三种常见的http content-type详解
content-type知识点介绍
content-type常见类型
介绍
http协议是建立在tcp/ip协议之上的应用层协议,主要包括三个部分,状态行,头部信息,消息主体。对应一个http请求就是:请求行,请求头,请求体。
协议规定post提交的数据,必须包含在消息主体中entity-body中,但是协议并没有规定数据使用什么编码方式。开发者可以自己决定消息主体的格式。
数据发送出去后,需要接收的服务端解析成功,一般服务端会根据content-type字段来获取参数是怎么编码的,然后对应去解码。
在最早的http post请求中,只支持application/x-www-form-urlencoded,参数都是通过浏览器的url传递。其实是不支持文件上传的,这样有很多不便。在1995年的时候,出台了rfc1867,也就是《RFC 1867 From-based file upload in HTML》,用以支持文件上传。所以content-type扩充了multipart/form-data用以支持向服务器发送二进制数据。后来随着web应用的增多,增加了诸如application/json的类型。
application/x-www-form-urlencoded
在最开始的请求方式中,请求参数都是放在url中,表单提交的时候,都是以key=&value=的方式写在url后面。这也是浏览器表单提交的默认方式。
此时可以直接调用request.getInputStream或request.getReader获取到请求内容,再解析出具体的参数。后者只是对前者的一个封装,可以让调用者更方便字符内容的处理。可以看到:
@Override
public BufferedReader getReader() throws IOException {
if (this.reader == null) {
this.reader = new BufferedReader(new InputStreamReader(getInputStream(),
getCharacterEncoding()));
}
return this.reader;
public InputStreamReader(InputStream in, String charsetName)
throws UnsupportedEncodingException
{
super(in);
if (charsetName == null)
throw new NullPointerException("charsetName");
sd = StreamDecoder.forInputStreamReader(in, this, charsetName);
}
也可以通过request.getParameter获取到参数。
但是需要注意,getInputStream、getReader、getParameter在一定的场景是互斥的。
multipart/form-data
此种方式多用于文件上传,表单数据都保存在http的正文部分,各个表单项之间用boundary分开。
一次完整的抓包如下:
POST /ecard/uploadFaceImage?timestamp=1531906535406 HTTP/1.0
Host: www.example.com
X-Real-IP: 183.156.142.242
X-Forwarded-For: 183.156.142.242
Connection: close
Content-Length: 230101
sign: 9a7d3b4978979ef65a12e34ae1cf7b2d
accept: */*
user-agent: Mozilla/5.0 (Linux; U; Android 6.0.1; zh-CN; OPPO R9s Build/MMB29M)
AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.108
UCBrowser/11.8.8.968 UWS/2.13.1.42 Mobile Safari/537.36 UCBS/2.13.1.42_180629181124
ChannelId(1) NebulaSDK/1.8.100112 Nebula AlipayDefined(nt:WIFI,ws:360|0|3.0)
AliApp(AP/10.1.28.560) AlipayClient/10.1.28.560 Language/zh-Hans useStatusBar/true
isConcaveScreen/false
Cookie: ssl_upgrade=0; spanner=6tlJA6NZwnkqTDN+BMhdT7lbzLPsFJUeXt2T4qEYgj0=
Accept-Encoding: gzip
Content-Type: multipart/form-data; boundary=pgRq9HriiaBmfSo5rfyEJPtcumxb4fd6o15f_3G
--pgRq9HriiaBmfSo5rfyEJPtcumxb4fd6o15f_3G
Content-Disposition: form-data; name="personCode"
Content-Type: text/plain; charset=US-ASCII
Content-Transfer-Encoding: 8bit
DM1203
--pgRq9HriiaBmfSo5rfyEJPtcumxb4fd6o15f_3G
Content-Disposition: form-data; name="DM1203"; filename="123524587.jpg"
Content-Type:
Content-Transfer-Encoding: binary
图片二进制数据(特别长)
--pgRq9HriiaBmfSo5rfyEJPtcumxb4fd6o15f_3G--
HTTP/1.1 200
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: POST, GET, OPTIONS, DELETE
Access-Control-Max-Age: 3600
Access-Control-Allow-Headers: Origin, No-Cache, X-Requested-With,
If-Modified-Since, Pragma, Cache-Control, Expires, Content-Type
Access-Control-Allow-Credentials: true
XDomainRequestAllowed: 1
Content-Type: application/json;charset=UTF-8
Date: Wed, 18 Jul 2018 09:35:36 GMT
Connection: close
{"retCode":1,"msg":"success","data":null}
可以看到里面有一个boundary分界,值为:pgRq9HriiaBmfSo5rfyEJPtcumxb4fd6o15f_3G,请求时,会放在Content-Type后面传到服务器,服务器根据这个边界解析数据,划分段,每一段都是一项数据。每一项中的name属性就是唯一的id
此时用request.getParameter是取不到数据的,这个时候需要通过request.getInputStream来获取数据。这时取到的是一个InputStream,无法直接取到指定的表单项。但是有很多开源的组件可以直接利用,比如apache的fileupload组件。通过这些开源的upload组件,提供的api,就可以直接从request中取得指定的表单项。
ServletFileUpload upload = new ServletFileUpload(factory);
List list = upload.parseRequest(request);
上面的代码中,接下来就可通过遍历list获取参数了。
application/json
现在越来越多的应用使用application/json,用来告诉服务端消息主体是序列化的json字符串。由于json规范的流行,各大浏览器都开始原生支持JSON.stringfy。
而且spring对这个content-Type上传的数据有很好的支持,可以直接通过@RequestBody进行接收。也是当前完美适配当前流行的RestApi。
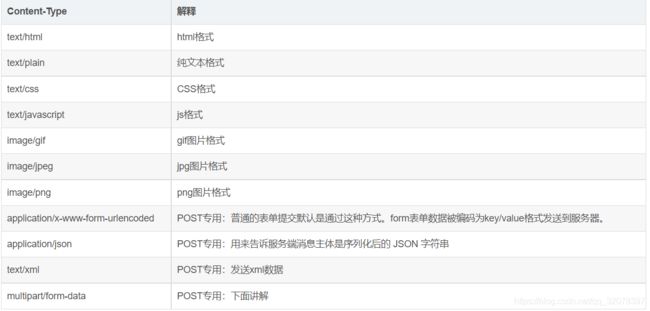
常见的Content-Type:
Http 协议中的扩展
http 协议除了这两种基本组成以外,还有很多大家比较常见的属性或者配置,我也简单罗列 一些
如果传输的文件过大怎么办
服务器上返回的资源文件比较大,比如有些 js 文件大小可能就有几兆。文件过大就会影响传 输的效率,同时也会带来带宽的消耗。怎么办呢?
1. 常见的手段是,对文件进行压缩,减少文件大小。那压缩和解压缩的流程怎么实现呢? 首先服务端需要能支持文件的压缩功能,其次浏览器能够针对被压缩的文件进行解压缩。浏 览器可以指定 Accept-Encoding 来高速服务器我当前支持的编码类型 Accept-Encoding:gzip,deflate 那服务端会根据支持的编码类型,选择合适的类型进行压缩。常见的编码方式有:gzip/deflate
2. 分割传输 在传输大容量数据时,通过把数据分割成多块,能够让浏览器逐步显示页面。这种把实体主 体分块的功能称为分块传输编码(Chunked Transfer Coding)。
每次请求都要建立连接吗?
在最早的 http 协议中,每进行一次 http 通信,就需要做一次 tcp 的连接。而一次连接需要进 行 3 次握手,这种通信方式会增加通信量的开销。

所以在 HTTP/1.1 中改用了持久连接,就是在一次连接建立之后,只要客户端或者服务端没有 明确提出断开连接,那么这个 tcp 连接会一直保持连接状态 持久连接的一个最大的好处是:大大减少了连接的建立以及关闭时延。 HTTP1.1 中有一个 Transport 段。会携带一个 Connection:Keep-Alive,表示希望将此条连接 作为持久连接。
HTTP/1.1 持久连接在默认情况下是激活的,除非特别指明,否则 HTTP/1.1 假定所有的连接都 是持久的,要在事务处理结束之后将连接关闭,HTTP/1.1 应用程序必须向报文中显示地添加 一个 Connection:close 首部。
HTTP1.1 客户端加载在收到响应后,除非响应中包含了 Connection:close 首部,不然 HTTP/1.1 连接就仍然维持在打开状态。但是,客户端和服务器仍然可以随时关闭空闲的连接。不发送 Connection:close 并不意味这服务器承诺永远将连接保持在打开状态。
管道化连接: http/1.1 允许在持久连接上使用请求管道。以前发送请求后需等待并收到响应, 才能发送下一个请求。管线化技术出现后,不用等待响应亦可直接发送下一个请求。这样就 能够做到同时并行发送多个请求,而不需要一个接一个地等待响应了。

Http 协议的特点
Http 无状态协议
HTTP 协议是无状态的,什么是无状态呢?就是说 HTTP 协议本身不会对请求和响应之间的 通信状态做保存。 但是现在的应用都是有状态的,如果是无状态,那这些应用基本没人用,你想想,访问一个 电商网站,先登录,然后去选购商品,当点击一个商品加入购物车以后又提示你登录。这种 用户体验根本不会有人去使用。那我们是如何实现带状态的协议呢?
客户端支持的 cookie
Http 协议中引入了 cookie 技术,用来解决 http 协议无状态的问题。通过在请求和响应报文 中写入 Cookie 信息来控制客户端的状态;Cookie 会根据从服务器端发送的响应报文内的一 个叫做 Set-Cookie 的首部字段信息,通知客户端保存 Cookie。当下次客户端再往该服务器 发送请求时,客户端会自动在请求报文中加入 Cookie 值后发送出去。
服务端支持的 session
服务端是通过什么方式来保存状态的呢? 在基于 tomcat 这类的 jsp/servlet 容器中,会提供 session 这样的机制来保存服务端的对象状态,服务器使用一种类似于散列表的结构来保存信 息,当程序需要为某个客户端的请求创建一个 session 的时候,服务器首先检查这个客户端 的请求是否包含了一个 session 标识- session id; 如果已包含一个 session id 则说明以前已经为客户端创建过 session,服务器就按照 session id 把这个 session 检索出来使用(如果检索不到,会新建一个); 如果客户端请求不包含 sessionid,则为此客户端创建一个 session 并且生成一个与此 session 相关联的 session id, session id 的值是一个既不会重复,又不容易被找到规律的仿造字符 串,这个 session id 将会返回给客户端保存
