YOLO NAS note 1
Git Hub: https://github.com/Deci-AI/super-gradients
Yolo-Nas 的代码比YOLO v8 还恐怖。之前的YOLO数据可以通过:
coco_detection_yolo_format_train, 和 coco_detection_yolo_format_val 自动转。
这里写目录标题
- Train
-
- 数据获取
- 数据增强
- 训练
-
- criterion
- params
- EMA
- self.training_params.batch_accumulate
- model
- QARepVGGBlock
- outputs = self.net(inputs)
- Test
- Deci
- Architecture
-
- QARepVGG
-
- reparameterizationbased models 有 quantization 困难
- 问题1
- 问题1的解决方案
- 问题2
- 问题2的解决方案
- 总结
Train
YOLO-NAS 的使用和 YOLO v8 类似。以下是parameters:
https://docs.deci.ai/super-gradients/super_gradients.training.html
from roboflow import Roboflow
import super_gradients
from super_gradients.training import Trainer
from super_gradients.training import dataloaders
from super_gradients.training.dataloaders.dataloaders import coco_detection_yolo_format_train, coco_detection_yolo_format_val
from super_gradients.training.losses import PPYoloELoss
from super_gradients.training.metrics import DetectionMetrics_050
from super_gradients.training.models.detection_models.pp_yolo_e import PPYoloEPostPredictionCallback
from super_gradients.training import models
import os
super_gradients.setup_device(device='cuda')
CHECKPOINT_DIR = 'helmet_checkpoints'
trainer = Trainer(experiment_name='helmet', ckpt_root_dir=CHECKPOINT_DIR)
if not os.path.exists('EEP_Detection-1'):
rf = Roboflow(api_key="IuYv6KOKs5p62rFSLvGa")
project = rf.workspace("objet-detect-yolov5").project("eep_detection-u9bbd")
dataset = project.version(1).download("yolov5")
# dataset_params = {
# 'data_dir':r'E:\data\alldata',
# 'train_images_dir': r'E:\data\alldata\train',
# 'train_labels_dir': r'E:\data\alldata\train',
# 'val_images_dir': r'E:\data\alldata\val',
# 'val_labels_dir': r'E:\data\alldata\val',
# 'test_images_dir': r'E:\data\alldata\val',
# 'test_labels_dir': r'E:\data\alldata\val',
# 'classes': ['helmet', 'normal']
# }
dataset_params = {
'data_dir':r'E:\data\helmet_head_2labels',
'train_images_dir': r'E:\data\helmet_head_2labels\train',
'train_labels_dir': r'E:\data\helmet_head_2labels\train',
'val_images_dir': r'E:\data\helmet_head_2labels\val',
'val_labels_dir': r'E:\data\helmet_head_2labels\val',
'test_images_dir': r'E:\data\helmet_head_2labels\val',
'test_labels_dir': r'E:\data\helmet_head_2labels\val',
'classes': ['helmet', 'normal']
}
mytransform = [{'DetectionStandardize': {'max_value': 255}},
{'DetectionMosaic': {'input_dim': [640, 640], 'prob': 1.0}},
{'DetectionRandomAffine': {'degrees': 10.0, 'translate': 0.1, 'scales': [0.1, 2], 'shear': 2.0, 'target_size': [640, 640], 'filter_box_candidates': True, 'wh_thr': 2, 'area_thr': 0.1, 'ar_thr': 20}},
{'DetectionMixup': {'input_dim': [640, 640], 'mixup_scale': [0.5, 1.5], 'prob': 1.0, 'flip_prob': 0.5}},
{'DetectionHSV': {'prob': 1.0, 'hgain': 5, 'sgain': 30, 'vgain': 30}},
{'DetectionHorizontalFlip': {'prob': 0.5}},
{'DetectionPaddedRescale': {'input_dim': [640, 640], 'max_targets': 120}},
{'DetectionTargetsFormatTransform': {'input_dim': [640, 640], 'output_format': 'LABEL_CXCYWH'}}]
train_data = coco_detection_yolo_format_train(
dataset_params={
'data_dir': dataset_params['data_dir'],
'images_dir': dataset_params['train_images_dir'],
'labels_dir': dataset_params['train_labels_dir'],
'classes': dataset_params['classes'],
'transforms': mytransform
},
dataloader_params={
'batch_size':8,
'num_workers':2
}
)
val_data = coco_detection_yolo_format_val(
dataset_params={
'data_dir': dataset_params['data_dir'],
'images_dir': dataset_params['val_images_dir'],
'labels_dir': dataset_params['val_labels_dir'],
'classes': dataset_params['classes'],
#'transforms': [{'DetectionStandardize': {'max_value': 255}},
# {'DetectionPaddedRescale':{'input_dim': [640, 640], 'max_targets': 120}},
# {'DetectionTargetsFormatTransform': {'input_dim': [640, 640], 'output_format': 'LABEL_CXCYWH'}}
]
},
dataloader_params={
'batch_size':8,
'num_workers':2
}
)
test_data = coco_detection_yolo_format_val(
dataset_params={
'data_dir': dataset_params['data_dir'],
'images_dir': dataset_params['test_images_dir'],
'labels_dir': dataset_params['test_labels_dir'],
'classes': dataset_params['classes'],
#'transforms': [{'DetectionStandardize': {'max_value': 255}},
# {'DetectionPaddedRescale':{'input_dim': [640, 640], 'max_targets': 120}},
# {'DetectionTargetsFormatTransform': {'input_dim': [640, 640], 'output_format': 'LABEL_CXCYWH'}}
]
},
dataloader_params={
'batch_size':8,
'num_workers':2
}
)
print(train_data.dataset.transforms)
print(train_data.dataset.dataset_params['transforms'][2])
train_data.dataset.dataset_params['transforms'][2]['DetectionRandomAffine']['degrees'] = 10.42
# train_data.dataset.plot()
model = models.get('yolo_nas_s',
num_classes=len(dataset_params['classes']),
pretrained_weights="coco"
)
train_params = {
# ENABLING SILENT MODE
'silent_mode': False,
"average_best_models":True,
"warmup_mode": "linear_epoch_step",
"warmup_initial_lr": 1e-6,
"lr_warmup_epochs": 3,
"initial_lr": 5e-4,
"lr_mode": "cosine",
"cosine_final_lr_ratio": 0.1,
"optimizer": "Adam",
"optimizer_params": {"weight_decay": 0.0001},
"zero_weight_decay_on_bias_and_bn": True,
"ema": True,
"ema_params": {"decay": 0.9, "decay_type": "threshold"},
# ONLY TRAINING FOR 10 EPOCHS FOR THIS EXAMPLE NOTEBOOK
"max_epochs": 3,
"mixed_precision": False,
"loss": PPYoloELoss(
use_static_assigner=False,
# NOTE: num_classes needs to be defined here
num_classes=len(dataset_params['classes']),
reg_max=16
),
"valid_metrics_list": [
DetectionMetrics_050(
score_thres=0.1,
top_k_predictions=30,
# NOTE: num_classes needs to be defined here
num_cls=len(dataset_params['classes']),
normalize_targets=True,
post_prediction_callback=PPYoloEPostPredictionCallback(
score_threshold=0.01,
nms_top_k=1000,
max_predictions=30,
nms_threshold=0.7
)
)
],
"metric_to_watch": '[email protected]'
}
if __name__ == '__main__':
trainer.train(model=model,
training_params=train_params,
train_loader=train_data,
valid_loader=val_data)
best_model = models.get('yolo_nas_s',
num_classes=len(dataset_params['classes']),
checkpoint_path="helmet_checkpoints/helmet/ckpt_best.pth")
trainer.test(model=best_model,
test_loader=test_data,
test_metrics_list=DetectionMetrics_050(score_thres=0.1,
top_k_predictions=300,
num_cls=len(dataset_params['classes']),
normalize_targets=True,
post_prediction_callback=PPYoloEPostPredictionCallback(score_threshold=0.01,
nms_top_k=1000,
max_predictions=300,
nms_threshold=0.7)
))
数据获取
YoloDarknetFormatDetectionDataset(super-gradients-master\src\super_gradients\training\datasets\detection_datasets)
-_setup_data_source:获取路径里的所有数据list
数据增强
增强的内容在transforms.py (super-gradients-master\src\super_gradients\training\transforms)
Nas 支持很多个大方向的内容,下面是例子:
DetectionMosaic('additional_samples_count': 3, 'non_empty_targets': False, 'prob': 1.0, 'input_dim': [640, 640], 'enable_mosaic': True, 'border_value': 114)
DetectionRandomAffine('additional_samples_count': 0, 'non_empty_targets': False, 'degrees': 10.0, 'translate': 0.1, 'scale': [0.1, 2], 'shear': 2.0, 'target_size': [640, 640], 'enable': True, 'filter_box_candidates': True, 'wh_thr': 2, 'ar_thr': 20, 'area_thr': 0.1, 'border_value': 114)
DetectionMixup('additional_samples_count': 1, 'non_empty_targets': True, 'input_dim': [640, 640], 'mixup_scale': [0.5, 1.5], 'prob': 1.0, 'enable_mixup': True, 'flip_prob': 0.5, 'border_value': 114)
DetectionHSV('additional_samples_count': 0, 'non_empty_targets': False, 'prob': 1.0, 'hgain': 5, 'sgain': 30, 'vgain': 30, 'bgr_channels': (0, 1, 2), '_additional_channels_warned': False)
DetectionHorizontalFlip('additional_samples_count': 0, 'non_empty_targets': False, 'prob': 0.5, 'max_targets': 120)
DetectionPaddedRescale('swap': (2, 0, 1), 'input_dim': [640, 640], 'max_targets': 120, 'pad_value': 114)
DetectionTargetsFormatTransform('additional_samples_count': 0, 'non_empty_targets': False, 'input_format': OrderedDict([('bboxes', name=bboxes length=4 format=<super_gradients.training.datasets.data_formats.bbox_formats.xyxy.XYXYCoordinateFormat object at 0x000001D80A2BE100>), ('labels', name=labels length=1)]), 'output_format': OrderedDict([('labels', name=labels length=1), ('bboxes', name=bboxes length=4 format=<super_gradients.training.datasets.data_formats.bbox_formats.cxcywh.CXCYWHCoordinateFormat object at 0x000001D80A2E92B0>)]), 'max_targets': 120, 'min_bbox_edge_size': 1, 'input_dim': [640, 640], 'targets_format_converter': <super_gradients.training.datasets.data_formats.format_converter.ConcatenatedTensorFormatConverter object at 0x000001D834D18C70>)
> * 比如我想要数据集做下 standardisation: 仅 ‘/255’, 那么在test,val里都得加上和train一样的standardisation, 让进model的数据值的分布一致(0-1之间)和yolo 之前操作一样,我需要一个letterbox, 辣么 train,val, test 的letterbox做法要一致(尺寸大小得一致,但是letterbox是居中还是如yolo nas 是放在上方,这几个过程要不要一致,其实看你啦)
*还有一个是格式转换:DetectionTargetsFormatTransform,这个在train里有的,在val, test 也必须加上。
训练
Trainer (super-gradients-master\src\super_gradients\training\sg_trainer)
criterion
这里的 DFL 从 YOLO v8 延续到NAS, 但是 YOLO v8 使用 CIOU
DFL + GIOU
class loss 同 yolov8 支持 varifocal loss
params
{'silent_mode': True,
'average_best_models': True,
'warmup_mode': 'linear_epoch_step',
'warmup_initial_lr': 1e-06,
'lr_warmup_epochs': 3,
'initial_lr': 0.0005,
'lr_mode': 'cosine', 'cosine_final_lr_ratio': 0.1,
'optimizer': 'Adam', 'optimizer_params': {'weight_decay': 0.0001},
'zero_weight_decay_on_bias_and_bn': True,
'ema': True, 'ema_params': {'decay': 0.9, 'decay_type': 'threshold'},
'max_epochs': 3,
'mixed_precision': False,
'loss': PPYoloELoss((static_assigner): ATSSAssigner()(assigner): TaskAlignedAssigner()),
'valid_metrics_list': [DetectionMetrics_050((post_prediction_callback): PPYoloEPostPredictionCallback())],
'metric_to_watch': '[email protected]'}
EMA
Exponential Moving Average , 随时间移动而平滑函数让其接近真实值。越是近期的数据,权重越大。不单纯只是exponential (在这一点上比moving mean/sum 好)。SGD 里可以加入 EMA 帮助优化。
EMA 不适用于 non-stable function. 虽然模型在训练中,weight一直在变化,但它最终的期望还是使得model converge 到某个分布, 所以针对weight,这个依然是可以用EMA的。
但是,训练中的changing gradients, loss values, and model performance 都是 non-stable 的。当然,EMA是给weight用的,和这些内容无关。
self.training_params.batch_accumulate
内存友好,积累到一定数量,统一更新
model
super-gradients-master\src\super_gradients\training\utils
wrappednet ⇒ CustomizableDetector
def forward(self, x):
x = self.backbone(x)
x = self.neck(x)
return self.heads(x)
QARepVGGBlock
Make RepVGG Greater Again: A Quantization-aware Approach
outputs = self.net(inputs)
outputs总的6个值
> 0:pred_scores (8,8400,2) :Tensor
> 1:pred_distri (8,8400,68) :Tensor
> 2:anchors (8400,4) : Tensor
> 3:anchor_points (8400,2) : Tensor
> 4:num_anchors_list 3 :list => [6400,1600,400]
> 5:stride_tensor (8400,1) :Tensor
self._get_losses(outputs, targets) #target (138,6)
target 包含3个值
> 0:gt_class (8,41,1) :Tensor
> 1:gt_bbox (8,41,4) :Tensor
> 2:pad_gt_mask (8,41,1) :Tensor (bool)
Test
from roboflow import Roboflow
import super_gradients
from super_gradients.training import Trainer
from super_gradients.training import dataloaders
from super_gradients.training.dataloaders.dataloaders import coco_detection_yolo_format_train, coco_detection_yolo_format_val
from super_gradients.training.losses import PPYoloELoss
from super_gradients.training.metrics import DetectionMetrics_050
from super_gradients.training.models.detection_models.pp_yolo_e import PPYoloEPostPredictionCallback
from super_gradients.training import models
import glob
from pathlib import Path
import os
import torch
dataset_params = {
'data_dir':r'E:\data\alldata',
'train_images_dir': r'E:\data\alldata\train',
'train_labels_dir': r'E:\data\alldata\train',
'val_images_dir': r'E:\data\alldata\val',
'val_labels_dir': r'E:\data\alldata\val',
'test_images_dir': r'E:\data\alldata\val',
'test_labels_dir': r'E:\data\alldata\val',
'classes': ['helmet', 'normal']
}
super_gradients.setup_device(device='cuda')
CHECKPOINT_DIR = 'helmet_checkpoints'
trainer = Trainer(experiment_name='helmet', ckpt_root_dir=CHECKPOINT_DIR)
if __name__ == '__main__':
best_model = models.get('yolo_nas_s',
num_classes=len(dataset_params['classes']),
checkpoint_path="helmet_checkpoints/helmet/ckpt_best.pth")
device = 'cuda' if torch.cuda.is_available() else "cpu"
import matplotlib
matplotlib.use('TkAgg', force=True)
imgfiles = glob.glob(str(Path('testImgs')/'*.*'),recursive=True)[13]
outfolder = 'testresultss'
os.makedirs(outfolder,exist_ok=True)
predictions = best_model.predict(imgfiles)
predictions.show()
# predictions.save(output_folder="testresultss") # Save in working directory
# models.convert_to_onnx(model=best_model, input_shape=(3, 640, 640), out_path="yolo_nas_s.onnx")
Deci
不支持windows 和 MacOS
Architecture
yolo v8 与 yolo nas 主要的框架改编自YOLO v6, 大的框架不变,都是先backbone, 再Neck, 后Head.
可以说 v6开始,就和v5 有很大不同了. 在 v6 中:
改动最多的是backbone,虽然套路依然延续CSP时期的yolo v5, 但是内核已经从 CSP 变成了 RepVGG.
Top-Down 中的的 CSPPlayer 都替换成了 RepVGG.
Head 中,虽然依然贴心的分出3个分支做尺寸友好的检测增强,但是,比起v5, v6 有了更多的conv去继续提取特征。
QARepVGG
RepVGG 在 yolo v6 里用了。
yolo v6
reparameterizationbased models 有 quantization 困难
hmmmm… 之前的VAE, 有使用reparameterization 做 Gaussian distribution 的latent space 表示。也有用reparameterization 中 SVD技术做matrix分解的。这些方法一定程度上缓解了计算效率和节省内存。RepVGG 类似的用了multi-branch的结构。这些方式更多注重在训练时候。而PTQ更加强调是训练后,也就是inference 时。
reparameterization 会牺牲一定精度换取计算效率。如果在reparameterization 基础上做 PTQ,那相当于在误差里做更误差的事情。在reparameterization 的基础上,至少按常理来说,数值精度越高越保险。
Post Training Quantization (PTQ) is a technique to reduce the required computational resources for inference while still preserving the accuracy of your model by mapping the traditional FP32 activation space to a reduced INT8 space.
针对 PTQ这一点,QARepVGG 好过 RepVGG. 而且这个模型也是 “INT8”的来源。
文中提到:our models are comparable to RepVGG in terms of FP32 accuracy
Weight & Activation 是主要优化的地方
问题1
作者发现 BN中的mean 没有什么影响(集中于0附近,约为0),但是variance不是。
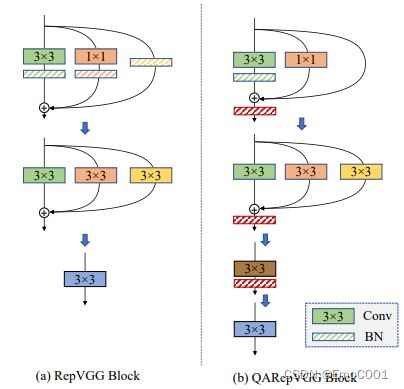 (凡是斜杠的block都是BN,凡是实心的都是各种kernel)
(凡是斜杠的block都是BN,凡是实心的都是各种kernel)

M2 是第一层加法的结果。 Y3, Y1, Y0 分别代表上面 3x3, 1x1, Identity 的 kernels的BN后的结果。
以 kernels 3x3的为例子:

因为 D ( λ X ) = λ 2 D ( X ) D(λX) = λ^2D(X) D(λX)=λ2D(X), 假设 X ( 3 ) = M ( 1 ) W ( 3 ) X(3) = M(1)W(3) X(3)=M(1)W(3), 代入式子, D ( λ X ) D(λX) D(λX) = D ( Y ( 3 ) ) D(Y(3)) D(Y(3)), D ( X ) D(X) D(X) = D ( X ( 3 ) ) D(X(3)) D(X(3)):

以上内容证明了variance影响巨大,除此之外,RepVGG 里的loss L2,放大了上面的部分来减少loss,也使得因改变variance of activation,让PTQ在这里失败。
问题1的解决方案
作者的解决方案很直接,把有影响的地方直接去除:

![]()
目前,去除分母的做法能够使得在INT8 精度下,改进的方式的model 成绩优于 RepVGG 里的。
问题2
作者发现based在问题1的做法上,导致了layers中有些格格不入的outliers.

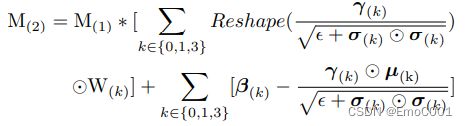
将问题1中的两个公式融合在一起为上面的M2,作者认为,前半部分的 γ / ϵ + σ 2 \gamma / \sqrt { \epsilon + \sigma ^2} γ/ϵ+σ2 如果本身值就大(特别是对于Y0, 因为它是identity的matrix,那么这个部分就会是1, 即 1*W0),它会把这个巨大的值贡献给经过fusion后的 同等 kernels。
作者后续,证明了 β 1 \beta _1 β1 = β 3 \beta _3 β3, 为 Expectation。(虽然这是个很标准的inductive的过程,但是对于 l k + 1 ∗ l^{k+1}* lk+1∗partial derivation 的部分有点懵)
作者还注意到RepVGG 使用的是 Relu, 但是基于常理: modern high-performance CNN models with BN often have zero means。 因此,为了防止 dead Relu, 全部相加在一起:

addition of the three branches introduces the covariate shift issue
问题2的解决方案
根据outlier 的layer锁定问题还是在variance of activation上,想要放大variance,并且证明了branch 1 和 branch 3的期望结果一致,将三个branch的BN结果相加,来抵消dead Relu. 又因为考虑到 直接相加BN会导致 BN 的 方差位移,因此最终解决方案为在相加后的BN结果上再进行一次BN。
最终 S4 为整个 QARepVGG 的方案,并且达到了 PTQ!

总结
- PTQ 是保障在FP32,INT8 上都要优于baseline model
- BN 操作时,如果遇到Relu, 可以用文中技巧: B N ( ∑ 0 n B N ) BN(\sum_0^n BN) BN(∑0nBN)
- BN 操作时,如果遇到模型不ok, 可以尝试去看一下每层layer BN的 mean 与 Variance
- 应该可以放弃RepVGG 了,直接上QARepVGG