在Amazon EKS上部署Zeppelin和Spark分析平台

Apache Spark是用于大规模数据处理的统一分析引擎。它提供了Java、Scala、Python和R的高级API。Amazon EKS是一项托管服务,借助该服务,您可以轻松在亚马逊云科技上运行 Kubernetes,而无需安装和操作您自己的 Kubernetes 控制平面或工作线程节点。从Apache Spark 2.3.0开始,您可以在Kubernetes上运行和管理Spark任务,在Spark 3.1版本Spark on Kubernetes正式GA。Apache Zeppelin是一个让交互式数据分析变得可行的基于网页的开源框架。Zeppelin提供了数据分析、数据可视化等功能。
本文介绍在Amazon EKS部署Apache Zeppelin和Apache Spark,数据科学家可以使用Zeppelin轻松在Amazon EKS集群中运行Spark分析任务,借助Amazon EKS提供的托管Kubernetes集群实现按需弹性的数据分析平台。
01
前提条件
Spark版本2.3及以上
Kubernetes版本 >= 1.6
Zeppelin >= 0.9.0
具备Kubernetes集群中 list、create、 edit 、delete Pod的权限
Kubernetes集群已经安装Kubernetes DNS
02
方案概述
本方案将在Amazon EKS上部署Apache Zeppelin和Apache Spark,在Amazon ECR中存储Zeppelin和Spark的镜像,以加速镜像的加载速度。使用Amazon S3持久化存储Zeppelin Notebook文件,同时Amazon S3也作为数据分析的存储,存放需要分析的海量数据。

03
操作步骤
01 创建Amazon EKS集群
本次采用的是Amazon EKS 1.19版本,详细步骤可以参考官方文档:
https://docs.aws.amazon.com/zh_cn/eks/latest/userguide/create-cluster.html
02 在Amazon ECR中创建Repository
aws ecr create-repository \
--repository-name spark \
--image-scanning-configuration scanOnPush=true \
--region ap-southeast-1
aws ecr create-repository \
--repository-name spark-py \
--image-scanning-configuration scanOnPush=true \
--region ap-southeast-1
aws ecr get-login-password --region ap-southeast-1 | docker login --username AWS --password-stdin 123456789012.dkr.ecr.ap-southeast-1.amazonaws.com*左滑查看更多
03 构建Spark Image并推送到Amazon ECR
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
gunzip spark-3.1.2-bin-hadoop3.2.tgz
wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.2.0/hadoop-aws-3.2.0.jar
wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/1.11.375/aws-java-sdk-bundle-1.11.375.jar
mv aws-java-sdk-bundle-1.11.375.jar ./jars
mv hadoop-aws-3.2.0.jar ./jars
./bin/docker-image-tool.sh -r 123456789012.dkr.ecr.ap-southeast-1.amazonaws.com -t 3.1.2 -p ./kubernetes/dockerfiles/spark/bindings/python/Dockerfile build
./bin/docker-image-tool.sh -r 123456789012.dkr.ecr.ap-southeast-1.amazonaws.com -t 3.1.2 -p ./kubernetes/dockerfiles/spark/bindings/python/Dockerfile push*左滑查看更多
04 在Amazon EKS集群中创建自定义的Service Account和对应权限
kubectl create namespace spark
kubectl create serviceaccount spark -n spark
kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=spark:spark --namespace=spark*左滑查看更多
05 使用Spark-Submit提交测试作业
./bin/spark-submit \
--master k8s://https://4C782E5D25995AE719BAA19EAA82F5xx.gr7.ap-southeast-1.eks.amazonaws.com \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.namespace=spark \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--conf spark.kubernetes.container.image=123456789012.dkr.ecr.ap-southeast-1.amazonaws.com/spark:3.1.2 \
local:///opt/spark/examples/jars/spark-examples_2.12-3.1.2.jar*左滑查看更多
其中master修改成Amazon EKS的API server地址,spark.kubernetes.container.image, 修改成步骤3中构建的image的地址
06 在Amazon EKS中查看作业运行状态

我们可以看到,Amazon EKS中会先生成Spark的Driver Pod,然后Driver Pod调度起executor Pod,最终完成计算作业后,executor Pod自动终止,Driver Pod处于Completed状态,需要被EKS自动回收或手工清理。
可以通过查看Driver Pod的日志查看作业运行状态
kubectl logs spark-pi-49f9147c00b0f8c7-driver -n spark*左滑查看更多

可以看到我们提交的example作业成功运行。
07 安装Amazon-Load-Balancer-Controller
因为后面部署zeppline需要借助ingress发布zeppelin UI提供给外部访问,所以这里我们选用Amazon-Load-Balancer-Controller,具体安装步骤可以参考如下链接:
https://kubernetes-sigs.github.io/aws-load-balancer-controller/v2.2/deploy/configurations/
08 安装Apache Zeppelin Notebook
为了能过让镜像快速加载,我们可以选择将Zeppelin镜像推送到Amazon ECR中。
#创建repository并将需要的image推送到Amazon ECR中
aws ecr create-repository \
--repository-name zeppelin \
--image-scanning-configuration scanOnPush=true \
--region ap-southeast-1
docker pull apache/zeppelin:0.10.0
docker tag apache/zeppelin:0.10.0 123456789012.dkr.ecr.ap-southeast-1.amazonaws.com/zeppelin:0.10.0
docker push 123456789012.dkr.ecr.ap-southeast-1.amazonaws.com/zeppelin:0.10.0
#下载zeppelin server的yaml文件
curl -s -O https://raw.githubusercontent.com/apache/zeppelin/master/k8s/zeppelin-server.yaml*左滑查看更多
完成zeppelin server的yaml文件下载后,我们需要修改zeppelin-server.yaml文件,修改内容包括修改:
修改ConfigMap类型zeppelin-server-conf-map中的SERVICE_DOMAIN地址,填入我们自己的域名地址,方便后面通过自定义DNS访问zeppelin UI,例如zeppelin.domain.com
修改ConfigMap类型zeppelin-server-conf-map中的ZEPPELIN_K8S_SPARK_CONTAINER_IMAGE,填入Spark Image镜像地址,例如:123456789012.dkr.ecr.ap-southeast-1.amazonaws.com/spark:3.1.2
修改ConfigMap类型zeppelin-server-conf-map中的ZEPPELIN_K8S_CONTAINER_IMAGE,填入zeppelin server的Image镜像地址,例如123456789012.dkr.ecr.ap-southeast-1.amazonaws.com/zeppelin:0.10.0
修改ConfigMap类型zeppelin-server-conf-map,增加zeppelin-site.xml配置,设置的参数包括:设置参数将Notebook持久化保存在S3中,连接超时时间设置,interpreter闲置回收策略等
修改Deployment类型zeppelin-server的image配置,指向到ECR的镜像地址,例如:123456789012.dkr.ecr.ap-southeast-1.amazonaws.com/zeppelin:0.10.0
增加ingress配置,以发布zeppelin UI给到外部访问
zeppelin-server.yaml修改部分的配置参考如下(下文内容只是列名了修改部分的内容,其他部分参考下载的原始文件)
apiVersion: v1
kind: ConfigMap
metadata:
name: zeppelin-server-conf-map
data:
SERVICE_DOMAIN: zeppelin.domain.com
ZEPPELIN_K8S_SPARK_CONTAINER_IMAGE: 123456789012.dkr.ecr.ap-southeast-1.amazonaws.com/spark:3.1.2
ZEPPELIN_K8S_CONTAINER_IMAGE: 123456789012.dkr.ecr.ap-southeast-1.amazonaws.com/zeppelin:0.10.0
ZEPPELIN_HOME: /opt/zeppelin
ZEPPELIN_SERVER_RPC_PORTRANGE: 12320:12320
SPARK_MASTER: k8s://https://kubernetes.default.svc
SPARK_HOME: /spark
zeppelin-site.xml: |-
zeppelin.interpreter.connect.timeout
300000
Interpreter process connect timeout in msec.
zeppelin.interpreter.output.limit
10240000
Output message from interpreter exceeding the limit will be truncated
zeppelin.interpreter.lifecyclemanager.class
org.apache.zeppelin.interpreter.lifecycle.TimeoutLifecycleManager
LifecycleManager class for managing the lifecycle of interpreters, by default interpreter will
be closed after timeout
zeppelin.interpreter.lifecyclemanager.timeout.checkinterval
600000
Milliseconds of the interval to checking whether interpreter is time out
zeppelin.interpreter.lifecyclemanager.timeout.threshold
10800000
Milliseconds of the interpreter timeout threshold, by default it is 1 hour
zeppelin.notebook.s3.bucket
your_bucket
bucket name for notebook storage
zeppelin.notebook.s3.user
zeppelin
user name for s3 folder structure
zeppelin.notebook.storage
org.apache.zeppelin.notebook.repo.S3NotebookRepo
notebook persistence layer implementation
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: zeppelin-server
labels:
app.kubernetes.io/name: zeppelin-server
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: zeppelin-server
strategy:
type: RollingUpdate
template:
metadata:
labels:
app.kubernetes.io/name: zeppelin-server
spec:
serviceAccountName: zeppelin-server
volumes:
- name: nginx-conf
configMap:
name: zeppelin-server-conf
items:
- key: nginx.conf
path: nginx.conf
- name: zeppelin-server-conf-map
configMap:
name: zeppelin-server-conf-map
items:
- key: zeppelin-site.xml
path: zeppelin-site.xml
containers:
- name: zeppelin-server
image: 123456789012.dkr.ecr.ap-southeast-1.amazonaws.com/zeppelin:0.10.0
command:
- "sh"
- "-c"
- >
cp /tmp/zeppelin-site.xml /opt/zeppelin/conf/;
$(ZEPPELIN_HOME)/bin/zeppelin.sh
lifecycle:
preStop:
exec:
# SIGTERM triggers a quick exit; gracefully terminate instead
command: ["sh", "-c", "ps -ef | grep org.apache.zeppelin.server.ZeppelinServer | grep -v grep | awk '{print $2}' | xargs kill"]
ports:
- name: http
containerPort: 8080
- name: https
containerPort: 8443
- name: rpc
containerPort: 12320
env:
- name: POD_UID
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.uid
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
envFrom:
- configMapRef:
name: zeppelin-server-conf-map
volumeMounts:
- name: zeppelin-server-conf-map
mountPath: /tmp/zeppelin-site.xml
subPath: zeppelin-site.xml
# volumeMounts:
# - name: zeppelin-server-notebook-volume # configure this to persist notebook
# mountPath: /zeppelin/notebook
# - name: zeppelin-server-conf # configure this to persist Zeppelin configuration
# mountPath: /zeppelin/conf
# - name: zeppelin-server-custom-k8s # configure this to mount customized Kubernetes spec for interpreter
# mountPath: /zeppelin/k8s
- name: zeppelin-server-gateway
image: nginx:1.14.0
command: ["/bin/sh", "-c"]
env:
- name: SERVICE_DOMAIN
valueFrom:
configMapKeyRef:
name: zeppelin-server-conf-map
key: SERVICE_DOMAIN
args:
- cp -f /tmp/conf/nginx.conf /etc/nginx/nginx.conf;
sed -i -e "s/SERVICE_DOMAIN/$SERVICE_DOMAIN/g" /etc/nginx/nginx.conf;
sed -i -e "s/NAMESPACE/$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace)/g" /etc/nginx/nginx.conf;
cat /etc/nginx/nginx.conf;
/usr/sbin/nginx
volumeMounts:
- name: nginx-conf
mountPath: /tmp/conf
lifecycle:
preStop:
exec:
# SIGTERM triggers a quick exit; gracefully terminate instead
command: ["/usr/sbin/nginx", "-s", "quit"]
- name: dnsmasq # nginx requires dns resolver for dynamic dns resolution
image: "janeczku/go-dnsmasq:release-1.0.5"
args:
- --listen
- "127.0.0.1:53"
- --default-resolver
- --append-search-domains
- --hostsfile=/etc/hosts
- --verbose
---
kind: Service
apiVersion: v1
metadata:
name: zeppelin-server
spec:
ports:
- name: http
port: 80
targetPort: 80
- name: rpc # port name is referenced in the code. So it shouldn't be changed.
port: 12320
targetPort: 12320
type: ClusterIP
selector:
app.kubernetes.io/name: zeppelin-server
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: "ingress-zeppelin-server"
annotations:
kubernetes.io/ingress.class: "alb"
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
labels:
app: zeppelin-server
spec:
rules:
- http:
paths:
- path: /*
backend:
serviceName: "zeppelin-server"
servicePort: 80*左滑查看更多
创建完成后,我们修改DNS配置,将自定义域名CNAME到新创建出来的ingress-zeppelin-server对应的ALB的DNS地址,如图中显示的:k8s-spark-ingressz-1785ba8d10-1219796319.ap-southeast-1.elb.amazonaws.com

修改完DNS配置后,我们可以通过前面配置的域名登陆Zeppelin UI,http://zeppelin.zeppelin.domain.com/#/

默认情况下,Zeppelin使用的是匿名anonymous账户登陆,如果想对权限进行控制,可以设置shiro,我们修改zeppelin-server-conf-map的configmap中增加shiro.ini配置信息,并且在zeppelin-site.xml中禁止匿名登陆,参考:
apiVersion: v1
kind: ConfigMap
metadata:
name: zeppelin-server-conf-map
data:
shiro.ini: |-
[users]
admin = admin, admin
[main]
sessionManager = org.apache.shiro.web.session.mgt.DefaultWebSessionManager
cookie = org.apache.shiro.web.servlet.SimpleCookie
cookie.name = JSESSIONID
cookie.httpOnly = true
sessionManager.sessionIdCookie = $cookie
securityManager.sessionManager = $sessionManager
securityManager.sessionManager.globalSessionTimeout = 86400000
shiro.loginUrl = /api/login
[roles]
admin = *
[urls]
/api/version = anon
/api/cluster/address = anon
/api/interpreter/setting/restart/** = authc
/api/interpreter/** = authc, roles[admin]
/api/notebook-repositories/** = authc, roles[admin]
/api/configurations/** = authc, roles[admin]
/api/credential/** = authc, roles[admin]
/api/admin/** = authc, roles[admin]
/** = authc
zeppelin-site.xml: |-
zeppelin.anonymous.allowed
false
Anonymous user allowed by default
*左滑查看更多
设置完后再次访问zeppelin UI界面,点击login按钮输入用户名和密码登陆

调用Spark进行数据分析
我们将Spark的example数据下载下来,然后上传到Amazon S3中
https://github.com/apache/spark/blob/master/examples/src/main/resources/people.json
aws s3 cp people.json s3://your_bucket/spark/people/*左滑查看更多
然后在Zeppelin UI上创建一个新的Notebook,Default Interpreter选择Spark

然后在note中输入如下Spark代码,点击运行按钮,可以看到已经成功的读取Amazon S3的数据。
%spark
val df1 = spark.read.json(s"s3a://your_bucket/spark/people/people.json")
df1.printSchema
df1.show()*左滑查看更多

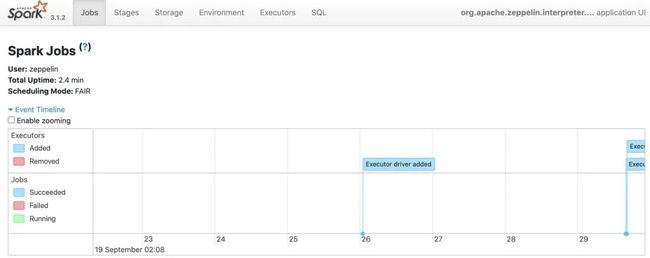
使用Spark UI查看作业情况
首先使用kubectl查看Spark interpreter Pod名字

例如我们配置的域名是zeppelin.domain.com ,那Spark interpreter Pod名字是 spark-vuxxmk,
Spark UI 默认在4040端口启动,我们访问http://4040-spark-vuxxmk.zeppelin.domain.com/jobs/即可以登陆到Spark UI界面查看job详细内容。
04
总结
在本文中,我们向您展示了如何在Amazon EKS上运行Spark和Zeppelin,以及如何使用Amazon S3来存储Zeppelin Notebook和数据文件,进而满足ETL、数据分析等各种场景。开发人员可以选择将Spark工作负载部署到已有的Amazon EKS集群当中,且无需进行任何额外的维护与升级。集群运营人员可以使用Kubernetes命名空间与资源配额机制,为集群访问活动添加资源限制条件等。
05
参考链接
http://zeppelin.apache.org/docs/0.10.0/quickstart/kubernetes.html
https://spark.apache.org/docs/latest/running-on-kubernetes.html
https://aws.amazon.com/cn/blogs/china/optimizing-spark-performance-on-kubernetes/?nc1=b_nrp
https://kubernetes-sigs.github.io/aws-load-balancer-controller/v2.2/deploy/configurations/
https://docs.aws.amazon.com/zh_cn/eks/latest/userguide/create-cluster.html
本篇作者

柳向全
亚马逊云科技解决方案架构师
负责基于亚马逊云科技的云计算方案架构的咨询和设计,目前主要专注于容器和大数据技术领域研究和亚马逊云科技云服务在国内和全球的应用和推广。
听说,点完下面4个按钮
就不会碰到bug了!