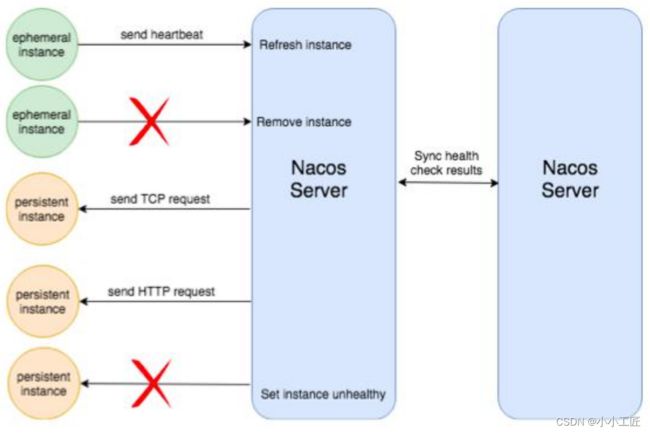
- Nacos也支持TTL机制,但与ConfigServer的机制有区别。Nacos支持临时实例使用心跳维持活性,默认心跳周期5秒。15秒无心跳设置为不健康,30秒摘除。
- 有些服务无法上报心跳但可以提供检测接口。这些服务同样强烈需要服务发现和负载均衡。
- 服务端健康检查常见方式是TCP端口探测和HTTP接口返回码探测,支持大多数场景。特殊场景需要特殊接口,如判断是否主库的MYSQL命令。
- 客户端健康检查关注客户端心跳方式和服务端摘除不健康客户端机制。服务端健康检查关注探测客户端方式、灵敏度和设置客户端健康状态机制。
- 服务端探测更复杂,需要执行接口判断返回结果、重试机制和线程池管理。客户端探测只需等待心跳刷新TTL。
- 服务端健康检查无法摘除不健康实例,需要维持所有注册实例的探测任务。客户端可以随时摘除不健康实例,减轻服务端压力。
- Nacos既支持客户端也支持服务端健康检查,同一服务可以切换模式。多样性健康检查方式支持各种服务使用Nacos负载均衡。
- Nacos下一步要实现健康检查方式的用户扩展机制,支持用户传入业务语义请求由Nacos执行,实现健康检查定制。
总之,Nacos通过支持多种健康检查方式,让更多类型的服务可以使用其负载均衡功能。同时也要继续扩展健康检查方式,进一步增强定制性。
性能与容量
-
影响性能的因素很多,如一致性协议、机器配置、集群规模、数据量、数据结构和逻辑设计等。
-
在服务发现场景下,读写性能都很关键,但性能更高并不一定更好,可能要牺牲其他方面。
-
Zookeeper写性能可达万级TPS,得益于精巧设计,但需要前提:仅进行K-V写入,无聚合或健康检查等;Paxos协议限制规模,3-5节点不能满足大规模服务订阅查询。
-
评估容量不仅考虑现有服务规模,也要预测未来3-5年的扩展规模。阿里内部中间件支撑百万级实例,面临的容量挑战不小于任何互联网公司。容量不仅是实例数,还有单个服务实例数、订阅者数和QPS等。
-
Nacos淘汰Zookeeper和Eureka,容量是一个非常重要的因素。
-
Zookeeper存储节点数可达百万级,但并不代表全部容量。大量实例上下线时表现不稳定,推送机制缺陷导致客户端资源占用上升和性能下降。
-
Eureka在5000个服务实例左右就出现不可用问题,高并发线程数会使Eureka崩溃。1000个左右的实例大多数注册中心都可以满足,Eureka也未在国内看到广泛的容量或性能问题报告。
-
Nacos开源版本可注册1千万服务实例,10万个服务。实际部署会因机器、网络、JVM参数不同而差别。
-
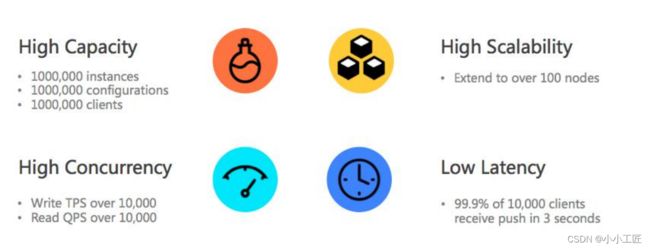
Nacos 1.0.0压力测试结果:
- 容量:注册实例1000万,服务10万
- 并发:读写QPS可达每秒5万
- 扩展性:预期机器数线性扩展性能
- 延迟:99%在10毫秒以内,极端场景100毫秒
总之,Nacos通过测试展示了较高的容量和性能,同时具有较好的扩展性,这些优势有助于满足用户的容量和性能需求。但实际使用中仍需根据自己的场景进行测试评估.
完整的测试报告可以参考 Nacos 官网:
https://nacos.io/en-us/docs/nacos-naming-benchmark.html
https://nacos.io/en-us/docs/nacos-config-benchmark.html
易用性
- 易用性包括API和客户端简单性、文档完整易懂、控制台界面完善等。对开源产品还包括社区活跃度。
- Zookeeper易用性较差:
- 客户端使用复杂,无针对服务发现的API和模型
- 多语言支持不好,无好用控制台进行运维管理
- Eureka和Nacos较Zookeeper改善很多:
- 有针对服务发现的客户端和Spring Cloud Starter,低成本无感知服务注册与发现
- 标准HTTP接口,支持多语言和跨平台
- Eureka 2.0宣布停止开发,易用性提高后续投入应减少。Nacos继续建设:
- 增强控制台能力,增加控制台登录权限管控、监控与Metrics暴露
- 不断完善文档,开发多语言SDK等
集群扩展性
Nacos支持两种模式:
- AP,如Eureka,支持临时实例,替代Zookeeper和Eureka,支持机房容灾
- CP,支持持久化实例,不支持双机房容灾
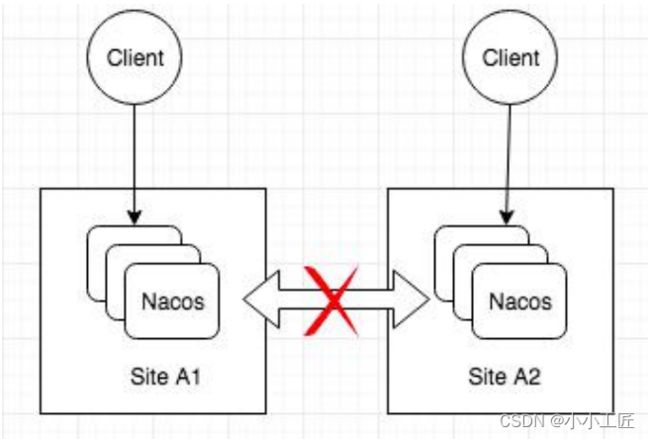
- Zookeeper和Eureka无官方多数据中心方案。Nacos基于阿里内部经验,采用Nacos-Sync组件在数据中心同步全量数据。Nacos-Sync不仅同步Nacos集群,也同步Eureka、Zookeeper、Kubernetes和Consul。
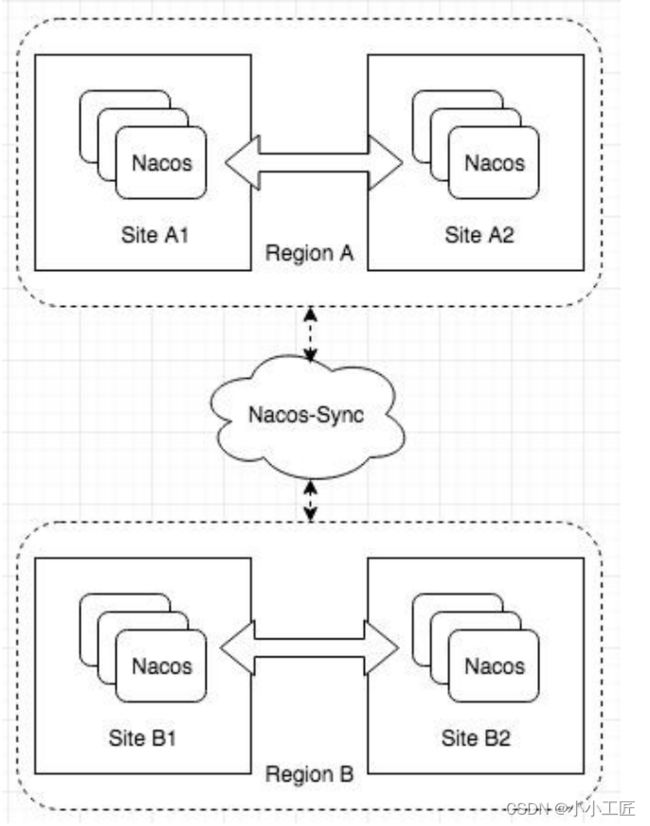
总之,Nacos支持临时实例AP模式和持久化实例CP模式来兼容不同场景。AP模式可替代Zookeeper和Eureka,支持机房容灾,但CP模式不支持。Nacos也提供异地多活和多数据中心方案,依赖Nacos-Sync实现数据中心同步。而Zookeeper和Eureka在这些方面支持较差。但具体选择还需考虑自身需求和使用成熟度。
用户扩展性
- 在框架设计中,扩展性是重要原则。Spring等通过接口及动态类加载实现用户扩展约定接口和自定义逻辑。
- 在服务器设计中,用户扩展审慎,可能影响可用性和排查难度。良好SPI可能带来稳定性和运维风险,需仔细考虑。
总之,框架设计注重扩展性,但服务器端考虑稳定性,需审慎。开源软件通过直接贡献实现扩展,是好模式。Zookeeper和Eureka不支持。Runtime扩展更佳,可简单解耦,对某功能设计时考虑。产品应支持用户Runtime扩展,需健壮SPI。Nacos已/将开放CMDB、健康检查、负载均衡扩展,支持解耦各需求。
