5 数据库缓存机制 redis集群 --SoringBoot整合redis--及redis命令集
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件
1 上传安装包
2 解压Redis
tar -xvf redis-5.0.4.tar.gz
3 安装Redis
要求:在redis的根目录中执行
make
make install
4 修改Redis配置文件
vim redis.conf
1).将IP绑定注释

2).关闭保护模式
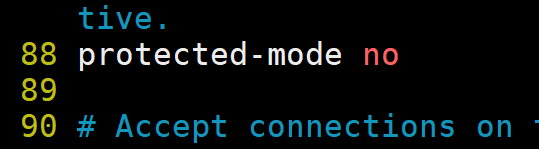
3).开启后台运行

完成!!
==========
关于Redis命令
启动redis
redis-server redis.conf
校验服务是否运行正常
ps -ef | grep redis
进入客户端命令: redis-cli -p 6379

关闭Redis命令:
方式1. kill -9/15 PID号
方式2. redis-cli -p 6379 shutdown
Redis分片机制 --通过分片,哨兵之后引入RedisCluster
说明:一般采用多台redis,分别保存用户的数据,从而实现内存数据的扩容.
对于用户而言:将redis分片当做一个整体,用户不在乎数据到底存储到哪里,只在乎能不能存.
分片主要的作用: 实现内存扩容.
Redis分片如果宕机不能实现高可用!!!
Redis的分片的计算发生在业务服务器中 将需要保存的数据存储到redis中.
Redis分片的执行的效率是最高的.
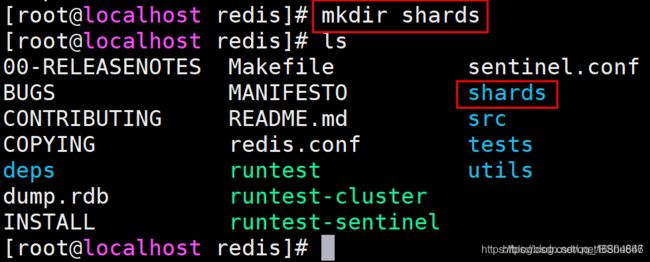
1 Linux系统中 --在redis根目录中创建一个shards目录
mkdir shards
2 分片搭建策略
说明:由于Redis启动是根据配置文件运行的,所以如果需要准备3台redis,则需要复制3份配置文件redis.conf. 端口号依次为6379/6380/6381

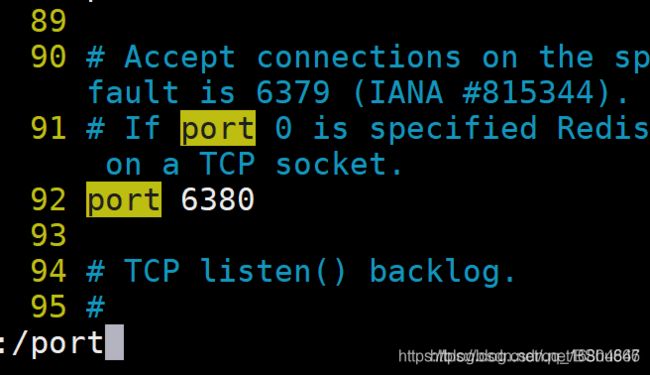
3 修改端口号:根据配置文件名称,动态修改对应的端口即可.
vim 6380.conf
/port #斜杠port在该文件里检索port

4 启动redis:
redis-server 6379.conf
redis-server 6380.conf
redis-server 6381.conf
ps -ef | grep redis
Redis分片入门案例
/**
* 测试Redis分片机制
* 业务思路:
* 用户需要通过API来操作3台redis.用户无需关心数据如何存储,只需要了解数据能否存储即可.
* 思考: 2005的数据存储到哪台redis中 --根据配置文件中的配置确定存储机制
* redis分片是如何实现数据存储的! --hash一致性算法 -目的是解决分布式缓存的问题,动态伸缩等问题
* 常见hash是8位16进制数00000000 ~ FFFFFFFF (2^4)^8 ---2^32 幂 对相同的数据进行hash值一致
*/
@Test
public void testShards(){
List<JedisShardInfo> list = new ArrayList<>();
list.add(new JedisShardInfo("192.168.126.129", 6379));
list.add(new JedisShardInfo("192.168.126.129", 6380));
list.add(new JedisShardInfo("192.168.126.129", 6381));
ShardedJedis shardedJedis = new ShardedJedis(list);
shardedJedis.set("2005", "redis分片学习");
System.out.println(shardedJedis.get("2005"));
}
一致性hash说明
步骤:
1.首先计算node节点
2.将用户的key进行hash计算,之后按照顺时针的方向找到最近的node节点之后链接,执行set操作.
特性一 平衡性
①平衡性是指hash的结果应该平均分配到各个节点,这样从算法上解决了负载均衡问题 [4] 。
说明: 如果发现节点中存储的数据负载不均,则采用虚拟节点的方式实现数据的平衡(相对平衡)
特性二 单调性
②单调性是指在新增或者删减节点时,不影响系统正常运行 因为可以实现自动的数据迁移.。
原则: 在进行数据迁移时 应该尽可能少的改变原有的数据.
特性三 分散性
③分散性是指数据应该分散地存放在分布式集群中的各个节点(节点自己可以有备份),不必每个节点都存储所有的数据 。
Spring整合Redis分片
1 编辑properties配置文件
#添加redis的配置
#添加单台配置
#redis.host=192.168.126.129
#redis.port=6379
#配置多台的redis信息
redis.nodes=192.168.126.129:6379,192.168.126.129:6380,192.168.126.129:6381
2 编辑Redis配置类
package com.jt.config;
@Configuration //标识我是一个配置类
@PropertySource("classpath:/properties/redis.properties")
public class JedisConfig {
@Value("${redis.nodes}")
private String nodes; //node,node,node
/**
* 添加Redis分片的配置
* 需求1: 动态的获取IP地址/PORT端口
* 动态的获取多个的节点信息. 方便以后扩展
*/
@Bean
//@Scope("prototype") //设置为多利对象
public ShardedJedis shardedJedis(){
List<JedisShardInfo> list = new ArrayList<>(); //Redis分片需要单个的JedisShardInfo对象..
String[] strArray = nodes.split(","); //[node,node,node]
for (String node : strArray){ //ip:port
String host = node.split(":")[0];
int port = Integer.parseInt(node.split(":")[1]);
list.add(new JedisShardInfo(host,port ));
}
return new ShardedJedis(list);
}
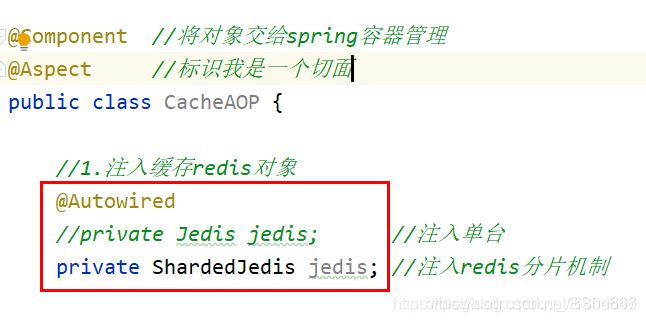
3 编辑 CacheAOP中的注入项
说明:将AOP缓存中的注入项 改为分片对象 --后面引入RedisCluster之后改为RedisCluster对象即可
Redis主从实现 --实现高可用前提 --哨兵机制
Linux系统中先关闭Redis服务器.
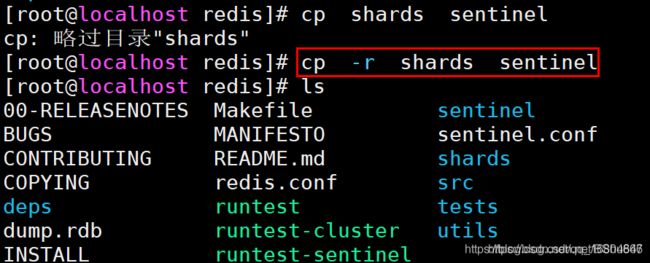
1).复制shards文件
直接复制目录里的内容到新的目录里
cp -r shards sentinel
2).删除持久化文件

3).运行3台Redis服务器
redis-server 6379.conf & redis-server 6380.conf & redis-server 6381.conf &
ps -ef | grep redis
4) 实现主从挂载
搭建规则: 6379 当作主机 6380/6381 当作从机
info replication

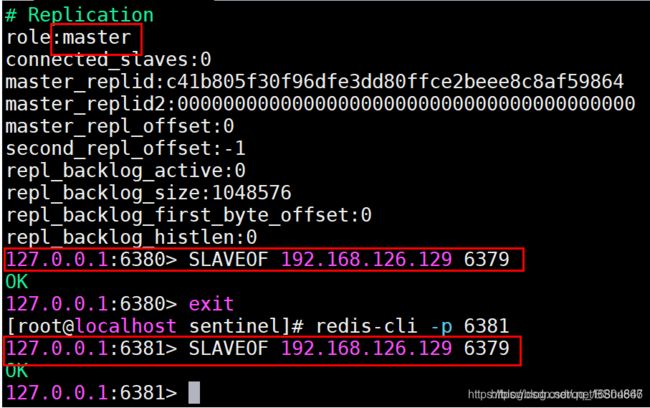
slaveof 主机IP 主机端口
slaveof 192.168.126.129 6379
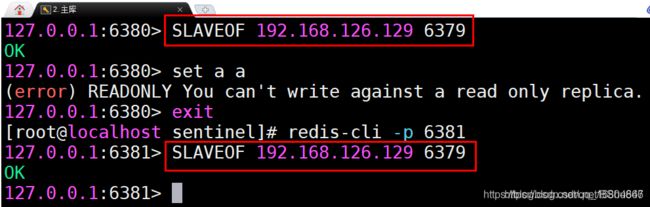
检查从机中的状态
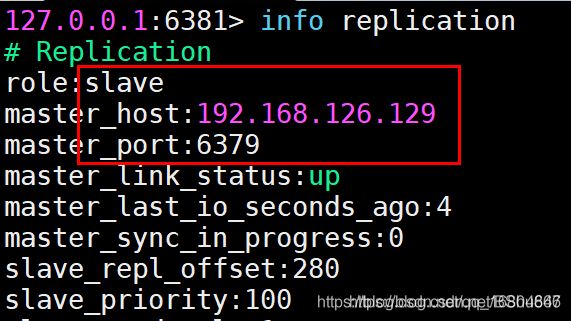
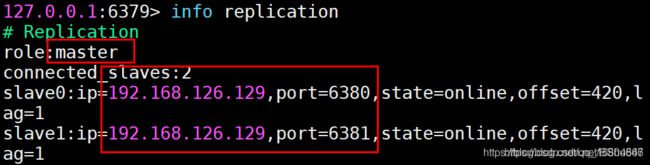
检查主机的状态:
关于挂载错误的说明
说明:由于误操作可能导致主从的结构挂载异常.如何重新挂载呢?
操作说明:可以将redis服务器全部关闭,之后重启 默认条件下的主从的挂载则会失效. 重新挂载即可.
补充说明:由于slaveof指令在内存中生效.如果内存资源释放,则主从的关系将失效.为了实现永久有效,应该将主从的关系写在配置文件中即可.
新问题的产生: 如果主机意外宕机,则由谁来完成配置文件的修改呢?
引入哨兵机制 --前面先做好主从挂载
哨兵工作原理说明
1).当哨兵启动时,会监控当前的主机信息.同时获取链接当前主机的从机信息.
2).当哨兵利用心跳检测机制(PING-PONG),检验主机是否正常.如果连续3次发现主机没有响应信息.则开始进行选举.
3).当哨兵选举完成之后.其他的节点都会当做新主机的从.
1 复制哨兵配置文件
cp sentinel.conf sentinel

2 修改配置文件
- 修改保护模式
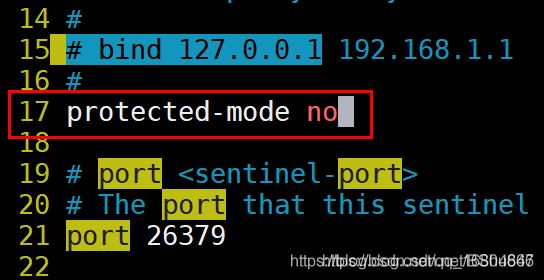
2).开启后台运行

3).修改哨兵的监控 其中的1表示投票生效的数量.

4).哨兵宕机之后的选举时间 --如果主机宕机10秒之后开始进行推选.

5).修改哨兵选举的超时时间

完成主从挂载后启动哨兵,实现了哨兵机制下的redis缓存高可用
测试
1).启动哨兵
redis-sentinel sentinel.conf
2).先关闭主机,之后等待10秒之后,检查从机是否当选主机.之后再次启动主机(宕机的),检查是否为新主机的从
关于哨兵选举平票的说明:
如果有多个哨兵进行选举,如果连续3次投票失败,可能引发脑裂现象的发生.
问题: 脑裂现象发生的概率是多大?? 1/8 = 12.5%
解决策略: 只要增加选举的节点的数量,可以有效的降低脑裂现象的发生. 概率论
引入哨兵的java代码就不写了 --没啥用,在最好用的还是RedisCluster
关于分片哨兵的总结说明
分片:
1.主要的作用实现内存数据的扩容.
2.由于运算发生在业务服务器中,所以执行的效率更高.
3.Redis的分片没有高可用的效果. 如果其中一个节点出现了问题则导致程序运行出错.
哨兵机制:
1.实现Redis高可用,当redis服务器发生宕机的现象时,哨兵可以灵活的监控.实现自动的选举实现 故障的迁移.
2.哨兵中所监控的redis节点中的数据都是相同的. 无法实现海量的数据存储.
3.哨兵虽然可以实现redis的高可用,但是由于哨兵的本身没有实现高可用.所以存在风险.
如果想要最大程度上减少损耗,则建议不要引入第三方的监控
RedisCluster集合了扩容和高可用功能
Redis集群搭建
主从划分: 3台主机 3台从机共6台 端口划分7000-7005
1 准备集群文件夹
Mkdir cluster
2.在cluster文件夹中分别创建7000-7005文件夹

3 复制配置文件
将redis根目录中的redis.conf文件复制到cluster/7000/ 并以原名保存 --修改一个,后面的五个都复制这一个即可
cp redis.conf cluster/7000/
4 编辑配置文件 – set nu 显示行
- 注释本地绑定IP地址

- 关闭保护模式

- 修改端口号

- 启动后台启动

- 修改pid文件

- 修改持久化文件路径

- 设定内存优化策略

- 关闭AOF模式
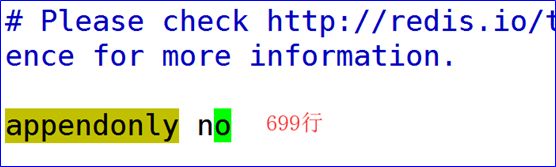
- 开启集群配置

- 开启集群配置文件

- 修改集群超时时间

5 复制修改后的配置文件
说明:将7000文件夹下的redis.conf文件分别复制到7001-7005中
[root@localhost cluster]# cp 7000/redis.conf 7001/
[root@localhost cluster]# cp 7000/redis.conf 7002/
[root@localhost cluster]# cp 7000/redis.conf 7003/
[root@localhost cluster]# cp 7000/redis.conf 7004/
[root@localhost cluster]# cp 7000/redis.conf 7005/
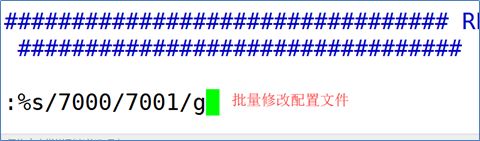
6 批量修改
说明:分别将7001-7005文件中的7000改为对应的端口号的名称,
修改时注意方向键的使用 --使用上键
:%s/7000/7001/g
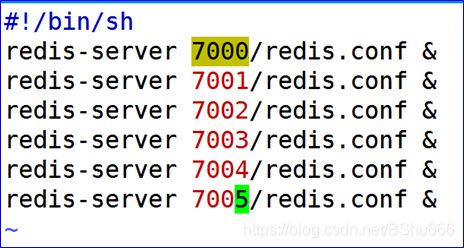
7 创建启动脚本
vim start.sh
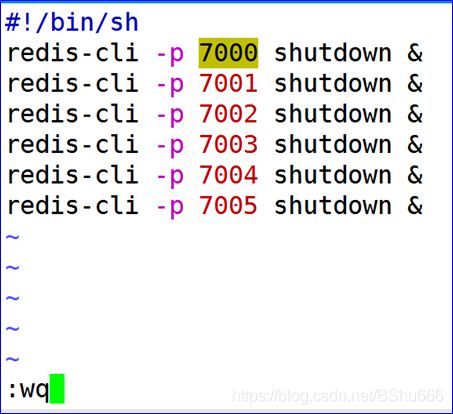
8 创建关闭的脚本
9 启动redis节点
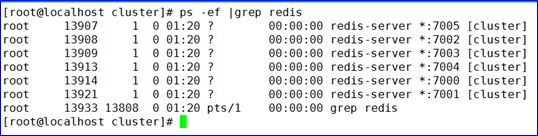
sh start.sh
10 检查redis节点启动是否正常
ps -ef | grep redis
11 核心步骤!!! --创建redis集群 --一行代码,中间不能有回车!!! 1代表一个主机有几台从机!!!
#5.0版本执行 使用C语言内部管理集群
redis-cli --cluster create --cluster-replicas 1 192.168.35.130:7000 192.168.35.130:7001 192.168.35.130:7002 192.168.35.130:7003 192.168.35.130:7004 192.168.35.130:7005
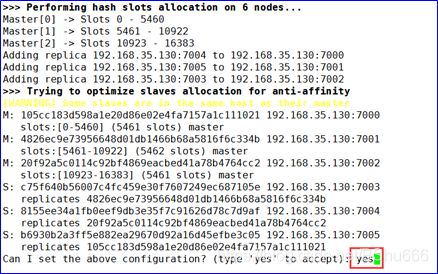

完成RedisCluster搭建!!!
redis集群高可用测试
1)检查redis主机的状态

2)将主机关闭
redis-cli -p 7000 shutdown
3)检查主机是否切换

4) 重启7000服务器.检查是否为7003的从

=============================
若搭建错误
- 关闭所有的Redis服务项
- 删除nodes.conf配置文件
由于搭建集群之后,所有的集群的信息都会写入nodes.conf文件中,如果下次重启会读取其中的配置信息实现redis集群的主从的搭建. 所以如果需要重新搭建集群,则必须删除该文件重新生成.
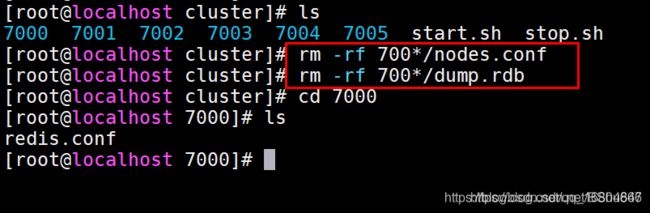
重启Redis服务器之后重新搭建集群 --中间不能有回车
redis-cli --cluster create --cluster-replicas 1 192.168.126.129:7000 192.168.126.129:7001 192.168.126.129:7002 192.168.126.129:7003 192.168.126.129:7004 192.168.126.129:7005
========================
Redis集群高可用测试
3. 关闭redis主机.检查是否自动实现故障迁移.
4. 再次启动关闭的主机.检查是否能够实现自动的挂载.
一般情况下 能够实现主从挂载
个别情况: 宕机后的节点重启,可能挂载到其他主节点中(7001-7002) 正确的
Redis集群原理说明
Redis的所有节点都会保存当前redis集群中的全部主从状态信息.并且每个节点都能够相互通信.当一个节点发生宕机现象.则集群中的其他节点通过PING-PONG检测机制检查Redis节点是否宕机.当有半数以上的节点认为宕机.则认为主节点宕机.同时由Redis剩余的主节点进入选举机制.投票选举链接宕机的主节点的从机.实现故障迁移.
Redis集群宕机条件
特点:集群中如果主机宕机,那么从机可以继续提供服务,
当主机中没有从机时,则向其它主机借用多余的从机(被借主机最少会保留一台从机不外借!!!).继续提供服务.如果主机宕机时没有从机可用,则集群崩溃.
示例:9个redis节点,节点宕机5-7次时集群才崩溃.–最少宕机5次(一直是一个节点宕机…) --原则: Redis的内存缺失则集群崩溃

Redis hash槽存储数据原理
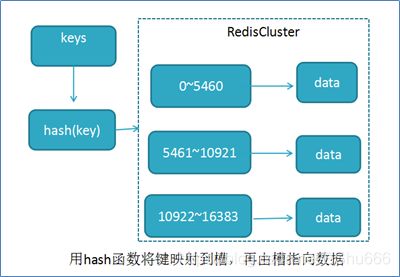
说明: RedisCluster采用此分区,所有的键根据哈希函数(CRC16[key]%16384)映射到0-16383槽内,共16384个槽位,每个节点维护部分槽及槽所映射的键值数据.根据主节点的个数,均衡划分区间.
算法:哈希函数: Hash()=CRC16[key]%16384
Redis集群中最多存储16384个key 错 –因为根据数据的key值哈希函数公式计算出的值可以是重复的,该值只是代表该key对应的value数据应存放的位置!!!
CRC16(KEY1)%16384 = 2000
CRC16(KEY2)%16384 = 2000
表示key1和key2都归节点1进行管理. 至于节点到底是否能够存储 由内存决定.
Redis集群中最多有多少个主机?? 16384台 --一般20台以内貌似就足够了…
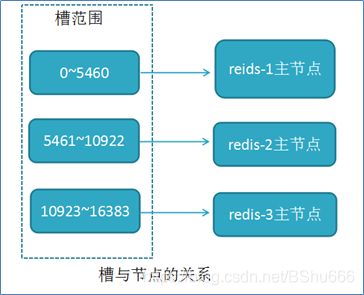
当向redis集群中插入数据时,首先将key进行计算.之后将计算结果匹配到具体的某一个槽的区间内,之后再将数据set到管理该槽的节点中.
Redis持久化策略说明 --定期将内存中的数据保存到磁盘中.
说明:Redis中的持久化方式主要有2种.
方式1: RDB模式 dump.rdb 默认的持久化方式
- RDB模式可以实现定期的持久化,但是可能导致数据丢失.
- **RDB模式作的是内存数据的快照,**并且后拍摄的快照会覆盖之前的快照.所以持久化文件较小.恢复数据的速度较快. 工作的效率较高.
命令:
用户可以通过命令要求redis进行持久化操作.
1). save 是同步操作 要求redis立即执行持久化操作. 用户可能会陷入阻塞状态.
2). bgsave 是异步操作, 开启单独的线程执行持久化操作. 持久化时不会影响用户的使用. 不能保证立即马上执行.
持久化策略说明:
LG: save 900 1 redis在900秒内执行一次set操作时则持久化一次.
用户操作越频繁则持久化的周期越短.

持久化目录: 可以执行持久化文件生成的位置 --最好别用当前目录 ./ 直接指定绝对路径
dir /usr/local/src/redis/cluster/7000
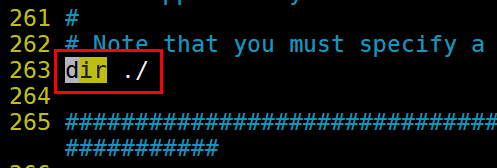
持久化文件名称的设定

方式2: AOF模式 appendonly.aof 默认关闭的需要手动的开启.
特点: - AOF模式默认的条件下是关闭状态,需要手动的开启.
- AOF模式记录的是用户的执行的状态.所以持久化文件占用空间相对较大.恢复数据的速度较慢.所以效率较低.
- 可以保证用户的数据尽可能不丢失.
配置:
1.开启AOF配置
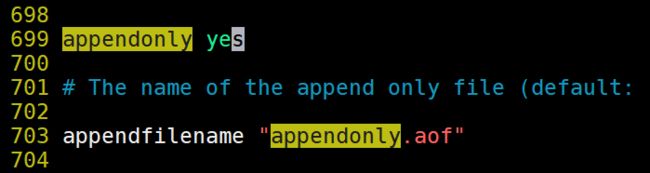
AOF模式的持久化策略
appendfsync always 如果用户执行的了一次set操作则持久化一次
appendfsync everysec aof每秒持久化一次
appendfsync no 不主动持久化.
关于RDB/AOF模式特点
1.如果用户可以允许少量的数据丢失可以选用RDB模式(快).
2.如果用户不允许数据丢失则选用AOF模式.
3.实际开发过程中一般2种方式都会配置. 一般主机开启RDB模式,从机开启AOF模式.
若不小心删除所有的redis缓存 --flushALL
解决方案: 应该将AOF模式中flushAll删除,之后重启redis即可.
Redis内存优化的说明 --LRU算法(最长时间未被使用的删),LFU算法(使用次数最少的删),Random算法(随机删…),TTL算法(设置了存活时间的,将存活时间最少的提前删)
Redis可以当做内存使用,但是如果一直往里存储不删除数据,则必然导致内存溢出.
1 LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的***数据***置换算法,选择最近最久未使用的***数据***予以淘汰。该算法赋予每个***数据***一个访问字段,用来记录一个***数据***自上次被访问以来所经历的时间 t,当须淘汰一个***数据***时,选择现有***数据***中其 t 值最大的,即最近最少使用的***数据***予以淘汰。
维度:时间T
LRU算法是当下实现内存清理的最优算法.
2 LFU算法
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
维度: 引用次数
3 Random算法
4 TTL算法
说明:监控剩余的存活时间,将存活时间少的数据提前删除.
Redis内存优化策略
1.volatile-lru 在设定了超时时间的数据中,采用lru算法.
2.allkeys-lru 所有数据采用lru算法
3.volatile-lfu 在超时的数据中采用lfu算法
4.allkeys-lfu -> 所有数据采用lfu算法
5.volatile-random -> 设定超时时间的数据采用随机算法
6.allkeys-random -> 所有数据随机删除
7.volatile-ttl -> 删除存活时间少的数据
8.noeviction -> 不会删除数据,如果内存溢出报错返回.
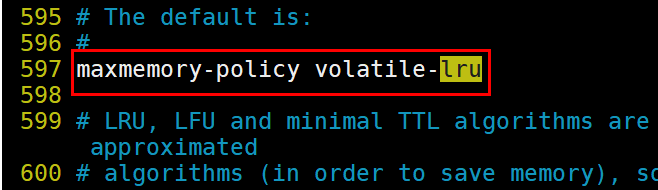
==============================
SpringBoot整合Redis集群
入门案例测试 --把redis集群代码写在上面了 --因为最常用,不懂的先看集群下面的代码分片和哨兵,一步步引入
/**
* jedisCluster 操作整个redis集群,链接redis的所有的节点 --RedisCluster集群需要HostSAndPort对象的set集合!!!
*/
@Test
public void testCluster(){
Set<HostAndPort> sets = new HashSet<>();
sets.add(new HostAndPort("192.168.126.129", 7000));
sets.add(new HostAndPort("192.168.126.129", 7001));
sets.add(new HostAndPort("192.168.126.129", 7002));
sets.add(new HostAndPort("192.168.126.129", 7003));
sets.add(new HostAndPort("192.168.126.129", 7004));
sets.add(new HostAndPort("192.168.126.129", 7005));
JedisCluster jedisCluster = new JedisCluster(sets);
jedisCluster.set("cluster", "集群测试");
System.out.println(jedisCluster.get("cluster"));
}
=====真正的RedisCluster集群项目代码
1 编辑properties配置文件
#添加redis的配置
#添加单台配置
#redis.host=192.168.126.129
#redis.port=6379
#配置Redis集群
redis.nodes=192.168.126.129:7000,192.168.126.129:7001,192.168.126.129:7002,192.168.126.129:7003,192.168.126.129:7004,192.168.126.129:7005
2 编辑配置类
@Configuration //标识我是一个配置类
@PropertySource("classpath:/properties/redis.properties")
public class JedisConfig {
@Value("${redis.nodes}")
private String nodes; //node,node,node
@Bean //实例化集群的对象之后交给Spring容器管理
public JedisCluster jedisCluster(){
Set<HostAndPort> set = new HashSet<>();
String[] nodeArray = nodes.split(",");
for(String node : nodeArray){ //host:port
String[] nodeTemp = node.split(":");
String host = nodeTemp[0];
int port = Integer.parseInt(nodeTemp[1]);
HostAndPort hostAndPort = new HostAndPort(host, port);
set.add(hostAndPort);
}
return new JedisCluster(set);
}
}
3 编辑CacheAOP缓存切面类注入RedisCluster对象
@Component //交给Spring容器管理
@Aspect //标识这是一个切面
public class CacheAOP{
//注入缓存redis对象 --RedisCluster
@Autowired
private JedisCluster jedis;
@Around("@annotation(cacheFind)")
public Object around(ProceedingJoinPoint joinPoint, CacheFind cacheFind){
//1.如何获取用户在注解中填写的内容呢??? 如何获取注解对象....
String key = cacheFind.key(); //前缀 ITEM_CAT_PARENTID
//2.如何获取目标对象的参数呢???
Object[] array = joinPoint.getArgs();
key += "::"+Arrays.toString(array); // "ITEM_CAT_PARENTID::[0]" //自己拼接一个标记key
//3.从redis中获取数据
Object result = null;
if(jedis.exists(key)){
//需要获取json数据之后,直接转化为对象返回!!
String json = jedis.get(key);
//如何获取返回值类型 --通过方法签名获得
MethodSignature methodSignature =(MethodSignature) joinPoint.getSignature();
Class targetClass = methodSignature.getReturnType();
result = ObjectMapperUtil.toObject(json,targetClass);
System.out.println("AOP实现缓存的查询!!!");
}else{
//key不存在,应该查询数据库
try {
result = joinPoint.proceed(); //执行目标方法,获取返回值结果
String json = ObjectMapperUtil.toJSON(result);
if(cacheFind.seconds()>0){ //判断是否需要超时时间
//将数据库查询的数据存入jedis中--后面直接把Jedis类型换成JedisCluster集群即可 --细节依赖于抽象!!其他的都不需要修改..
jedis.setex(key, cacheFind.seconds(), json);
}else{
jedis.set(key,json);
}
System.out.println("AOP执行数据库操作!!!");
} catch (Throwable throwable) {
throwable.printStackTrace();
//一般都需要将"检查"异常转化为运行异常!!
throw new RuntimeException(throwable);
}
}
return result;
}
}
}
4 自定义注解 --需要执行缓存操作的方法上加上该注解即可实现缓存功能!!!
@Retention(RetentionPolicy.RUNTIME) //该注解什么时候有效
@Target({ElementType.METHOD}) //对方法有效
public @interface CacheFind {
String key(); //该属性为必须添加
int seconds() default 0; //设定超时时间 默认不超时
}
5 示例: 商品列表分类实现缓存处理 --有了AOP切面直接加注解即可实现缓存… --直接在controller上加注解貌似能提升一点性能比在service上加的
**
* 分析业务: 通过itemCatId获取商品分类的名称
* 1.url地址: url:"/item/cat/queryItemName",
* 2.参数: {itemCatId:val},
* 3.返回值: 商品分类名称 String
*/
@RequestMapping("/queryItemName")
@CacheFind(key="ITEM_CAT_NAME")
public String findItemCatName(Long itemCatId){
return itemCatService.findItemCatNameById(itemCatId);
}
==================================
SpringBoot整合redis
1 pom.xml中加入依赖
<!--spring整合redis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
</dependency>
2.测试代码 --正式项目配好redis集群将host及port写入配置类中
package com.jt.test;
//@SpringBootTest //如果需要在测试类中引入spring容器机制才使用该注解
public class TestRedis {
/**
* 测试远程redis服务器是否可用
* host: 192.168.126.129
* port: 6379
* 思路:
* 1.实例化链接对象
* 2.利用对象执行redis命令
*
* 报错调试:
* 1.检查Redis.conf的配置文件是否按照要求修改 ip/保护/后台
* 2.redis启动方式 redis-server redis.conf
* 3.关闭防火墙 systemctl stop firewalld.service
* */
@Test
public void test01(){
Jedis jedis = new Jedis("192.168.126.129",6379);
jedis.set("redis", "测试redis是否可用");
System.out.println(jedis.get("redis"));
}
/**
* String类型API学习
* 需求: 判断key是否存在于Redis.如果存在则不赋值,否则入库.
*/
@Test
public void test02(){
Jedis jedis = new Jedis("192.168.126.129",6379);
if(jedis.exists("redis")){
System.out.println("数据已存在");
jedis.expire("redis", 10);
}else{
jedis.set("redis", "aaaa");
}
System.out.println(jedis.get("redis"));
}
//可以利用优化的API实现业务功能.
//业务: 如果数据存在则不赋值
@Test
public void test03(){
Jedis jedis = new Jedis("192.168.126.129",6379);
jedis.flushAll(); //清空redis服务器
// 如果key存在则不做任何操作
jedis.setnx("redis", "测试赋值操作!!!");
System.out.println(jedis.get("redis"));
}
/**
* 测试添加超市时间的有效性.
* 业务: 向redis中保存一个数据之后,要求设定10秒有效.
* 原子性: 要么同时成功,要么同时失败.
*/
@Test
public void test04(){
Jedis jedis = new Jedis("192.168.126.129",6379);
/* jedis.set("aa", "aa"); //该数据将永不删除.
int a = 1/0;
jedis.expire("aa", 10);*/
jedis.setex("aa", 10, "aa"); //单位秒
//jedis.psetex(, ); //设置毫秒
}
/**
* 需求: 要求添加一个数据,只有数据存在时才会赋值,并且需要添加超时时间
* 保证原子性操作.
* private static final String XX = "xx"; 有key的时候才赋值
* private static final String NX = "nx"; 没有key时才赋值
* private static final String PX = "px"; 毫秒
* private static final String EX = "ex"; 秒
* redis分布式锁的问题
* */
@Test
public void test05(){
Jedis jedis = new Jedis("192.168.126.129",6379);
SetParams setParams = new SetParams();
setParams.xx().ex(10);
jedis.set("aaa", "aaa", setParams);
}
@Test
public void testList(){
Jedis jedis = new Jedis("192.168.126.129",6379);
jedis.lpush("list2", "1,2,3,4,5");
System.out.println(jedis.rpop("list2"));
}
/**
* 控制redis事务
* 说明:操作redisredis适用于事务控制
* 但是如果是多台redis则不太适用事务.
* */
@Test
public void testTx(){
Jedis jedis = new Jedis("192.168.126.129",6379);
//开启事务
Transaction transaction = jedis.multi();
try {
transaction.set("bb", "bb");
transaction.exec(); //提交事务
}catch (Exception e){
transaction.discard();
}
}
}
3 redis 稍微正式点的用法 --将对象存入redis缓存中,redis中存k-v 并且v是String类型的
通过Json来转换–json本质是字符串
–总结: 对象转换为json串,将json串存入redis缓存中
将redis缓存中json串取出,将json串转化为对象
1)编辑配置文件
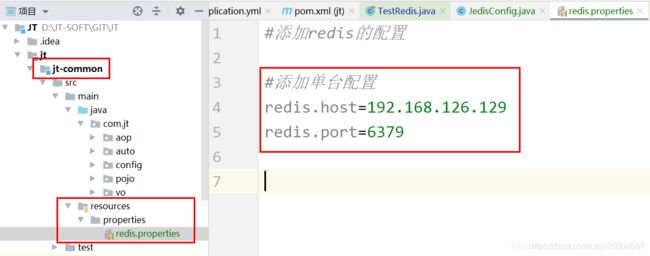
2)编辑配置类
package com.jt.config;
@Configuration //标识我是一个配置类
@PropertySource("classpath:/properties/redis.properties")
public class JedisConfig {
@Value("${redis.host}")
private String host;
@Value("${redis.port}")
private Integer port;
/**
* 将jedis对象交给spring容器管理
*/
@Bean
public Jedis jedis(){
//由于将代码写死不利于扩展,所以将固定的配置添加到配置文件中
return new Jedis(host,port);
}
}
- 对象与JSON之间相互转化 --同过ObjecrMapper对象的writeValueAsString()和readValue()方法实现
package com.jt.test;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.jt.pojo.ItemDesc;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class ObjectMapperTest {
//实现对象与JSON之间的转化
//任务: 对象转化为json
@Test
public void test01(){ ***//单个对象形式的转化 类型直接用类名.class获取即可!!***
ObjectMapper objectMapper = new ObjectMapper();
ItemDesc itemDesc = new ItemDesc();
itemDesc.setItemId(100L).setItemDesc("json测试")
.setCreated(new Date()).setUpdated(new Date());
try {
//1.将对象转化为json
String result = objectMapper.writeValueAsString(itemDesc);
System.out.println(result);
//2.将json数据转化为对象 只能通过反射机制..
//给定xxx.class类型 之后实例化对象.利用对象的get/set方法为属性赋值.
ItemDesc itemDesc2 = objectMapper.readValue(result,ItemDesc.class);
System.out.println(itemDesc2.toString());
System.out.println(itemDesc2.getCreated());
} catch (JsonProcessingException e) {
e.printStackTrace();
}
}
@Test
public void test02(){ ***//List集合形式的对象转化 类型用.getClass()获取***
ObjectMapper objectMapper = new ObjectMapper();
ItemDesc itemDesc = new ItemDesc();
itemDesc.setItemId(100L).setItemDesc("json测试")
.setCreated(new Date()).setUpdated(new Date());
List<ItemDesc> list = new ArrayList<>();
list.add(itemDesc);
list.add(itemDesc);
//1.将对象转化为JSON
try {
String json = objectMapper.writeValueAsString(list);
System.out.println(json);
//2.json转化为对象
List<ItemDesc> list2 = objectMapper.readValue(json, list.getClass());
System.out.println(list2);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
}
}
4)为了降低工具API ObjectMapper中的异常处理等繁琐代码每次都要写,直接准备一些工具API简化代码的调用.
说明:在jt-common(通用项目中)中添加工具API对象
package com.jt.util;
public class ObjectMapperUtil {
//定义常量对象
// 优势1: 对象独一份节省空间
// 优势2: 对象不允许别人随意篡改
private static final ObjectMapper MAPPER = new ObjectMapper();
/**
* 1.将任意对象转化为JSON
* 思考1: 任意对象对象应该使用Object对象来接
* 思考2: 返回值是JSON串 所以应该是String
* 思考3: 使用什么方式转化JSON FASTJSON/objectMapper
*/
public static String toJSON(Object object){
try {
if(object == null){
throw new RuntimeException("传递的参数object为null,请认真检查");
}
return MAPPER.writeValueAsString(object);
} catch (JsonProcessingException e) {
e.printStackTrace();
//应该将检查异常,转化为运行时异常.
throw new RuntimeException("传递的对象不支持json转化/检查是否有get/set方法");
}
}
//2.将任意的JSON串转化为对象 传递什么类型转化什么对象
public static <T> T toObject(String json,Class<T> target){
if(StringUtils.isEmpty(json) || target == null){
throw new RuntimeException("传递的参数不能为null");
}
try {
return MAPPER.readValue(json,target);
} catch (JsonProcessingException e) {
e.printStackTrace();
throw new RuntimeException("json转化异常");
}
}
}
5)项目小试 实现商品分类的缓存
编辑ItemCatController
/**
* 关于缓存实现业务说明
* 1.应该查询缓存
* 2.判断缓存中是否有数据
* 3.如果没有数据,则查询数据库
* 4.如果有数据,则直接返回数据.
*/
@RequestMapping("/list")
public List<EasyUITree> findItemCatList(Long id){
//当初始时树形结构没有加载不会传递ID,所以ID为null.只需要传递0.
Long parentId = (id==null)?0:id;
return itemCatService.findItemCache(parentId);
}
编辑ItemCatService
/**
* 步骤:
* 先查询Redis缓存 K:V
* true 直接返回数据
* false 查询数据库
* KEY有什么特点: 1.key应该动态变化 2.key应该标识业务属性
* key=ITEM_CAT_PARENTID::parentId
*/
@Override
public List<EasyUITree> findItemCache(Long parentId) {
//0.定义空集合
List<EasyUITree> treeList = new ArrayList<>();
String key = "ITEM_CAT_PARENTID::"+parentId;
//1.从缓存中查询数据
String json = jedis.get(key);
//2.校验JSON中是否有值.
if(StringUtils.isEmpty(json)){
//3.如果缓存中没有数据,则查询数据库 --调用前面写好的查询方法
treeList = findItemCatList(parentId);
//4.为了实现缓存处理应该将数据添加到redis中.
//将数据转化为json结构,保存到redis中
json = ObjectMapperUtil.toJSON(treeList);
jedis.set(key, json);
System.out.println("第一次查询数据库,并将数据存入redis缓存中了!!!!");
}else{
//标识程序有值 将json数据转化为对象即可
treeList = ObjectMapperUtil.toObject(json,treeList.getClass());
System.out.println("查询Redis缓存服务器成功,不需要查数据库了,见笑了数据库压力!!!!");
}
return treeList;
}
前面是原理性的代码引入 正式项目代码
1 AOP实现Redis缓存服务
AOP:面向切面编程.
一句话总结: 在不改变原有代码的条件下,对功能进行扩展. --实现代码的复用,降低代码的耦合性
专业术语:
1.切入点: 能够进入切面的一个判断 一个if判断
2.连接点: 在执行正常的业务过程中满足了切入点表达式时进入切面的点.(织入) 多个
3.通知: 在切面中执行的具体的业务(扩展) 方法
4.目标方法: 将要执行的真实的业务逻辑.
环绕通知around: 在目标方法执行前后都要执行的通知方法. 控制目标方法是否执行.功能最为强大.其他四大通知不能控制目标方法执行,貌似只是用来记录程序的执行状态
连接点必须位于通知的参数的第一位.

关于JoinPoint方法说明
@Before("@annotation(com.jt.anno.CacheFind)")
public void before(JoinPoint joinPoint){
Object target = joinPoint.getTarget(); //获取目标对象 --这是个对象
Object[] args = joinPoint.getArgs(); //获取方法参数的 --这是目标方法上的参数
String targetName = joinPoint.getSignature().getDeclaringTypeName(); //获取目标对象的名称 --这是获取目标对象的签名(若是方法就是强转为MethodSignature方法签名)后再获取该对象的类型的名称 --仅仅是个字符串名称
Class targetClass = joinPoint.getSignature().getDeclaringType(); //获取目标对象的类型 --这个真正获取到目标对象的类型
String methodName = joinPoint.getSignature().getName(); //获取目标方法的名称 --前面那个是获取到目标对象的类型的名字,这个是真正获取到方法的名字(貌似是方法的时候强转为MethodSignature即可!!..)
}
切入点表达式说明 --四种表达式都是在(" … … “) 括号引号里面@Pointcut(”…") 或者直接在通知注解里@Around("…")
bean(bean的id) 类名首字母小写 匹配1个类
@Pointcut(value = “bean(itemCatServiceImpl)”)
within(包名.类名) 按包路径匹配类 匹配多个类
@Pointcut(“within(com.jt.service…*)”) //…点点貌似表示所有
上述表达式是粗粒度的控制,按类匹配.
execution(返回值类型 包名.类名.方法名(参数列表))
@Pointcut(“execution(* com.jt.service….(…))”) //拦截com.jt.service下的所有类的所有方法的任意参数类型
public void pointcut(){ }
@Before(“pointcut()”)
public void before(){ System.out.println(“我是前置通知”); }
@annotation(包名.注解名) 按注解进行拦截.
@Around("@annotation(cacheFind)") //不用@Pointcut注解直接将切入点写到通知注解里也可以
开始项目代码
1 自定义注解
@Retention(RetentionPolicy.RUNTIME) //该注解什么时候有效
@Target({ElementType.METHOD}) //对方法有效
public @interface CacheFind {
String key(); //该属性为必须添加
int seconds() default 0; //设定超时时间 默认不超时
}
2 编辑CacheAOP --AOP类必须加注解@Aspect !!!
package com.jt.aop;
@Component //将对象交给spring容器管理
@Aspect //标识我是一个切面
public class CacheAOP {
//1.注入缓存redis对象
@Autowired
private Jedis jedis; //后面直接把Jedis类型换成JedisCluster集群即可 --细节依赖于抽象!!其他的都不需要修改..
/**
* 拦截@CacheFind注解标识的方法.
* 通知选择: 缓存的实现应该选用环绕通知
* 步骤:
* 1.动态生成key 用户填写的key+用户提交的参数
*/
@Around("@annotation(cacheFind)")
public Object around(ProceedingJoinPoint joinPoint, CacheFind cacheFind){
//1.如何获取用户在注解中填写的内容呢??? 如何获取注解对象....
String key = cacheFind.key(); //前缀 ITEM_CAT_PARENTID
//2.如何获取目标对象的参数呢???
Object[] array = joinPoint.getArgs();
key += "::"+Arrays.toString(array); // "ITEM_CAT_PARENTID::[0]" //自己拼接一个标记key
//3.从redis中获取数据
Object result = null;
if(jedis.exists(key)){
//需要获取json数据之后,直接转化为对象返回!!
String json = jedis.get(key);
//如何获取返回值类型 --通过方法签名获得
MethodSignature methodSignature =(MethodSignature) joinPoint.getSignature();
Class targetClass = methodSignature.getReturnType();
result = ObjectMapperUtil.toObject(json,targetClass);
System.out.println("AOP实现缓存的查询!!!");
}else{
//key不存在,应该查询数据库
try {
result = joinPoint.proceed(); //执行目标方法,获取返回值结果
String json = ObjectMapperUtil.toJSON(result);
if(cacheFind.seconds()>0){ //判断是否需要超时时间
//将数据库查询的数据存入jedis中--后面直接把Jedis类型换成JedisCluster集群即可 --细节依赖于抽象!!其他的都不需要修改..
jedis.setex(key, cacheFind.seconds(), json);
}else{
jedis.set(key,json);
}
System.out.println("AOP执行数据库操作!!!");
} catch (Throwable throwable) {
throwable.printStackTrace();
//一般都需要将"检查"异常转化为运行异常!!
throw new RuntimeException(throwable);
}
}
return result;
}
}
3 商品列表分类实现缓存处理 --有了AOP切面直接加注解即可实现缓存…
**
* 分析业务: 通过itemCatId获取商品分类的名称
* 1.url地址: url:"/item/cat/queryItemName",
* 2.参数: {itemCatId:val},
* 3.返回值: 商品分类名称 String
*/
@RequestMapping("/queryItemName")
@CacheFind(key="ITEM_CAT_NAME")
public String findItemCatName(Long itemCatId){
return itemCatService.findItemCatNameById(itemCatId);
}
===================================
redis 命令集
1 String类型
set a a
get a
strlen a
exists a
返回1存在 0不存在
del a
Keys * 查询redis中全部的key
keys n?me 使用占位符获取数据
keys nam* 获取nam开头的数据
mset 赋值多个key-value mset key1 value1 key2 value2 key3 value3
mget 获取多个key的值 mget key1 key2
append 对某个key的值进行追加 append key value
type 检查某个key的类型 type key
select 切换redis数据库 select 0-15 redis中共有16个数据库
flushdb 清空单个数据库 flushdb
flushall 清空全部数据库 flushall
incr 自动加1 incr key
decr 自动减1 decr key
incrby 指定数值添加 incrby 10
decrby 指定数值减 decrby 10
expire 指定key的生效时间 单位秒 expire key 20
key20秒后失效
pexpire 指定key的失效时间 单位毫秒 pexpire key 2000
key 2000毫秒后失效
ttl 检查key的剩余存活时间 ttl key -2数据不存在 -1该数据永不超时
persist 撤销key的失效时间 persist key
2 Hash类型
说明:可以用散列类型保存对象和属性值
例子:User对象{id:2,name:小明,age:19}
命令 说明 案例
hset 为对象添加数据 hset key field value
hget 获取对象的属性值 hget key field
hexists 判断对象的属性是否存在 HEXISTS key field
1表示存在 0表示不存在
hdel 删除hash中的属性 hdel user field [field …]
hgetall 获取hash全部元素和值 HGETALL key
hkyes 获取hash中的所有字段 HKEYS key
hlen 获取hash中所有属性的数量 hlen key
hmget 获取hash里面指定字段的值 hmget key field [field …]
hmset 为hash的多个字段设定值 hmset key field value [field value …]
hsetnx 设置hash的一个字段,只有当这个字段不存在时有效 HSETNX key field value
hstrlen 获取hash中指定key的值的长度 HSTRLEN key field
hvals 获取hash的所有值 HVALS user
3 List类型
说明:Redis中的List集合是双端循环列表,分别可以从左右两个方向插入数据.
List集合可以当做队列使用,也可以当做栈使用
队列:存入数据的方向和获取数据的方向相反
栈:存入数据的方向和获取数据的方向相同
命令 说明 案例
lpush 从队列的左边入队一个或多个元素 LPUSH key value [value …]
rpush 从队列的右边入队一个或多个元素 RPUSH key value [value …]
lpop 从队列的左端出队一个元素 LPOP key
rpop 从队列的右端出队一个元素 RPOP key
lpushx 当队列存在时从队列的左侧入队一个元素 LPUSHX key value
rpushx 当队列存在时从队列的右侧入队一个元素 RPUSHx key value
lrange 从列表中获取指定返回的元素 LRANGE key start stop
Lrange key 0 -1 获取全部队列的数据
lrem 从存于 key 的列表里移除前 count 次出现的值为 value 的元素。 这个 count 参数通过下面几种方式影响这个操作:
• count > 0: 从头往尾移除值为 value 的元素。
• count < 0: 从尾往头移除值为 value 的元素。
• count = 0: 移除所有值为 value 的元素。 LREM list -2 “hello” 会从存于 list 的列表里移除最后两个出现的 “hello”。
需要注意的是,如果list里没有存在key就会被当作空list处理,所以当 key 不存在的时候,这个命令会返回 0。
Lset 设置 index 位置的list元素的值为 value LSET key index value
4 Redis事务命令
说明:redis中操作可以添加事务的支持.一项任务可以由多个redis命令完成,如果有一个命令失败导致入库失败时.需要实现事务回滚.
命令 说明 案例
multi 标记一个事务开始 127.0.0.1:6379> MULTI
OK
exec 执行所有multi之后发的命令 127.0.0.1:6379> EXEC
OK
discard 丢弃所有multi之后发的命令
2 Redis高级应用
入门案例-List
@Test
public void test02(){
Jedis jedis = new Jedis(“192.168.126.148”, 6379);
Long number = jedis.lpush(“list”, “a”,“b”,“c”,“d”,“e”);
System.out.println(“获取数据”+number);
List list= jedis.lrange(“list”, 0, -1);
System.out.println(“获取参数:”+list);
}
结果展现:
获取数据5
获取参数:[e, d, c, b, a]