Promising 2.0:宽松内存并发中的全局优化
本文由 Hana 根据论文解读视频整理所得,如有错误欢迎指正!
原视频内容较长,已经分上下两部分发布 B 站,欢迎点开学习!
论文解读 | Promising 2.0:宽松内存并发中的全局优化(上)_哔哩哔哩_bilibili论文解读 | Promising 2.0:宽松内存并发中的全局优化(上) https://www.bilibili.com/video/BV1Fq4y1V73D论文解读 | Promising 2.0:宽松内存并发中的全局优化(下)_哔哩哔哩_bilibili论文解读 | Promising 2.0:宽松内存并发中的全局优化(下)
https://www.bilibili.com/video/BV1Fq4y1V73D论文解读 | Promising 2.0:宽松内存并发中的全局优化(下)_哔哩哔哩_bilibili论文解读 | Promising 2.0:宽松内存并发中的全局优化(下) https://www.bilibili.com/video/BV1eF411e7f2分享嘉宾介绍:
https://www.bilibili.com/video/BV1eF411e7f2分享嘉宾介绍:
冯新宇 博士 现任中央软件院编程语言实验室主任,编程语言首席专家,主导通用编程语言的设计和实现。加入华为前,先后于中国科学技术大学和南京大学担任教授、博士生导师,主要研究方向是程序设计语言理论和程序验证。
# 论文简介 #
内存模型是编程语言的语义定义的重要构成部分,是开发者和编译器构建者之间的重要接口。然而,由于处理器和编译器优化导致的并发程序的弱内存模型,一直没有很好的定义。
当前的业界共识是,Java 和 C++ 当前的内存模型都有严重的问题,特别是 C++ 的内存模型会允许 out of thin air 行为,导致程序的行为难以理解和推理。
本篇论文 [1] 是试图解决 C11 内存模型问题的一系列论文中非常重要的一篇, 采用了一种虚拟机模型,给出一个 C11 模型的改进方案,解决目前面临的各种问题。
-
项目地址:Promising 2.0: Global Optimizations in Relaxed Memory Concurrency
-
论文地址:https://sf.snu.ac.kr/publications/promising2-full.pdf
-
形式化实现(Coq):https://github.com/snu-sf/promising2-coq
-
视频报告(Youtube): https://www.youtube.com/watch?v=Z6W7_xDr2pY
本次分享更多的是给大家介绍一下内存模型的背景和相关领域的现状,并针对内存模型 1.0 说明一下存在的问题和 2.0 的大致方案。因为时间原因,我这里借用了作者们之前的分享材料,以及我自己之前的教学讲义,可能有些杂乱,大家包涵哈~
# 内存模型与弱内存模型 #
# 为什么需要内存模型?
先来介绍一下 内存模型 Memory Model,我们为什么关心内存模型,或者说内存模型是讲什么的?
如下图示,我们用 C1 || C2 表示一个并发程序,用 C1 和 C2 分别表示两个线程。那么,这个并发程序要执行的话,需要经过编译器(广义上的编译器,比如对 Java 来说 bytecode 是在虚拟机上运行的),再往下就是在硬件层上运行,实际上就是最基本的 读写内存 的行为,最后得到我们想要的结果。以上是一个并发程序真正的执行过程。
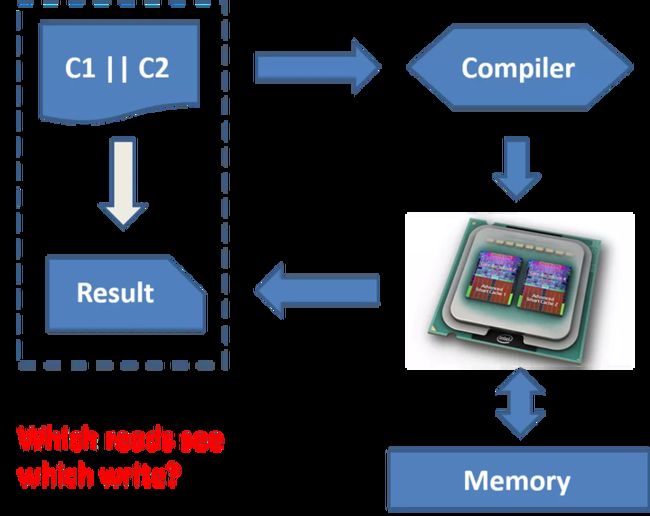
并发程序的执行过程
那么,作为普通的开发者,面对这样一个程序,我们关心什么?
我肯定不可能知道编译器的每一个细节,也不可能知道底层硬件的每个细节,但是我一定想知道这样一个程序写在这里,它最后的运行结果是什么,我们管这个叫 程序语义。这个问题最关键的地方就是程序里的 内存读写,我们要能够回答出最终在结果里应该 哪一个读 看到 哪一个写。这就是内存模型要回答的问题。
# 从 Sequentially Consistent Model 讲起
Leslie Lamport 在 1979 年 [2] 提出一种理解并发程序执行的内存模型,即 Sequentially Consistent Model(顺序一致性模型),如下图所示。
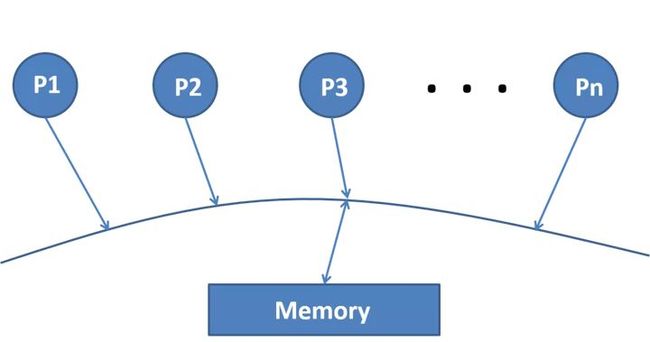
Sequentially Consistent (SC) Model [2]
我们可以将这个模型当做有多个处理器或者多个任务 ... ,每个任务你可以认为是在串行执行,即每次按照串行执行的顺序,往下执行下一条指令。当任务涉及到读写内存时,在任何时刻我们只能选其中一个任务,让其执行一个内存操作,这个就是 Sequentially Consistent (SC) Model,也是一个最简单的并发模型。
我们一般学并发的时候,可能老师教的往往都是这种模型。但在实际当中这种模型有些过于理想化了。我们如果一定要保证程序遵循这种模型的话,很多的优化就做不到了。
比如有下面这样一个例子,其中 x 和 y 可以看做是内存,r1 和 r2 是寄存器:
-
在开始的时候,假设 x 和 y 为 0 x = y = 0;
-
在第一个线程中,我们要往 x 里写 1 x = 1,然后 r1 读 y 的值 r1 = y;
-
在第二个线程中,我们往 y 里写 1 y = 1,然后 r2 读 x 的值 r2 = x。
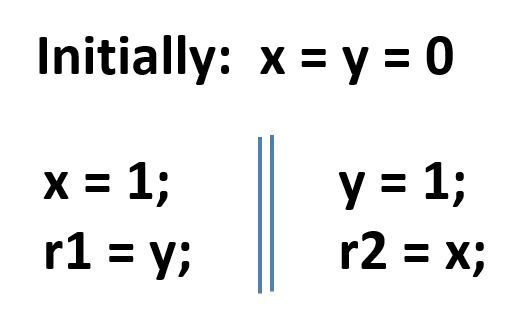
问题是,有没有可能 r1 和 r2 两个寄存器读到的值都为 0?
## r1=r2=0?
如果我们认为这个程序是交替执行的话,即在任何时刻选一个任务让他去执行,而且每个任务当成串行从前往后执行的话,这是不可能的。
至少有一个寄存器读到的一定是 1。
比如说 r1 如果读到 0(即 成立),就表示 r1 读 y(r1 = y)的时候,y 的写(y = 1)还没做,即 r1 的读发生在 y 写 1 之前。那么如果是这样的话, x = 1 发生在读 y(r1 = y)之前,因此这个时候 x 写 1(x = 1)已经做了。因此,这个顺序必然是,先执行 x 写 1(x = 1),然后再读 y(r1 = y),这个时候 y 还是 0;然后等这边的任务做完之后 y 再写 1(y = 1);然后 r2 再读 x(r2 = x),此时 x 必然已经是 1 了(即 ),不可能是 0。
类似地,如果 r2 读到的值是 0 的话,那么你可以用类似的办法推出来 y 必须得是 1。如果按照 SC Model, 是不可能成立的。
其实上面提到的推断方法已经被用在很多领域了。大家如果学并发或者操作系统的话,应该了解 Dekker's 算法 [3](即 实现互斥算法)实际上就是这么做的:当两个线程实现互斥,那我就让两边的代码块各自进入临界区。
回到原来的例子。第一个线程里,x 写 1(x = 1)表示 x 想进入临界区;第二个线程里,y 写 1(y = 1)表示自己也要进入临界区了;第一个线程中 r1 读 y(r1 = y)表示也要进入临界区了。这时,我们需要看一下第二个线程是不是想进临界区?如果 r2 是 0 的话,即没有要求进临界区,那第一个线程就可以继续执行下去。因为我们知道 r1 与 r2 不可能同时是 0,也就是说两个线程不可能同时进入临界区,因此我们能做到互斥。这个模型实际上已被用来实现 Dekker's Algorithm。
## r1=r2=0
实际上你会发现,真正的编译器编译之后,我们的实际效果是完全是有可能出现 r1=r2=0 的。之所以能导致这个结果,是什么原因呢?
编译器可能会发现这两个线程之间实际上 没有数据依赖关系(两个线程分别是访问 x,和访问 y),那么编译器可以根据某种需要,颠倒程序的执行顺序。因为编译器会认为每个任务都是串行程序,对于串行程序来说,如果没有数据依赖关系,那么颠倒顺序是不会影响最后结果的,因此编译器会做顺序重排的优化。
颠倒顺序执行后(如下图示),你会发现,r1 读 y 就会读到 0(当前 y 初始为 0),另一边线程里 y 写 1,然后 r2 读 x 读到 0(x 初始为 0),然后再 x 写 1。这种情况下,r1=r2=0 就成立了。
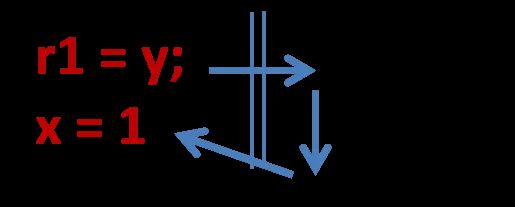
甚至这种结果的产生都不需要依赖于编译器。实际上在 x86 下面这个结果已经会出现了(x86 的内存模型相比 SC Model 会弱一些)。如果再考虑到编译器中间的各种优化,比如 Java 或者 C/C++,都有可能会产生这种行为。
这告诉我们什么呢?
其实,在编译器和硬件实现上,我们都会做各种各样的优化。这些优化叠加起来,就会导致可能实际的行为与最开始讲的 SC Model 不符。反过来讲,如果我们非要求程序执行的结果一定满足 SC Model 的话,那么我们现在很多编译器和处理器里的优化就不能像现在这么做了。随之可能会带来的结果就是,我们的程序性能就不会像现在这么好了。
这就是为什么说 SC Model 是一个比较理想化的内存模型,而真正我们程序展示出来的行为可能比我们 SC Model 要允许的行为还要多很多。这就是内存模型要回答的问题,我们管这个叫 弱内存模型 Weak Memory Model。
弱内存模型相对于 SC Model 来说,它会比 SC Model 展示出更多的行为来。如果说我们必须得接受现在编译器和处理器做了各种优化的话,那当我们需要理解前面的程序时,我们就需要理解弱内存模型下面能产生的各种行为。
# 以 C/C++11 和 LLVM 为例说明
我从 Viktor Vafeiadis 的 Weak Memory Concurrency in C/C++11 and LLVM 讲义 [4] 上摘过来比较有意思的例子。(BTW,Viktor 是今天讲的 Promising Semantics 的主要作者之一,德国 MPI-SWS 软件研究所的研究员,曾是华为德累斯顿研究所顾问。)
我们看一下,下面两个例子是不是同时都能被允许?(例子中的 a 和 b 都可以看做是处理器的局部变量(或者可以看做是寄存器),x 和 y 是内存,我们关心内存模型实际上就是关心对 x 和 y 的访问。)
## 1# 在获取锁的过程中进行 CSE
CSE 即 公共子表达式消除 Common Subexpression Elimination [5]。
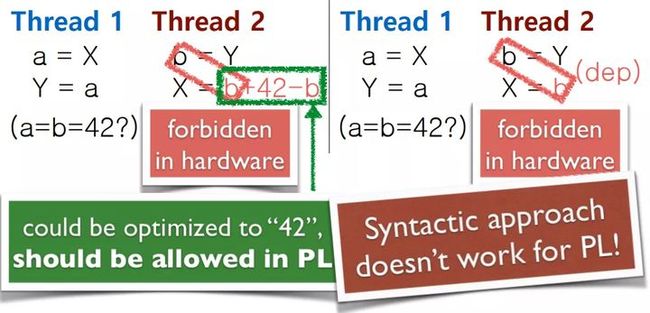
如下图示,我们在加锁 lock() 之前对 x 进行了读 a = x,在加锁之后再次读取 x b = x。在这个过程中,我们是否可以做这样一个优化,鉴于我们并没有在加锁前后对 x 进行修改,那么在临界区里我可以直接让 b 读 a 的值 b = a(这里做了程序变换),这样就可以减少一次内存读的操作。

你可能会觉得,并发程序怎么可以这么优化呢,这过程中有可能任务会被别人打断,两次对 x 的读有可能会读到不一样的值,怎么能直接优化为读 a 的值呢?
我们讲这个优化实际上是合理的。之所以这么说,是因为若存在被其他任务打断和修改 x 的值的情况,表示你的程序是有 数据竞争(data race) 的。对于 C/C++ 来说,如果存在数据竞争,那么程序的行为是 未定义 的,因此上述的优化方式是可以接受的。
## 2# Load Hoisting
另一个例子,是 读内存是否可以向外提升? 如下图所示,假设我不管三七二十一,先将 x 的值读到一个临时的局部变量或寄存器中 t = x(这里我们也做了程序变换,引入了一个不会与别的地方有冲突的局部变量 t),然后判断 c 是否成立。如果 c 成立的话,就用刚才读的临时变量 t 的值;否则 a = a 即 a 值不变。

可能大家乍一看,会觉得这种做法不太对。因为左边的程序里,可能压根都不会读 x 的值(即条件 c 不成立时),此种情况下,别的线程若访问 x,与当前的线程是不存在竞争的;可是提升之后,当前线程就会一定读 x 的值(t = x),这样就将一个本没有数据竞争的程序变得有数据竞争了。这怎么可以呢?
实际上,这在 LLVM 里面是被允许的。LLVM 编译器的理论是,虽然程序中存在数据竞争了,但如果 c 本来就成立,那么提升前后是没啥区别的;如果 c 不成立,那作为局部变量,提升后的 c 也不会成立,好像也不会存在问题。
## 1# 和 2# 不能同时被允许!
单看前面这两种程序变换,好像都没有问题。但这两种变换不能同时被允许。
我们以下图为例,假设程序中有一个判断条件 c:
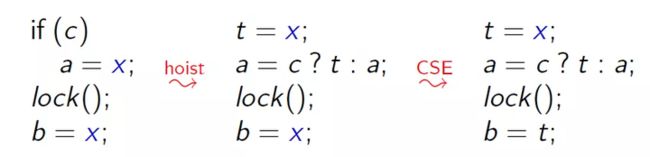
-
若 c 为 true,则将 x 的值读到 a,然后加锁 lock(),在临界区再次读 x
-
若 c 为 false,程序会在临界区的保护下访问内存 x 的值
这个例子实际上是没有数据竞争的。
针对这个例子,我们先后做 提升(hoist) 和 CSE 两步变换后,会发现,如果 c 是 false 的话,原来没有数据竞争的程序,变得有可能有竞争了;另一方面,我们在临界区里还访问到了内存里的值,这明显是有问题的。这个例子说明,提升和 CSE 这两个行为不能同时被允许。
那么现实当中大家是如何做的呢?
-
C11 标准里明确禁止了 读内存时的提升,但允许在加锁前后进行 CSE
-
LLVM 允许进行 读内存时的提升,但禁止在加锁前后做 CSE
这么看来,大家总算还是做对了,没有两个都允许。
# 我们需要怎样的内存模型?
但实际情况远比我们的例子复杂。大家可能在内存模型上或程序变换上允许了某个变换,组合起来后就会出大问题。所以说这实际上是一些非常非常绕的一些问题。
## Formal Model
因此我们 需要一个对内存模型的精确描述,而不是靠经验来约定。即使大家对编译器和处理器都很熟,基于对编译器和处理器的经验知识,可以大概预测程序的行为,但是经验不一定靠得住,而且没办法让更多的人来理解这个事情。
因此,我们在给出一个相对形式化的定义前,需要先解决几个问题:
-
像定义程序语义一样给出一个准确的、无歧义的描述出,在什么时候,程序所有可能的行为是哪些?
-
说明编译器相比于前面所讲的 SC Model 允许了哪些更多的优化,即 Weak Memory Model(WMM,或者叫 Relax Memory Model)
-
模型需要足够合理和易懂,能够让我们对程序的行为进行一些推断和预测
要做到这几点是非常困难的。当前的现状是,两大主要应用的语言 Java 和 C/C++ 的内存模型都存在不足。
## Weak Memory Model
实际上,内存模型本身可以看做开发者与编译器甚至处理器的实现者之间的重要接口。对于开发者来说,我们要理解它,才能更好地预测程序的行为;对于编译器和处理器的实现者,内存模型是我们判断优化是否可以做的依据。那么,我们期望如何定义?
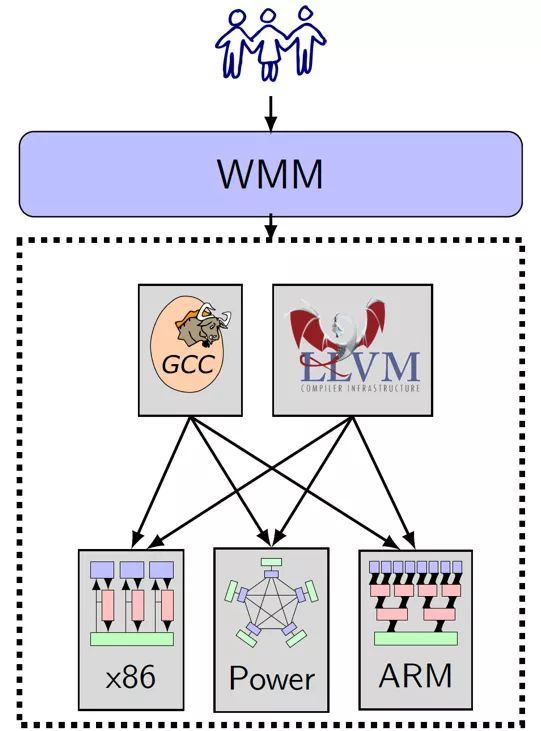
数学上要合理 Mathematically Sane比如说一个性质是 单调性 monotone。简单地说,假设你写一个程序,当我们向这个程序里插入更多的同步语句时,我如果做更多的同步,那它跟别的线程之间的交互行为的可能性只会变少,所以它可产生的可能行为只会变少,不能变多,这就是一种单调性。单调性是一个非常自然合理的要求,即不能明显违背我们的直观,否则我们没法理解我们的程序了。
不能太弱 Not Too Weak除了受前面一点的限制外,WMM 还不能允许太多的行为。允许太多的行为会加大程序员对程序行为预测的难度,程序员无法正确地理解程序所有可能的行为,就无法判断自己写的程序是否正确。
不能太强 Not Too Strong我们不能约束行为一定只有固定的几种可能。这样的话就会导致如前面所讲,有可能在硬件里面都不能保证,有可能就是说你的这个编译器的一些优化就要禁止掉。
## Defining WMM
如下图所示,我认为问题在于以下几点:
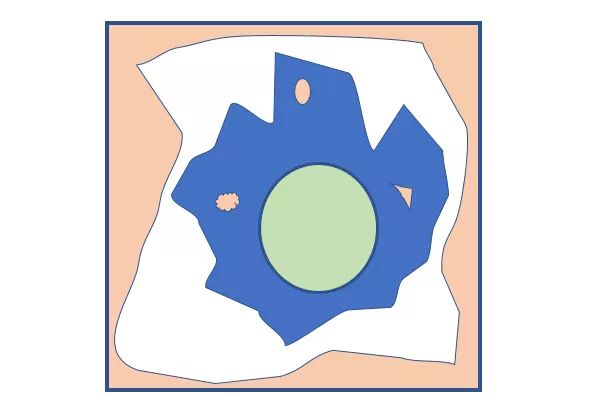
- 实际编译器 + 硬件产生的行为过于复杂,无法精确描述。
很多时候我们在编译器和处理器中引入优化时,并没有很好地考虑到并发,仅单纯能保证程序在串行的情况下,语义是符合预期的;另外,编译器和处理器的各种优化是在不同的历史时期,由不同的人将各种各样的优化引进来的。因此程序的行为是由这些累加组合而得。
鉴于这两类不属于一个特别系统的东西,因此上图中,我用 不规则的蓝色图形 来表示经过编译器和处理器后的程序可能展示出来的行为。
- SC Model:利于开发者理解,但禁止了太多优化。
我们在图中使用十分规则的 绿色圆形 来表示 SC Model,其中圆的面积是 SC Model 允许的可能行为的状态空间。SC Model 非常好懂,但是由于限制了太多的行为,因此很多外面的编译器实际产生的行为都不被允许,对应地,这些优化都不能做了。
- 明显不合理、无法接受的行为。
比如下面这个例子,其中 是否成立? 插句题外话,我不知道为什么研究 WMM 的人都很喜欢 42 这个数字,当然实际上这里可以是任意的数字。

这是一个明显不合理的行为,当然肯定不能允许。我们可以认为这些不合理的行为会落在图中浅橘色的部分。
我们可以将定义一个内存模型看做要画出图右侧的红色圆圈,如下图所示。
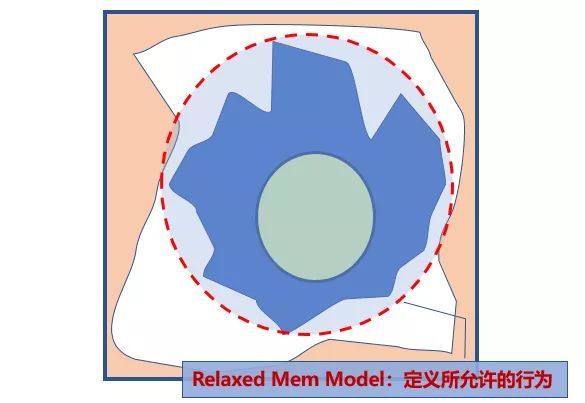
这个圆圈要:
-
尽量包含所有编译器 / 硬件行为 这个圆需要尽可能地将实际编译器与处理器优化的这个不规则蓝色图形圈进去(即,尽量地包含蓝色不规则图形)
-
边界要足够简单 尽量简单的目的是方便开发者理解(即,形状要尽量简单规则)
-
不能包含不合理行为 否则我们就很难理解程序的行为,无法推断合理的结果了(即,尽量地避开浅橘色部分)
而实际情况是,没有人知道这个不规则的边界(不合理行为)在哪里,因此如何尽可能地绕开这些不合理行为,是一个很难解决的问题。我想通过这样一个图给大家一个直观感受,为什么定义内存模型很难。
# C/C++11 内存模型
我们看一下 C/C++ 内存模型的发展过程。
在 2008 年,由 Hans-J. Boehm 与 Sarita V. Adve(大家如果做编译器相关的工作,应该会很熟悉这二位)提出一个 C++ 内存模型 的提案 [6],该 Model 是非形式化的。这篇论文发表在 PLDI 2008:

后来剑桥这帮人给出一个形式化的定义 [7],这篇论文发表在 POPL 2021。

但是大家发现这个模型仍然存在各种各样的问题,比如这个模型真的会允许刚才提到过的一个很关键的问题 Out-of-Thin-Air (OoTA)。

Out-of-Thin-Air (OoTA) Problem
大家认为编译器中并没有理由会出现 OoTA 的问题,这属于模型没定义好,就如前面所示,红色圈没画好,一不小心将这些不合理的行为都圈进去了。因此,很多人在想办法如何重新调整红色的圈,将 OoTA 排除出去。这就是后续很多人改进 C/C++ 内存模型的一系列动作,实际上现在仍然没有一个特别成功的结果。
后来,Hans-J. Boehm 在 2014 年的这篇论文 [8] 中提到,不论 Java 还是 C/C++ 大家都在尝试描述内存模型并阻止 OoTA 这种行为,并且都失败了。 因此,在 C++14 的草案中,有一个对该问题非形式化的描述,并号召大家尽量避开一些程序的写法。这个时候的大家还认为,OoTA 仅仅是因为我们没定义好,并不代表这是一个现实中可能出现的问题,我们的编译器是没有问题的。

Hans-J. Boehm 在 2018 年发表了另一篇文章,他说,一开始大家都认为 OoTA 是不会出现的,但他发现 实际上的确存在一些程序的实现,会允许一些看起来不合理的行为,这些行为都是 OoTA 的一种表现。

Hans-J. Boehm 表示,对于 C/C++11 来说, 通过一种内存次序 relaxed ordering [9],可以在编译器或者硬件中禁止掉一些优化(见文章里 Possible fixes and their cost 章节),从而真正避免 OoTA 的问题。但是这种做法有很多争议,因为禁止掉这些优化会影响程序在 ARM 或者某些 GPU 上的性能,而我们当前处于一个极致追求性能的时代。因此直到今天为止,C/C++ 的内存模型仍然一直没有采用这个方案。
近年来有大量论文一直致力于研究 OoTA 问题,例如:

Repairing Sequential Consistency in C/C++11 [10]
# Java 内存模型
Java 的内存模型也是一样。
当前的 Java 内存模型已经是第二版了,最早的版本来自 1996 年的 《The Java Language Specification》 [11]。大家认为这个模型很多优化都不被允许,是 fatally flawed 的。

然后大家开始聚集起来说要解决这个问题。在 2005 年 POPL 上一个新的 Java 内存模型 [12] 被提出,并被 Java 的新规范采用(JSR133 [13])。但其实,这个内存模型先不说存在的问题,其描述就相当复杂( 反正我尝试读了好多遍这个文章,发现非常难懂 :P)。之后,大家尝试形式化这个模型,发现里面又存在各种各样的问题 [14]。

Doug Lea(Java 并发领域的大神级人物之一)因此在 2013 年发起新一轮的 Java 内存模型更新(最新的讨论截止到 2016 年) [15],这个问题目前为止仍然没有得到很好的解决。

Java 内存模型里有一些典型的问题,比如刚才提到过的 单调性 Monotonicity。
举个例子,在下图中左侧的程序中加了更多的 同步 Synchronization(比如,将更多的东西移到临界区里,或者将原来非临界区的东西加锁保护起来),结果程序可能的行为比原先多了很多,这是非常违背我们直观的一种情况。
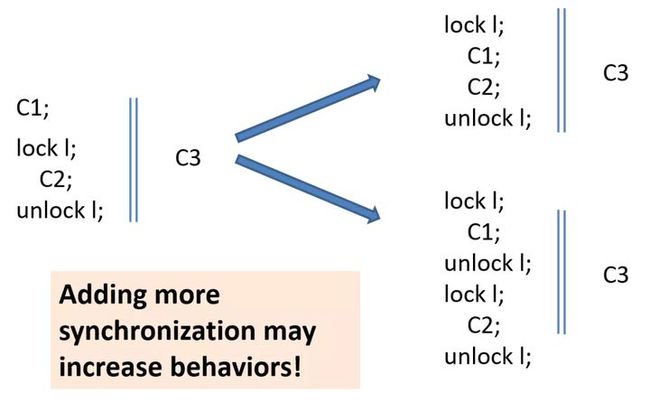
再举个例子,我们将左侧两个并发的程序 C2 与 C3 内联起来,变成串行(如图右所示),照理说也是有更多的同步,程序可能的行为应该变得更少才对,但事实上这种做法也会增加程序的行为。
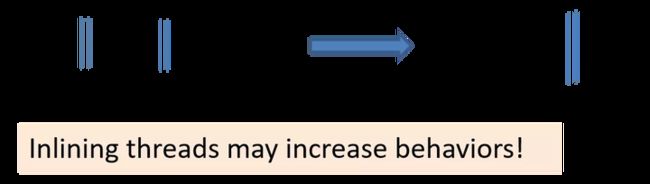
还有其他问题,这里就不展开讲了。

# Background of WMM & C11 内存模型 #
接下来,我们分别讲一下当前 C11 内存模型的情况,以及 Promising Semantics 和 Promising Semantics 2.0,这些都是为了解决前面提到过的 OoTA 而做的努力。
# WMM 介绍
简单介绍一下 WMM 的几种定义方式。
-
操作语义 Operational
-
程序变换 Transformational
-
公理语义 Axiomatic
## 操作语义 Operational
操作语义 实际上就是通过定义一个虚拟机来刻画程序可能会有的行为。
以 x86-TSO(x86 Total Store Order)为例。该模型引入了 write buffer,每次对内存进行写操作时都会先放到 write buffer 中,而不是直接写到内存里。对应地,本地每次也会优先读 write buffer。这种模型下,本地处理器与其他处理器读到的值不保证一致。我们通过这个模型来解释程序会产生什么样的行为。

注意,这个并不是 x86 下面处理器真实会发生的事情,至少不需要是真实发生的事情,我们只是需要画出这样一个模型,它可以是虚拟的,但要足够简单,又能准确刻画真实 x86 里的行为,那我们就满意了。
ARM 也有类似的内存模型,这个模型也不太好定义,相比 x86 来说 ARM 的内存模型是更弱一点的模型。这个模型在很多硬件上是可以工作的。但相对于硬件,因为编译器会对程序做更多更复杂的优化,因此这个模型在程序上是难以理解的。
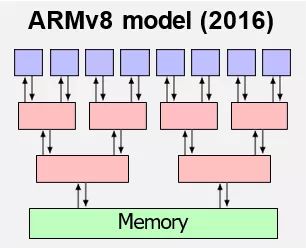
Viktor 他们后来做的 Promising Semantics,就是用这种虚拟机的方式来定义内存模型的。这些模型本身是好的,它会告诉你这些指令是如何一条条被执行的,是一个构造式、产生式的过程,结果有迹可循,因此更容易阻止 OoTA 的行为。而且这样的模型不是数学化的定义,并且对状态迁移的验证很友好,因此更为好懂。
## 程序变换 Transformational
程序变换 也是一种定义模型的方式。
TSO 还有另一个大家了解的 PSO(Partially Store Ordering,部分存储排序)都是通过程序变换的方式来告诉我们程序可能产生的行为。TSO 不允许调整内存写的前后顺序,但是允许 reorder 读和写的顺序。
![]()
但是程序变换的描述能力非常有限,甚至连 ARM 的行为都没办法描述。
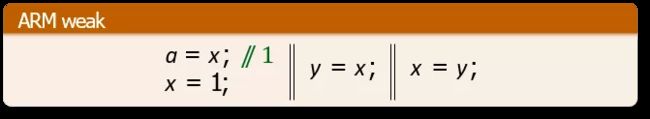
## 公理语义 Axiomatic
事实上,现在大多数模型是使用所谓公理语义的形式来描述的。
比如给定下图的程序,左侧的线程中 a = x 读到 1,对应 R x, 1,向 y 写 1 即 y =1 对应 W y, 1;右侧线程中读 y 的值即 b = y 读到 1,对应 R y, 1,然后再对 x 进行写操作 x = b,因为这里的 b 依赖上面读到的值,因此会读到 1,对应地,向 x 写 1 即 W x, 1。大家可以看到,左侧的每一条指令都会对应右侧的一个 event。我们通过公理性的描述,对每个模型定义一些前后的依赖关系,只有满足依赖关系的 events 对应指令的执行才是合理的。这些定义好的约束就是我们的内存模型。
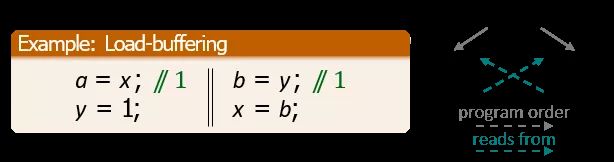
当然,如果你单独看会发现这种定义方式还是很难懂,因为它并不会告诉你这些约束是怎么来的。比如刚才例子里,它没有告诉你为什么读 x 即 a = x 时读到的值是 1。它不是 constructive 的,结果不是按照指令顺序一条条执行下来的。而由于 x 是共享变量,任何人都可以对 x 进行写操作,那么实际上我们读 x 时就会有无穷多个可能的结果。对 y 进行写操作,是确定的,而读 y 和刚才读 x 一样,也会对应无穷多个可能的结果。
但如果有一些明显不合理的行为,比如 x 和 y 的初始值是 0,在整个程序中 x 的值从来没有被写为 2,那 x 就一定不会读到 2。换句话说,你找不到一个写操作,使得我这个 读操作来源于某一个写操作(下图中绿色箭头,表示 reads from),那就表示这种是明显不合理的行为,不可被接受;只有明确可以找到对应读操作的写操作(当然还会有一些额外的要求),才是可以被接受的。
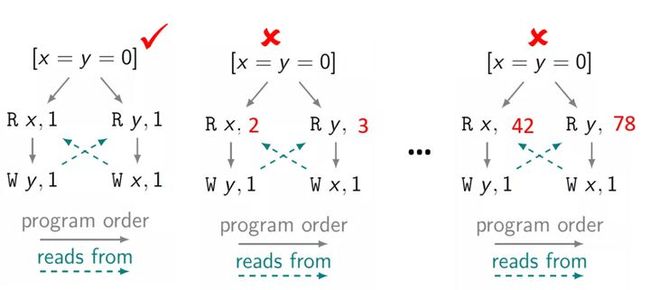
因此,你可以认为,程序在开始时会有无穷多个可能,然后一点点将明显不合理、不符合约束的可能过滤掉,最终剩下的就是可允许的行为。
这种方式可以描述出一个程序所能产生的可能行为,但它不具有构造性,那它有什么好处呢?对测试有好处。比如我们在测试过程中,日志记录到一条现象,我们通过判断这个现象是否符合我们的内存模型,是否可以使用我们定义的约束(即公理)解释。
公理语义对我们理解程序上的帮助还是比较有限的。但非常不幸地,现在 Promising Semnatics 这条线上的内存模型,大多数都是用公理语义这种方式来描述的。这也解释了为什么刚才会出现 42。因为首先它都不需要程序里有 42,默认是存在有无穷多个读操作,然后再一点点补充公理语义,提高模型的完备性,从而将不合理的行为过滤掉。
公理语义的定义不能太强,即我们不能过滤掉太多,这样会大大降低可优化的空间;又不能太弱,不能有“漏网之鱼”。这就是公理语义定义内存模型的困难之处,大家做不到,那么就一定会有“漏网之鱼”(OoTA)。使用这种方式定义内存模型,很大程度上是要负一定的责任,这也解释了为什么 C++ 的内存模型允许有 OoTA。
## More about OoTA Problem
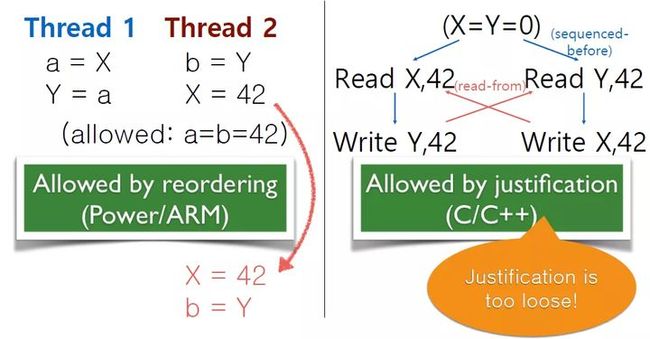
我们看一下下图的例子 [16]。a 和 b 是寄存器,X 和 Y 是共享内存,共享内存初始值都为 0,X 会写 42,这个程序中是允许 成立的。我们可以将 Thread 2 的两个执行做 reorder,整个程序的执行顺序就如图右侧所示:
先执行 Thread 2 里对 X 写 42(Write X, 2),然后执行 Thread 1 里读 a 的操作(Write Y, 42),这时候 a 读到 42(),然后执行对 Y 的写(Write Y, 42);在 Thread 2 里读 Y(Read Y, 42),会读到 42()。
C/C++ 内存模型不是这么解读的,而是看给定的行为是否可以被 validate,即读到的 42 是否可以找到一个写,从而建立一个 reads from 的关系。若可以被 validate,则表示这个行为是可以允许的。我们会发现这两边是一致的,好像这个内存模型没有问题。
"OoTA" Problem: LoadBuffering (LB)
我们再看下面这样一个例子,假设寄存器 a 和 b、共享内存 X 和 Y 的初始值都为 0。那么,在这个场景下, 就是一个典型的 OoTA 的问题。但这个场景还是被允许的。
为什么?我们先假设这里 a 和 b 是 42 的读和写,当建立下图所示的执行后,我们会发现,每一个 读都可以 justify 地找到一个写。当然,为什么写 42,是因为前面的 a 读到了 42,那为什么 a 读到 42?是因为这里有给 x 写 42。总之,这个过程被 validate 了。
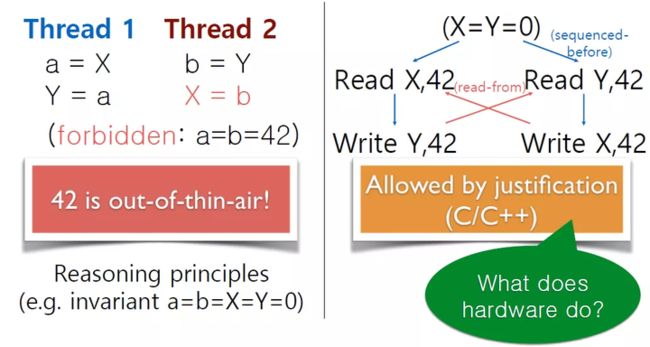
"OoTA" Problem: Classical Out-of-Thin-Air (OoTA))
这明显是一个循环论证。
对比这两个例子(如下图所示),在执行图一样、论证方式一样的前提下,左侧程序的行为是合理的,右侧程序的行为就是不合理的。C/C++ 内存模型里由于用了左侧的解读方式,导致了模型没法将这种 OoTA 的行为排除掉,所以 C/C++ 里允许了这个 OoTA 的后果。这就是问题的来源。
大家认为这实际上是一个 open problem [17]。但如刚才所讲,这个其实不算 fundamental problem,这是大家自己选的。编译器和处理器如今的设计方式就是很不规则,我们既不想反推出一个合理的内存模型,而为了保持当前模型的合理,我们又不肯接受少做一些优化,自然就会导致这样一个后果。
所以说某种意义上,我们被现实所绑架了,这个不是一个 fundamental 的天然的问题,而是现实就是如此,我们需要对这个现实做一个相对容易的解读。
以上是一个比较冗长的背景介绍,当然实际上也解释了 C/C++ 内存模型的一些问题。
# C11 内存模型介绍
C/C++ 内存模型有下图中的几类,包括原子操作和非原子操作:
原子操作 Atomic
原子操作包含了几类内存模型( SC,release,acquire,relaxed),其中越往上的模型越强,即表示 允许的顺序打乱的可能性越强(比如 SC 模型完全不允许调整顺序),而越往下则表示允许优化的可能性越多。这些内存模型允许同时有读和写的,而且因为是原子操作,也不会认为存在数据竞争。
非原子操作 Non-Atomic
即 完全没有任何顺序的约束,但是程序中不能存在数据竞争,若存在数据竞争,则 C/C++ 会认为程序的行为是 undefined 的。
C11 内存模型中数据竞争的定义是非常复杂,它的原子操作太多。
正常来说,C11 内存模型的形式化描述会类似下图的例子,给定一个程序后,会通过一堆箭头和各种关系(happens before, program order, read from, synchronize with 等)来描述要满足什么样的约束,什么样的行为是允许的,为什么允许。

An execution in C11: actions and relations (and axioms)
因此,定义 C11 内存模型是无比复杂的,或者说定义这个模型的人之前也没有做到兼顾各方,导致后面暴露出来很多定义时没意识到的问题。用刚才的几个问题评价 C11 的模型,会发现其实都没有真正做到:

更多有关 C11 内存模型缺陷的讨论可以看 Viktor 这篇发表在 POPL 2015 的论文:Common Compiler Optimisations are Invalid in the C11 Memory Model and what we can do about it [18]。
# Overview of Promising Semantics and PS 2.0 #
Promising Semantics 系列的工作就是来解决 OoTA 的问题。PS 1.0 的工作是由 MPS-SWS 的 Viktor 等人推动的,该工作 [19] 发表在了 POPL 2017,一起的还有几位当时在德访问的韩国研究者。

后来大家发现 PS 1.0 还是有 OoTA 问题,然后用 Event Structure [20] 来尽量避免这个问题。因此又提了一种方法叫 Promising 2.0 [1](发表在 PLDI 2020),在 1.0 的基础上做了一些改进。

今天主要是给大家介绍一下 Promising 系列工作。
# PS 1.0
在基本模型里,我们希望:
-
允许一些读写的 reordering:即弱一致性的架构(如 ARM)(write-read) (write-write) (read-read) (read-write)
-
每个内存地址的 coherence:语义上没必要太弱。即,不同的线程可能会观察到不同顺序在不同内存地址的写操作,但对同一内存地址的写,不同线程观察到的顺序必须一致。如下图所示,图中第三个和第四个线程,观察到写 X 和写 Y 的顺序是不一样的,这是允许的。

但是我们想禁止的是什么?想禁止如果都是对 X 的写操作。如下图例子中,左边线程里读了两次 X,第一次读到 1,第二次读到 2,这说明左边线程看到的写操作是先写了 1,后写了 2;而右侧线程里,是先读到 2,再读到 1,说明其看到的写操作顺序和左侧不同。这是我们想禁止的。
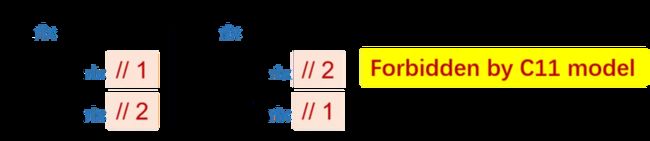
## Basic Model: Timestamps
Promising Semantics 是一个操作语义,它通过定义一个虚拟机来解释所有的行为。我们可以将内存不仅仅看做是一个地址和值的映射,而是将每一个地址看做一个消息池,所有对该地址的写,每次都打好对应的时间戳,保留在池子里。这样,每个内存地址就会变成一堆包含值和时间戳的 message,初始状态下内存的值和时间戳都是 0。除了公共内存外,每个线程都有一个自己的局部视图,这个视图表示该线程对 X 和 Y 基于某个时间戳的认知。以上可以看做一个机器的虚拟机的状态。
Reordering
那么,如何定义一个支持 reordering 的模型,即假设 X 写 1,Y 写 1,a 读 Y 的值,b 读 X 的值,那么是否会存在 的可能?我们以下图程序为例。

第一个线程里,X 写 1,对应的时间戳 + 1,此时 Y 的时间戳还是 0。那么从时间的角度来说,第一个线程看到的视图是边界(即红色线条)右侧的值。
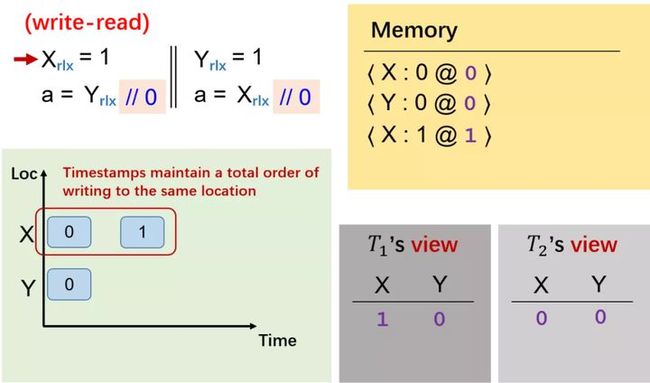
因此,此时线程一里 X 是 1,Y 还是 0。
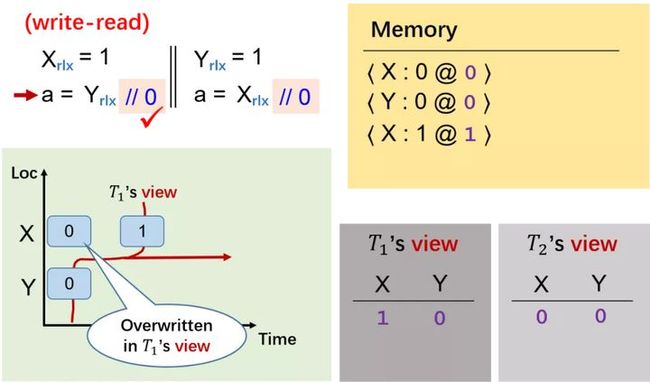
第二个线程,Y 写 1,对应的时间戳要比上一个时间戳大,我们这里选 2。然后大家可以看到,这里 X 因为还没有被读,因此值还是 0。对第二个线程来讲,其视图是蓝色边界右侧的值。

当第二个线程开始读 X 时,我们可以看到,0 和 1 都是可能被读到的。

因此,两边各自读 X 时都可以读到 0。
Per-location Coherence
那么,我们应该如何禁止在同一内存地址读到不同值的行为?请看下面的例子。

第一个线程里,X 写 1,对应时间戳给 1(初始时间戳为 0)。
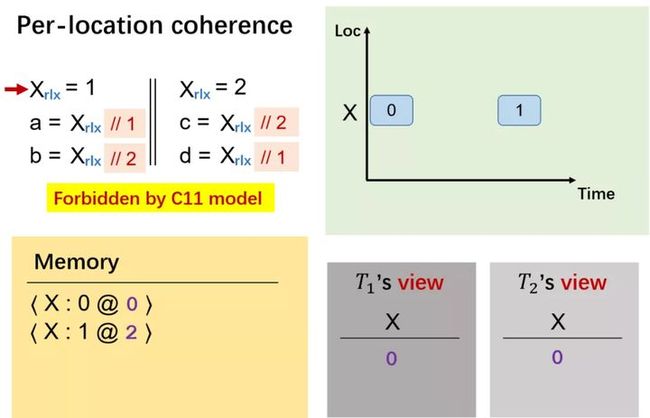
在第二个线程里我们向 X 写 2,对应时间戳给 2(比上一个时间戳大即可)。
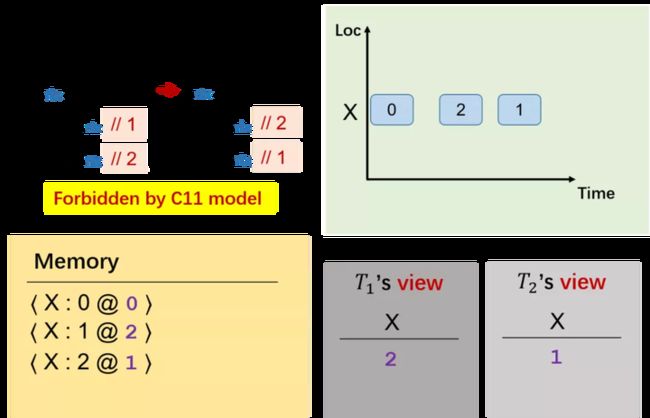
第二个线程中,c 读 X 的值时,通过其视图可以看出,其边界右侧(即蓝色线条右侧)的值是 c 可以看到的,因此,c 既可能读到 X 为 1,也可能读到 2,此时线程二的时间戳为 1。假设此时 c 读到 X 的值为 2。
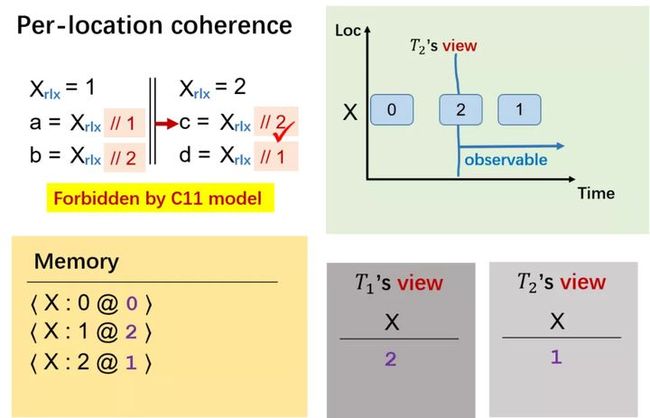
d 读 X 的值也是既可能为 1 也可能为 2,此时线程二的时间戳为 2。假设此时 d 读到 X 的值为 1。
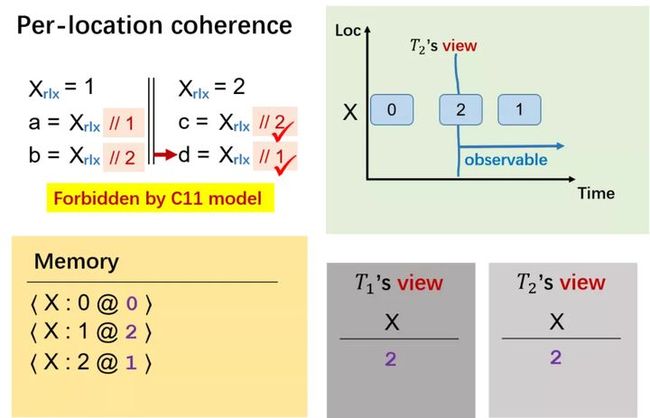
回到第一个线程 a 读 X 时,由于此时时间戳为 2,因此线程一的视图只能是红色线条右侧的值,即此时只能看到 X 的值为 1,因此 a 读到 1。而 b 此时是不会看到 X 为 2。

因此,我们通过这个内存模型禁止了违背 coherence 的这种现象。
Timestamp is not enough
有一个比较有意思的事情是,coherence 会允许 write-read,write-write,read-read 这三种行为,但是会阻止 read-write 的 reordering。如下图所示,我们希望允许将 Y 写 1 提前,从而允许 a 和 b 都读到 1。这种将写提前的行为会被 Timestamp 禁止,因此我们需要进一步扩展这个模型。

## Basic Model: Promises
怎么把写提前?大家想了一个方法,做 promising,有点像前面将的做 speculation 一样。
那么 Promises 是什么?Promises 是说我并不真的写,但是我知道我将来要写,所以我先承诺要写,然后将这个 promise 放在内存里。并且通过特殊标记记录好这个并不是真的写,而是个 promise。具体定义为:A thread can promise (at any point) to write Y = V in the future, after which other threads can read Y = V.

此时,这个 Promise 已经可以被别的线程读到了,比如第二个线程 b 读 Y 时,就可以读到 1,此时 Promise 的时间戳是 1,线程二的时间戳因此也需要更新为 1。

接下来,将 b 写到 X 里,即 X 写 1,对应 X 的时间戳是 1。

回到线程一中,a 读 X 的值读到 1。

下一步是 Y 写 1,我们发现此时满足了之前的承诺(即承诺 Y 要写 1),这个程序行为是允许的。因此,我们通过 Promise 的方式,实现了写提前的效果。

Certification can avoid OoTA
但是,此时的方式若不加约束的话,还会引入 OoTA 的问题。
大家看下面的例子(X 和 Y 初始值都为 0),和刚才不一样的是,这个例子里压根就没有写 1 的操作。我们的问题是,有没有可能 a 和 b 都读到 1?如果有可能的话,这就是 OoTA(C11 里是可能的)。

按照前面的 promise,我们是阻止不了这种行为的。具体来讲,我们还是 promise 未来一定会给 Y 写 1,那么我们在线程二中 b 读 Y 时会读到 1。然后 1 写到 X 中,回到线程一,a 读 X 读到 1,并且将 a 写到 Y 中,此时我们满足了前面的 promise。

上面的问题在于,我们 promise 的事情后面真的做了,但做到这件事的前提又是 promise 的存在,即对 promise 形成了循环依赖。因此为了避免这种行为,不是任何 promise 都是能被接受的。
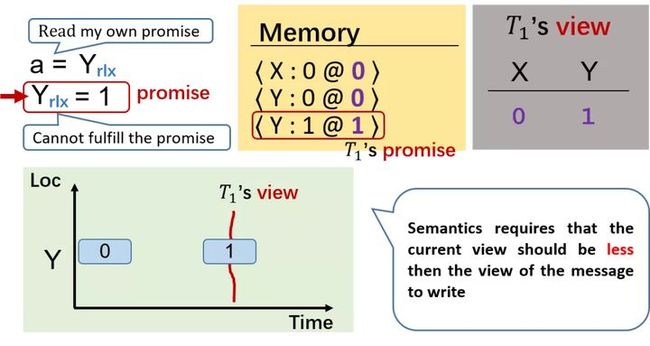
那么我们的办法是,对 promise 做 certification。即,promise 保证未来一定兑现,但是兑现 promise 时不能依赖于别人的帮助,因为别人可能已经依赖之前的 promise 了。大家可以类比时间悖论来理解,当你从未来穿越回来,你只能观察,不能对它形成影响,或者说未来的你跟现在你不能见面或者怎么着,不然就形成了悖论。
我们再看下面的例子,这种 OoTA 的问题在 C11 的内存模型中是允许存在的。在这个例子中,我们给 Y 写 a,a 读 X 的值,这里 X 可能是任意的值,那么兑现 promise 时 Y 可能是任意的值写给 a,因此这个例子中,我们无法兑现 promise,从而阻止了这个 OoTA 的发生。

还有一点是,不能在同个线程内形成循环。如下面例子所示,我们 promise 在未来 Y 会写 1,然后基于 promise 在当前线程里将 Y 的值写给 a,这时 a 会读到 1。这相当于我们先依赖自己的 promise,得到 a 后再通过该 promise 的依赖来 validate 我们的 promise。这也是一种循环,所以这种场景也是不能被允许的。
以上是对 Promising Semantics 1.0 的简单介绍。
# Problems and PS 2.0
PS 2.0 Youtube: https://www.youtube.com/watch?v=Z6W7_xDr2pY
## PS 1.0 的问题
PS 1.0 已经能够阻止一些 OoTA 问题了,但事实上并没有完全阻止。一个最主要的问题是,很多的全局 optimization 不能被支持了。如刚才所讲,我们 justify promise 的时候,只能用当前的本地的线程局部视角去看,而不能依赖于任何其他线程的知识。
我们看下面这个例子 [21](这个例子来自 Promising 2.0 在 PLDI 2020 的视频分享),SWAP() 是原子操作,表示交换,X 的初值为 0,a = SWAP(X, 1) 即 a = X; X = 1:
-
线程一:如果 a < 100,Y 会写 1
-
线程二:如果 Y 的值是 1,则 X 写 42
-
a=42?
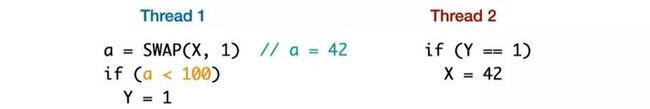
上面例子在 promising semantics 1.0 中是不允许的。这相当于将 Y 的写提前(即提前 Y = 1)。
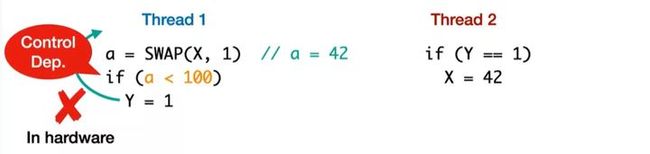
但编译器实际上会做全局优化(Global Optimization)。假设编译器的全局视角了解到,不管 X 怎么变,X 都不会超过 100(即 X < 100 全局都成立),那么编译器就可以将这里的 control dependency 去掉(即去掉 if (a < 100))。这种情况下,我们就可以将 Y 的写提前。实际情况中,编译器在基于全局的知识下,是可以做这样的优化,因此述例子是可以被允许的。
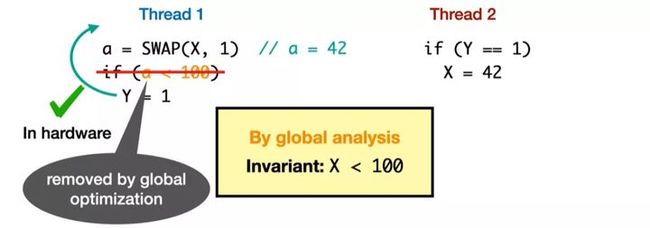
在前面介绍 PS 1.0 时提过,justify promise 时,promise 需要在单个线程下满足任何将来可能的状态。任何将来可能的状态里,会包含一些真的会出现的状态,也可能包含一些永远不出现的状态,如果我们要求 promise 都满足的话,这个约束太强了,编译器基于这样的强约束下去做优化,很多的优化就不能被允许。作者认为,这就是 PS 1.0 问题的本质,即 需要对甚至不可能的未来进行认证,因此 Promising Semantics 2.0 主要就是用于解决这一类的问题。

## PS 2.0
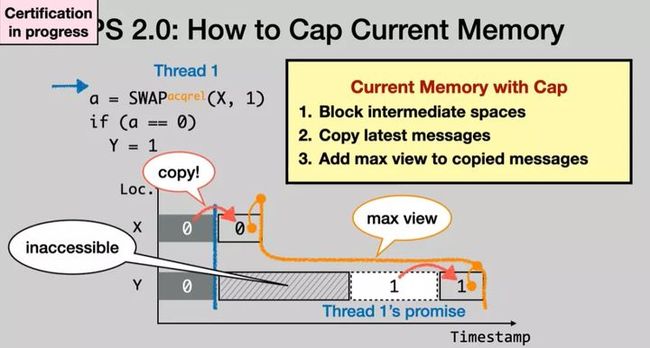
PS 2.0 解决上面问题的方式是:Certification against "Current Memory with Cap":
-
即只考虑基于当前的内存(Current Memory)下真正可能执行出来的那些行为,过滤掉永远不会发生的行为。基于当前内存下可能产生的结果来 justify promise 可以减弱我们对模型的约束。
-
为了防止约束太松,PS 2.0 对上一条改进做法增加了限制,即 不允许 promsing acquire 的 atomic updates,这个限制被叫做 Cap。(注:atomic updates 即 原子读取-修改-写入操作,或称为 RMW 操作(Read-Modify-Write operations),本质上是对同一位置的一对先读后写的访问,这对访问有一个额外的原子性保证:读取的信息紧接在写入的信息之前。)
下图是 PS 2.0 的相关规则。
# 总结 #
# PS 2.0 小结
PS 2.0 号称解决了我们前面提到的问题,一方面,它通过增加 current memory 的约束,支持了 global optimizations;同时,capped memory 又帮助程序保留了更多的 DRF guarantees(Data-Race-Free guarantees)。
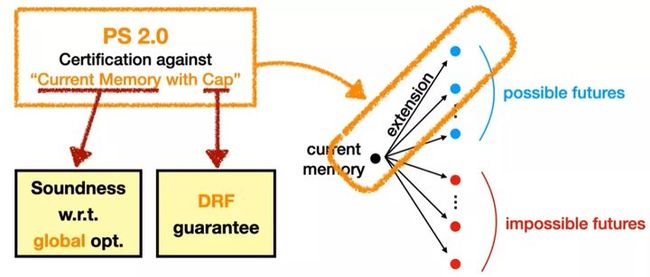
Summary of Promising Semantics 2.0
PS 2.0 还解决了一些其他 1.0 存在的问题:
-
Problems with 1.0
-
unsoundness of register promotion
-
less efficient compilation to ARMv8
-
Solutions in PS 2.0: Reservation
# 一些思考
我们为什么关心弱内存模型,或者说谁应该关心弱内存模型呢?
Language Design
这个问题听上去像纯学术界要解决的事情,而事实上,当你设计一个编程语言时,都要回答这个问题,你的语言里变量的读写存在并发时,它之间的先后关系是什么?
前面提到过,Java 和 C/C++ 实际上都没有回答好这个问题。现在新的语言基本上都学精了,大家都学 C/C++,但凡存在数据竞争,就说程序的行为是 undefined 的,语言概不负责。Java 一开始就比较吃亏,它号称是 type-safe 的,因此当存在数据竞争时,Java 仍然想将程序的行为描述出来,这很大程度上增加了其内存模型定义的困难。
Compiler Implementation
内存模型可以给编译器和硬件的实现,提供一些原则性的要求,告诉编译器哪些优化是可以做的,哪些优化不可以做。
Advanced Libraries
大多数内存模型如果不用关注效率的话,比如 C++ 里,那么 SC atomic 就很好,程序也很好理解,内存模型也很好定义这样程序的行为。
但是,对性能的追求往往是无止境的。我们总想放松对模型的约束,总担心这些约束会影响到程序性能。为了追求性能,会采用一些诸如弱的同步原语(synchronization primitives),移除 false,甚至引入良性数据竞争(benign data race)的内存操作。我们需要论证这些操作是否正确,程序各种可能的行为是否合理,这时就需要我们对内存模型有所了解。
Is PS 2.0 satisfactory?
本次分享简单给大家梳理了一下脉络,PS 2.0 算是当前来看起来比较有希望的内存模型。但是,PS 2.0 是否真的彻底解决问题了,其实也不一定。这个方向近几年也是一个研究热点,所以未来会不会有 PS 3.0,PS 4.0,这都难讲。
刚才讲,这实际上是一个“烂坑",这并不是一个 fundamental 的问题,而是因为大家做工程的时候,没有足够小心,没有考虑到并发,而是先从串行的角度进行了优化,后来又不愿意牺牲性能,导致我们不得不接受这些各式各样的行为,并尝试将其定义为一个相对简单的模型。这可能也是一个可以继续讨论的问题。
今天的分享就到这里,谢谢大家。
参考
[1] Lee, Sung-Hwan & Cho, Minki & Podkopaev, Anton & Chakraborty, Soham & Hur, Chung-Kil & Lahav, Ori & Vafeiadis, Viktor. (2020). Promising 2.0: global optimizations in relaxed memory concurrency. 362-376. DOI: 10.1145/3385412.3386010.
[2] Lamport, Leslie (Sep 1979). "How to make a multiprocessor computer that correctly executes multiprocess programs". IEEE Transactions on Computers. C-28 (9): 690–691. DOI: 10.1109/TC.1979.1675439.
[3] Dekker's algorithm - Wikipedia https://en.wikipedia.org/wiki/Dekker's_algorithm
[4] Weak Memory Concurrency in C/C++11 and LLVM, by Viktor Vafeiadis. On Max Planck Institute for Software Systems (MPI-SWS), March 2017. https://llvm.org/devmtg/2017-03//assets/slides/weak_memory_concurrency_in_c_cxx11_and_llvm.pdf
[5] Common subexpression elimination - Wikipedia https://zh.wikipedia.org/zh-tw/公共子表达式消除
[6] Hans-J. Boehm and Sarita V. Adve. 2008. Foundations of the C++ concurrency memory model. In Proceedings of the 29th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI'08). Association for Computing Machinery, New York, NY, USA, 68–78. DOI: https://doi.org/10.1145/1375581.1375591
[7] Mark Batty, Scott Owens, Susmit Sarkar, Peter Sewell, and Tjark Weber. 2011. Mathematizing C++ concurrency. In Proceedings of the 38th annual ACM SIGPLAN-SIGACT symposium on Principles of programming languages (POPL'11). Association for Computing Machinery, New York, NY, USA, 55–66. DOI: https://doi.org/10.1145/1926385.1926394
[8] Hans-J. Boehm and Brian Demsky. 2014. Outlawing ghosts: avoiding out-of-thin-air results. In Proceedings of the workshop on Memory Systems Performance and Correctness (MSPC'14). Association for Computing Machinery, New York, NY, USA, Article 7, 1–6. DOI: https://doi.org/10.1145/2618128.2618134
[9] Relaxed Ordering - Memory Order. by cppreference https://en.cppreference.com/w/cpp/atomic/memory_order#Relaxed_ordering
[10] Ori Lahav, Viktor Vafeiadis, Jeehoon Kang, Chung-Kil Hur, and Derek Dreyer. 2017. Repairing sequential consistency in C/C++11. In Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI 2017). Association for Computing Machinery, New York, NY, USA, 618–632. DOI: https://doi.org/10.1145/3062341.306235
[11] James Gosling, Bill Joy, and Guy L. Steele. 1996. The Java Language Specification (1st. ed.). Addison-Wesley Longman Publishing Co., Inc., USA.
[12] Jeremy Manson, William Pugh, and Sarita V. Adve. 2005. The Java memory model. In Proceedings of the 32nd ACM SIGPLAN-SIGACT symposium on Principles of programming languages (POPL'05). Association for Computing Machinery, New York, NY, USA, 378–391. DOI: https://doi.org/10.1145/1040305.1040336
[13] JSR 133: JavaTM Memory Model and Thread Specification Revision https://jcp.org/en/jsr/detail?id=133
[14] Aspinall, David. “Java Memory Model Examples: Good, Bad and Ugly.” (2007).
[15] JEP 188: Java Memory Model Update https://openjdk.java.net/jeps/188
[16] A Promising Semantics for Relaxed-Memory Concurrency. On Shonan Meeting, May 2017. https://sf.snu.ac.kr/publications/promise-talk-gil.pdf
[17] Batty, Mark, Memarian, Kayvan, Nienhuis, Kyndylan, Pichon-Pharabod, Jean, Sewell, Peter (2015). The Problem of Programming Language Concurrency Semantics. In 24th European Symposium on Programming, ESOP 2015. DOI: 10.1007/978-3-662-46669-8_12.
[18] Viktor Vafeiadis, Thibaut Balabonski, Soham Chakraborty, Robin Morisset, and Francesco Zappa Nardelli. 2015. Common Compiler Optimisations are Invalid in the C11 Memory Model and what we can do about it. In Proceedings of the 42nd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL '15). Association for Computing Machinery, New York, NY, USA, 209–220. DOI: https://doi.org/10.1145/2676726.2676995
[19] Jeehoon Kang, Chung-Kil Hur, Ori Lahav, Viktor Vafeiadis, and Derek Dreyer. 2017. A promising semantics for relaxed-memory concurrency. In Proceedings of the 44th ACM SIGPLAN Symposium on Principles of Programming Languages (POPL 2017). Association for Computing Machinery, New York, NY, USA, 175–189. DOI: https://doi.org/10.1145/3009837.3009850
[20] Soham Chakraborty and Viktor Vafeiadis. 2019. Grounding thin-air reads with event structures. Proc. ACM Program. Lang. 3, POPL, Article 70 (January 2019), 28 pages. DOI: https://doi.org/10.1145/3290383
[21] Promising 2.0 - Global Optimizations in Relaxed Memory Concurrency, from ACM SIGPLAN on Youtube. https://www.youtube.com/watch?v=Z6W7_xDr2pY
