尚硅谷大数据技术Spark教程-笔记09【SparkStreaming(概念、入门、DStream入门、案例实操、总结)】
- 尚硅谷大数据技术-教程-学习路线-笔记汇总表【课程资料下载】
- 视频地址:尚硅谷大数据Spark教程从入门到精通_哔哩哔哩_bilibili
- 尚硅谷大数据技术Spark教程-笔记01【SparkCore(概述、快速上手、运行环境、运行架构)】
- 尚硅谷大数据技术Spark教程-笔记02【SparkCore(核心编程,RDD-核心属性-执行原理-基础编程-并行度与分区-转换算子)】
- 尚硅谷大数据技术Spark教程-笔记03【SparkCore(核心编程,RDD-转换算子-案例实操)】
- 尚硅谷大数据技术Spark教程-笔记04【SparkCore(核心编程,RDD-行动算子-序列化-依赖关系-持久化-分区器-文件读取与保存)】
- 尚硅谷大数据技术Spark教程-笔记05【SparkCore(核心编程,累加器、广播变量)】
- 尚硅谷大数据技术Spark教程-笔记06【SparkCore(案例实操,电商网站)】
- 尚硅谷大数据技术Spark教程-笔记07【Spark内核&源码(环境准备、通信环境、应用程序执行、shuffle、内存管理)】
- 尚硅谷大数据技术Spark教程-笔记08【SparkSQL(介绍、特点、数据模型、核心编程、案例实操、总结)】
- 尚硅谷大数据技术Spark教程-笔记09【SparkStreaming(概念、入门、DStream入门、案例实操、总结)】
目录
03_尚硅谷大数据技术之SparkStreaming.pdf
P185【185.尚硅谷_SparkStreaming - 概念 - 介绍】09:25
第1章 SparkStreaming概述
P186【186.尚硅谷_SparkStreaming - 概念 - 原理 & 特点】10:24
第2章 Dstream入门
P187【187.尚硅谷_SparkStreaming - 入门 - WordCount - 实现】14:40
P188【188.尚硅谷_SparkStreaming - 入门 - WordCount - 解析】03:11
第3章 DStream创建
P189【189.尚硅谷_SparkStreaming - DStream创建 - Queue】02:39
P190【190.尚硅谷_SparkStreaming - DStream创建 - 自定义数据采集器】07:36
P191【191.尚硅谷_SparkStreaming - DStream创建 - Socket数据采集器源码解读】03:26
P192【192.尚硅谷_SparkStreaming - DStream创建 - Kafka数据源】10:51
第4章 DStream转换
P193【193.尚硅谷_SparkStreaming - DStream转换 - 状态操作】16:09
P194【194.尚硅谷_SparkStreaming - DStream转换 - 无状态操作 - transform】09:06
P195【195.尚硅谷_SparkStreaming - DStream转换 - 无状态操作 - join】03:59
P196【196.尚硅谷_SparkStreaming - DStream转换 - 有状态操作 - window】12:17
P197【197.尚硅谷_SparkStreaming - DStream转换 - 有状态操作 - window - 补充】08:39
第5章 DStream输出
P198【198.尚硅谷_SparkStreaming - DStream输出】04:43
第6章 优雅关闭
P199【199.尚硅谷_SparkStreaming - 优雅地关闭】15:45
P200【200.尚硅谷_SparkStreaming - 优雅地关闭 - 恢复数据】03:30
第7章 SparkStreaming案例实操
P201【201.尚硅谷_SparkStreaming - 案例实操 - 环境和数据准备】16:43
P202【202.尚硅谷_SparkStreaming - 案例实操 - 需求一 - 分析】10:20
P203【203.尚硅谷_SparkStreaming - 案例实操 - 需求一 - 功能实现 - 黑名单判断】19:28
P204【204.尚硅谷_SparkStreaming - 案例实操 - 需求一 - 功能实现 - 统计数据更新】16:26
P205【205.尚硅谷_SparkStreaming - 案例实操 - 需求一 - 功能实现 - 测试 & 简化 & 优化】19:30
P206【206.尚硅谷_SparkStreaming - 案例实操 - 需求二 - 功能实现】09:26
P207【207.尚硅谷_SparkStreaming - 案例实操 - 需求二 - 乱码问题】06:11
P208【208.尚硅谷_SparkStreaming - 案例实操 - 需求三 - 介绍 & 功能实现】15:51
P209【209.尚硅谷_SparkStreaming - 案例实操 - 需求三 - 效果演示】09:54
P210【210.尚硅谷_SparkStreaming - 总结 - 课件梳理】08:12
03_尚硅谷大数据技术之SparkStreaming.pdf
P185【185.尚硅谷_SparkStreaming - 概念 - 介绍】09:25

//数据处理的方式角度
流式(streaming)
数据处理批量(batch)数据处理
//数据处理延迟的长短
实时数据处理:毫秒级别
离线数据处理:小时or天 级别
Sparkstreaming:准实时(秒,分钟),微批次(时间)的数据处理框架。第1章 SparkStreaming概述
P186【186.尚硅谷_SparkStreaming - 概念 - 原理 & 特点】10:24
第1章 SparkStreaming概述
1.1 Spark Streaming 是什么
Spark Streaming 用于流式数据的处理。Spark Streaming 支持的数据输入源很多,例如:Kafka、 Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语,如:map、reduce、join、window 等进行运算,而结果也能保存在很多地方,如 HDFS,数据库等。

第2章 Dstream入门
P187【187.尚硅谷_SparkStreaming - 入门 - WordCount - 实现】14:40
第 2 章 Dstream 入门
2.1 WordCount 案例实操
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming01_WordCount {
def main(args: Array[String]): Unit = {
// TODO 创建环境对象
// StreamingContext创建时,需要传递两个参数
// 第一个参数表示环境配置
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
// 第二个参数表示批量处理的周期(采集周期)
val ssc = new StreamingContext(sparkConf, Seconds(3))
// TODO 逻辑处理
// 获取端口数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordToOne = words.map((_, 1))
val wordToCount: DStream[(String, Int)] = wordToOne.reduceByKey(_ + _)
wordToCount.print()
// TODO 关闭环境
// 由于SparkStreaming采集器是长期执行的任务,所以不能直接关闭。
// 如果main方法执行完毕,应用程序也会自动结束,所以不能让main执行完毕。
//ssc.stop()
// 1. 启动采集器
ssc.start()
// 2. 等待采集器的关闭
ssc.awaitTermination()
}
}P188【188.尚硅谷_SparkStreaming - 入门 - WordCount - 解析】03:11
2.2 WordCount解析
Discretized Stream 是 Spark Streaming 的基础抽象,代表持续性的数据流和经过各种 Spark 原语操作后的结果数据流。在内部实现上,DStream 是一系列连续的 RDD 来表示。每个 RDD 含有一段时间间隔内的数据。

第3章 DStream创建
P189【189.尚硅谷_SparkStreaming - DStream创建 - Queue】02:39
第 3 章 DStream 创建
3.1 RDD 队列
3.1.1 用法及说明
测试过程中,可以通过使用 ssc.queueStream(queueOfRDDs)来创建 DStream,每一个推送到这个队列中的 RDD,都会作为一个 DStream 处理。
3.1.2 案例实操
➢ 需求:循环创建几个 RDD,将 RDD 放入队列。通过 SparkStream 创建 Dstream,计算 WordCount。
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming02_Queue {
def main(args: Array[String]): Unit = {
// TODO 创建环境对象
// StreamingContext创建时,需要传递两个参数
// 第一个参数表示环境配置
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
// 第二个参数表示批量处理的周期(采集周期)
val ssc = new StreamingContext(sparkConf, Seconds(3))
val rddQueue = new mutable.Queue[RDD[Int]]()
val inputStream = ssc.queueStream(rddQueue, oneAtATime = false)
val mappedStream = inputStream.map((_, 1))
val reducedStream = mappedStream.reduceByKey(_ + _)
reducedStream.print()
ssc.start()
for (i <- 1 to 5) {
rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
}P190【190.尚硅谷_SparkStreaming - DStream创建 - 自定义数据采集器】07:36
3.2 自定义数据源
3.2.1 用法及说明
3.2.2 案例实操
需求:自定义数据源,实现监控某个端口号,获取该端口号内容。
package com.atguigu.bigdata.spark.streaming
import java.util.Random
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming03_DIY {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val messageDS: ReceiverInputDStream[String] = ssc.receiverStream(new MyReceiver())
messageDS.print()
ssc.start()
ssc.awaitTermination()
}
/*
自定义数据采集器
1.继承Receiver,定义泛型, 传递参数
2.重写方法
*/
class MyReceiver extends Receiver[String](StorageLevel.MEMORY_ONLY) {
private var flg = true
override def onStart(): Unit = {
new Thread(new Runnable {
override def run(): Unit = {
while (flg) {
val message = "采集的数据为:" + new Random().nextInt(10).toString
store(message)
Thread.sleep(500)
}
}
}).start()
}
override def onStop(): Unit = {
flg = false;
}
}
}P191【191.尚硅谷_SparkStreaming - DStream创建 - Socket数据采集器源码解读】03:26
3.2.2 案例实操
需求:自定义数据源,实现监控某个端口号,获取该端口号内容。

P192【192.尚硅谷_SparkStreaming - DStream创建 - Kafka数据源】10:51
3.3 Kafka 数据源(面试、开发重点)
3.3.1 版本选型
3.3.2 Kafka 0-8 Receiver 模式(当前版本不适用)
3.3.3 Kafka 0-8 Direct 模式(当前版本不适用)
3.3.4 Kafka 0-10 Direct 模式
package com.atguigu.bigdata.spark.streaming
import java.util.Random
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming04_Kafka {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
kafkaDataDS.map(_.value()).print()
ssc.start()
ssc.awaitTermination()
}
}第4章 DStream转换
P193【193.尚硅谷_SparkStreaming - DStream转换 - 状态操作】16:09
第 4 章 DStream 转换
DStream 上的操作与 RDD 的类似,分为 Transformations(转换)和 Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种 Window 相关的原语。
4.1 无状态转化操作
package com.atguigu.bigdata.spark.streaming
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming05_State {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
// 无状态数据操作,只对当前的采集周期内的数据进行处理
// 在某些场合下,需要保留数据统计结果(状态),实现数据的汇总
// 使用有状态操作时,需要设定检查点路径
val datas = ssc.socketTextStream("localhost", 9999)
val wordToOne = datas.map((_, 1))
//val wordToCount = wordToOne.reduceByKey(_+_)
// updateStateByKey:根据key对数据的状态进行更新
// 传递的参数中含有两个值
// 第一个值表示相同的key的value数据
// 第二个值表示缓存区相同key的value数据
val state = wordToOne.updateStateByKey(
(seq: Seq[Int], buff: Option[Int]) => {
val newCount = buff.getOrElse(0) + seq.sum
Option(newCount)
}
)
state.print()
ssc.start()
ssc.awaitTermination()
}
}P194【194.尚硅谷_SparkStreaming - DStream转换 - 无状态操作 - transform】09:06
4.1.1 Transform
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("localhost", 9999)
// transform方法可以将底层RDD获取到后进行操作
// 1. DStream功能不完善
// 2. 需要代码周期性地执行
// Code : Driver端
val newDS: DStream[String] = lines.transform(
rdd => {
// Code : Driver端,(周期性执行)
rdd.map(
str => {
// Code : Executor端
str
}
)
}
)
// Code : Driver端
val newDS1: DStream[String] = lines.map(
data => {
// Code : Executor端
data
}
)
ssc.start()
ssc.awaitTermination()
}
}P195【195.尚硅谷_SparkStreaming - DStream转换 - 无状态操作 - join】03:59
4.1.2 join
两个流之间的 join 需要两个流的批次大小一致,这样才能做到同时触发计算。计算过程就是对当前批次的两个流中各自的 RDD 进行 join,与两个 RDD 的 join 效果相同。
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Join {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val data9999 = ssc.socketTextStream("localhost", 9999)
val data8888 = ssc.socketTextStream("localhost", 8888)
val map9999: DStream[(String, Int)] = data9999.map((_, 9))
val map8888: DStream[(String, Int)] = data8888.map((_, 8))
// 所谓的DStream的Join操作,其实就是两个RDD的join
val joinDS: DStream[(String, (Int, Int))] = map9999.join(map8888)
joinDS.print()
ssc.start()
ssc.awaitTermination()
}
}P196【196.尚硅谷_SparkStreaming - DStream转换 - 有状态操作 - window】12:17
4.2.2 WindowOperations
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Window {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
// 窗口的范围应该是采集周期的整数倍
// 窗口可以滑动的,但是默认情况下,一个采集周期进行滑动
// 这样的话,可能会出现重复数据的计算,为了避免这种情况,可以改变滑动的幅度(步长)
val windowDS: DStream[(String, Int)] = wordToOne.window(Seconds(6), Seconds(6))
val wordToCount = windowDS.reduceByKey(_ + _)
wordToCount.print()
ssc.start()
ssc.awaitTermination()
}
}P197【197.尚硅谷_SparkStreaming - DStream转换 - 有状态操作 - window - 补充】08:39
4.2.2 WindowOperations
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming06_State_Window1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
// reduceByKeyAndWindow : 当窗口范围比较大,但是滑动幅度比较小,那么可以采用增加数据和删除数据的方式
// 无需重复计算,提升性能。
val windowDS: DStream[(String, Int)] =
wordToOne.reduceByKeyAndWindow(
(x: Int, y: Int) => {
x + y
},
(x: Int, y: Int) => {
x - y
},
Seconds(9), Seconds(3))
windowDS.print()
ssc.start()
ssc.awaitTermination()
}
}第5章 DStream输出
P198【198.尚硅谷_SparkStreaming - DStream输出】04:43
第 5 章 DStream输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库 或输出到屏幕上)。与 RDD 中的惰性求值类似,如果一个 DStream 及其派生出的 DStream 都没有被执行输出操作,那么这些 DStream 就都不会被求值。如果 StreamingContext 中没有设定输出操作,整个 context 就都不会启动。
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming07_Output {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
val windowDS: DStream[(String, Int)] =
wordToOne.reduceByKeyAndWindow(
(x: Int, y: Int) => {
x + y
},
(x: Int, y: Int) => {
x - y
},
Seconds(9), Seconds(3))
// SparkStreaming如何没有输出操作,那么会提示错误
//windowDS.print()
ssc.start()
ssc.awaitTermination()
}
}package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming07_Output1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
val windowDS: DStream[(String, Int)] =
wordToOne.reduceByKeyAndWindow(
(x: Int, y: Int) => {
x + y
},
(x: Int, y: Int) => {
x - y
},
Seconds(9), Seconds(3))
// foreachRDD不会出现时间戳
windowDS.foreachRDD(
rdd => {
}
)
ssc.start()
ssc.awaitTermination()
}
}第6章 优雅关闭
P199【199.尚硅谷_SparkStreaming - 优雅地关闭】15:45
第 6 章 优雅关闭
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}
object SparkStreaming08_Close {
def main(args: Array[String]): Unit = {
/*
线程的关闭:
val thread = new Thread()
thread.start()
thread.stop(); // 强制关闭
*/
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
wordToOne.print()
ssc.start()
// 如果想要关闭采集器,那么需要创建新的线程
// 而且需要在第三方程序中增加关闭状态
new Thread(
new Runnable {
override def run(): Unit = {
// 优雅地关闭
// 计算节点不在接收新的数据,而是将现有的数据处理完毕,然后关闭
// Mysql : Table(stopSpark) => Row => data
// Redis : Data(K-V)
// ZK : /stopSpark
// HDFS : /stopSpark
/*
while ( true ) {
if (true) {
// 获取SparkStreaming状态
val state: StreamingContextState = ssc.getState()
if ( state == StreamingContextState.ACTIVE ) {
ssc.stop(true, true)
}
}
Thread.sleep(5000)
}
*/
Thread.sleep(5000)
val state: StreamingContextState = ssc.getState()
if (state == StreamingContextState.ACTIVE) {
ssc.stop(true, true)
}
System.exit(0)
}
}
).start()
ssc.awaitTermination() // block 阻塞main线程
}
}P200【200.尚硅谷_SparkStreaming - 优雅地关闭 - 恢复数据】03:30
package com.atguigu.bigdata.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}
object SparkStreaming09_Resume {
def main(args: Array[String]): Unit = {
val ssc = StreamingContext.getActiveOrCreate("cp", () => {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_, 1))
wordToOne.print()
ssc
})
ssc.checkpoint("cp")
ssc.start()
ssc.awaitTermination() // block 阻塞main线程
}
}第7章 SparkStreaming案例实操
P201【201.尚硅谷_SparkStreaming - 案例实操 - 环境和数据准备】16:43
第 7 章 SparkStreaming 案例实操
7.1 环境准备
package com.atguigu.bigdata.spark.streaming
import java.util.{Properties, Random}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
object SparkStreaming10_MockData {
def main(args: Array[String]): Unit = {
// 生成模拟数据
// 格式 :timestamp area city userid adid
// 含义: 时间戳 区域 城市 用户 广告
// Application => Kafka => SparkStreaming => Analysis
val prop = new Properties()
// 添加配置
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "linux1:9092")
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](prop)
while (true) {
mockdata().foreach(
data => {
// 向Kafka中生成数据
val record = new ProducerRecord[String, String]("atguiguNew", data)
producer.send(record)
println(data)
}
)
Thread.sleep(2000)
}
}
def mockdata() = {
val list = ListBuffer[String]()
val areaList = ListBuffer[String]("华北", "华东", "华南")
val cityList = ListBuffer[String]("北京", "上海", "深圳")
for (i <- 1 to new Random().nextInt(50)) {
val area = areaList(new Random().nextInt(3))
val city = cityList(new Random().nextInt(3))
var userid = new Random().nextInt(6) + 1
var adid = new Random().nextInt(6) + 1
list.append(s"${System.currentTimeMillis()} ${area} ${city} ${userid} ${adid}")
}
list
}
}P202【202.尚硅谷_SparkStreaming - 案例实操 - 需求一 - 分析】10:20
7.3 需求一:广告黑名单
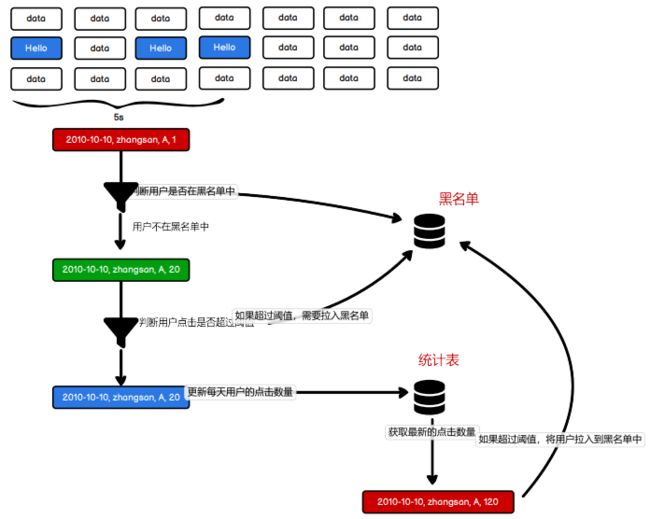
P203【203.尚硅谷_SparkStreaming - 案例实操 - 需求一 - 功能实现 - 黑名单判断】19:28
package com.atguigu.bigdata.spark.streaming
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming11_Req1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
kafkaDataDS.map(_.value()).print()
ssc.start()
ssc.awaitTermination()
}
}package com.atguigu.bigdata.spark.streaming
import java.sql.ResultSet
import java.text.SimpleDateFormat
import com.atguigu.bigdata.spark.util.JDBCUtil
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
object SparkStreaming11_Req1_BlackList {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0), datas(1), datas(2), datas(3), datas(4))
}
)
val ds = adClickData.transform(
rdd => {
// TODO 通过JDBC周期性获取黑名单数据
val blackList = ListBuffer[String]()
val conn = JDBCUtil.getConnection
val pstat = conn.prepareStatement("select userid from black_list")
val rs: ResultSet = pstat.executeQuery()
while (rs.next()) {
blackList.append(rs.getString(1))
}
rs.close()
pstat.close()
conn.close()
// TODO 判断点击用户是否在黑名单中
val filterRDD = rdd.filter(
data => {
!blackList.contains(data.user)
}
)
// TODO 如果用户不在黑名单中,那么进行统计数量(每个采集周期)
filterRDD.map(
data => {
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val day = sdf.format(new java.util.Date(data.ts.toLong))
val user = data.user
val ad = data.ad
((day, user, ad), 1) // (word, count)
}
).reduceByKey(_ + _)
}
)
ds.foreachRDD(
rdd => {
rdd.foreach {
case ((day, user, ad), count) => {
println(s"${day} ${user} ${ad} ${count}")
if (count >= 30) {
// TODO 如果统计数量超过点击阈值(30),那么将用户拉入到黑名单
val conn = JDBCUtil.getConnection
val pstat = conn.prepareStatement(
"""
|insert into black_list (userid) values (?)
|on DUPLICATE KEY
|UPDATE userid = ?
""".stripMargin)
pstat.setString(1, user)
pstat.setString(2, user)
pstat.executeUpdate()
pstat.close()
conn.close()
} else {
// TODO 如果没有超过阈值,那么需要将当天的广告点击数量进行更新。
val conn = JDBCUtil.getConnection
val pstat = conn.prepareStatement(
"""
| select
| *
| from user_ad_count
| where dt = ? and userid = ? and adid = ?
""".stripMargin)
pstat.setString(1, day)
pstat.setString(2, user)
pstat.setString(3, ad)
val rs = pstat.executeQuery()
// 查询统计表数据
if (rs.next()) {
// 如果存在数据,那么更新
val pstat1 = conn.prepareStatement(
"""
| update user_ad_count
| set count = count + ?
| where dt = ? and userid = ? and adid = ?
""".stripMargin)
pstat1.setInt(1, count)
pstat1.setString(2, day)
pstat1.setString(3, user)
pstat1.setString(4, ad)
pstat1.executeUpdate()
pstat1.close()
// TODO 判断更新后的点击数据是否超过阈值,如果超过,那么将用户拉入到黑名单。
val pstat2 = conn.prepareStatement(
"""
|select
| *
|from user_ad_count
|where dt = ? and userid = ? and adid = ? and count >= 30
""".stripMargin)
pstat2.setString(1, day)
pstat2.setString(2, user)
pstat2.setString(3, ad)
val rs2 = pstat2.executeQuery()
if (rs2.next()) {
val pstat3 = conn.prepareStatement(
"""
|insert into black_list (userid) values (?)
|on DUPLICATE KEY
|UPDATE userid = ?
""".stripMargin)
pstat3.setString(1, user)
pstat3.setString(2, user)
pstat3.executeUpdate()
pstat3.close()
}
rs2.close()
pstat2.close()
} else {
// 如果不存在数据,那么新增
val pstat1 = conn.prepareStatement(
"""
| insert into user_ad_count ( dt, userid, adid, count ) values ( ?, ?, ?, ? )
""".stripMargin)
pstat1.setString(1, day)
pstat1.setString(2, user)
pstat1.setString(3, ad)
pstat1.setInt(4, count)
pstat1.executeUpdate()
pstat1.close()
}
rs.close()
pstat.close()
conn.close()
}
}
}
}
)
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData(ts: String, area: String, city: String, user: String, ad: String)
}P204【204.尚硅谷_SparkStreaming - 案例实操 - 需求一 - 功能实现 - 统计数据更新】16:26
SparkStreaming11_Req1_BlackList
P205【205.尚硅谷_SparkStreaming - 案例实操 - 需求一 - 功能实现 - 测试 & 简化 & 优化】19:30
package com.atguigu.bigdata.spark.streaming
import java.sql.ResultSet
import java.text.SimpleDateFormat
import com.atguigu.bigdata.spark.util.JDBCUtil
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
object SparkStreaming11_Req1_BlackList1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0), datas(1), datas(2), datas(3), datas(4))
}
)
val ds = adClickData.transform(
rdd => {
// TODO 通过JDBC周期性获取黑名单数据
val blackList = ListBuffer[String]()
val conn = JDBCUtil.getConnection
val pstat = conn.prepareStatement("select userid from black_list")
val rs: ResultSet = pstat.executeQuery()
while (rs.next()) {
blackList.append(rs.getString(1))
}
rs.close()
pstat.close()
conn.close()
// TODO 判断点击用户是否在黑名单中
val filterRDD = rdd.filter(
data => {
!blackList.contains(data.user)
}
)
// TODO 如果用户不在黑名单中,那么进行统计数量(每个采集周期)
filterRDD.map(
data => {
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val day = sdf.format(new java.util.Date(data.ts.toLong))
val user = data.user
val ad = data.ad
((day, user, ad), 1) // (word, count)
}
).reduceByKey(_ + _)
}
)
ds.foreachRDD(
rdd => {
// rdd. foreach方法会每一条数据创建连接
// foreach方法是RDD的算子,算子之外的代码是在Driver端执行,算子内的代码是在Executor端执行
// 这样就会涉及闭包操作,Driver端的数据就需要传递到Executor端,需要将数据进行序列化
// 数据库的连接对象是不能序列化的。
// RDD提供了一个算子可以有效提升效率 : foreachPartition
// 可以一个分区创建一个连接对象,这样可以大幅度减少连接对象的数量,提升效率
rdd.foreachPartition(iter => {
val conn = JDBCUtil.getConnection
iter.foreach {
case ((day, user, ad), count) => {
}
}
conn.close()
}
)
rdd.foreach {
case ((day, user, ad), count) => {
println(s"${day} ${user} ${ad} ${count}")
if (count >= 30) {
// TODO 如果统计数量超过点击阈值(30),那么将用户拉入到黑名单
val conn = JDBCUtil.getConnection
val sql =
"""
|insert into black_list (userid) values (?)
|on DUPLICATE KEY
|UPDATE userid = ?
""".stripMargin
JDBCUtil.executeUpdate(conn, sql, Array(user, user))
conn.close()
} else {
// TODO 如果没有超过阈值,那么需要将当天的广告点击数量进行更新。
val conn = JDBCUtil.getConnection
val sql =
"""
| select
| *
| from user_ad_count
| where dt = ? and userid = ? and adid = ?
""".stripMargin
val flg = JDBCUtil.isExist(conn, sql, Array(day, user, ad))
// 查询统计表数据
if (flg) {
// 如果存在数据,那么更新
val sql1 =
"""
| update user_ad_count
| set count = count + ?
| where dt = ? and userid = ? and adid = ?
""".stripMargin
JDBCUtil.executeUpdate(conn, sql1, Array(count, day, user, ad))
// TODO 判断更新后的点击数据是否超过阈值,如果超过,那么将用户拉入到黑名单。
val sql2 =
"""
|select
| *
|from user_ad_count
|where dt = ? and userid = ? and adid = ? and count >= 30
""".stripMargin
val flg1 = JDBCUtil.isExist(conn, sql2, Array(day, user, ad))
if (flg1) {
val sql3 =
"""
|insert into black_list (userid) values (?)
|on DUPLICATE KEY
|UPDATE userid = ?
""".stripMargin
JDBCUtil.executeUpdate(conn, sql3, Array(user, user))
}
} else {
val sql4 =
"""
| insert into user_ad_count ( dt, userid, adid, count ) values ( ?, ?, ?, ? )
""".stripMargin
JDBCUtil.executeUpdate(conn, sql4, Array(day, user, ad, count))
}
conn.close()
}
}
}
}
)
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData(ts: String, area: String, city: String, user: String, ad: String)
}P206【206.尚硅谷_SparkStreaming - 案例实操 - 需求二 - 功能实现】09:26
7.4 需求二:广告点击量实时统计
package com.atguigu.bigdata.spark.streaming
import java.text.SimpleDateFormat
import com.atguigu.bigdata.spark.streaming.SparkStreaming11_Req1_BlackList.AdClickData
import com.atguigu.bigdata.spark.util.JDBCUtil
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming12_Req2 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0), datas(1), datas(2), datas(3), datas(4))
}
)
val reduceDS = adClickData.map(
data => {
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val day = sdf.format(new java.util.Date(data.ts.toLong))
val area = data.area
val city = data.city
val ad = data.ad
((day, area, city, ad), 1)
}
).reduceByKey(_ + _)
reduceDS.foreachRDD(
rdd => {
rdd.foreachPartition(
iter => {
val conn = JDBCUtil.getConnection
val pstat = conn.prepareStatement(
"""
| insert into area_city_ad_count ( dt, area, city, adid, count )
| values ( ?, ?, ?, ?, ? )
| on DUPLICATE KEY
| UPDATE count = count + ?
""".stripMargin)
iter.foreach {
case ((day, area, city, ad), sum) => {
pstat.setString(1, day)
pstat.setString(2, area)
pstat.setString(3, city)
pstat.setString(4, ad)
pstat.setInt(5, sum)
pstat.setInt(6, sum)
pstat.executeUpdate()
}
}
pstat.close()
conn.close()
}
)
}
)
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData(ts: String, area: String, city: String, user: String, ad: String)
}P207【207.尚硅谷_SparkStreaming - 案例实操 - 需求二 - 乱码问题】06:11
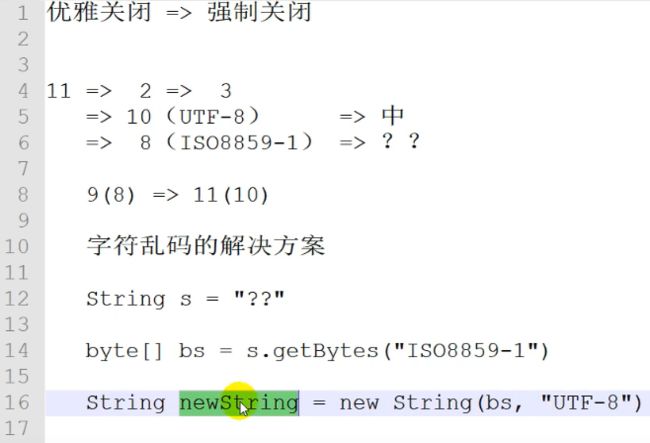
P208【208.尚硅谷_SparkStreaming - 案例实操 - 需求三 - 介绍 & 功能实现】15:51
7.5 需求三:最近一小时广告点击量

package com.atguigu.bigdata.spark.streaming
import java.text.SimpleDateFormat
import com.atguigu.bigdata.spark.util.JDBCUtil
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming13_Req3 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0), datas(1), datas(2), datas(3), datas(4))
}
)
// 最近一分钟,每10秒计算一次
// 12:01 => 12:00
// 12:11 => 12:10
// 12:19 => 12:10
// 12:25 => 12:20
// 12:59 => 12:50
// 55 => 50, 49 => 40, 32 => 30
// 55 / 10 * 10 => 50
// 49 / 10 * 10 => 40
// 32 / 10 * 10 => 30
// 这里涉及窗口的计算
val reduceDS = adClickData.map(
data => {
val ts = data.ts.toLong
val newTS = ts / 10000 * 10000
(newTS, 1)
}
).reduceByKeyAndWindow((x: Int, y: Int) => {
x + y
}, Seconds(60), Seconds(10))
reduceDS.print()
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData(ts: String, area: String, city: String, user: String, ad: String)
}P209【209.尚硅谷_SparkStreaming - 案例实操 - 需求三 - 效果演示】09:54
package com.atguigu.bigdata.spark.streaming
import java.io.{File, FileWriter, PrintWriter}
import java.text.SimpleDateFormat
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
object SparkStreaming13_Req31 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0), datas(1), datas(2), datas(3), datas(4))
}
)
// 最近一分钟,每10秒计算一次
// 12:01 => 12:00
// 12:11 => 12:10
// 12:19 => 12:10
// 12:25 => 12:20
// 12:59 => 12:50
// 55 => 50, 49 => 40, 32 => 30
// 55 / 10 * 10 => 50
// 49 / 10 * 10 => 40
// 32 / 10 * 10 => 30
// 这里涉及窗口的计算
val reduceDS = adClickData.map(
data => {
val ts = data.ts.toLong
val newTS = ts / 10000 * 10000
(newTS, 1)
}
).reduceByKeyAndWindow((x: Int, y: Int) => {
x + y
}, Seconds(60), Seconds(10))
//reduceDS.print()
reduceDS.foreachRDD(
rdd => {
val list = ListBuffer[String]()
val datas: Array[(Long, Int)] = rdd.sortByKey(true).collect()
datas.foreach {
case (time, cnt) => {
val timeString = new SimpleDateFormat("mm:ss").format(new java.util.Date(time.toLong))
list.append(s"""{"xtime":"${timeString}", "yval":"${cnt}"}""")
}
}
// 输出文件
val out = new PrintWriter(new FileWriter(new File("D:\\mineworkspace\\idea\\classes\\atguigu-classes\\datas\\adclick\\adclick.json")))
out.println("[" + list.mkString(",") + "]")
out.flush()
out.close()
}
)
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData(ts: String, area: String, city: String, user: String, ad: String)
}P210【210.尚硅谷_SparkStreaming - 总结 - 课件梳理】08:12
03_尚硅谷大数据技术之SparkStreaming.pdf