zookeeper
zoomkeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。
本质:用于注册分布式服务,存储和管理的元数据,如果服务器状态发生改变会通知客户端
zookeeper=注册中心+通知机制+文件系统
zookeeper特点
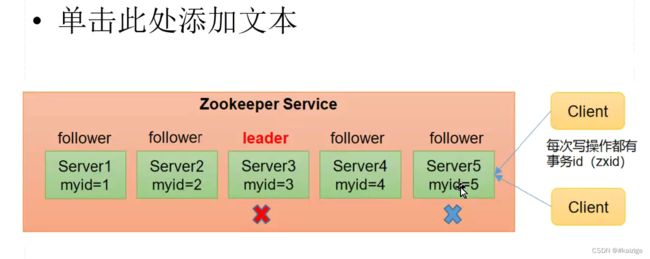
1)zookeeper是一个领导者(leader),多个跟随着(follower)组成的集群
2)zookeeper集群中只要有半数以上节点存货,zookeeper集群就能正常服务。zookeeper适合安装奇数台服务器
3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行,即先进先出。
5)数据更新原子性,一次数据更新要么成功,要么失败。
6)实时性,在一定时间范围内,Client能读到最新数据
zookeeper数据模型的结构与linux文件系统相似,整体上可以看作是一颗树,每棵树是一个znode,每个znode默认能存储1mb的数据,每个咋弄的都可以通过其路径唯一标识
zookeeper选举机制:
第一次选举:比较服务器节点大的myid,谁大谁会获取myid比它小的服务器节点的选票,当选举超过节点数量半数则该节点选举为leader,其他几点为follower,就算以后有其他myid更大的急待你加入到集群,也不会应该之前的选举结果。
非第一次选举:如果是非leader节点故障,代替的新节点继续当follower;如果leader节点故障,则需要重新选举leader,先比较每个节点的epoch(参加的选举次数),选最大的当leader
若epoch下个南通,则比较zxid(写操作的事务id),选取zxid最大的当leader
若zxid也相同,则比较sid(服务器id,等同于myid)选取sid最大的当leader
epoch每个leader的任期代号
事务id zxid写操作的偏移量
服务器myid(服务器唯一标识)大的胜出
配置服务
cp/usr/local/zookeeper3.5.7/conf/bin/zkServer.sh/etc/init.d/zookeeper
chkconfig --add zookeeper
中间件:沟通两个不同主键
A http:// HTTP:// B rpc:// C rpc://
web应用型中间件消息队列型,nginx haproxy lvs tomcat
消息队列型 redis kafka rabbitMQ rocketMQ
kafka是一个分布式基于发布/订阅模式的消息队列大数据领域的实时计算以及日记收集
大数据应用:hadoop,park/flink,kafka做消息对列,中间件连接
kafka系统架构
一台kafaka服务器就是一个broker,一个集群由多个broker组成,一个broker课容纳多个topic
topic一个队列,类似于数据库的表明或者es的inde
而可以保证每个patition的数据不变但是patition顺序可能改变
抢红包,商品秒杀,需将partition数目设置为1.少于集群数量
cousmer可以从broke中pull拉去数据。消费者可以消费多个topic中的数据
offset偏移量,唯一标识一条消息
zookeepe作用1,r生产者推送数据到kafaka集群,需要zookeeper找到kafaka集群节点位置,2,找消费者消费的那一条数据
后台启动

replicas副本数 isr