分库分表-ShardingSphere
分库分表拆常见分方法与特点
| 分片策略 |
数据分布 |
以后扩展 |
| 基于Hash:hash(分片键)%分片数 |
数据分布均匀 |
不易扩容,扩容需要数据迁移 |
| 范围分片:例如按年分,按月,按日 |
数据分表可能不均匀 |
易扩展,扩展不需要数据迁移 |
分库分表的常见问题与解决方式
如何确定最初需要多少张表?
一般考虑10年的数据量即可,如果是基于Hash,扩容需要再次迁移
分库之后Join如何处理?
如果是绑定表,即有关联的一组表,例如订单与订单详情表,使用同一个分库分表策略。
如果要join的表,是个字典表(表小,数据变动不大),建议做成广播表,所有的库都有存一份。
如果就是落在不同的库,例如订单,商品,可以采取 CQRS或者API Composition
用户分表了,某个用户手机号,找到用户信息?
加一张关联表, phone -> userId, 先根据phone 查找userId,之后根据userId ,查询订单表
分库分表后全局唯一ID如何生产?
- UUID,无序,写入性能差
- snowflake·: ShardingSphere提供这个算法, 有序,写入性能好,生成性能无上限。
- 利用Redis作为发号器: String 类型 key:yyyyMMddHHmmssSSS value: 序号 防止时钟不准,key的有效时间为:30s,生产性能受到redis限制,一般业务够用
ShardingSphere 分片流程
分片流程:解析--> 路由->改写->执行->归并
解析 SQLParserEngine
1.解析成AST 语法树 官网图片如下:

2.提取SQLSegment
3.填充SQL语句 SQLStatement
路由SQLRouteEngine
获取SQLRouteExecutor 并执行
创建ShardingConditions
对SQLStatement进行校验。
调用链条
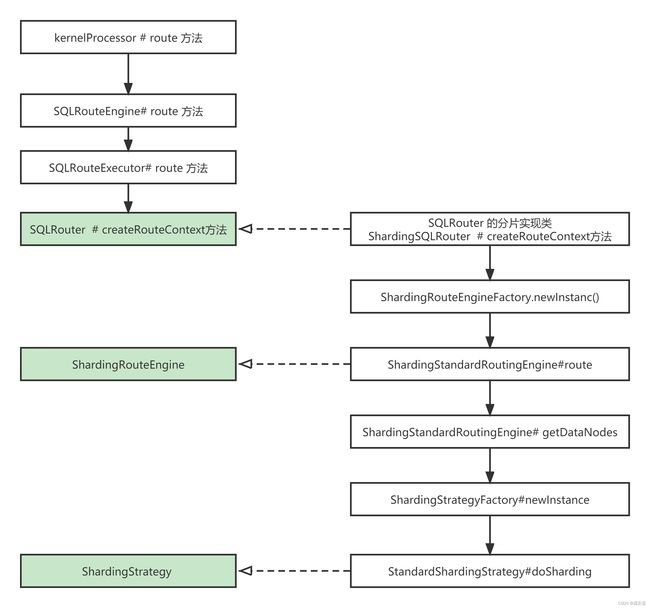
StandardShardingStrategy 内部doSharding方法 对精准和范围均有支持
PreciseShardingValue 处理精准分片 = ,in
RangeShardingValue 处理范围分片 >,>=,
从ShardingStrategy 的生命可以得出:分片 = 分片键+ 分片算法
public interface ShardingStrategy {
// 分片键
Collection getShardingColumns();
// 算法
ShardingAlgorithm getShardingAlgorithm();
//分片方式
Collection doSharding(
Collection availableTargetNames,
Collection shardingConditionValues,
DataNodeInfo dataNodeInfo,
ConfigurationProperties props);
} 改写SQLRewriteEntry
调用链条
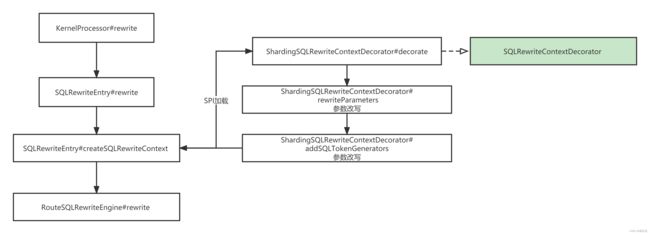
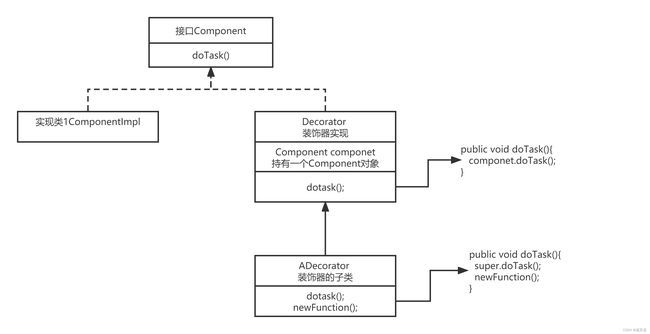
扩展 - 装饰者模式
不改变对象结构,动态给该对象,添加额外的功能。
标准类图,ShardingSphere 改写部分的 略有不同。
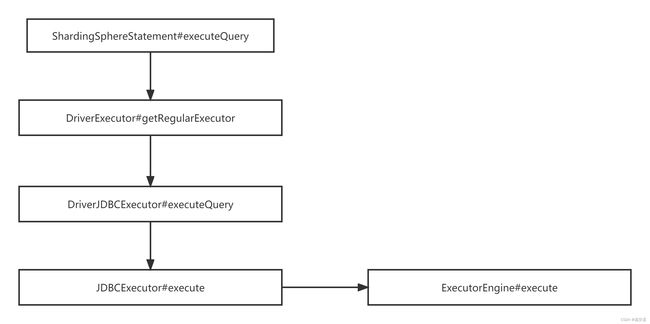
执行ExecutorEngine
官网图

连接模式说明
public enum ConnectionMode {
MEMORY_STRICTLY, CONNECTION_STRICTLY
}MEMORY_STRICTLY 内存模式,适合OLAP,并行处理
- Sharding Sphere 一次性获取所需的数据库连接。
- 只需获取一个数据库的连接不加锁
CONNECTION_STRICTLY 连接模式,适合OLTP,串行处理。
配置项
props:
max-connections-size-per-query: 1
默认为1 ,标示使用CONNECTION_STRICTLY
自动控制算法
内部自动选择算法,位于AbstractExecutionPrepareEngine#prepare
ConnectionMode connectionMode =
maxConnectionsSizePerQuery < sqlUnits.size()
? ConnectionMode.CONNECTION_STRICTLY
: ConnectionMode.MEMORY_STRICTLY;maxConnectionsSizePerQuery 用户的配置
sqlUnits.size() 路由引擎产生的Sqlunits数,粗暴的理解:要查询的SQL语句数
归并MergeEngine
官网流程

流式归并:
每一次从结果集中获取的数据,都能通过逐条的方式返回正确的单条数据,就会流式归并
流式与内存互斥。
核心接口MergedResult 实现
分页LimitDecoratorMergedResult 是装饰者模式,在skipOffset(),跳过了不需要的数据,不会存在内存中。
public final class LimitDecoratorMergedResult extends DecoratorMergedResult {
private final PaginationContext pagination;
private final boolean skipAll;
private int rowNumber;
public LimitDecoratorMergedResult(final MergedResult mergedResult, final PaginationContext pagination) throws SQLException {
super(mergedResult);
this.pagination = pagination;
skipAll = skipOffset();
}
private boolean skipOffset() throws SQLException {
for (int i = 0; i < pagination.getActualOffset(); i++) {
if (!getMergedResult().next()) {
return true;
}
}
rowNumber = 0;
return false;
}
@Override public boolean next() throws SQLException {
if (skipAll) {
return false;
}
if (!pagination.getActualRowCount().isPresent()) {
return getMergedResult().next();
}
return ++rowNumber <= pagination.getActualRowCount().get() && getMergedResult().next();
}
}AggregationUnitFactory 能查到对应的聚合函数
public static AggregationUnit create(final AggregationType type, final boolean isDistinct) {
switch (type) {
case MAX:
return new ComparableAggregationUnit(false);
case MIN:
return new ComparableAggregationUnit(true);
case SUM:
return isDistinct ? new DistinctSumAggregationUnit() : new AccumulationAggregationUnit();
case COUNT:
return isDistinct ? new DistinctCountAggregationUnit() : new AccumulationAggregationUnit();
case AVG:
return isDistinct ? new DistinctAverageAggregationUnit() : new AverageAggregationUnit();
case BIT_XOR:
return new BitXorAggregationUnit();
default:
throw new UnsupportedSQLOperationException(type.name());
}
}