windows kafka mq 安装和使用介绍 及踩坑记录 及集群架构kafka实现架构 各自运行机制 一次性看明白
目录
介绍
安装集群
简单介绍按照步骤
zookeeper 安装
kafka安装
基础配置3个节点
在配置三个启动bat
重点
常见问题
内存不够配置文件中增加如下
java.io.IOException: Map failed
基础使用
创建主题
查看创建
生产者
消费者
应用场景
kafka一些原理和特点
基准测试 内置性能测试 生产者 消费者 tps
基准测试
测试步骤:
测试结果:
java 写
集群架构
幂等性
生产者写入分区策略
消费者组再均衡
副本机制
低级api 高级 api
Kafka-eagl监控工具
Ar 、ISR 、 OSR 已分配副本 同步中副本 、不同步副本
Controller
执行leader 重新分配
Kafka读写流程
LEO log end offset
物理存储 稠密索引 稀疏索引
Kafka物理存储
深入了解读数据流程
删除消息
*消息不丢失机制
Broker数据不丢失
生产者数据不丢失
消费者数据不丢失
**消息丢失流程*
**重复消费*
**数据库事务保证成功(数据不丢失,解决重复消息,保证执行一次)*
数据积压
定期清理
java 示例代码
java 生产消息示例代码
java 消费消息
介绍
更详细的安装细节可以从网上搜非常多,这里主要做重点总结和踩坑经验,在众多的文章中,只要保证在重点中有的内容,都加上了,服务一定可以稳定运行正常使用。看踩坑经验省去踩坑,此篇文章主要介绍此些方面。
安装集群
简单介绍按照步骤
zookeeper 安装
①下载Zookeeper地址:https://zookeeper.apache.org/releases.html
②解压文件
③在文件E:\zookeeper\zookeeper-3.7.0内,新增两个文件夹,分别命名为dataDir和dataLogDir
④进入 E:\zookeeper\zookeeper-3.7.0\conf 文件内,复制zoo_sample.cfg文件,并将新复制的文件命名为zoo.cfg,修改文件zoo.cfg内容
修改内容
dataDir=E:\zookeeper\zookeeper-3.7.0\dataDir
dataLogDir=E:\zookeeper\zookeeper-3.7.0\dataLogDir⑥运行Zookeeper: 打开cmd然后执行zkserver 命令
kafka安装
①下载kafka地址:http://kafka.apache.org/downloads.html
②解压文件
本文:解压到 E:\kafka\kafka_2.13-2.8.0
③进入E:\kafka\kafka_2.13-2.8.0\config文件内,修改文件server.properties
log.dirs=E:\kafka\kafka_2.13-2.8.0\logs④执行启动kafka $.\bin\windows\kafka-server-start.bat .\config\server.properties
到此 单机kafka就启动了,接下来看集群版本如下
基础配置3个节点
#
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.check.interval.ms=300000
group.initial.rebalance.delay.ms=0
#
zookeeper.connect=127.0.0.1:2181
zookeeper.connection.timeout.ms=18000
host.name=localhost
port=9001
listeners=PLAINTEXT:// localhost:9001
advertised.listeners=PLAINTEXT:// localhost:9001
broker.id=1
log.dirs=/tmp/kafka/logs1
修改重点9002
host.name=localhost
port=9002
listeners=PLAINTEXT:// localhost:9002
advertised.listeners=PLAINTEXT:// localhost:9002
broker.id=2
log.dirs=/tmp/kafka/logs2
9003
port=9003
listeners=PLAINTEXT:// localhost:9003
advertised.listeners=PLAINTEXT:// localhost:9003
broker.id=3
log.dirs=/tmp/kafka/logs3
在配置三个启动bat
依次启动
d:
cd D:\kf\kafka\kafka_2.12-3.4.0\bin\windows
kafka-server-start.bat ../../config/server1.properties
pause
endlocal
d:
cd D:\kf\kafka\kafka_2.12-3.4.0\bin\windows
kafka-server-start.bat ../../config/server2.properties
pause
endlocal
d:
cd D:\kf\kafka\kafka_2.12-3.4.0\bin\windows
kafka-server-start.bat ../../config/server3.properties
pause
endlocal
重点
如果日志库id 单机集群有错误的覆盖要删除否则报错起不来
listeners=PLAINTEXT:// localhost:9003
advertised.listeners=PLAINTEXT:// localhost:9003
要带上 PLAINTEXT://
单机不开启这俩个也没啥事
常见问题
内存不够配置文件中增加如下
set JAVA_OPTS=-server -Xms512m -Xmx512m -XX:PermSize=256m -XX:MaxPermSize=256m。java.io.IOException: Map failed
要么就是内存配置大了,本机不够用,要么就是小了启动不起来,调调即可,大不好使那就配置小点灵活分析。
set KAFKA_HEAP_OPTS=-Xmx256M -Xms256M
set KAFKA_HEAP_OPTS=-Xmx512M -Xms512M
set KAFKA_HEAP_OPTS=-Xmx1G -Xms1G基础使用
一般用于测试下安装的结果怎么样,保证可以正常运行
创建主题
bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
kafka-topics.bat --create --topic quickstart-events --bootstrap-server localhost:9092查看创建
kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
kafka-topics.bat --describe --topic quickstart-events --bootstrap-server localhost:9092生产者
$ bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
kafka-console-producer.bat --topic quickstart-events --bootstrap-server localhost:9092This is my first event
This is my second event消费者
$ bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
kafka-console-consumer.bat --topic quickstart-events --from-beginning --bootstrap-server localhost:9092This is my first event
This is my second event应用场景
- 异步处理:单主任务多子任务并发异步处理
- 项目解耦:上下游,消息规范,代码可以随意开发
- 流量消峰:
- 一般情况:618 双11 一般数据库会成为瓶颈
- 解决方式:先把消息存到消息列队中,提示客户等待中(客户看到等待5分钟,等待5分钟后再刷新,比较人性化)
- 大数据日志处理:如用户审计日志用户点击,发送到消息列队,任务再去消费记录ES等>spark消费大数据汇总>生成redis报告
kafka ui
https://github.com/provectus/kafka-ui/releases
GitHub - provectus/kafka-ui: Open-Source Web UI for Apache Kafka Management
kafka tool
https://www.kafkatool.com/download.html
kafka一些原理和特点
基准测试 内置性能测试 生产者 消费者 tps
基准测试

基准测试(benchmark testing)是一种测量和评估软件性能指标的活动。我们可以通过基准测试,了解到软件、硬件的性能水平。主要测试负载的执行时间、传输速度、吞吐量、资源占用率等。
基于1个分区1个副本的基准测试
测试步骤:
1.启动Kafka集群
2.创建一个1个分区1个副本的topic: benchmark
3.同时运行生产者、消费者基准测试程序
4.观察结果
4.1 创建topic
bin/kafka-topics.sh --zookeeper node1.itcast.cn:2181 --create --topic benchmark --partitions 1 --replication-factor 1
4.2 生产消息基准测试
在生产环境中,推荐使用生产5000W消息,这样会性能数据会更准确些。为了方便测试,课程上演示测试500W的消息作为基准测试。
bin/kafka-producer-perf-test.sh --topic benchmark --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=node1.itcast.cn:9092,node2.itcast.cn:9092,node3.itcast.cn:9092 acks=1
测试结果:
吞吐量
93092.533979 records/sec
每秒9.3W条记录
吞吐速率
(88.78 MB/sec)
每秒约89MB数据
平均延迟时间
346.62 ms avg latency
最大延迟时间
1003.00 ms max latencyjava 写
引入pom.xml
Kafka-client.jar
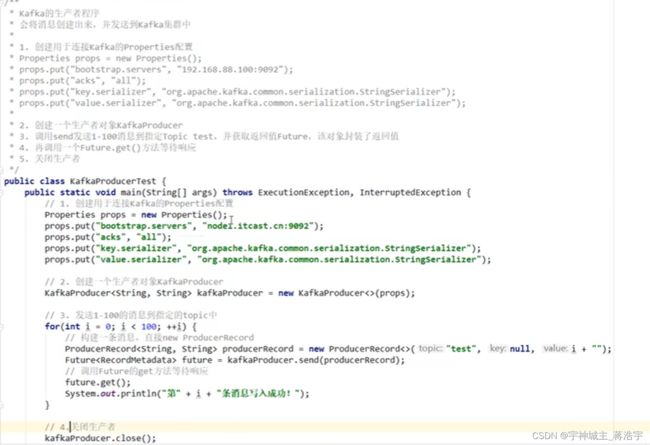
-
- 服务器地址
- Acks kafka策略
- Key val Senaizer 序列化方式
- 创建生产者
- 调用send发送 producerRecor 封装的key val
- 调用futue.get() 获取响应
- 关闭生产者
- Offset
消费者
Properties p = new Properties();
- 服务器地址
- Group.id 消费组
- 自动提交offset
- 自动提交offsest的时间间隔
- Group.id 一个消费组中一起消费()
- Offset 拉取模式
- 一批一批的拉去
生产者同步等待发送消息

生产者异步回调发送消息
成功或者异常
匿名内部类实现 callback()
- 主题
- 分区id
- 偏移量

集群架构

分区=分布式
副本=备份和数据服务-副本一般大于1 可以容错
消费者指定分区
生产者指定分区
Offset = 偏移量 存在 zookeeper 中
可以自动提交offset 到 zookeeper
Offset 对应分区

桶 是服务器 生产者消费者链接桶
集群有多个桶注册实现负载均衡
主题多个,一个主题有多个分区
逻辑结构果审查消费都要指定topic
分区是分布式,topic 可以在多个分区中
消费组消费对应的topic配置group.id 一样消费者属于通一个组
Offset 偏移量,相对消费者,分片可以通过offset拉去数据
多个分区对应多个消费者
俩个消费者消费一个分区=一个等待一个消费
多少个分区,只能被同一个分组中多个少个消费者消费
幂等性
防止重复一模一样数据
如果一个任务生成失败,重试,多次可能出现幂等性问题一样值
Sequence Number (递增id)+PID 和生成这一起发送,kafka 检查,保存成功返回ack
Sequence Number (递增id)+PID实现生产者的防止幂等性
- 生产者 发送到分区,kafka 保存到分区,返回一个ack ,若果失败,生产者会重新发送
- Kafka开启幂等性
- Kafka 生成消息的时候会增加一个pid 生产者唯一编号,和sequencenumber 最大消息递增
- 发消息会练着pid和sequence number 一块发送
- Kafka 接受道下次,会将消息和pid sequence number 一并保存小赖
- 如果ack响应失败,生产者重试,再次发送消息,kafka会根据pid和 sequence number 是否保存同一条消息
- 判断条件,生产者发过来的sequencenumber 是否小于等于分片中的sequence
- 实现防止重复
生产者写入分区策略
- 轮询分区
- 随机分区
- 按照key分区
- 自定义策略
乱序问题
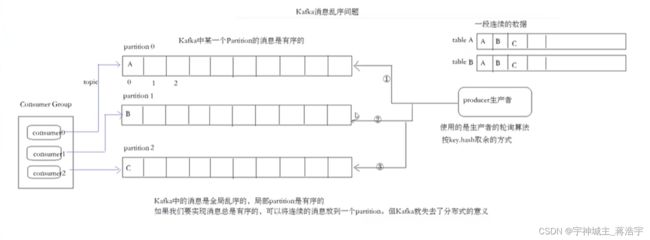

Key = null 默认 轮询 规则
消费者组再均衡
- 消费者数量发生变化,触发
- 订阅主题数量发生变化,触发
- 订阅分区数量发生变化,触发
触发,所有消费者暂停等待,重新分配规则执行(均衡消费者)
-
-
-
- 消费者规则
-
-

Range范围分配策略
8%3 3 3 2
RoundRobin 轮询
Stricky 粘性分配
发生再分配的时候尽量和之前一样
副本机制
数据丢失,依然保证数据可用
生产者Ack 规则:
- -1 or All 全部副本同步,再发一下一条,性能稍低一点,保证数据不丢失
- 0 不等待副本同步,性能最好会有概率数据丢失,性能高
- 1 成功写入领导分区,再发下一条(一个分区有一个领导),性能中
分区有 领导 和 随从 :
- 领导为了消费数据是一直的,只能从一个分区中读写消息
- Follower 事情做同步数据 backup
低级api 高级 api
- 低级api操作性更强
- 高级api操作内容少简单集成

Kafka-eagl监控工具
- KAFKA-eagle 监控集群可视化工具
EFAK
开启 kafka jmx 端口
安装教程:视频
018.安装Kafka egale_哔哩哔哩_bilibili
安装教程:文章
【kafka可视化工具】kafka-eagle在windows环境的下载、安装、启动与访问_kafka eagle下载_No8g攻城狮的博客-CSDN博客
-
-
-
- 分区的leader 与follower
-
-
- 每个分区都有一个leader实现均衡
- Follower 制作副本,leader挂掉的时候替补上去
Ar 、ISR 、 OSR 已分配副本 同步中副本 、不同步副本
- AR分区所有已分配副本
- ISR 在同步中的副本
- OSR 不同步副本
如果有一个节点挂掉,分区领导会渠道其他地方当上领导 保持分区总数到位
应为数据量大要保证性能所以尽快选举领导
如此设计副本作为及时选举当上领导实现高性能
举个例子
0、1、2 节点 三个 副本 0挂掉 0的领导会在 1 or 2 上马上出现领导,实现保证分区全在
Controller
每个桶中有一个 controller 执行api
- 每个节点启动都会去zk 上申请成为 controller
- 如果有一个节点挂掉 会再次申请 controller
-

执行leader 重新分配

Kafka读写流程
写流程:
- 通过zookeeper 找leader
- 分配开始读写
- Isr中的副本同步数据,并返回给leader ack
- 返回给 分片ack
读流程:
- 通过zookeeper 找leader
- 通过zookeeper 找到 消费者对应的offset
- 然后从offset顺序拉去
- 提交offset 自动提交 手动提交
LEO log end offset
文件默认最大1个G

物理存储 稠密索引 稀疏索引

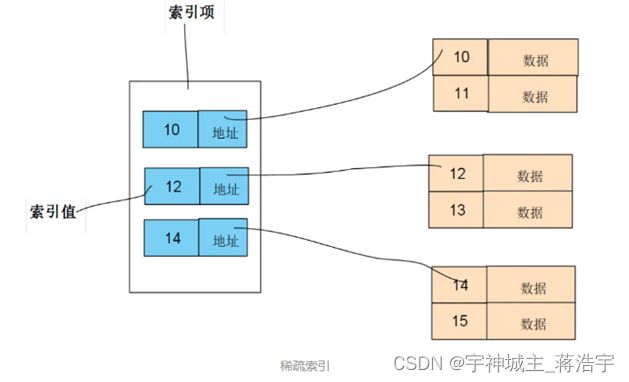
- 稀疏索引需要的空间小,占用内存也小,但是查询次数更多,速度较慢。
- 稠密索引占用空间大,但是查询次数更少,速度更快。
- Offset 找对应的数据
- 全局offset 找到对应的分片,分片对应offset 对应多个文件每个文件对应单独的offset
- 对应稀疏索引 俩层索引寻址
分片油多个文件组成,每个文件设置大小默认1G
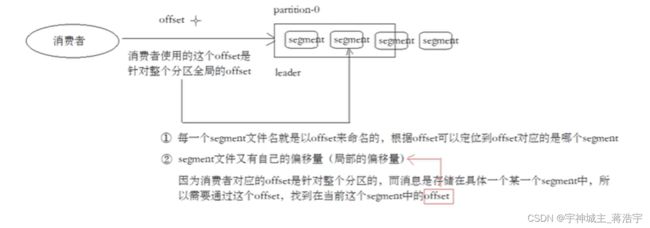
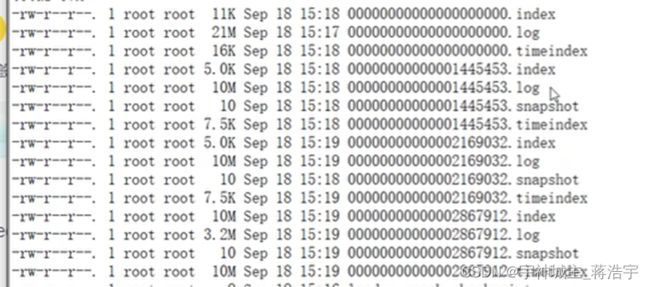
- Segment 段包含 index log timeindex snapshot
Kafka物理存储
- Topic
- Parition
- Segment
- Log数据文件
- Index索引文件
- Timeindex 稀疏索引
深入了解读数据流程
- 消费者offset 针对一个 分片找到 全局offset
- 根据这个全局offset找到对应的segment组的局部offset
- 根据全局的offset可以从index稀疏索引找到对应数据的位置
- 开始顺序读取
删除消息
Kafka定期清理数据,一次删除对应的 segment段的数据
Kafka日志管理器 会根据配置删除
*消息不丢失机制
Broker数据不丢失
所有写都写到leader 副本保存,leader崩溃,副本还有数据,所以不会丢失,另外 isc,数据都是同步到副本才返回写入成功。
生产者数据不丢失
ACK = -1 or all 全部同步数据不丢失
ACK = 0 丢失
ACK = 1 少量丢失
消费者数据不丢失
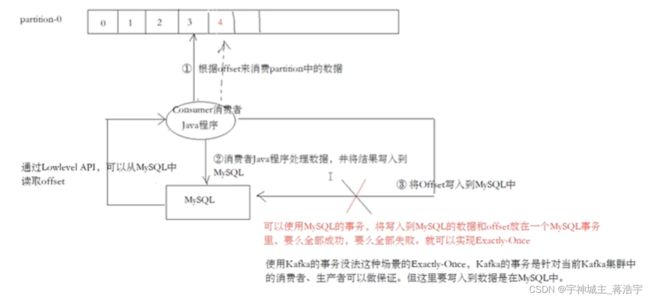
只要记录好offset就不会丢失,要保持好offset。,先保证数据库或redis记录好 offset 后在处理返回。
Mq》消费者》数据库
Mq<(提交offset)消费者<(保存成功)数据库

**消息丢失流程*

**重复消费*
写入mysql成功,写入zookeeper失败,就会出现重复消费

**数据库事务保证成功(数据不丢失,解决重复消息,保证执行一次)*
把提交offset 和放到数据库事务中,offset提交成功,提交数据库中的事务
数据积压
例如 数据库提交报错,导致积压,开发查日志解决
消费超时 网络抖动
建议降级慢点发
定期清理
日志删除
日志整合压缩
如:相同的key报错最后一个
设置定期删除
- 基于时间保留策略 默认7天
- 基于文件大小保留策略
- 基于日志起始偏移量策略
# 启用删除主题
delete.topic.enable=true
# 检查日志段文件的间隔时间,以确定是否文件属性是否到达删除要求。
log.retention.check.interval.ms=1000



java 示例代码
java 生产消息示例代码
@Test
public void testProducer1() throws InterruptedException {
Properties prop = new Properties();
prop.put("bootstrap.servers", "localhost:9092");
prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
prop.put("acks", "all");
prop.put("retries", 0);
prop.put("batch.size", 16384);
prop.put("linger.ms", 1);
prop.put("buffer.memory", 33554432);
String topic = "test02";
KafkaProducer producer = new KafkaProducer<>(prop);
int i = 0;
while (true) {
i++;
Thread.sleep(600);
// for (int i = 0; i < 1000; i++) {
final String key = i + "";
producer.send(new ProducerRecord(topic, key, key+" hello " + UUID.randomUUID()), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
System.out.println(key + " send success");
} else {
System.out.println(key + "send fail");
}
}
});
}
// producer.close();
}
java 消费消息
public static final String brokerList = "localhost:9092";
@Test
public void testConsumer1() {
String recordStrFormat = "offset = %d, key = %s, value = %s\n";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "group1");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", 1000);
props.put("session.timeout.ms", 30000);
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer consumer = new KafkaConsumer(props);
//test test2 为topic的名字
consumer.subscribe(Arrays.asList("test", "test11","test02"));
try {
while (true) {
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records) {
System.out.printf((recordStrFormat) + "%n", record.offset(), record.key(), record.value());
}
}
} finally {
if (null != consumer) consumer.close();
}
}
ok

持续更新