ORC与Parquet压缩分析
ORC与Parquet压缩分析
@date:2023年6月14日
文章目录
- ORC与Parquet压缩分析
-
- 压测环境
-
- 数据schema
- 数据实验
- 压缩结果
- 文件使用建议
- 附录
-
- 编译hadoop-lzo
-
- 编译前提
- 编译程中出现的错误
- 结果文件
- file-compress.jar源码
-
- ReadWriterOrc类
- NativeParquet类
- FileUtil类
压测环境
- OS:CentOS 6.5
- JDK:1.8
- 内存:256G
- 磁盘:HDD
- CPU:Dual 8-core Intel® Xeon® CPU (32 Hyper-Threads) E5-2630 v3 @ 2.40GHz
通过Orc和Parquet原生方式进行数据写入,并采用以下算法进行压缩测试
- lzo
- lz4(lz4_raw)
- Zstandard
- snappy
数据schema
尽可能的保持parquet与ORC的schema一致。
parquet
MessageType schema = MessageTypeParser.parseMessageType("message schema {\n" +
" required INT64 long_value;\n" +
" required double double_value;\n" +
" required boolean boolean_value;\n" +
" required binary string_value (UTF8);\n" +
" required binary decimal_value (DECIMAL(32,18));\n" +
" required INT64 time_value;\n" +
" required INT64 time_instant_value;\n" +
" required INT64 date_value;\n" +
"}");
orc
TypeDescription readSchema = TypeDescription.createStruct()
.addField("long_value", TypeDescription.createLong())
.addField("double_value", TypeDescription.createDouble())
.addField("boolean_value", TypeDescription.createBoolean())
.addField("string_value", TypeDescription.createString())
.addField("decimal_value", TypeDescription.createDecimal().withScale(18))
.addField("time_value", TypeDescription.createTimestamp())
.addField("time_instant_value", TypeDescription.createTimestampInstant())
.addField("date_value", TypeDescription.createDate());
数据实验
将工程打包成uber JAR,通过java命令执行
⚠️对parquet使用lzo时需要额外的配置
在使用lzo的时候需要在系统上安装Lzo 2.x
# 查询是否有lzo安装包 [root@demo ~]# rpm -q lzo # yum方式安装 yum install lzo # rpm方式 下载lzo的rpm包 rpm -ivh lzo-2.06-8.el7.x86_64.rpm # 源码编译安装 # 1源码编译的依赖 yum -y install lzo-devel zlib-devel gcc autoconf automake libtool # 解压缩源码 tar -zxvf lzo-2.10.tar.gz -C ../source # 配置和安装 cd ~/source/lzo-2.10 ./configure --enable-shared --prefix /usr/local/lzo-2.1 make && sudo make install由于GPLNativeCodeLoader类在加载的时候默认lib的目录是
/native/Linux-amd64-64/lib,所以需要使用的lib copy进去。-rw-r--r-- 1 root root 112816 Jun 13 17:57 hadoop-lzo-0.4.20.jar -rw-r--r-- 1 root root 117686 Jun 13 17:17 libgplcompression.a -rw-r--r-- 1 root root 1157 Jun 13 17:17 libgplcompression.la -rwxr-xr-x 1 root root 75368 Jun 13 17:17 libgplcompression.so -rwxr-xr-x 1 root root 75368 Jun 13 17:17 libgplcompression.so.0 -rwxr-xr-x 1 root root 75368 Jun 13 17:17 libgplcompression.so.0.0.0 -rw-r--r-- 1 root root 1297096 Jun 13 17:17 libhadoop.a -rw-r--r-- 1 root root 1920190 Jun 13 17:17 libhadooppipes.a -rwxr-xr-x 1 root root 765897 Jun 13 17:17 libhadoop.so -rwxr-xr-x 1 root root 765897 Jun 13 17:17 libhadoop.so.1.0.0 -rw-r--r-- 1 root root 645484 Jun 13 17:17 libhadooputils.a -rw-r--r-- 1 root root 438964 Jun 13 17:17 libhdfs.a -rwxr-xr-x 1 root root 272883 Jun 13 17:17 libhdfs.so -rwxr-xr-x 1 root root 272883 Jun 13 17:17 libhdfs.so.0.0.0 -rw-r--r-- 1 root root 290550 Jun 13 17:17 liblzo2.a -rw-r--r-- 1 root root 929 Jun 13 17:17 liblzo2.la -rwxr-xr-x 1 root root 202477 Jun 13 17:17 liblzo2.so -rwxr-xr-x 1 root root 202477 Jun 13 17:17 liblzo2.so.2 -rwxr-xr-x 1 root root 202477 Jun 13 17:17 liblzo2.so.2.0.0 -rw-r--r-- 1 root root 246605 Jun 13 17:17 libsigar-amd64-linux.so在执行java需要手动配置
java.library.path和引用hadoop-lzo-0.4.20.jar(没有找到将其一并打包到工程uber.jar里面的方式) hadoop-lzo编译
# 命令解释
java -cp file-compress.jar com.donny.orc.ReadWriterOrc {数据记录数} {压缩简称}
# ORC未压缩
java -cp file-compress.jar com.donny.orc.ReadWriterOrc 10000 none
# ORC采用lzo压缩
java -cp file-compress.jar com.donny.orc.ReadWriterOrc 10000 lzo
# ORC采用lz4压缩
java -cp file-compress.jar com.donny.orc.ReadWriterOrc 10000 lz4
# ORC采用zstd压缩
java -cp file-compress.jar com.donny.orc.ReadWriterOrc 10000 zstd
# ORC采用snappy压缩
java -cp file-compress.jar com.donny.orc.ReadWriterOrc 10000 snappy
# Parquet未压缩
java -cp file-compress.jar com.donny.parquet.NativeParquet 10000 none
# Parquet采用lzo压缩
java -Djava.library.path=/native/Linux-amd64-64/lib -cp file-compress.jar:hadoop-lzo-0.4.20.jar com.donny.parquet.NativeParquet 300000000 lzo
# Parquet采用lz4压缩
java -cp file-compress.jar com.donny.parquet.NativeParquet 10000 lz4_raw
# Parquet采用zstd压缩
java -cp file-compress.jar com.donny.parquet.NativeParquet 10000 zstd
# Parquet采用snappy压缩
java -cp file-compress.jar com.donny.parquet.NativeParquet 10000 snappy
压缩结果


文件使用建议
在数仓和数据湖的场景中,数据一般按以下结构进行分层存储:
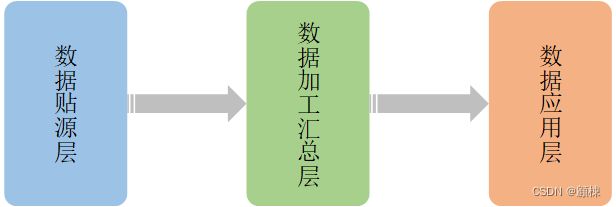
-
贴源层:该层是将数据源中的数据直接抽取过来的,数据类型以文本为主,需要保持数据原样。数据不会发生变化,在初次清洗之后被读取的概率也不大,可以采用ORC格式文件外加Zstandard存储。以控制存储最小。
-
加工汇总层:该层是数仓的数据加工组织阶段,会做一些数据的清洗和规范化的操作,比如去除空数据、脏数据、离群值等。采用ORC能够较好支持该阶段的数据ACID需求。数据压缩可以采用Lz4,以达到最优的性价比。
-
应用层:该层的数据是供数据分析和数据挖掘使用,比如常用的数据报表就是存在这里。此时的数据已经具备了对外部的直接使用的能力。数据的可能具备了一定层度的结构化,而Parquet在实现复杂的嵌套结构方面,比ORC更具有优势。所以该层一般采用Parquet,处于该层的数据一般变化不大,可以采用Zstandard压缩。
主要考虑的因素
- 数据的变化性
- 数据的结构复杂性
- 数据的读写高效性
- 数据压缩率
附录
编译hadoop-lzo
编译前提
- 安装JDK1.8+
- 安装maven
- OS已经安装lzo的库
- 下载源码包 https://github.com/twitter/hadoop-lzo/releases/tag/release-0.4.20
# 解压安装包
tar -zxvf hadoop-lzo-0.4.20.tar.gz -C /opt/software/hadoop-lzo/;
# 重命名
mv hadoop-lzo-release-0.4.20 hadoop-lzo-0.4.20;
# 进入项目目录
cd /opt/software/hadoop-lzo/hadoop-lzo-0.4.20;
# 进行编译
mvn clean package
可以通过对root模块的pom.xml进行修改来对Hadoop进行适配。一般开源的不需要调整。
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<hadoop.current.version>2.9.2hadoop.current.version>
<hadoop.old.version>1.0.4hadoop.old.version>
properties>
编译程中出现的错误
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.7:run (build-native-non-win) on project hadoop-lzo: An Ant BuildException has occured: exec returned: 1
[ERROR] around Ant part ...<exec failonerror="true" dir="${build.native}" executable="sh">... @ 16:66 in /opt/software/hadoop-lzo/hadoop-lzo-0.4.20/target/antrun/build-build-native-non-win.xml
[ERROR] -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
通过配置JAVA_HOME环境变量解决
结果文件
target/hadoop-lzo-0.4.20.jartarget/native/Linux-amd64-64/lib下的文件
file-compress.jar源码
ReadWriterOrc类
package com.donny.orc;
import com.donny.base.utils.FileUtil;
import com.donny.parquet.NativeParquet;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hive.common.type.HiveDecimal;
import org.apache.hadoop.hive.ql.exec.vector.*;
import org.apache.hadoop.hive.ql.io.sarg.PredicateLeaf;
import org.apache.hadoop.hive.ql.io.sarg.SearchArgumentFactory;
import org.apache.hadoop.hive.serde2.io.HiveDecimalWritable;
import org.apache.orc.*;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.IOException;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.sql.Timestamp;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.UUID;
/**
*
* org.apache.orc
* orc-core
* 1.8.3
*
*
*
* org.apache.hadoop
* hadoop-client
* 2.9.2
*
*
*
* org.lz4
* lz4-java
* 1.8.0
*
*
* @author [email protected]
* @description
* @date 2023/6/8
*/
public class ReadWriterOrc {
private static final Logger LOG = LoggerFactory.getLogger(ReadWriterOrc.class);
public static String path = System.getProperty("user.dir") + File.separator + "demo.orc";
public static CompressionKind codecName;
static int records;
public static void main(String[] args) throws IOException {
// 写入记录数
String recordNum = args[0];
records = Integer.parseInt(recordNum);
if (records < 10000 || records > 300000000) {
LOG.error("压缩记录数范围是10000~300000000");
return;
}
// 压缩算法
String compressionCodecName = args[1];
switch (compressionCodecName.toLowerCase()) {
case "none":
codecName = CompressionKind.NONE;
break;
case "lzo":
codecName = CompressionKind.LZO;
break;
case "lz4":
codecName = CompressionKind.LZ4;
break;
case "zstd":
codecName = CompressionKind.ZSTD;
break;
default:
LOG.error("目前压缩算法支持none、lzo、lz4、zstd");
return;
}
long t1 = System.currentTimeMillis();
writerToOrcFile();
long duration = System.currentTimeMillis() - t1;
String fileSize = "";
File afterFile = new File(path);
if (afterFile.exists() && afterFile.isFile()) {
fileSize = FileUtil.fileSizeByteConversion(afterFile.length(), 2);
}
LOG.info("Using the {} compression algorithm to write {} pieces of data takes time: {}s, file size is {}.",
compressionCodecName, recordNum, (duration / 1000), fileSize);
}
public static void readFromOrcFile() throws IOException {
Configuration conf = new Configuration();
TypeDescription readSchema = TypeDescription.createStruct()
.addField("long_value", TypeDescription.createLong())
.addField("double_value", TypeDescription.createDouble())
.addField("boolean_value", TypeDescription.createBoolean())
.addField("string_value", TypeDescription.createString())
.addField("decimal_value", TypeDescription.createDecimal().withScale(18))
.addField("time_value", TypeDescription.createTimestamp())
.addField("time_instant_value", TypeDescription.createTimestampInstant())
.addField("date_value", TypeDescription.createDate());
Reader reader = OrcFile.createReader(new Path(path),
OrcFile.readerOptions(conf));
OrcFile.WriterVersion writerVersion = reader.getWriterVersion();
System.out.println("writerVersion=" + writerVersion);
Reader.Options readerOptions = new Reader.Options()
.searchArgument(
SearchArgumentFactory
.newBuilder()
.between("long_value", PredicateLeaf.Type.LONG, 0L, 1024L)
.build(),
new String[]{"long_value"}
);
RecordReader rows = reader.rows(readerOptions.schema(readSchema));
VectorizedRowBatch batch = readSchema.createRowBatch();
int count = 0;
while (rows.nextBatch(batch)) {
LongColumnVector longVector = (LongColumnVector) batch.cols[0];
DoubleColumnVector doubleVector = (DoubleColumnVector) batch.cols[1];
LongColumnVector booleanVector = (LongColumnVector) batch.cols[2];
BytesColumnVector stringVector = (BytesColumnVector) batch.cols[3];
DecimalColumnVector decimalVector = (DecimalColumnVector) batch.cols[4];
TimestampColumnVector dateVector = (TimestampColumnVector) batch.cols[5];
TimestampColumnVector timestampVector = (TimestampColumnVector) batch.cols[6];
count++;
if (count == 1) {
for (int r = 0; r < batch.size; r++) {
long longValue = longVector.vector[r];
double doubleValue = doubleVector.vector[r];
boolean boolValue = booleanVector.vector[r] != 0;
String stringValue = stringVector.toString(r);
HiveDecimalWritable hiveDecimalWritable = decimalVector.vector[r];
long time1 = dateVector.getTime(r);
Date date = new Date(time1);
String format = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(date);
long time = timestampVector.time[r];
int nano = timestampVector.nanos[r];
Timestamp timestamp = new Timestamp(time);
timestamp.setNanos(nano);
System.out.println(longValue + ", " + doubleValue + ", " + boolValue + ", " + stringValue + ", " + hiveDecimalWritable.getHiveDecimal().toFormatString(18) + ", " + format + ", " + timestamp);
}
}
}
System.out.println("count=" + count);
rows.close();
}
public static void writerToOrcFile() throws IOException {
Configuration configuration = new Configuration();
configuration.set("orc.overwrite.output.file", "true");
TypeDescription schema = TypeDescription.createStruct()
.addField("long_value", TypeDescription.createLong())
.addField("double_value", TypeDescription.createDouble())
.addField("boolean_value", TypeDescription.createBoolean())
.addField("string_value", TypeDescription.createString())
.addField("decimal_value", TypeDescription.createDecimal().withScale(18))
.addField("time_value", TypeDescription.createTimestamp())
.addField("time_instant_value", TypeDescription.createTimestampInstant())
.addField("date_value", TypeDescription.createDate());
Writer writer = OrcFile.createWriter(new Path(path),
OrcFile.writerOptions(configuration)
.setSchema(schema)
.stripeSize(67108864)
.bufferSize(64 * 1024)
.blockSize(128 * 1024 * 1024)
.rowIndexStride(10000)
.blockPadding(true)
.compress(codecName));
//根据 列数和默认的1024 设置创建一个batch
VectorizedRowBatch batch = schema.createRowBatch();
LongColumnVector longVector = (LongColumnVector) batch.cols[0];
DoubleColumnVector doubleVector = (DoubleColumnVector) batch.cols[1];
LongColumnVector booleanVector = (LongColumnVector) batch.cols[2];
BytesColumnVector stringVector = (BytesColumnVector) batch.cols[3];
DecimalColumnVector decimalVector = (DecimalColumnVector) batch.cols[4];
TimestampColumnVector dateVector = (TimestampColumnVector) batch.cols[5];
TimestampColumnVector timestampVector = (TimestampColumnVector) batch.cols[6];
for (int r = 0; r < records; ++r) {
int row = batch.size++;
longVector.vector[row] = r;
doubleVector.vector[row] = r;
booleanVector.vector[row] = r % 2;
stringVector.setVal(row, UUID.randomUUID().toString().getBytes());
BigDecimal bigDecimal = BigDecimal.valueOf((double) r / 3).setScale(18, RoundingMode.DOWN);
HiveDecimal hiveDecimal = HiveDecimal.create(bigDecimal).setScale(18);
decimalVector.set(row, hiveDecimal);
long time = new Date().getTime();
Timestamp timestamp = new Timestamp(time);
dateVector.set(row, timestamp);
timestampVector.set(row, timestamp);
if (batch.size == batch.getMaxSize()) {
writer.addRowBatch(batch);
batch.reset();
}
}
if (batch.size != 0) {
writer.addRowBatch(batch);
batch.reset();
}
writer.close();
}
}
NativeParquet类
package com.donny.parquet;
import com.donny.base.utils.FileUtil;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.parquet.column.ParquetProperties;
import org.apache.parquet.example.data.Group;
import org.apache.parquet.example.data.GroupFactory;
import org.apache.parquet.example.data.simple.SimpleGroupFactory;
import org.apache.parquet.hadoop.ParquetFileWriter;
import org.apache.parquet.hadoop.ParquetReader;
import org.apache.parquet.hadoop.ParquetWriter;
import org.apache.parquet.hadoop.example.GroupReadSupport;
import org.apache.parquet.hadoop.example.GroupWriteSupport;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import org.apache.parquet.schema.MessageType;
import org.apache.parquet.schema.MessageTypeParser;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.IOException;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.util.Date;
import java.util.Random;
import java.util.UUID;
/**
*
* org.lz4
* lz4-java
* 1.8.0
*
*
*
* org.apache.hadoop
* hadoop-client
* 2.9.2
*
*
*
* org.apache.parquet
* parquet-avro
* 1.13.1
*
*
*
* org.apache.avro
* avro
* 1.11.1
*
*
* @author [email protected]
* @description
* @date 2023/6/12
*/
public class NativeParquet {
private static final Logger LOG = LoggerFactory.getLogger(NativeParquet.class);
public static String path = System.getProperty("user.dir") + File.separator + "demo.parquet";
public static void main(String[] args) throws IOException {
// 写入记录数
String recordNum = args[0];
int records = Integer.parseInt(recordNum);
if (records < 10000 || records > 300000000) {
LOG.error("压缩记录数范围是10000~300000000");
return;
}
// 压缩算法
String compressionCodecName = args[1];
CompressionCodecName codecName;
switch (compressionCodecName.toLowerCase()) {
case "none":
codecName = CompressionCodecName.UNCOMPRESSED;
break;
case "lzo":
codecName = CompressionCodecName.LZO;
break;
case "lz4":
codecName = CompressionCodecName.LZ4;
break;
case "lz4_raw":
codecName = CompressionCodecName.LZ4_RAW;
break;
case "zstd":
codecName = CompressionCodecName.ZSTD;
break;
default:
LOG.error("目前压缩算法支持none、lzo、lz4、lz4_raw、zstd");
return;
}
long t1 = System.currentTimeMillis();
MessageType schema = MessageTypeParser.parseMessageType("message schema {\n" +
" required INT64 long_value;\n" +
" required double double_value;\n" +
" required boolean boolean_value;\n" +
" required binary string_value (UTF8);\n" +
" required binary decimal_value (DECIMAL(32,18));\n" +
" required INT64 time_value;\n" +
" required INT64 time_instant_value;\n" +
" required INT64 date_value;\n" +
"}");
GroupFactory factory = new SimpleGroupFactory(schema);
Path dataFile = new Path(path);
Configuration configuration = new Configuration();
GroupWriteSupport.setSchema(schema, configuration);
GroupWriteSupport writeSupport = new GroupWriteSupport();
ParquetWriter<Group> writer = new ParquetWriter<>(
dataFile,
ParquetFileWriter.Mode.OVERWRITE,
writeSupport,
codecName,
ParquetWriter.DEFAULT_BLOCK_SIZE,
ParquetWriter.DEFAULT_PAGE_SIZE,
ParquetWriter.DEFAULT_PAGE_SIZE, /* dictionary page size */
ParquetWriter.DEFAULT_IS_DICTIONARY_ENABLED,
ParquetWriter.DEFAULT_IS_VALIDATING_ENABLED,
ParquetProperties.WriterVersion.PARQUET_1_0,
configuration
);
Group group;
for (int i = 0; i < records; i++) {
group = factory.newGroup();
group.append("long_value", new Random().nextLong())
.append("double_value", new Random().nextDouble())
.append("boolean_value", new Random().nextBoolean())
.append("string_value", UUID.randomUUID().toString())
.append("decimal_value", BigDecimal.valueOf((double) i / 3).setScale(18, RoundingMode.DOWN).toString())
.append("time_value", new Date().getTime())
.append("time_instant_value", new Date().getTime())
.append("date_value", new Date().getTime());
writer.write(group);
}
writer.close();
// GroupReadSupport readSupport = new GroupReadSupport();
// ParquetReader reader = new ParquetReader<>(dataFile, readSupport);
// Group result = null;
// while ((result = reader.read()) != null) {
// System.out.println(result);
// }
long duration = System.currentTimeMillis() - t1;
String fileSize = "";
File afterFile = new File(path);
if (afterFile.exists() && afterFile.isFile()) {
fileSize = FileUtil.fileSizeByteConversion(afterFile.length(), 2);
}
LOG.info("Using the {} compression algorithm to write {} pieces of data takes time: {}s, file size is {}.",
compressionCodecName, recordNum, (duration / 1000), fileSize);
}
}
FileUtil类
package com.donny.base.utils;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.text.DecimalFormat;
/**
* File使用帮助工具类
*
* @author [email protected]
* @date 2019/11/21 14:44
* @since 1.0
*/
public class FileUtil {
/**
* 数据存储单位类型 B
*/
public static final int STORAGE_UNIT_TYPE_B = 0;
/**
* 数据存储单位类型 KB
*/
public static final int STORAGE_UNIT_TYPE_KB = 1;
/**
* 数据存储单位类型 MB
*/
public static final int STORAGE_UNIT_TYPE_MB = 2;
/**
* 数据存储单位类型 GB
*/
public static final int STORAGE_UNIT_TYPE_GB = 3;
/**
* 数据存储单位类型 TB
*/
public static final int STORAGE_UNIT_TYPE_TB = 4;
/**
* 数据存储单位类型 PB
*/
public static final int STORAGE_UNIT_TYPE_PB = 5;
/**
* 数据存储单位类型 EB
*/
public static final int STORAGE_UNIT_TYPE_EB = 6;
/**
* 数据存储单位类型 ZB
*/
public static final int STORAGE_UNIT_TYPE_ZB = 7;
/**
* 数据存储单位类型 YB
*/
public static final int STORAGE_UNIT_TYPE_YB = 8;
/**
* 数据存储单位类型 BB
*/
public static final int STORAGE_UNIT_TYPE_BB = 9;
/**
* 数据存储单位类型 NB
*/
public static final int STORAGE_UNIT_TYPE_NB = 10;
/**
* 数据存储单位类型 DB
*/
public static final int STORAGE_UNIT_TYPE_DB = 11;
private FileUtil() {
throw new IllegalStateException("Utility class");
}
/**
* 将文件大小转为人类惯性理解方式
*
* @param size 大小 单位默认B
* @param decimalPlacesScale 精确小数位
*/
public static String fileSizeByteConversion(Long size, Integer decimalPlacesScale) {
int scale = 0;
long fileSize = 0L;
if (decimalPlacesScale != null && decimalPlacesScale >= 0) {
scale = decimalPlacesScale;
}
if (size != null && size >= 0) {
fileSize = size;
}
return sizeByteConversion(fileSize, scale, STORAGE_UNIT_TYPE_B);
}
/**
* 将文件大小转为人类惯性理解方式
*
* @param size 大小
* @param decimalPlacesScale 精确小数位
* @param storageUnitType 起始单位类型
*/
public static String fileSizeByteConversion(Long size, Integer decimalPlacesScale, int storageUnitType) {
int scale = 0;
long fileSize = 0L;
if (decimalPlacesScale != null && decimalPlacesScale >= 0) {
scale = decimalPlacesScale;
}
if (size != null && size >= 0) {
fileSize = size;
}
return sizeByteConversion(fileSize, scale, storageUnitType);
}
private static String sizeByteConversion(long size, int decimalPlacesScale, int storageUnitType) {
BigDecimal fileSize = new BigDecimal(size);
BigDecimal param = new BigDecimal(1024);
int count = storageUnitType;
while (fileSize.compareTo(param) > 0 && count < STORAGE_UNIT_TYPE_NB) {
fileSize = fileSize.divide(param, decimalPlacesScale, RoundingMode.HALF_UP);
count++;
}
StringBuilder dd = new StringBuilder();
int s = decimalPlacesScale;
dd.append("0");
if (s > 0) {
dd.append(".");
}
while (s > 0) {
dd.append("0");
s = s - 1;
}
DecimalFormat df = new DecimalFormat(dd.toString());
String result = df.format(fileSize) + "";
switch (count) {
case STORAGE_UNIT_TYPE_B:
result += "B";
break;
case STORAGE_UNIT_TYPE_KB:
result += "KB";
break;
case STORAGE_UNIT_TYPE_MB:
result += "MB";
break;
case STORAGE_UNIT_TYPE_GB:
result += "GB";
break;
case STORAGE_UNIT_TYPE_TB:
result += "TB";
break;
case STORAGE_UNIT_TYPE_PB:
result += "PB";
break;
case STORAGE_UNIT_TYPE_EB:
result += "EB";
break;
case STORAGE_UNIT_TYPE_ZB:
result += "ZB";
break;
case STORAGE_UNIT_TYPE_YB:
result += "YB";
break;
case STORAGE_UNIT_TYPE_DB:
result += "DB";
break;
case STORAGE_UNIT_TYPE_NB:
result += "NB";
break;
case STORAGE_UNIT_TYPE_BB:
result += "BB";
break;
default:
break;
}
return result;
}
}