Redis集群详解
为了提高redis的高可用性,可以通过集群来容灾,一般有三种集群方案:
1、主从复制
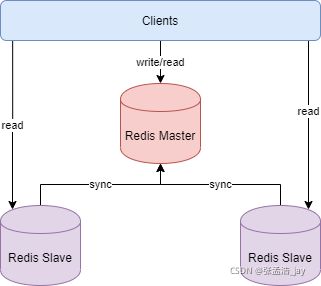
主从复制模式下,redis分为 一个master 主库 和 多个 slave 从库。
master 主库 可以提供读、写操作。slave 从库 只能提供读操作。master不断的将数据同步给slave。
主从复制的两个关键点:
1、runid
当主从复制的时候,没有利用 ip地址+端口号 来标识,而是采用runid。
runid 是一个 40位的随机UUID,当redis重启后,会重新生成runid,runid可以唯一标识redis的一次运行。
如果采用ip地址+端口号的话,如果master重启的话,对应的数据可能会改变,这个时候从库也要跟随主库的变化。如果按照ip地址+端口号的话,不太好判断master是否重启或者改变了。
2、offset
redis采用了全量同步和增量同步的混合模式。
增量同步就是master将收到的写操作数据保存起来,将对应的写操作同步给slave,slave直接执行对应的写操作就可以了,这样比每次都全量同步效率更高。
offset 就是 增量同步中的写操作数据中的偏移量。
master中维护了一个缓冲池,用来存放写操作数据。
缓冲池是循环使用的,当空间不足的时候,会覆盖之前的数据。
master维护了两个指针,一个小offset和一个大的offset。
小的offset对应着当前缓冲池中保存的最旧的写操作偏移量
大的offset对应着当前最新的写操作偏移量
每个从库都会有一个offset变量,代表着当前从库同步的最新的写操作偏移量,当收到主库传来的写操作后,会将offset加上对应的偏移量。
主从同步流程:
首先说一下psync(runid,offset)命令,这是 从库 向 主库发起同步请求的一个命令,runid对应着主库的id,offset对应着从库请求的同步偏移。
1、当slave启动后,还没有master的runid信息,向master发送psync命令,其中offset = -1,runid = ?
2、master接到fsync命令后,发现offset = -1,说明是首次同步,会通过bgsave生成一个全局备份快照rdb,将master的runid和offset(rdb数据对应的offset)传送给对应的slave,并且会利用缓冲区记录快照之后的所有的写操作。在发送完runid和offset后,将对应的rdb发送给从库。
3、slave将master发来的runid和offset保存起来。
4、slave收到rdb后,将rdb加载到内存中,并保存好对应的offset。到此,全量同步完成。
5、当master接到新的写操作的时候,将对应的写操作执行后,将写操作写入到缓冲区中,增加master的offset。接着写操作和新的offset发送给所有的slave,slave在收到写操作后,也会更新内存和对应的offset。
心跳机制:
1、slave心跳
slave每隔1s,就会向主库发送一个请求,请求中携带了自己的offset信息。
master在收到对应的请求后,会维护slave和其对应的offset,通过其offset和自己的offset比对,就可以判断slave是否master的数据是否保持一致了。由于增量同步数据包可能丢失,offset会不一致,master会将对应的写操作数据发送给从库。
2、master心跳
master会每隔10s向slave发送心跳探测,如果在规定时间内收不到回信,就说明slave下线了,后继不会再像slave发送同步信息。
slave断网重连
slave如果断网了,在重新与master建立连接后,会发送fsync命令,会带上对应的runid和offset。master会检验offset,如果offset对应的数据还在缓冲区中,就将对应的数据发送给slave。如果缓冲区重写了,就发送一个rdb和对应的offset发送给slave。
缓冲区会维护一个最小offst和最大offset,相当于一个循环队列,当缓冲区不够用的时候,会覆盖之前的数据。
总结来说,就是首先做一个全量备份,然后在运行期间,就执行增量备份。
实际部署
主从复制只需要在slave中配置相关信息就可以了。
replicaof 127.0.0.1 6379 # master的ip,port
masterauth 123456 # master的密码
replica-serve-stale-data no # 如果slave无法与master同步,设置成slave不可读,方便监控脚本发现问题
主从复制的优缺点:
优点:
1、 slave可以进行读取操作,减轻了master的压力
2、 slave的同步是异步进行的,不会阻塞master处理客户端的读写请求
缺点:
1、 不具有自动容灾功能,当master宕机后,需要手动更换将master的IP更换为一个slave的IP,然后其他slave的master IP也要重新指定。
2、哨兵模式 Sentinel
哨兵模式是在主从复制的基础上改进的一种集群方案。
哨兵模式中会对master和slave进行监控,当master宕机后,立即进行容灾处理。
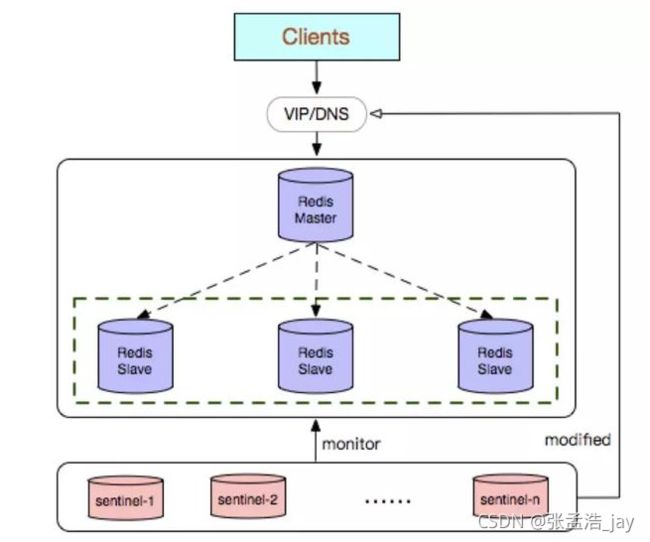
哨兵是一个进程,通过sentinel.conf来配置哨兵进程监视的相关信息。
哨兵进程可以与redis放在同一个机器中,也可以单独运行。
哨兵进程会监视 master和master对应的slave,当master宕机的时候,会从slave中选出一个slave作为新的master。
为了防止哨兵进程挂掉,导致整个系统瘫痪,会有多个哨兵进程同时监视master和slave。
哨兵模式工作流程:
1、配置sentinel.conf
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 当quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了
# sentinel monitor <master-name> <master ip> <master port> <quorum>
sentinel monitor mymaster 192.168.10.133 6379 1
首先在sentinel.conf中配置哨兵监视的master的信息。
2、启动哨兵服务
./redis-sentinel sentinel.conf
3、哨兵的自动发现
细心的同学有可能会发现,我们在sentinel.conf中并没有配置其他哨兵的信息,只配置了master的信息。
哨兵如何与其他哨兵通信呢?
这就依赖于Redis的pub/sub,也就是发布/订阅机制了。
1、 哨兵首先订阅master中的 sentinel:hello 这个key。
2、 哨兵每隔2s就会把自己的ip地址、端口号、runid等信息通过publish 也就是推送的方式 推送到 sentinel:hello channel 中。
我们简单的说下redis的pub/sub机制。
struct redisServer {
...
//用来存放pub/sub信息
dict *pubsub_channels;
...
}
redisServer中 pubsub_channels 是一个dict对象,dict中存储的是若干个channel对象,channel的key就是哨兵订阅的key,也就是 sentinel:hello ,channel的value就是一个列表,存放的是订阅该key的所有客户端。
当一个客户端订阅了redis 的一个key后,会在redisServer中的pubsub_channels中对应的key的列表中加入一个客户端对象,客户端对象中包括了客户端的IP地址、端口等信息。
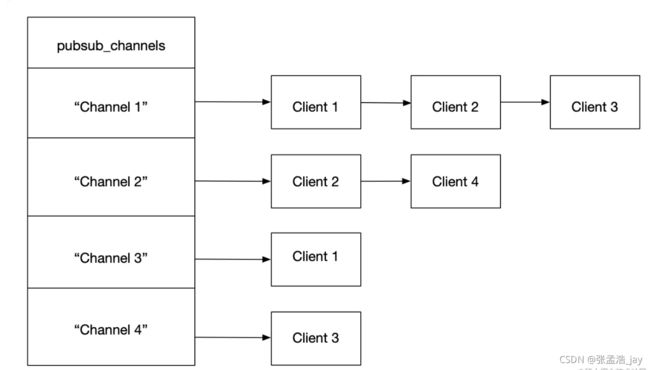
当哨兵每隔2s 通过publish 向 sentinel:hello 发送自己的ip+端口+runid信息的时候,redis会在 pubsub_channels 找到 sentinel:hello 对应的 客户端列表,然后遍历这个客户端列表,将ip地址+端口+runid信息挨个发送给对应的客户端。
当客户端收到这些信息的时候,就可以得到其他哨兵的信息了。
4、故障探测
每个哨兵每隔1s 会向 master 发送一个ping探测信息。
如果master正常工作,会返回一个响应,里面包括了slave的信息。
如果master在规定时间内没有回应,那么哨兵就认为 master存在 主观宕机。
为什么是主观宕机呢?
因为有可能是当前哨兵掉线了,或者当前哨兵和master之间的网络不太通畅,所以是主观宕机。
如果一个哨兵认为master客观宕机后,回向所有其他的哨兵节点发送一个SENTINEL is-master-down-by-addr 探测信息,里面记录了自己的ip地址、端口号、runid等信息。
当其他哨兵收到SENTINEL is-master-down-by-addr 探测信息后,会返回自己对于master的探测结果在线 or 宕机 给源哨兵。
如果一个哨兵接收到了超过 quorum 的 其他哨兵的关于master的宕机回应,这个时候哨兵就会判定 master 是一个客观宕机
quorum可以在sentinel.conf中配置。
5、选举哨兵leader
当一个哨兵 判定 master 客观宕机了,就开始进入选取哨兵leader,哨兵leader会进行选择新的master的工作。
为什么要选取一个leader呢?直接选择新的master不就好了吗?
因为各个哨兵都是平等的关系,也就是说没有中心,是一种去中心化的集群。
如果一个哨兵直接选取新的master的话,其他哨兵也有可能选取其他的master,出现重复选取的情况。这一切的原因是哨兵集群是去中心化的。
具体的选取流程如下:
首先,选取信息中有一个epoch字段,代表着选取的迭代次数。因为选取称为leader的条件比较严苛,一般需要一半以上的哨兵支持,具体的由参数majority决定。 majority 可以在 sentinel.conf 中配置
所以经过了好几轮还是没选取出leader。
1、哨兵向所有其他哨兵发送一个选取请求,里面携带了自己的ip地址、端口、runid信息。
2、当其他哨兵收到选取请求的时候,就返回一个回应,代表支持对应的哨兵当leader。 值得注意的是,哨兵只会对第一个选取请求回应,后来的请求不会回应,这样才能保证只有一个leader被选取。
3、当哨兵收到的支持票数大于规定的票数的时候,当前哨兵就成了leader。 哨兵称为leader后,会向其他哨兵发送对应的通知。当其他哨兵收到通知后,会停止发送选票请求。
4、如果在规定期间,没有选取出leader,就会开启下一轮投票。
6、选取新的master
哨兵leader会通过以下优先级来选取slave
1、首先根据slave的优先级
2、其次根据slave的offset,offset越大,说明slave的数据越完整
3、最后根据runid,优先选取runid小的slave
接下来还需要改变配置信息:
1、更改被选中的slave的配置信息,将其设置为master,比如开始写模式等操作。
2、向其他slave发送更改信息,将新的master的ip地址、端口号、runid发送给其他slave
3、向其他哨兵发送更改信息,将新的master的ip地址、端口号、runid发送给其他哨兵
3、cluster
哨兵模式只是对主从复制的一个可靠性提高,仍然是一个master支持读写。
当redis中需要的缓存数据比较大的时候,超过了一个机器的处理能力的时候。这个时候需要将数据分为多个块,散布到不同的机器中去读写。
这就是cluster的基本思想。
cluster可以将多个master和slave集群到一起,提供一个非常大的缓存系统。
怎么讲数据分区呢?
1、固定哈希算法
1、对key进行hash,获取到hash值
2、将hash值 对 master的节点个数 取模,将对应的key存储到对应的master节点中
3、当获取数据的时候,就对key进行hash,然后获取到对应的取模结果,到对应的master节点获取数据。
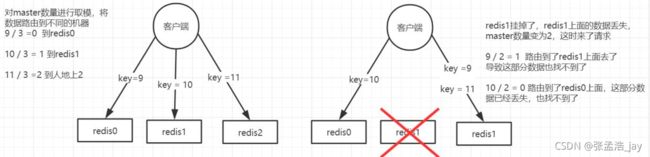
固定哈希有个缺点,无法动态扩展,也就是无法动态的加入或者删除master节点。
如果新增或者删除master节点后,会影响其他master节点的读取。
因为节点的个数发生了变化,对应的key取模的结果就变了,就无法找到key对应的master节点了。如果要搬运数据的话,会比较麻烦。
2、一致性hash
一致性hash 也是采用对key做hash然后取模的方法,但是不是对节点的个数取模,而是对 232 -1 取模。
这 232 个数 构成了一个哈希空间。
每一个master会对应着一个哈希空间中的一个位置。

当一个key写入或者读取的时候,会进行hash值求取,然后对
232取模,得到对应的哈希位置 p1。
然后在哈希空间中顺时针查找,找到最近的一个哈希位置对应着一个master,就将对应的数据存储到该master上,或者从该master中读取数据。
当位置超过了232,就从0继续开始向上查找。
一致性hash的好处就是如果一个master移除了,只会影响它的下一个master节点,不会影响其他的master的读取。
我们只需要将移除的master的数据搬运到他的下一个master就ok了。
当新增一个master的时候,我们只需要将他的下一个master中的所有 key的取模结果小于新master的哈希位置 的 key搬运到新的master就ok了。
带有虚拟节点的一致性hash
上面的一致性hash有一个缺点,当一个master移除后,会将master的压力全部转移给后继的master,给后继的master带来了极大的负荷,容易让其崩溃。
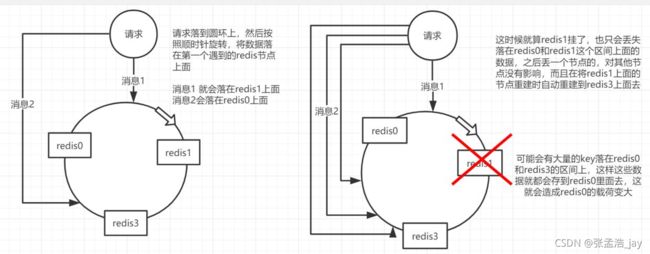
所以引入了带有虚拟节点的一致性hash!
所谓虚拟节点,就是在一致性hash的上方加入了一层虚拟逻辑。
之前是3个master,我们可以在虚拟层加入多个虚拟节点,但是其实际存储地址还是之前的3个master。
看下图就可以理解了,虽然还是之前的3个master,但是3个master对应的哈希空间,不再是连续的一大段空间了,而是变成了多个离散的小空间。
这样的话,当一个master删除后,可以将对应的数据分散到其他多个master上,而不是像之前把全部的数据都压到一个master上。
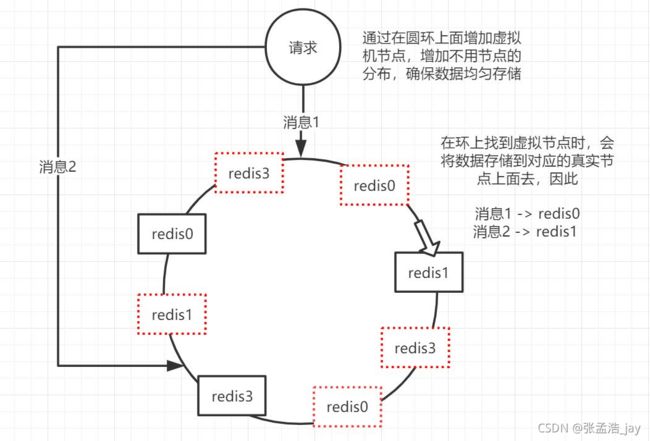
redis cluster的做法
redis cluster 采用的是带有虚拟节点的一致性hash算法,只不过redis没有采用 232的映射空间,而是0-16383,也就是对16384进行取模。
redis cluster中 0 - 16383 中的每个位置都称之为 槽 。每个master都占用多个槽。
每个master都会负责多个槽,然后master之间会交流各自维护的槽信息,每个master中会维护所有的master对应的槽信息。

当一个key做完 hash ,然后对16384取模后,得到对应的位置,然后查找槽信息,找到槽对应的master,进行读写操作。
新增master
当新增master的时候,会从其他master中的槽位中截取一点槽位,然后赋予给新master。并且需要将其他master中对应的数据转移到新master中。
删除master
当删除master时,需要将master的槽位和槽位对应的数据转移到其他的master中。
redis-cluster中集群状态和slot信息
一个节点有着一个clusterState 对象,clusterState记录了一个集群的所有信息。
typedef struct clusterState {
...
// 负责处理各个槽的节点
// 例如 slots[i] = clusterNode_A 表示槽 i 由节点 A 处理
clusterNode *slots[REDIS_CLUSTER_SLOTS];
...
} clusterState;
// 节点状态
struct clusterNode {
// 节点的名字,由 40 个十六进制字符组成
// 例如 68eef66df23420a5862208ef5b1a7005b806f2ff
char name[REDIS_CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
// 由这个节点负责处理的槽
// 一共有 REDIS_CLUSTER_SLOTS / 8 个字节长
// 每个字节的每个位记录了一个槽的保存状态
// 位的值为 1 表示槽正由本节点处理,值为 0 则表示槽并非本节点处理
// 比如 slots[0] 的第一个位保存了槽 0 的保存情况
// slots[0] 的第二个位保存了槽 1 的保存情况,以此类推
unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */
// 该节点负责处理的槽数量
int numslots; /* Number of slots handled by this node */
};
就这样的方式,每个redis节点都保存了一份集群信息,里面也包括了每个slot对应的节点信息。
配置
redis-cluster采用去中心化的架构,每个master自己都会自己维护一个集群的配置信息,对应的每个redis都有一个cluster.conf文件。
redis-cluster采用gossip协议来解决master之间的通信。
gossip主要由以下几种消息类型:
1、meet
通过「cluster meet ip port」命令,一个master可以像另一个master发送集群消息。另一个master会将自己的信息和维护的集群列表信息返回。
2、ping
master 定时 向自己维护的集群节点列表的所有节点,依次将自己的信息和维护的集群节点列表信息发送出去。
这也做的目的是,所有的节点都维护一个相同的集群列表信息。
3、pong
用于回复ping和meet请求,会携带自己的信息和维护的集群节点列表信息。
4、fail
当一个master对应另一个master ping 得不到回应的时候,会向自己的集群列表中的节点依次发送fail消息,里面携带了掉线的master的信息。

怎么让多个master集群到一块呢?
master想要和其他redis集群到一块,需要手动的进行连接。。。
所以master要依次meet集群中的所有节点,手动建立联系。
Cluster meet xxx:6380
1、使用meet命令来连接其他redis。 meet指令会将master的ip地址+端口号等信息发送给xxx:6380对应的redis。
2、当xxx:6380收到后,会返回一个pong命令给master,代表着二者连接成功了。
节点上线
节点上线就需要meet命令手动连接对应的节点,只meet一个节点就行,因为节点会把新上线的节点传播给其他节点。但是这个需要时间。如果需要快速上线,就把集群中的所有节点都meet一下。
节点上线后,还需要从一个源节点中为其分配对应的槽位,需要手动使用命令。
我们先说下单个槽的迁移,流程如下:
1、将新节点设置为导入模式,slot为对应的槽位置,sourceNodeId为对应的源node信息
CLUSTER SETSLOT <slot> IMPORTING <source-node-id>
2、将对应的源节点设置为迁移模式,destination-node-id是导入的node信息
CLUSTER SETSLOT <slot> MIGRATING <destination-node-id>
3、获取迁移的key,源节点执行下面的命令,slot为槽位置,count为迁移的槽中的key个数
cluster getkeysinslot {slot} {count}
4、开始迁移,在源节点中执行,key是步骤3中查出的key
migrate {targetIP} {targetPort} key 0 {timeout}
5、重复3和4,直到槽中的key全部迁移完成
6、通知集群所有节点,槽迁移了。
CLUSTER SETSLOT <slot> NODE <destination-node-id>

上面这是单个槽的迁移,如果要迁移上千个槽,那。。。
所以redis支持了批量迁移槽的命令
redis-cli --cluster reshard host:port --from <arg> --to <arg> --slots <arg> --yes --timeout
<arg> --pipeline <arg>
redis-cli --cluster reshard 可以实现多个源节点同时迁移到 一个 目标节点的操作。

迁移操作知识来自于链接深入学习Redis之Redis Cluster
节点下线:
和哨兵模式一样,节点下线也有客观和主观之分,原理基本一致。
当一个节点ping另一个节点的时候,如果在规定时间内收不到pong,就会像集群中其他节点发送节点主观下线的消息。
每个节点都会记录一个关于主观下线节点的对应次数,当一个节点收到一个主观节点下线通知的时候,就将对应的次数+1,当次数超过集群中的节点的一般时,就会在自己的内存中,标志节点为客观下线。然后将节点客观下线的消息传递给集群中的所有节点。
从上述配置流程可以看出,每个节点都存储了关于集群的配置信息,包括所有节点对应的slot信息。
删除节点
上面说的节点下线是节点意外下线,当一个节点正常下线的时候,需要将对应的槽和数据迁移到其他节点上去,和节点上线的迁移方法一致,就不再赘述了。
Moved重定向
客户端只会指向集群中的一个节点,当对应的节点发生数据迁移后,有可能客户端请求的数据被转移到了节点2上去了。
那么节点会返回一个moved重定向,客户端收到后会访问节点2访问对应的数据。
客户端会更新对应的slot缓存,下一次在请求对应的slot的时候,会直接请求节点2。
Ask重定向
和Moved重定向不同的是,Ask针对的是正在发生数据迁移的情况,如果存在对应的key,就直接返回。
如果不存在就返回一个ask重定向,客户端会请求重定向中的对应节点,但是不会客户端中的slot缓存更新,下次还会请求老节点。