像医生一样的大规模AI模型
目录
- 华佗:BenTsao
-
- 相关工作
- 华佗模型
- 实验
- HuatuoGPT
-
- 动机
- 解决方案
-
- 混合数据的SFT
- 基于AI反馈的RL
- 医学中的LLM
- 指令微调
华佗:BenTsao
大型语言模型(LLM),如LLaMA模型,已经证明了它们在各种通用领域自然语言处理(NLP)任务中的有效性。尽管如此,LLM在生物医学领域的任务中还没有得到最佳的执行,因为需要医学专业知识。为了应对这一挑战,作者提出华驼,一个基于LLaMA的模型,该模型已经用QA实例进行了监督和微调。实验结果表明,华佗具有更可靠的医学知识。
来自:HuaTuo (华驼): Tuning LLaMA Model with Chinese Medical Knowledge
以ChatGPT为代表的instruction-following大型语言模型(LLM),由于其在理解指令和生成类人语言方面的卓越表现,引起了人们的极大兴趣。与较小的模型相比,LLM在各种自然语言处理(NLP)任务中表现出强大的泛化能力,并在解决unseen或其他复杂任务方面表现出独特的能力。尽管ChatGPT处于非开源状态,但开源社区已经提供了几种替代方案,如LLaMa(LLaMA: Open and Efficient Foundation Language Models),其训练成本相对较低。
然而,尽管LLM有许多优点,但它们并不是专门为医疗领域而设计的。在涉及这些专业领域时,他们的领域知识往往不足,而准确和特定领域的专家知识至关重要。这会导致次优的诊断准确性,药物推荐,医疗建议,并危及到患者。很少有人努力解决这个问题,现有的方法主要集中在向LLM提供从对话中检索到的医疗信息,而在对话中,人为错误可能会更频繁地发生。此外,LLM通常接受英语训练,这限制了他们在与英语显著不同的语言中(如汉语)的理解能力,导致在汉语环境中的直接应用不理想。
因此,华驼是为生物医学领域量身定制的LLM,专注于中文。通过基于CMeKG的医学知识生成不同的指令数据,作者强调确保模型在响应中事实的正确性,这在生物医学领域至关重要。通过这个过程,收集了8000多个指令数据,用于监督微调。模型建立在开源LLaMa-7B的基础上,集成了来自中国医学知识图谱(CMeKG)的结构化和非结构化医学知识,并使用基于知识的指令数据进行微调。
相关工作
大型语言模型:LLM的最新进展已经证明了它们优于前一代范式,如预训练和微调。模型规模的显著增加导致LLM发生了质的变化。其中包括针对零样本任务的上下文学习,以及增强模型在复杂任务中的性能的思想链。OpenAI对ChatGPT和GPT-4的开发彻底改变了人类对LLM的认知。尽管这些模型表现出了显著的性能,但OpenAI尚未披露有关其训练策略或权重参数的细节。LLaMa是GPT的开源替代方案,参数大小从70亿到650亿不等。Taori等人在LLaMa的基础上通过指令调整训练了Alpaca。
虽然LLaMa的性能与GPT-3.5相当,但由于其训练数据主要局限于英语语料库,因此其在中文任务上的性能较差。为了解决涉及中文的具体应用,Du等人,Zeng等人提出了GLM,这是一个1300亿参数的自回归预训练模型,具有多个训练目标。ChatGLM进一步结合了代码训练,并通过监督微调与人类意图保持一致,为中文上下文提供了量身定制的解决方案。
医学领域的预训练模型:尽管大语言模型(LLM)在一般领域表现出显著的性能,但它们缺乏特定领域的知识,导致在生物医学等需要专业知识的领域表现不佳。生物医学领域的固有性质要求模型拥有相关查询的全面知识库,特别是当应用于患者寻求健康和医疗建议的情况时。为了使LLM适应生物医学领域,目前已经做出了一些努力。
现有的方法主要使用ChatGPT进行辅助,并使用其提炼或翻译的知识来训练较小的模型。Chatdoctor首次尝试通过使用通过ChatGPT合成的会话演示来微调LLaMa,从而使LLM适用于生物医学领域。DoctorGLM利用ChatGLM-6B作为基础模型,并通过ChatGPT获得的ChatDoctor数据集的中文翻译对其进行微调。此外,Chen等人在他们的LLM集合中开发了一个中文和医学增强语言模型。总之,这些工作说明了LLM在生物医学领域成功应用的潜力。
华佗模型
LLaMA是一个多语言基础模型的集合,参数从70亿到650亿不等,对研究界来说是开源的。在这里,作者采用了LLaMA-7B模型来进行更方便的训练。
医学知识种类繁多,通常包括:
- 像医学知识图谱这样的结构化医学知识
- 像医学指南这样的非结构化医学知识。
作者使用了中文医学知识图谱CMeKG,该图谱还提供了可检索到的有关疾病、药物、症状等医学知识。表1显示了CMeKG知识库中的几个知识案例。
- 表1:CMeKG知识案例
| 类型 | 中文知识 | 知识翻译到英语 |
|---|---|---|
| Disease(疾病) | {“class”: “百种常见病”, “中心词”: “肝 癌”, “药物治疗”: [“瑞格非尼”, “对乙型 或丙型肝炎有效的抗病毒药物”, “索拉 非尼”], “多发地区”: [“撒哈拉以南的非 洲”], “高危因素”: [“肥胖”, “HBV DNA过 高”, “慢性酗酒”, “男性”, “慢性乙型肝 炎感染”, “肝癌家族史”, “慢性丙型肝 炎肝硬化”, “核心启动子突变”, “肝硬 化”, “HCV重叠感染”, “老年性心瓣膜病”, “乙型肝炎e抗原”, “糖尿病”],“发病部位”: [“肝脏”], “辅助检查”: [“肝功能检查”], “病史”: [“长期慢性乙肝病史”]} | {“class”: “Common Diseases”, “Key Word”: “Liver Cancer”, “Drug Treatment”: [“Regorafenib”, “Antiviral drugs effective against hepatitis B or C”, “Sorafenib”], “High Prevalence Regions”: [“Sub-Saharan Africa”], “High Risk Factors”: [“Obesity”, “High HBV DNA levels”, “Chronic alcoholism”, “Male gender”, “Chronic hepatitis B infection”, “Family history of liver cancer”, “Cirrhosis due to chronic hepatitis C”, “Core promoter mutation”, “Liver cirrhosis”, “HCV co-infection”, “Senile valvular heart disease”, “Hepatitis B e antigen”, “Diabetes”], “Affected Area”: [“Liver”], “Auxiliary Examination”: [“Liver function test”], “Medical History”: [“Long-term history of chronic hepatitis B”]} |
| Drug(药物) | { “class”: “西药”, “中心词”: “二甲双胍”, “性状”: [“糖衣或薄膜衣片,除去包衣 后显白色”], “英文名称”: [“异福片”, “格 华止”], “分类”: [“双胍类”, “抗结核病 药”], “规格”: [“0.25g”], “OTC类型”: [“乙 类OTC”, “甲类OTC”], “适应证”: [“糖尿 病”, “肥胖”], “通用名”: [“异福片”], “成 份”: [“利福平及异烟肼”, “异烟肼”, “异 烟肼0.1克”, “异烟肼150毫克”, “本品为 复方制剂”, “利福平”, “利福平300毫克”, “利福平0.15克”, “盐酸二甲双胍”, “盐 酸”]} | { “Class”: “Western Medicine”, “Key Word”: “Metformin”, “Appearance”: [“Sugarcoated or film-coated tablets, white after removal of coating”], “English Names”: [“Yifupian”, “Gehuazhi”], “Classification”: [“Biguanide class”, “Anti-tuberculosis drug”], “Specifications”: [“0.25g”], “OTC Types”: [“OTC Class B”, “OTC Class A”], “Indications”: [“Diabetes”, “Obesity”], “Generic Name”: [“Yifupian”], “Ingredients”: [“Isoniazid and pyrazinamide”, “Pyrazinamide”, “0.1g pyrazinamide”, “150mg pyrazinamide”, “This product is a compound preparation”, “Isoniazid”, “300mg isoniazid”, “0.15g isoniazid”, “Metformin hydrochloride”, “Hydrochloride”]} |
| Symptom(症状) | { “中心词”: “毛发脱落”, “检查”: [“毛发 矿物质检查”], “相关疾病”: [“斑秃”, “慢 性疲劳综合症”], “相关症状”: [“毛发色 淡而呈棕色”, “毛发干燥易断”, “皮肤变 硬”], “所属科室”: [“内科”, “皮肤性病”, “放疗、化疗科”], “发病部位”: [“头部”]} | {“Key Word”: “Hair Loss”, “Examinations”: [“Hair mineral analysis”], “Related Diseases”: [“Alopecia areata”, “Chronic Fatigue Syndrome”], “Related Symptoms”: [“Hair color is light and brown”, “Hair is dry and brittle”, “Skin becomes hardened”], “Related Departments”: [“Internal Medicine”, “Dermatology and Venereology”, “Radiation and Chemotherapy”], “Affected Area”: [“Head”]} |
- 表2:带有指令的实例
| Instruction(指令) | Input(输入) | Output(输出) |
|---|---|---|
| Translate the following sentence into Chinese. | What are the possible reasons for liver cancer? | 肝癌可能的原因有什么? |
指令微调已被证明对大型语言模型的微调是有效的,这有助于模型在零样本场景下以足够的注释指令为代价取得令人满意的性能。作者基于上述医学知识生成了指令数据。如表2所示,指令微调包括对训练实例的监督微调和用自然语言描述任务的指令。然而,对于医学对话的大型语言模型,输入大多以问题的形式表示,说明都类似于“回答以下问题”。因此,作者丢弃了指令,只为华佗保留输入。生成的指令需要足够多样化,以完成看不见的任务,来自大语言模型的响应中的事实的正确性在生物医学领域更受关注。因此,作者首先从知识图中抽取知识实例,然后使用OpenAI API基于特定知识生成实例。最后,收集了8000多个指令数据,如表3,作为监督微调的训练实例。
- 表3:监督微调的训练实例
| Instance(实例) | Instance(翻译到英文) | |
|---|---|---|
| Question | 患者XXX因头部及眼后部疼痛并能听到连续不断的隆隆声来到医院,医生对其进行了检查后诊断为偏头痛。请问,该病有什么治疗方法? | Patient XXX came to the hospital due to pain in the head and behind the eyes, accompanied by continuous rumbling sounds. After an examination, the doctor diagnosed the patient with a migraine. What are the treatment options for this condition? |
| Answer | 治疗偏头痛的方法包括药物治疗和非药物治疗。药物治疗主要包括三大类:急性发作期治疗、预防性治疗和混合治疗。非药物治疗包括改变生活方式,如减少熬夜、避免过度劳累、避免饮酒、戒烟等;此外还包括针灸、按摩、脉冲放电治疗等。在治疗中应该综合评估患者的病情、临床表现、个人情况等因素,制定个性化的治疗方案。 | The methods for treating migraines include medication and non-pharmacological therapies. Medication therapy primarily consists of three categories: acute attack treatment, preventative treatment, and mixed treatment. Non-pharmacological therapies include lifestyle changes such as reducing staying up late, avoiding overwork, avoiding alcohol consumption, and quitting smoking; in addition, they also include treatments such as acupuncture, massage, and pulse discharge therapy. During treatment, a comprehensive assessment of the patient’s condition, clinical manifestations, personal circumstances, and other factors should be taken into account to develop a personalized treatment plan. |
实验
为了证明华佗的性能,作者与四个基线模型进行了比较分析:
- LLaMA(Touvron等人,2023)是华佗的基础模型。使用LLaMA-7B是因为它与其他基线相比相对公平,并且易于训练。
- Alpaca(Taori等人,2023)是LLaMA的一个指令编辑版本,拥有在通用域中生成的80000多个实例。
- ChatGLM(Zeng et al,2023)是一个专门为中文聊天场景设计的对话模型。作者将华佗的性能与ChatGLM-6B进行了比较。
对于医疗QA任务,需要安全性safety、可用性usability和流畅性smoothness。安全性决定了是否包括任何可能误导用户进入危险的内容,例如错误的药物建议。可用性反映了特定的医学专业知识。流畅性表示作为语言模型的基本能力。
在自然语言生成领域,各种评估指标被用来评估生成模型的有效性。在一般领域中广泛使用的指标包括Bleu和Rouge,它们将生成的响应与ground truth进行比较。此外,对于医学问答任务,作者引入了一个评估指标SUS。SUS度量包括三个维度:安全性、可用性和流畅性。
在这项研究中,作者构建了一个汉语对话场景的测试集,并将华佗模型与其他三个基线模型产生的回答进行了比较。为了评估模型的性能,招募了五名具有医学背景的注释者,他们使用安全性、可用性和平稳性(SUS)来评估模型。SUS等级范围从1(不可接受)到3(良好),其中2表示可接受。SUS的平均分数如表4所示。尽管LLaMA获得了最高的安全性分数,但其回答往往没有信息,并对问题进行了重新表述,导致可用性分数较低。另一方面,华佗模型在不影响安全性的情况下显著提高了知识的可用性。
- 表4:实验结果比较

作者称华佗计划主要致力于研究,并非旨在提供医疗建议。研究中使用的医学信息来源于开放获取的医学知识图谱。

- 图1:模型结果对比,BenTsao为华佗模型
HuatuoGPT
HuatuoGPT的核心是在监督微调阶段利用来自ChatGPT的提取数据和来自医生的真实世界数据。ChatGPT的反应通常是详细的、呈现良好的和信息丰富的,而它在许多方面不能像医生一样表现,例如在综合诊断方面。作者认为,来自医生的真实世界数据将与提取的数据互补,因为前者可以训练语言模型,使其表现得像医生。为了更好地利用两种数据的优势,作者训练了一个奖励模型,以使语言模型与两种数据带来的优点保持一致,并遵循RLAIF(从人工智能反馈中强化学习)。
来自:HuatuoGPT, towards Taming Language Model to Be a Doctor
ChatGPT在医学上已经足够吗?回答是“否”。根据最近的研究,已经观察到ChatGPT甚至GPT-4,在医学等垂直领域表现出相对较差的性能。造成这种现象的一个因素是注释者可能缺乏医学知识的熟练程度。因此,在这一领域存在着进一步探索和改进的重大机遇。
另一方面,在线医疗往往带来定制化和本地化的挑战。例如,中国医学与西方医学有着根本的不同,印度医学和许多其他医学也是如此。然而,ChatGPT作为一种通用的语言模型,缺乏定制能力。此外,将用户的医疗数据委托给私营公司会引起人们的担忧,这强调了私人部署以确保本地数据存储的必要性。开发一种完全开源且具有商业可行性的医疗ChatGPT将有利于个人健康。
LLM4Med的预期目的是医疗和健康建议、分诊、诊断、开药、解释医疗报告等。一般来说,任何医疗或健康信息都可以合并到在线聊天过程中,类似于使用ChatGPT。在线医疗咨询提供了许多优势,包括:
- 成本效益:以在线方式为多个用户服务的成本与为单个用户服务的成本不成线性比例。一旦对模型进行了训练,这种可扩展性就可以实现经济高效的扩展。
- 减少医院拥挤:最近的疫情凸显了医院人满为患的风险,因为许多人即使不需要立即就医也会寻求线下咨询。通过提供在线替代方案,可以缓解医院的压力,以减轻未来流行病的风险。
- 解决心理障碍:一些人可能因为恐惧或迷信而不寻求医疗帮助或治疗。在线聊天平台可以为这些人提供一个更舒适的环境来讨论他们的担忧。
- 医疗平等:中国的医疗保健不平等是一个重大问题。一线城市居民与小城市和农村地区居民在医疗条件方面的差异非常显著。
目前,ChatGPT在医疗领域存在下面问题:
- ChatGPT在医学领域表现不佳,尤其是在中文领域;
- ChatGPT因道德和安全问题拒绝诊断和开药;
- ChatGPT的表现不如医生,例如,它从不提问,即使患者的情况不完整,医生通常会询问更多细节。在这种情况下,ChatGPT会给出一个通用的响应,而不是专门的响应。
为了克服上述问题,HuatuoGPT的核心是在监督微调(SFT)阶段利用来自医生的真实世界数据和来自ChatGPT的提取数据;这两个数据都包括医疗指令数据和医疗会话数据。从ChatGPT提取的数据被用来训练语言模型,使其遵循医学指示并流利地说话。额外的真实世界医学数据不仅将医学知识注入语言模型,而且还训练语言模型,以执行医学诊断或开药,像医生一样行事,并提供准确的信息。
HuatuoGPT的特点如下:
- HuatuoGPT是第一个使用RLAIF来利用真实数据和提取数据(包括指令和会话数据)的优点的医学语言模型。
- 人类评估显示,HuatuoGPT优于现有的开源LLM和ChatGPT(GPT-3.5-turbo)。其性能与医生最相似。
动机
从纯粹的真实世界对话中训练语言模型是一种常见的做法。然而,这受到低质量数据的影响。例如,现实世界对话中的回答可能是无信息的、简短的和糟糕的。更重要的是,这些数据中的值并不一致,甚至相互矛盾。与ChatGPT相比,向纯人类学习通常会导致不满意的基于聊天的语言模型。
最近的工作倾向于从ChatGPT中提取语言模型,要么模仿单回合指令中的ChatGPT响应,要么在与人类交互聊天时学习ChatGPT反应。通过提取ChatGPT的输出,模型可以快速获得令人印象深刻的指令跟随能力和无缝对话技能。此外,以其多样性和快速生成为特点,ChatGPT提取的数据可以跨越各种医学对话,包括各种疾病、症状和治疗模式。这种广度和多样性大大提高了模型的预测性能和可推广性。
然而,从ChatGPT中提取可能不适用于医学LLM,因为ChatGPT反应和医生反应之间存在根本差距,如图1和表1所示。提取的数据的质量可能会波动,表现为生成的对话中的不正确或模棱两可的信息。

- 图1:医疗咨询对话中ChatGPT回复(左)和医生回复(右)的示例,其中,文本从中文翻译为英文。医生提出的问题用蓝色表示,医学诊断用下划线表示。注意,ChatGPT通常不会像医生一样在回答患者时提出问题或提供医学诊断。

- 表1:ChatGPT和医生在各个方面的行为差异。作者认为,向ChatGPT和Doctors学习是相辅相成的。
解决方案
考虑到这些挑战,作者建议将提取数据(来自ChatGPT)和真实世界数据(来自Doctors)的优势结合起来,如表2所示。目的是训练医学LLM,使其表现得像医生。例如,它不仅要提供详细、信息丰富、呈现良好的内容,而且要像医生一样进行准确和互动的诊断(通常提出澄清的问题)。为此,首先在监督微调阶段(SFT)混合提取的数据和真实世界的数据。然后,使用人工智能反馈的RL(RLAIF)来利用这两种数据的优势,同时减轻它们的弱点。

- 表2:流行的医学模型中数据源和训练方法的比较。
HuatuoGPT侧重于整合医生和ChatGPT的特征,通过两阶段训练策略提高医疗咨询中的反应质量:混合数据的SFT和人工智能反馈的RL。首先利用精心选择的混合数据,通过监督微调来训练模型,然后通过人工智能的反馈来加强所需响应的生成,如图2所示。

- 图2:HuatuoGPT框架。
混合数据的SFT
在第一阶段,采用了提取数据和真实世界数据的混合,利用这两种优势赋予模型类似医生和患者友好的特征。在每个数据类别中,收集了指令数据和会话数据,以使模型具有指令跟踪和交互式诊断的能力。
从ChatGPT提取指令:遵循self-instruct的工作构建了一组医疗指导数据,旨在使模型能够遵循用户的医疗指导。不同之处在于,采用了自上而下的方式来创造更自然、更全面的应对措施。作者设计了一个分类法来收集或手动创建基于角色和用例的种子指令。根据每个角色或用例,使用自我指导分别生成指令。这可以提供广泛的说明,同时为每个角色或用例保留足够的说明。最后,将所有的种子指令混合在一起,进行自我指导;这可能有助于生成更加多样化的指令。
根据之前的工作,使用self-instruct从ChatGPT生成指令,并使用手动构建的医学种子指令,提示如下:

与最初的self-instruct不同,作者生成了角色增强指令,它将用于生成具有以下提示的输出。
- 假设你是一名经验丰富的[MedicalRole],会对患者给予非常耐心且全面的回答,并且语气温柔亲切,非常受患者喜欢。如果患者没有提供给你足够的信息判断,你会反问他相关问题。而且在诊断最后,你还会给予他一些额外的建议。如果患者提问:
{Question}
那么,你会回答:
从医生获取真实世界指令:真实世界的指令数据来源于医生和患者之间的问答。医生的回答是专业知识,具有高度的相关性和简洁性。因此,通过提炼真实的医患QA对,进一步提高了single-turn指令数据的质量和可靠性。
在实验中,从网络上收集了真实世界的问答数据,并对一组用于训练的高质量问答对进行了采样。每一对都经过LLM的提炼。提示如下:

从ChatGPT获取对话:提取的对话由两个ChatGPT生成,每个ChatGPT使用精心设计的提示与一个角色(医生或患者)进行关联。首先,利用第三方医学诊断数据库作为生成合成对话数据的医学知识和专业知识的来源。基于患者的基本背景和医生的最终诊断,两个ChatGPT被要求逐一生成对话。在这些对话中,LLM产生的回答通常信息丰富、详细、呈现良好,并遵循一致的风格;格式和信息通常对患者友好。
作者展示了用于患者LLM和医生LLM的提示。患者LLM的提示为:
- 你是一名患者,下面是你的病情,你正在向HuatuoGPT智能医生咨询病情相关的问题,请记住这是一个多轮咨询过程,每次询问要精炼一些,第一次询问要尽可能简单点、内容少一点。
{medical_case}
当你认为整个问诊应该结束的时候请说:再见
医生LLM的提示为:
- 你是一名经验丰富的医生,会对患者给予非常耐心且全面的回答,说话方式像医生,并且语气温柔亲切,非常受患者喜欢,对患者的询问要回复的更详细更有帮助。如果患者没有提供足够的信息用以诊断,你要反问他相关问题来获取更多信息来做出诊断,做出诊断后你还会给予他一些额外详细的建议。注意,你只能接收患者的描述没法看到图片之类的材料或附件。
如果无法做出明确的诊断,请询问出患者更多的病情信息,最后给出的诊断结果可以是:
{doctor_diagnosis}
从医生获得真实世界对话:真实世界的对话是从真实的场景中收集的,医生的反应通常需要不同的能力,包括长期推理和提出问题来指导患者描述自己的症状。然而,这种数据有时过于简洁和口语化。为了解决这一问题,作者利用语言模型来增强和细化基于原始内容的数据,从而生成高质量的真实对话数据集。
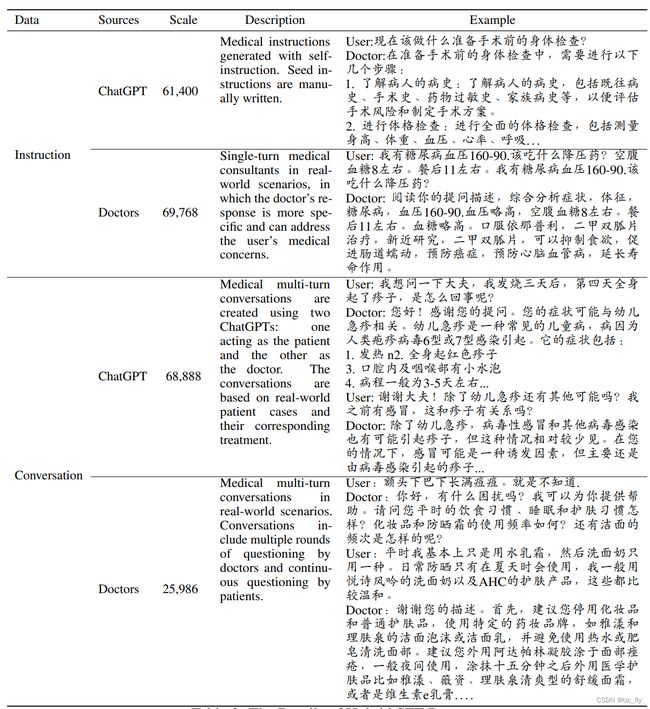
- 表3:混合SFT数据的详细信息。description分别为:
- 通过self-instruct生成的医疗指令。种子指令是手动编写的。
- 现实世界场景中的单轮医疗顾问,医生的反应更具体,可以解决用户的医疗问题。
- 医疗多回合对话是使用两个ChatGPT创建的:一个充当患者,另一个充当医生。这些对话基于真实世界中的患者案例及其相应的治疗。
- 现实世界场景中的医学多回合对话,对话包括医生的多轮提问和患者的连续提问。
基于AI反馈的RL
在监督微调(SFT)阶段,作者引入了一个多样化的数据集,旨在使HuatuoGPT能够模仿医生的询问和诊断策略,同时保持LLM反应的丰富、逻辑和连贯特征。为了进一步使模型的生成偏好与人类需求相一致,建议将强化学习与人工智能反馈相结合,以提高模型响应(response)的质量。此前,OpenAI引入了带有人类反馈的强化学习,以使LLM与人类偏好保持一致,但需要付出大量的时间和人力成本。作者设计了一个新的管道,以迫使模型在不偏离医生诊断的情况下生成信息和逻辑响应。
需要训练一个奖励模型,以符合医生和LLM的特点。使用真实的指令和对话作为训练数据,从微调的模型中采样多个响应。对于多回合对话,提供对话历史,以调整模型的响应生成。然后,这些response由LLM(如ChatGPT)进行评分,考虑到信息性、连贯性、对人类偏好的遵守以及基于给定真实医生诊断的事实准确性。评分LLM评估每个响应并分配一个分数。使用这些成对的响应数据来训练奖励模型,使用微调模型作为其骨干,以更好地泛化。
在RL过程中,通过对当前策略 π \pi π对给定query x x x的 k k k个不同response { y 1 , . . . , y k } \left\{y_1,...,y_k\right\} {y1,...,yk}进行采样。每个response y i y_i yi被送到奖励模型以得到奖励分数 r R M r_{RM} rRM。为了确保模型不会偏离初始状态 π 0 π_0 π0太远,作者添加了经验估计的KL惩罚项,最终的奖励函数如下: r = r R M − λ K L D K L ( π ∣ ∣ π 0 ) r=r_{RM}-\lambda_{KL}D_{KL}(\pi||\pi_{0}) r=rRM−λKLDKL(π∣∣π0)其中 λ K L λ_{KL} λKL是KL惩罚的超参数, D K L D_{KL} DKL是KL函数。 λ K L λ_{KL} λKL通常设置为0.05。输入查询被消除重复并从剩余的SFT混合数据中采样。这确保了输入的多样性,同时在单回合指令和多回合对话场景中都保留了模型的response偏好。
医学中的LLM
医学领域的语言模型一直是研究者关注的问题。早期的模型主要基于GPT-2系列模型,以继续在医学领域进行训练。BioMedLM是生物医学领域特定的大型语言模型,由2.7B GPT-2训练而成。它是在Pile数据集的PubMed Abstracts和PubMed Central部分上训练的,该数据集包含约50B个token,涵盖生物医学文献中的1600万篇摘要和500万篇全文文章。类似地,BioGPT是从PubMed官方网站收集的医学数据+GPT-2。对于下游任务,它使用软提示(soft prompt)进行微调训练。
最近,许多人努力试图使用指令微调(instruction fine-tuning)来增强大规模语言模型(>6B)上的医学咨询能力。MEDALACA是在Medical Meadow上训练的LLaMA模型,由两个主要类别组成,分为以指令微调格式重新格式化的已建立的医学NLP任务集合,以及各种互联网资源。ChatDoctor是一个接受过HealthCareMagic-100k训练的LLaMA。HealthCareMagic-100k数据集由来自在线医疗咨询网站的10万个真实世界的患者-医生对话组成。ChatDoctor具有自主知识检索能力,可以访问实时权威信息,并基于维基百科等数据库回答患者问题,以提高模型响应的准确性。Baize-healthcare是Baize的一个变体,它对医学数据(Quora对话框和医学对话框)进行了微调。与之相关的技术报告尚未公布,导致可用的细节有限,因为只公布了模型权重。Med-PaLM2基于PaLM2,并在MultiMedQA中进行了微调,用于专家级医疗问答。
对于中文,DoctorGLM是在基于ChatGLM的多个医学QA数据集上训练的中文医学LLM。它通过翻译利用来自ChatDoctor的训练数据,并将包含五个部门的QA和MedDialog聊天数据的中医对话作为训练数据的一部分。BenTsao是一个知识增强型中医LLM,在8K以上的指令下进行训练。该指令由ChatGPT API从CMeKG生成。MedicalGPT-zh是一个基于ChatGLM-6B LoRA的中文医学通用模型,具有16-bit指令微调。用于训练模型的数据集是从28个医疗部门的中医知识问答对和临床指南文本中获得的。
指令微调
参考:FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS
这是一个提高语言模型零样本学习能力的方法,在通过指令描述的一组数据集上,instruction tuning可以提高零样本表现。

- 比较instruction tuning,pretrain–finetune和prompting。对于预训练微调:通常需要许多特定任务的示例,并且每个任务都有一个专门的模型。对于提示:通过few-shot提示或提示工程提高性能。对于指令微调:模型通过自然语言指令学习执行许多任务。
对于预训练-微调范式,这是BERT时代引入的,缺点是每个任务都对应一个专用模型。提示范式由GPT-3推广,采用一个经过预训练的大模型,并使用提示在推理时执行下游任务。"提示"可以被视为一种尝试,用于弥合预训练目标和下游任务的差距。对于难以编写提示的任务,依然不能很好工作。
指令微调是在提示范式中插入了一个微调阶段,其目的是教模型执行基于指令的任务,然后要求模型执行一个unseen的任务,这是零样本学习,因为模型事先不知道任务,没有任何推理任务的例子。unseen任务可以是NLP中的任何任务,表述为指令。例如对影评进行情感分类,或者将句子翻译成丹麦语。
从而引出指令微调:对通过指令描述的任务集合的语言模型进行微调。方法从数据集开始,62个NLP数据集被分为12个任务群组。其中,每个任务群组中的数据集都具有相同的任务类型。

对于每个任务群组,描述该任务的10个自然语言指令模板是手动编写的。

上图是一个自然语言推理任务的例子,这里有一些关于俄罗斯人在太空的前提(premise)和假设(hypothesis)。任务是回答假设是否是由前提引起的。
表述任务的一种方法是给出前提再询问模型:基于以上段落,我们能得出俄罗斯人保持着太空停留时间最长的记录吗?
该任务也可以表述为:阅读下面的内容,并确定是否可以从该前提推断出该假设。
为了评估零样本表现,实验应该如下:如果要在NLI(自然语言推理)上评估,则对其他所有任务进行微调,并要求微调中没有见到NLI数据集。
训练数据中,每个实例都使用10个指令模板表示,训练时,为每个任务群组训练一个单独的ckpt,用于专用该任务。