3.1 哈希键和集合键的渐进编码
出于同样的为了节省空间的目的,哈希键和集合键也有两种不同的编码
对于Hash来说,当同时满足以下两个条件时:
- 元素个数≤hash-max-ziplist-entries(默认为512)
- value的最大空间占用≤hash-max-ziplist-value(默认为64)
Hash键采用压缩列表(ziplist)的形式实现,任意一个不满足,将会采用hashtable,也就是字典实现。
对于Set来说,当满足这一个条件
- 元素个数≤set-maxintset-entries(默认为512)
- 元素类型全部为整数类型
Set键采用整数集合(intset)的形式实现,任意一个不满足,将会采用hashtable,也就是字典实现。
我们可以用通过调整上面展示的两种参数来灵活控制这种转化的时机.
顺带一提,我们之前对于压缩列表的笼统认识仅仅停留在它可以很好的压缩空间,但是到底能压缩多少,仍是一种模糊的概念,接下来将就压缩列表深入的讲解其在Redis中的应用
3.2 量化研究压缩列表
(From《Redis开发与运维》)
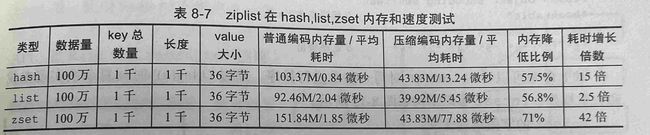
表8-7显示了压缩列表在其他数据结构中最典型的底层实现,可以看到,压缩列表在很多情况下是一些数据结构在元素规模较小时的首选,这是因为对于仅仅几百个元素的键来说,即便是O(N²)的复杂度,也是完全可以接受的开销,相比而言,redis的作者更愿意用这些开销来换取内存的节省,毕竟这是Redis赖以生存的土壤,因为我们可以从后面的介绍得知,内存淘汰的过程也是一个相当消耗cpu的过程,对内存的节省也就会大大延迟内存淘汰的到来或者减轻其运行时的压力,这对于单线程的redis的运行稳定来说,显然是经过了精打细算的好设计。
那我们来细细解读一下上面的表8-7,可以看到:
- 压缩列表的节约是非常惊人的,在Zset(一种带索引的排序链表结构,后文将会详细介绍)中达到了惊人的71%,当然这不是没有代价的——zset引以为豪的快速遍历修改和索引机制都被压缩列表无情没收,平均耗时增加了40多倍,在这样的开销下,redis的OPS仅仅在12K左右,和10万QPS可谓是天差地别——这还是命令执行,算上排队和网络开销将会更加惨不忍睹
- 相对来讲,List的处境就会好多了——因为这玩意儿本来也不怎么快,从双向链表到压缩列表,多出来的开销仅仅也就是主线程每次计算entries长度和按长度寻址的常数复杂度,所以针对List的结构,我们即便适当放宽它的转变阈值也未尝不可。
- Hash处于不多不少的中间地位,大家可能会有疑惑,哈希不是O(1)查找吗,为何变成顺序查找后复杂度反而不如O(logN)的下降的厉害?笔者认为主要原因在于hash的常数开销并不低,主要集中在哈希函数的计算上
到这里或许能解答我们前一节关于redis作者为何要两度改动压缩列表的困惑——压缩列表作为Redis很多重要结构的根基,其在Redis中作用很大,对于它的缺陷再怎么放大都不为过,这也是Redis被大家盛赞精打细磨的原因所在。

(From《Redis开发与运维》)
回到本文的Hash中,对比不同的set集合实现,内存占用又有天差地别,Hash和Set的底层有一部分是公有的,那就是HashTable,这是一种字典实现,是正统的散列表,其各自的小规模实现分别是intset和ziplist,从表8-8中可以窥见,ziplist节约的内存数量相当夸张足足达到了86%的数量,62M内存变成了8.6M,但相应的,时间复杂度也逐渐到达了不可接受的程度
在这其中,我们看到了另一个非常亮眼的结构,那就是intset,内存占用精致小巧,查找速度更是风驰电掣,这就是完美的结构吗?关于它的奥秘我们在下一节为大家揭秘。
3.3 短小精悍的intset
如果要选出最能代表Redis设计精神的数据结构,intset一定是有力候选人之一(另外几个候选人我认为是ziplist、skipList),具体的原因就在它的速度和空间占用中,它的速度在百万量级完全超过了号称O(1)的hashtable,占用空间更加令其自愧不如,我们分两方面介绍它的优越性
typedef struct intset{
//编码方式
uint32_t encoding;
//集合元素数量
uint32_t length;
//保存元素的数组
uint8_t contents[];
} intset
时间上:
- intset对插入元素每次都排序,查找的代价是O(logN)
空间上:
- intset采用独特的编码方式,分为16位、32位和64位整数,并且支持升级
- intset会采用对象池来复用整型对象,这个池容纳的元素为[0,9999],但这严格来说是Redis自身提供的机制
针对这三点特性,我们分别地娓娓道来
3.3.1 排序的intset
intset对每个加入的元素都采用排序的策略:
redis > sadd set:tjd 1 4 2 8 5 7
(integer) 6 //乱序写入6个数字
redis > object encoding set:tjd//看一下用的什么编码
"intset"
redis > smembers set:tjd//输出全部元素
"1" "2" "4" "5" "7" "8"这样的好处是显而易见的,也是符合redis设计理念的——查询原本是O(N)的,每次插入操作的主动分担到O(N),使得高频的查询操作可以减少到O(N)。查询操作是相对更高频的,也更加不容易阻塞主线程,这对intset的整体表现提升很大,但转变阈值其实一定程度上限制了它的发挥,我们在实际中可以适当调大intset的set-maxintset-entries,笔者认为转变为哈希的查找优势要在万级别的数据上才会比较明显。
完美的化身intset并非毫无弱点,它的死穴像他的优点那么明显:对于频繁的插入操作,intset显得非常的力不从心,这个弱点会随着数据规模以及插入操作的频繁程度越来越影响intset的效率
3.3.2 intset的编码与升级
虽然contents是采用的INT8编码,但并不存储INT8元素,INT8最多只支持-128~127——这太容易升级了!下图展示了一个只有1314和520两个元素的intset是如何存储元素的

要问为什么有三种INT类型编码,那当然是节省空间了,如果我们能把所有元素都控制在16位整数的范围内,其空间占用便能达到最理想状态,但它又不至于像压缩列表这么笨拙——每一个都单独编码,空间是省了,O(logN)的二分查找开销也没办法实现了。
当一个名叫32767的整数加入集合时,它打破了整数集合原有的宁静——整数集合会开始升级,具体的会改用32位整数编码时,升级操作开始了

(From 小林coding-Redis数据结构-整数集合)
看起来比较复杂,我们只需要记住整数集合内部只会按照占用空间最多的元素统一编码,并且升级时会多分配【新编码插入后长度-旧编码插入前长度】的空间即可
可以升级,那可以降级吗?不能的话,为什么不能?
不能降级,但是在问为什么之前,我们可以想一下如何实现降级,最重要的当然是监控intset中最大的值,恰好我们的set是排序列表,我们甚至不需要维护一个新字段,只需要在表尾部查找一个元素就行了
监控的实现非常简单,重点就放在了迁移上,迁移也比较简单,找一块新内存,这块内存只需要是原来的一半大小,再原来的元素重新编码放入其中即可,这实现起来也没什么难度
既然实现起来没有难度,为什么不这么做呢?难道是省下来的一半空间不香吗?
当然不是,笔者认为,与浪费资源相反,这也是redis精心设计的一种:
当32位整数第一次加入集合时,集合就产生了一种假定——这不会是32位整数最后一次造访,我们在许多地方见过类似的假定:经受住了15次minorGC的对象一定会长久存活下去、哈希表的红黑树直到6个节点时才会发生退化。
- 如果我们不采用这种假定,那么固然我们这次降级可以获取很多空间上的收益,但下次32位整数造访集合时,redis会继续进行升级操作,一来一回对redis主线程来说是非常吃亏的
- 我们前面提到,intset的弱点在于频繁插入,如果某个场景需要对其频繁的删除插入,这些元素又恰好会使得集合升级降级,那么对intset的开销以及主线程来说,造成的影响是灾难性的
基于以上两点,redis会选择接受整数集合不降级的方案,固然redis对于内存是极为贪心的,但它更知道有它更值得守护的东西——主线程(哈哈哈哈)。
3.3.3 共享对象池
Redis内部维护了[0,9999]的整数对象池,因为整数也是以对象形式存在的,而每个对象最少的开销就是16个byte,作为最常用的数据类型之一,制作一个对象池很有必要,先来看一下是否使用对象池对空间占用的影响
| 操作 | 是否共享对象 | key大小 | value大小 | used_mem | used_memory_rss |
|---|---|---|---|---|---|
| 插入200w | 是 | 20字节 | [0-9999]整数 | 199.91MB | 205.28MB |
| 插入200w | 否 | 20字节 | [0-9999]整数 | 138.87MB | 143.28MB |
空间占用的开销降低了30%以上,我们来通过引用计数的方式来查看其是如何工作的,redis的对象结构如下图所示

由于单线程的缘故,redis内部是用引用计数法来实现对象回收的,这也可以帮助我们观察对象池的工作方式
redis>set TJD 99
OK
redis>set HNU 99
OK
redis>object refcount TJD
(integer) 3现在的情况如下图所示

注意,对象池在设置了maxmemory并且启动LRU淘汰策略时,将不会启用共享对象池
redis>config set maxmemory-policy volatile-lru //设置LRU缓存淘汰策略
OK
redis>config set maxmemory 1GB //设置最大可用内存
OK
redis>set BAT 99
OK
redis>object refcount BAT
(integer) 1 //可以发现已经无法启用共享池从上面代码可以发现已经无法启用对象池
redis>config set maxmemory-policy volatile-ttl //设置非LRU缓存淘汰策略
OK
redis>set AUV 99
OK
redis>object refcount AUV
(integer) 4 //对象池被再次启用为何开启maxmemory和LRU后无法使用对象池了?
redis的LRU实现是:随机抽样5个对象,淘汰其中时间戳最远的对象。实现这样策略,是因为实现一个纯正的LRU双向链表对于拥有这么多对象的redis是非常奢侈的,而事实证明这是一个效果非常接近经典实现的LRU,但是也给对象池带来了问题:共用的对象,导致其无法判断到底是被哪个引用访问而导致更新时间戳,从而剔除那个对象了
至于为什么要同时设置maxmemory,是因为只有超过maxmemory才会启动淘汰策略
maxmemory+LFU策略会禁用对象池吗?
原理相同,也会禁用,LFU同样需要在对象头中记录时间戳,只是多维护了一个8位的log_count,优先淘汰更少使用的,同样使用次数中淘汰最久未使用的
为何只有整型的对象池?Jvm中还有字符串常量池啊?
整数类型的复用概率是最大的,不仅如此,字符串相等性的开销令人无法接受,字符串的开销是O(N),而经过哈希映射的整数类型的开销是O(1)
3.4 探究hashtable的实现——渐进式rehash揭秘
哈希表是我们非常亲近的结构,它能实现平均上O(1)的复杂度查找,Redis中也同样有这种神奇的结构,在那之前,我们先来回顾一下java中的哈希实现
- 找到一个最小且不小于给定初始容量的2次幂来作为初始化哈希桶长度,如果不给定,初始化为16
- 在put元素时,对给定的元素计算Hash值,得到一个32位的有符号整型,对桶长度取模后,得到其对应的哈希桶,安置此元素
- 在扩容时,两倍扩容,这样可以不用重新计算旧元素的哈希桶
- 在冲突时,采用链地址法,桶大于64个且链表大于8时,转变为红黑树
Redis与以上的特点或多或少有不同我们从最简单的实现看起
typedef struct dictht{
//哈希表数组
dicEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,快速计算桶位置,用于与hash值进行"&"操作
//等于size-1
unsigned long sizemask;
//该哈希表已有的节点数量
unsigned long used;
} dictht下图展示了dictht的基本结构

dictEntry中保存的是键值对
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_t u64;
int64_t s64;
} v
//指向下一个哈希节点,形成链表
struct dictEntry *next;
} dictEntryRedis采用MurmurHash2的算法来计算哈希值,我们已经可以看到这已经出具一个哈希表的雏形了,但最终实现仍然不是我们看到的这样,我们知道,hash表的查找开销很小,但是容量到达阈值时的rehash非常消耗性能,redis采用了一种渐进式hash的方法来避免rehash对主线程的拖累
typedef struct dict{
//类型特定函数集合指针
dictType *type;
//私有数据
void *privatedata;
//哈希表,有0和1两张hash表
dictht ht[2];
//rehash索引
//当rehash未在进行时,值为-1
int rehashidx;
} dict
为何dictht结构有两份呢?渐进式rehash又是什么呢?
当我们尝试扩容hash时,会把ht[1]作为新的表,但不会立刻把旧表的元素迁移到ht[1],每当旧表的元素被访问时,如果主线程发现此表正在执行rehash(rehashidx不为-1):
- 计算出桶位置后,先在ht[0]查看是否存在此元素,如果不存在,去ht[1]上寻找此元素
- 如果ht[0]上存在此元素,那么先将其迁移到ht[1]上后,再将查询到的值返回给调用者,给rehashidx+1
- 直到ht[0]的used变量为0,说明此时已经全部迁移完毕,交换ht[0]和ht[1],并把rehashidx置为-1
这是典型的分治思想,避免了集中式的rehash对主线程的负担,而是把这种开销分摊到了每一次的查找、删除、和更新的操作上。
让我们最后来回顾一下哈希表的数据结构

3.5 Hash In Action
存储简单的用户字段以提升内聚性和减少空间占用
一般而言,假设我们有如下的用户实体
public class User{
int id;
int age;
String name;
String city;
}如果我们要存在Redis中,一半会有如下几种方式
原生字符串
set user:1:name TJD set user:1:age 24 set user:1:city changsha优点:简单直观,速度飞快,对键的操作灵活
缺点:缺乏内聚性,空间占用极大
序列化JSON
set user:1 serialize(userInfo)优点:简化编程,序列化合理的情况下能节省内存
缺点:序列化和反序列话是有开销的,并且不支持对属性进行单独操作
Hash存储
hmset user:1 name TJD age 24 city changsha优点:简单直观,内存占用也不高
缺点:ziplist和hashtable的切换不好控制,hashtable的开销会使得空间占用的优势消失
从如下图中,我们可以很方便的理解,方法1和方法3的开销差距,尤其是当小规模元素在采用ziplist编码时,会有更大的优势最多可以节省接近90%的空间,但我们需要注意控制ziplist的转变阈值,因为当其转为hashtable编码时,其产生的优势也就荡然无存了————redis的键空间本身就是一个hash表,对其中再进行hashMap分组当然只会增加冗余的实例对象结构,因此hash的真正优势实际上在于其压缩列表的空间节省能力上。

(From 《Redis开发与运维》——Chap.8 理解内存)
3.6 Set In Action
Set的应用比较狭窄,一般来讲用作user:tags比较多,笔者曾经拿它实现过user:like集合,但并非最佳实践,比较好的实践详见笔者的第一篇文章
//给用户添加标签
sadd user:1:tags tag1 tag2 tag3
sadd user:2:tags tag2 tag3 tag5
sadd user:3:tags tag1 tag3 tag4//给标签添加用户
sadd tags1:user 1 3
sadd tags2:user 1 4 5
sadd tags3:user 2 3 4我们还可以通过Redis提供的集合运算找到哪些是用户们喜爱最多的标签
redis> sinter user:1:tags user:2:tags总得来说,set的用处有以下方面
- sadd→tagging(标签)
- spop/srandmember→Random Item(抽奖)
- sadd+sinter→Social Graph(用户画像)
3.7 总结
无论是渐进式编码、渐进式哈希、渐进式升级的整数集合,我们都可以发现,渐进是redis中重要的概念,无论某个数据结构它平时的表现如何优良,如果它某些时候会突发恶疾,那么它一定会被redis改造甚至废弃,这样的设计理念其实就是redis的精髓所在——单线程模式给予了它足够简单的并发模型,降低了很大的设计难度(比如我们在java中被废弃的引用计数法,在redis中焕发着非常强的生命力),它又用设计上的力求完美为单线程保驾护航,所以单线程,实际是一种看似简单实则精巧的构想,理解了这个设计理念,我们就离redis的真谛更近了一步。