MYSQL 在优化器缺陷在次验证,与MYSQL 熄火了 还是 成熟了??

开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共850人左右 1 + 2 + 3)新人会进入3群。
上次在写了一篇关于MYSQL的优化器关于索引方面的问题的文章后,有同学说不对,当时答应在做更深入的测试,来深度证明MYSQL 的确在索引方面的一些问题。
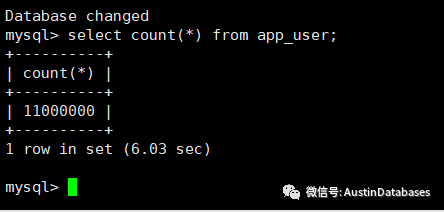
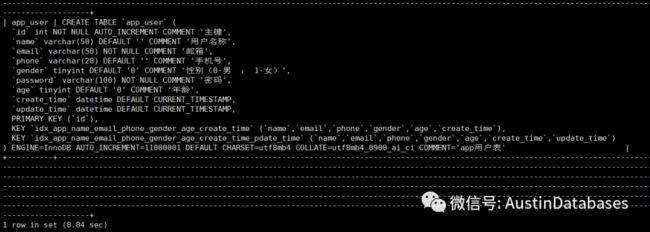
我们还是产生1000万的数据,MYSQL 数据库版本8.030
CREATE TABLE `app_user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(50) DEFAULT '' COMMENT '用户名称',
`email` varchar(50) NOT NULL COMMENT '邮箱',
`phone` varchar(20) DEFAULT '' COMMENT '手机号',
`gender` tinyint DEFAULT '0' COMMENT '性别(0-男 :1-女)',
`password` varchar(100) NOT NULL COMMENT '密码',
`age` tinyint DEFAULT '0' COMMENT '年龄',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
`update_time` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_app_name_email_phone_gender_age_create_time` (`name`,`email`,`phone`,`gender`,`age`,`create_time`),
KEY `idx_app_name_email_phone_gender_age_create_time_pdate_time` (`name`,`email`,`phone`,`gender`,`age`,`create_time`,`update_time`)
) ENGINE=InnoDB AUTO_INCREMENT=11000001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='app用户表'
SET GLOBAL log_bin_trust_function_creators=TRUE;
DELIMITER $$
CREATE FUNCTION mock_data()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 11000000;
DECLARE i INT DEFAULT 0;
WHILE i < num DO
INSERT INTO app_user(`name`,`email`,`phone`,`gender`,`password`,`age`)
VALUES(CONCAT('用户',i),'2548928007qq.com',CONCAT('18',FLOOR(RAND() * ((999999999 - 100000000) + 1000000000))),FLOOR(RAND() * 2),UUID(),FLOOR(RAND() * 100));
SET i = i + 1;
END WHILE;
RETURN i;
END;
DELIMITER $$
SELECT mock_data();
set session optimizer_trace = 'enabled=on';
针对以上的表进行查询
select * from app_user where name in ('用户1','用户2') and create_time = '2023-04-14';
通过trace 最终走了 name 与 create_time的索引
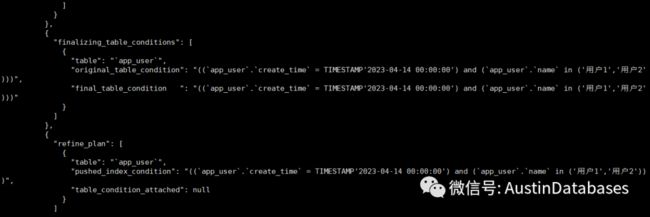
我们调整索引将 name 和 create_time 的索引清理后, 在添加一个name ,phone,create_time 的索引,在使用同样的查询后,查询并没有在走我们新添加的索引,而是走了一个更大的索引 idx_app_name_email_phone_gender_age_create_time` (`name`,`email`,`phone`,`gender`,`age`,`create_time`) 而没有走 (name,phone,create_time) 索引,按照我们常人的思维模式,我在选择一个不能覆盖我所有查询返回值的情况下,我应该选择一个更小的索引,而让我占据的 share buffer pool , 而 MYSQL的优化器竟然选择了,不是最大的索引 也不是最小的索引,而是一个 13不靠的索引。
我们经过查询发现实际上,针对于MYSQL 索引的大小并在计算COST 中虽然三个索引都符合要求,但是在COST的计算上这三个索引的COST 是一点都不差。 但明眼人都看的出,这个索引本身在使用的时候是有差别的,根据查询的语句与索引的匹配,最优的 idx_name_phone_create_time,但是没有走。
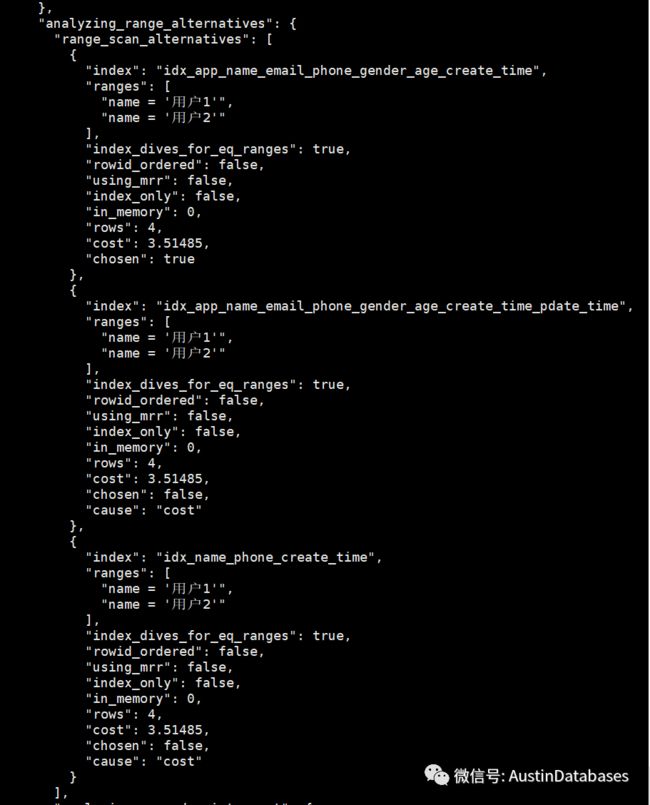
走了莫名其妙 idx_app_name_email_phone_gender_age_create_time

此时此刻我只想问一句, 麻烦8.030的版本的MYSQL 在优化器这个部分能稍微的在进步一点,或者解释一下,为什么最优的索引不是你的菜呢????而且使用三个索引的COST 是一样的????
所以问题 1 ,在多个都可以满足查询的索引在系统中,MYSQL 是无法分辨那个更好,选择的最终的索引,不是常理最优的原因不明。

来来来,贫道在来运行一遍,马上索引走了我们常理认为最优的索引。
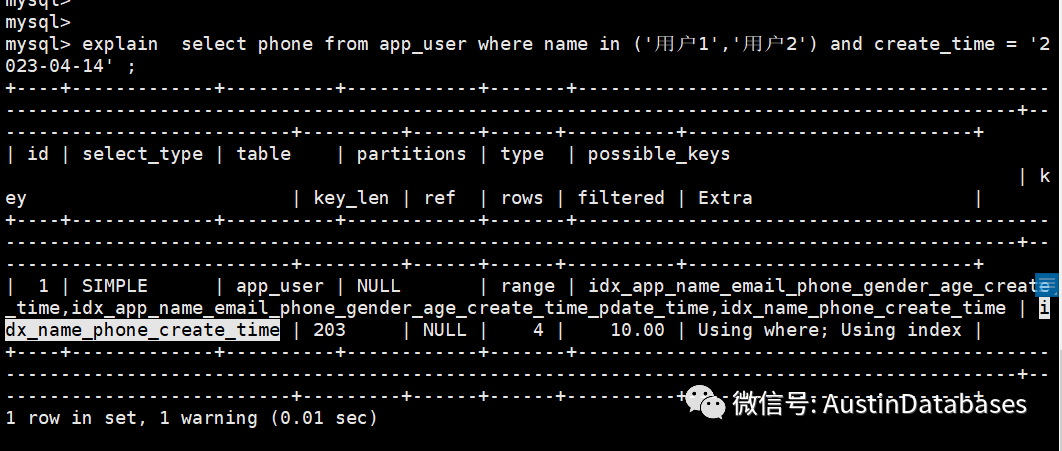
为什么,为什么 ,为什么,难道MYSQL 吃仙风道骨这一套。来贫道再次来说说,上次有人说的,我说的不对的问题。
MYSQL 最终重新都了我们认为对的索引的原因是,那个短的索引中的行有一行中的PHONE 字段是 NULL,在我将NULL 那行的NULL的值补充后,再次进行查询,系统又走了我们认为应该走的索引。

截止到目前,再次印证了上次的文章,和印证了MYSQL 优化器智商的缺陷的问题。
总结通过此测试获得的问题,1 存在NULL 的字段的索引,在查询中如果是最优选的索引,MYSQL 8.030 不会选择这个索引,而是选择一个比这个索引包含字段更多的索引。
2 我们将所有的索引删除,只留下这个一个有效索引,下图也再次证明如果走了相关的索引也不会走后面的时间部分,只会走NULL 值之前的字段,进行索引的查找。
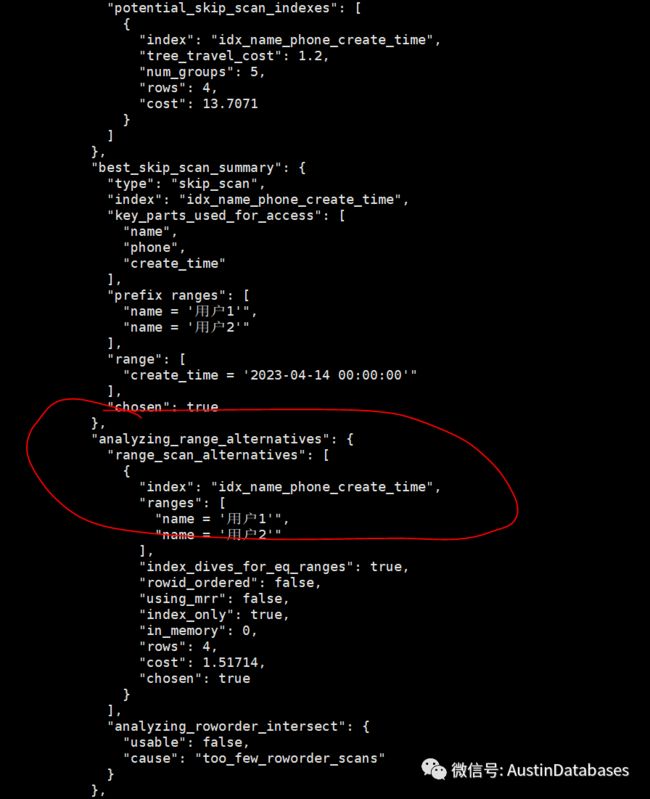
MYSQL 8 中间字段有NULL 值,还是无法走索引,所以我高估了MYSQL 的查询智商

第二个标题关于MYSQL 熄火的了或成熟了问题,主要还是个人感受,5-10年前MYSQL 的各类社区是非常红火的,相关的培训也是如火如荼,各种传道解惑的文字,书籍非常的多,但最近1-2年,MYSQL的声音不知道为什么变的小了,社区的一些声音和以前相比,也变得温和了。
个人感觉有几个原因
1 MYSQL 8的使用群体还是没有特别的大,很多企业还是在MYSQL5.7 上转悠,而基于MYSQL 5.7 的部分的文字,可以说基本上该写的都写了,问题该暴露的都暴露了。
2 MYSQL 的一些方案基本上人尽皆知,而一些新的方案如MYSQL 8 的MYSQL INNODB CLUSTER , MYSQL INNODB REPLIACTION 的方案使用的人或单位不多,并且大型的机构也不敢使用,也是基于mysql 8.029 的新闻。

3 国产化的数据库产品中,POSTGRESQL VS MYSQL ,一般人都知道MYSQL 在这个进程中,是一个被抛弃的结果,这局POSTGRESQL 是稳赢的。
4 MYSQL 本身在数据库承载力上面是无法负担大型应用的,也是在一些大型项目中,MYSQL 不在是热点,这也是MYSQL 在持续降温的一个原因。
5 上云后,很多替代MYSQL的数据库产品,从性能,价格,成本等角度都比MYSQL RDS 的产品要好,也导致一部分 MYSQL 的项目使用分流了
终究30年河东 ,30年河西,MYSQL被替换的方案太多,MYSQL本身逐渐趋于平淡的时期也到来了。
