技术博客神经网络分布式训练中参数优先传播方法
作者:倪昊
这篇论文来自 2019 年 SysML 会议中 Parallel & Distributed Learning 的部分。
数据并行训练(Data parallel training) 已经广泛地运用在在深度神经网络的分布式计算中,但是,分布式计算带来的性能提升经常受限于参数同步性能的瓶颈。作者等人提出了一种新的参数同步机制:Priority-based Parameter Propagation (P3),提高了模型的训练集群对网络带宽的利用率,加快了模型的训练速度。
我们首先来回顾一下神经网络的分布式训练。
深度神经网络(DNN)的分布式训练
神经网络的分布式训练通常有两种策略。一种是模型并行,指的是分布式系统中的不同机器分别负责在单个网络的不同部分计算,即把模型的不同层(layer)放到不同的工作节点上,常用与模型过大的情况,它的计算效率不高。另一种是数据并行,不同的机器有着整个模型的完全拷贝,每个机器只获得整个数据的不同部分,即把训练数据分成许多块,分给不同的 worker 节点,各个节点单独进行计算,但是共享一个模型,计算的结果通过某些方法结合起来。当然,这两种策略并不冲突,完全可以混合使用。
数据并行常用的架构是参数服务器(Parameter Server),即 PS 架构。
数据并行有两种不同的并行模式:同步训练和异步训练。同步训练是指所有 worker 节点的梯度都计算完成,统一进行梯度更新。而异步训练是指 worker 节点计算是独立地从 PS 节点获取模型参数,独立计算梯度并更新。采用同步随机梯度下降算法(SGD)算法的数据并行训练是一种非常流行的方法。
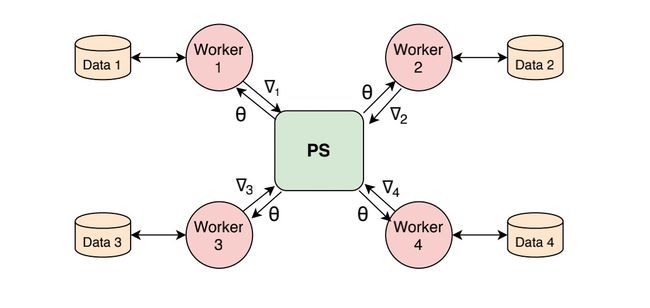
每个节点的工作大致可以分成三步:
- 节点从 PS 节点获取最新的模型参数,对各自负责的训练数据进行前向传播。
- 各个节点独立地对不同部分的训练数据进行反向传播,得到每个模型参数的梯度。
- 对各个 worker 节点的梯度计算结果进行同步,利用更新模型的参数
然后不断的循环迭代。
节点的每一次迭代都需要通过网络进行海量参数的同步,这对网络带宽提出了非常高的要求。解决这个问题的一个方法是增加网络的带宽,但这样做意味着极高的成本,同时随着模型体量的增大,成本也无法估量。因此,我们应该寻求在有限带宽下的解决方案。
近年来一种流行的方案是梯度压缩,但是这种方案的缺点在于丢失了一部分信息,可能会影响到模型的准确度。
还有一种方法,就是提高网络带宽的利用率。在训练的过程中,如果我们在每次迭代完成后才去同步梯度,就会导致网络流量爆炸性地增高,而在 worker 节点计算的过程中,网络却基本处于空闲状态。因此,我们可以将已经计算出来的梯度在 worker 节点计算其他层梯度的时候发给 PS 节点,即让 worker 节点与 PS 节点之间的通信和 worker 节点的反向传播同时进行,这样,网络带宽就可以得到更有效的利用。一些深度学习框架已经实现了这一点,比如 TensorFlow、MXNet 和 Caffe2。
局限性与优化
作者等人在工作中发现了以上方案还存在一定的局限性,通过优化,模型对网络带宽的利用率和计算速度可以进一步提高。
反向传播中参数传递的优先级
在神经网络模型的训练中,我们通常是:反向传播——用反向传播所得的参数进行前向传播,更细致一点,从最后一层开始进行反向传播的计算,再从第一层开始前向传播,如下图所示。
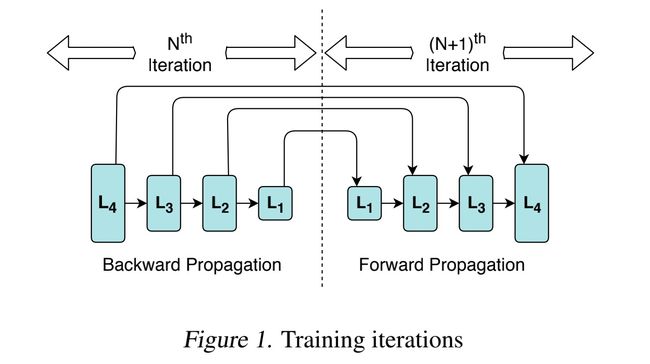
在第 N 次迭代中,我们从输出层开始根据 Loss 计算出梯度并更新 L4 层的参数,然后递归地求出输入层即 L1 层的梯度同时更新整个模型的参数,然后我们从输入层开始,进行 N+1 次的迭代,利用更新后模型的参数一层一层地计算,直到获得输出层的结果,然后进行再进行反向传播。
我们可以观察到一点,在迭代的过程中,最先计算出来的参数(L4层的参数)总是最后被使用,而反向传播最后计算出来的参数却最先被前向传播所使用。我们发现在神经网络的计算过程中,各个层的参数从获得到使用中间的间隔是不同的,层数靠近输出层,这一间隔也越大。在以往的分布式训练中,参数往往在某一层的反向传播结束时就开始同步,这就有可能导致 L2 层的参数还没有同步完,但是 L1 层已经反向传播结束,不得不等待 L2 层完成同步,L1 层完成参数同步然后再接受 PS 节点的参数更新,才能开始进行 L1 层的前向传播。这样,就会导致前向传播和反向传播之间的间隔过大。
所以,我们认为,在参数的同步中,层数低的层相比层数高的层,应该具有更高的优先级。

上图中(a)代表以往的同步机制,我们对其进行改进,优先同步较低的层的梯度,如(b)所示,当 L1 层的梯度计算完成,但是更高层的参数还没有完成同步时,优先进行 L1 层的参数同步,这样就缩短了反向传播和正向传播之间的间隔,但是并没有增加网络的负载。
参数同步中的粒度选取
参数同步所需的通信时间主要由三部分组成:
- 梯度从 worker 节点传输到 PS 节点的时间
- PS 节点利用梯度更新模型参数所需的时间
- PS 节点发送更新完的参数到各个 worker 节点
就如之前描述的一样,以往我们以层为粒度去进行参数同步,如图(a)所示,通过实现数据的传输和计算并行执行来尽可能地利用空闲的网络带宽,缩短通信所需要的时间。
但是在模型中,如果有一层的参数非常多,比如图(a)中的 L2 层,它完成参数同步所需的时间每一步都是 L1 和 L3 的三倍,我们会发现他会拖慢参数同步,或者说「阻塞」了参数的传递。比如在时间为 4 时,只有梯度的传输,却没有进行任何参数更新的计算。这是因为我们的参数同步是以层为单位,每一层中参数的更新必须要等到该层所有的节点的梯度都传输完成,但是我们并不需要等到接收完所有节点的梯度后再开始更新参数。

所以,我们可以采取更小的参数同步粒度,比如,将 L2 层的参数分成 3 份,单独地进行参数同步,如(b)所示。通过采取更小的粒度,我们可以尽可能地提升带宽的利用率,直观来讲就是增大图中不同层之间的重合度。
总结
以上两点就是 P3 采取的优化方式,作者在 MXNet 的基础上实现了这一机制,有兴趣的同学可以访问 GitHub 阅读相关源码。根据作者的测试,使用 P3,ResNet-50、Sockeye、VGG-19 等模型的训练效率分别提升了25%、38%、66%。这种同步机制的优点在于它与其他的优化方式并不冲突,且不会影响模型的精度,但是它对分布式模型训练效率的提升也有限,且并不是所有的模型都有明显的提升,特别是模型较小或者网络带宽十分受限时。