postgresql应用开发者指南
内容
- 基本SQL语法
- 数据类型和操作符
- 数据库对象类型
- 高级SQL用法
- 事务隔离级别
锁
- 触发器、事件触发器、规则
- 表继承和分区表
- 异步消息
基本SQL语法
- 大小写
- 建表
- select into & create table as
- DML
- COPY
- 排序
- 聚合
- DISTINCT和DISTINCT ON
- 表连接
- 组合查询
- ALL|ANY|SOME
- 条件表达式
- 窗口函数
ddl in tran SQL是结构化查询语言(STRUCTURED QUERY
LANGUAGE)的简称,它是最重要的关系型数据库操作语言。
SQL语句一般分为DQL、DML、DDL几类。
DQL:数据查询语句,常用的就是SELECT查询命令,用于数据查询;
DML:数据操纵语言(Data Manipulation Language),主要用于插入(INSERT)、更新(UPDATE)、删除数据(DELETE)。
DDL:数据定义语言(Data Definition Language),主要用于创建、删除,以及修改表、索引等数据库对象语言。
建表
CREATE TABLE code_master (
ct_seq_no int4 NOT NULL DEFAULT NULL,
code varchar(300) NOT NULL DEFAULT NULL,
is_servicecode varchar(1) not null default 'N'
);
注意保留字:select * from pg_get_keywords();
1、unreserved,不保留,可以用于任何identity(视图、表、函数、类型、索引、字段、类型 等名称)。
2、reserved,保留,不可用于任何identity。
3、reserved (can be function or type name),保留,但是可用于函数、类型名。
4、unreserved (cannot be function or type name),不保留,但是不可用于函数、类型名。
select into & create table as
-
SELECT INTO — SELECT
INTO从一个表中选取数据,然后把数据插入另一个表中。常用于创建表的备份复件或者用于对记录进行存档。SELECT * INTO films_recent FROM films WHERE date_prod >= '2002-01-01'; -
CREATE TABLE AS — 从一个查询的结果定义一个新表。只会复制表中的数据,表结构中的索引,约束等不会复制过来
CREATE TABLE films_recent as SELECT * FROM films WHERE date_prod >= '2002-01-01';
DML
-
基本DML语法
INSERT INTO table_name(x,x) VALUES (y,z); UPDATE table_name SET x=y; DELETE FROM table_name WHERE x=y; SELECT x FROM table_name WHERE y;
COPY
-
服务端COPY
copy tbl to 'filepath'; copy (SQL) to 'filepath'; copy tbl from 'filepath'; copy tbl from 'filepath' where x=y; pg12 这里的filepath都是指PostgreSQL数据库所在服务器的路径。需要数据库superuser权限。 -
客户端COPY
copy tbl to stdout; copy (query) to stdout; copy tbl from stdin; 以上客户端COPY不需要数据库superuser权限。通过标准输出、输入,可以实现COPY接收来自客户端的数据。 psql (\copy to | from); ----不需要数据库superuser权限。保存或者读取的文件是在客户端所在的服务器,不需要数据库superuser权限。
排序&分页
-
ASC或DESC关键词来设置排序方向为升序或降序。不指定默认为ASC。
''' -
NULLS FIRST和NULLS
LAST选项将可以被用来决定在排序顺序中,空值是出现在非空值之前或者出现在非空值之后。默认情况下,排序时空值被认为比任何非空值都要大,即NULLS FIRST是DESC顺序的默认值,而不是NULLS LAST的默认值。 -
顺序选项是对每一个排序列独立考虑的。
SELECT a, b FROM table1 ORDER BY a + b, c DESC; a + b, c DESC表示ORDER BY a + b ASC, c DESC,而和ORDER BY a + b DESC, c DESC不同。 -
LIMIT和OFFSET
select * from tbl_1 order by relname limit 10 offset 10; 使用ORDER BY子句把结果行约束成一个唯一的顺序,否则使用LIMIT和OFFSET将会得到一个随机的查询子集。
聚合
-
常用聚合函数详见官方手册
https://www.postgresql.org/docs/11/functions-aggregate.html -
查看数据库中所有的聚合函数
SELECT DISTINCT(proname) FROM pg_proc WHERE proisagg order by proname; -
举例
select array_agg(id) from (values(null),(1),(2)) as t(id);----计入空值 select avg(id) from (values(null),(1),(2)) as t(id); ----不计入空值 select count(id) from (values(null),(1),(2)) as t(id); ----不计入空值
DISTINCT和DISTINCT ON
-
语法
SELECT DISTINCT column_name1,column_name2,... FROM TABLE_NAME; SELECT DISTINCT ON (column_name1,column_name2),... FROM TABLE_NAME; DISTINCT:行内去重 DISTINCT ON:组内去重 -
举例
select distinct relname,relnamespace from pg_class; select distinct on (subject) subject,stu_name,grade from score;
表连接
-
交叉连接:表T1和T2的行的每一种可能的组合(即笛卡尔积)

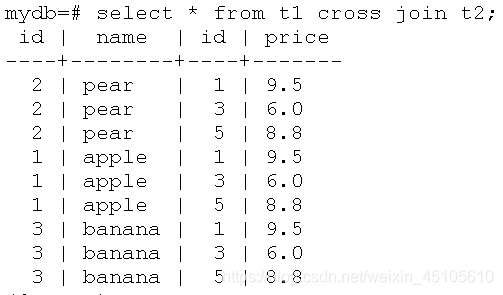
-
内连接:表T1和表T2做一个笛卡尔积,记为表T3,然后在T3中挑选出满足符合条件的内容。
SELECT * FROM t1 INNER JOIN t2 ON t1.id = t2.id; SELECT * FROM t1 INNER JOIN t2 USING (id); SELECT * FROM t1 NATURAL INNER JOIN t2;
-
左连接:在内连接的基础上,将T1中有但T2中没有的元组也加上。新增的元组左边照搬T1,右边为null。
SELECT * FROM t1 LEFT JOIN t2 ON t1.id = t2.id; SELECT * FROM t1 LEFT JOIN t2 USING (id);
-
右连接:在内连接的基础上,将T2中有但T1中没有的元组也加上。新增的元组左边为null,右边照搬T2。
SELECT * FROM t1 RIGHT JOIN t2 ON t1.id = t2.id; -
全连接:在内连接的基础上同时做左连接和右连接,表T1和表T2中的都要,两边不满足条件的都为null。
SELECT * FROM t1 FULL JOIN t2 ON t1.id = t2.id;
-
半连接 (in ,exists)
semi-join -
反连接 (not exists)
anti-join
组合查询
-
A UNION B 与 A UNION ALL B
取两个查询的并集,UNION默认会去重,即重复数据只会返回一行,如果需要保留重复数据所有行可以使用UNION ALL。UNION默认会去重,即重复数据只会返回一行,如果需要保留重复数据所有行可以使用UNION ALL。 -
A EXCEPT B 与 A EXCEPT ALL B
取两个查询的交集,EXCEPT默认会去重,如果需要保留重复数据所有行可以使用EXCEPT ALL。 -
A INTERSECT B 与 A INTERSECT ALL B
取两个查询的差集(除去B后),INTERSECT默认会去重,如果需要保留重复数据所有行可以使用INTERSECT ALL。
ALL|ANY|SOME
- ALL
expression operator ALL (subquery)
select * from T1 where id > ALL(select id from T2); - ANY
expression operator ANY (subquery)
select * from T1 where id > ANY (select id from T2); - SOME
expression operator SOME (subquery)
select * from T1 where id > SOME (select id from T2);
条件表达式
-
CASE
语法:
CASE WHEN condition THEN result
[WHEN …]
[ELSE result]
END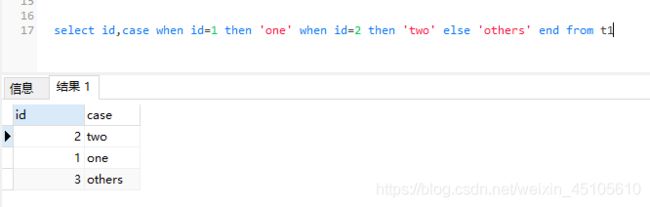
-
COALESCE
语法:COALESCE(value [, …])
COALESCE 函数返回它的第一个非空参数的值。 -
NULLIF
语法:NULLIF(value1, value2)
当value1和value2相等时, NULLIF返回一个空值。 否则它返回value1。 -
GREATEST 和LEAST
语法:
GREATEST(value [, …])
LEAST(value [, …])
GREATEST和LEAST函数从一个任意的数字表达式列表里选取最大或者最小的数值。
窗口函数
-
聚合和窗口函数的区别
聚合:聚合函数(sum,min,avg……) + GROUP BY
针对分组只返回一个结果
窗口函数:聚合函数(sum,min,avg……) + OVER ( …… ) + order by ( …… )
针对分组中的每一行返回函数的结果 -
常用窗口函数见官方手册
窗口函数大体上分为两大种:
(1)能够作为窗口函数的聚合函数(sum,avg,count,max,min);
(2)rank、dense_rank、row_number等专用窗口函数。
具体详见官方手册:https://www.postgresql.org/docs/11/tutorial-window.html -
举例
-
例1
创建学生成绩表score:
create table score(
id int PRIMARY key,
subject character(32),
stu_name character(32),
grade NUMERIC(3,0)
);
插入数据:
INSERT INTO SCORE(id,subject,stu_name,grade) values
(1,‘语文’,‘小王’,100),
(2,‘语文’,‘小张’,120),
(3,‘语文’,‘小李’,110),
(4,‘英语’,‘小王’,120),
(5,‘英语’,‘小张’,120),
(6,‘英语’,‘小李’,110),
(7,‘数学’,‘小王’,130),
(8,‘数学’,‘小张’,140),
(9,‘数学’,‘小李’,150),
(10,‘物理’,‘小李’,70),
(12,‘物理’,‘小张’,60),
(13,‘物理’,‘小王’,60); -
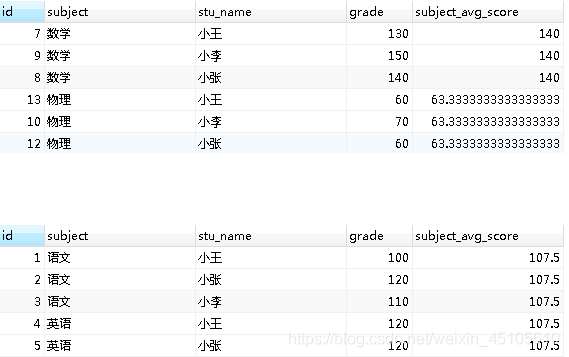
(1)avg() OVER()
求每个不同学科的平均值:
SELECT *,
avg(grade) OVER (PARTITION BY subject)
as subject_avg_score
FROM score;
(2)avg() OVER(),OVER为空
求所有学科的平均值:
SELECT *,
avg(grade) OVER () as subject_avg_score
FROM score;
(3)row_number()
对分组后的结果集标注行号:
SELECT row_number() OVER(partition by subject order by grade desc), *
FROM score;

(4)rank() 和dense_rank()
SELECT rank() OVER(partition by subject order by grade asc), *
FROM score;
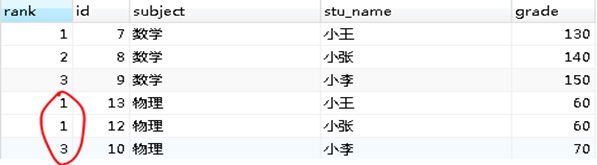
SELECT dense_rank() OVER(partition by subject order by grade asc), *
FROM score;

(5)窗口函数别名
select avg(grade) OVER®,sum(grade) OVER®,
* FROM
score WINDOW r as (PARTITION BY subject);
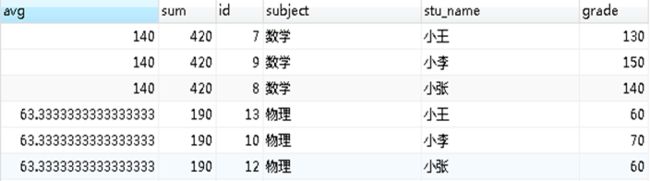
-
ddl in tran
例如:改表名,用t1替换t。
begin;
alter table t rename to t2;
alter table t1 rename to t;
commit; 1.
在t有人访问的时候执行修改命令,会被阻塞,等带事务结束才可以获取到锁,进行重命名。
执行修改命令被阻塞期间,开始的对t表查询,会被重命名的事务阻塞。
在修改事务获取到锁后,执行未完成期间,对t表的查询,同样会被阻塞,需要等重命名事务提交或回滚后才可以查询。
数据类型和操作符
PostgreSQL拥有大量的内置的数据类型用来存储不同类型的数据。
https://www.postgresql.org/docs/12/datatype.html
- 标准类型(Standard)
(1)Boolean and Logic
(2)Strings - char(n), varchar(n), text
(3)Numbers - integer, floating point, numeric
(4)Date/time - timestamp(), date, time(), interval() - 扩展类型(Extended)
(1)Geometric - point, line, box, etc
(2)Network - inet, cidr, macaddr
(3)Bit - bit, bit varying - 数组和复合类型(Arrays and Composite types)
- json/jsonb
- 系统类型(System types)
数值型
- smallint、integer、bigint类型都是整数类型,存储一定范围的整数,超出范围将会报错。
smallint 2字节
integer 4字节
bigint 8字节 - decimal和numeric存储指定精度的数据,可变长度。
- real和double precision指指定浮点数据类型,real支持4字节,double precision支持8字节。
- smallserial、serial、bigserial类型为自增serial类型:
smallserial 2字节
serial 4字节
bigserial 8字节
字符型
-
字符类型分类
character varying(n), varchar(n):变长,有限制
text:无限变长 -
char(n)和varchar(n)
(1)如果给定的一个字符型长度比n长,将会报错;
(2)char(n)末尾的空格,在两个char(n)比较时将被忽略掉,在转换为其他string类型时也会被去掉;
(3)char()或者char等同于char(1);
(4)varchar()或者varchar等同于一个没有长度限制的varchar。这是Postgres的扩展(extension)。
字符型模式匹配
PostgreSQL有三种方式实现模式匹配:
-
LIKE操作符
(1)语法
string LIKE pattern [ESCAPE escape-character] 用ESCAPE指定一个不同的逃逸字符
string NOT LIKE pattern [ESCAPE escape-character]
(2)举例
select ‘abc’ LIKE ‘abc’;
select ‘abc’ LIKE ‘a%’; -
SIMILAR TO(支持正则表达式,例如:)
(1)语法
string SIMILAR TO pattern [ESCAPE escape-character]
string NOT SIMILAR TO pattern [ESCAPE escape-character]
(2)举例
select ‘abc’ SIMILAR TO ‘a%’;
select ‘abc’ SIMILAR TO ‘%(b|d)%’; -
POSIX正则表达式
作符 描述 ~ 匹配正则表达式,大小写敏感 ~ * 匹配正则表达式,大小写不敏感 !~ 不匹配正则表达式,大小写敏感 !~* 不匹配正则表达式,大小写不敏感
日期/时间类型
- 日期/时间类型
timestamp [§][without time zone]:8字节,包括日期和时间(无时区)
timestamp [§] with time zone:8字节,包括日期和时间(有时区)
date:4字节,日期类型
time [§][without time zone]:8字节,时间类型(无时区)
time [§] with time zone:8字节,时间类型(有时区)
interval [fields][§]:16字节,时间间隔 - 特殊值
now – 当前事务开始时间
today, tomorrow, yesterday - 那天的midnight
epoch - unix epoch (midnight, Jan. 1, 1970) Unix系统时间
格式转换
PostgreSQL可以将日期/时间、整数、浮点、数字转换成字符串,以及将字符串转换成指定的数据格式。
- 日期和字符串的转换
to_char(current_timestamp,‘HH12:MI:SS’)
to_date(‘2020-01-08’,‘YYYY-MM-DD’)
to_timestamp(‘08 Jan 2020’,‘DD Mon YYYY’); - 数值与字符串的转换
to_char(20200108,‘999999999D99S’)
to_number(‘12,454.8-’,‘99G999D9S’)
日期/时间函数
-
获取当前完整时间
select now();
select current_timestamp; -
获取当前日期/时间
select current_date;
select current_time; -
计算两年后、两个月后的时间
select now()+interval ‘2 years’,now()+interval ‘2 month’; -
获取年份、月份
select extract(year from now()),extract(month from now()),extract(day from now());
数组
- 任何基本类型 (不是组合类型或域) 可以用作数组,只要在类型后面加一个中括号([]) 。
- 数组类型的定义
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
如上,表sql_emp中列pay_by_quarter类型为不限尺寸的一维integer类型数组,schedule为不限尺寸的二维text类型数组。
常量数组:’{{1,2,3},{4,5,6},{7,8,9}}’;
PostgreSQL 不强制要求定义数组大小,甚至维数也可以不定义。
数组输入
数组输入方式:'{ val1 delim val2 delim ... }'
例1:'{{1,2,3},{4,5,6},{7,8,9}}'
例2:INSERT INTO sal_emp
VALUES ('Bill',
'{10000, 10000, 10000, 10000}',
'{{"meeting", "lunch"}, {"training", "presentation"}}');
mydb=# select * from sal_emp ;
name | pay_by_quarter | schedule
------+---------------------------+-------------------------------------------
Bill | {27000,25000,10000,15000} | {{meeting,lunch},{training,presentation}}
访问数组
-
默认情况下,PostgreSQL为数组使用了一种从1开始的编号习惯,即一个具有 n 个元素的数组从 array[1] 开始,结束于array[n]。
mydb=# select pay_by_quarter[2] from sal_emp; pay_by_quarter ---------------- 25000 -
一个数组切片可以通过在一个或多个数组维度上指定下界:上界来定义,例如:
mydb=# select schedule[1:2] from sal_emp ;schedule ------------------------------------------- {{meeting,lunch},{training,presentation}} -
数组元素追加
通过array_append 函数或 || 操作符向数组末尾添加一个元素;
通过array_prepend函数在数组开头添加一个元素。mydb=# select array_append(array[1,2,3],4),array[1,2]||3; array_append | ?column? --------------+---------- {1,2,3,4} | {1,2,3} -
数组元素删除
通过array_remove 函数删除数组元素。mydb=# select array_remove(array[1,2,3,3,4,5],3); array_remove -------------- {1,2,4,5} -
数组元素更新
通过update更新整个数组或数组的某些元素。mydb=# update sal_emp set pay_by_quarter[3]=1000 where name='Bill'; UPDATE 1 mydb=# update sal_emp set pay_by_quarter[1:2]='{1000,2000}' where name='Bill'; UPDATE 1
数组函数
-
array_dims:返回数组维数的文本表示。
postgres=# SELECT array_dims(ARRAY[[1,2,3], [4,5,6]]); array_dims ------------ [1:2][1:3] -
array_cat:连接两个数组
postgres=# SELECT array_cat(ARRAY[1,2,3], ARRAY[3,4,5]); array_cat --------------- {1,2,3,3,4,5} -
array_length:返回数组长度
postgres=# SELECT array_length(array[1,2,3],1); array_length -------------- 3 postgres=# SELECT array_length(array[[1,2,3],[4,5,6]],1); array_length -------------- 2 postgres=# SELECT array_length(array[[1,2,3],[4,5,6]],2); array_length -------------- 3 -
unnest: 将数组元素转换为行
postgres=# SELECT unnest(ARRAY[1,2]); unnest -------- 1 2 postgres=# SELECT * from unnest(ARRAY[1,2],ARRAY['a','b','c']); unnest | unnest --------+-------- 1 | a 2 | b | c -
array_to_string: 使用字符串将数组元素连接起来
postgres=# select array_to_string(array[1,2,3,4,5],'xy'); array_to_string ----------------- 1xy2xy3xy4xy5 -
string_to_array:使用指定的分隔符将字符串分割为数组
postgres=# select string_to_array('1xy2xy3xy4xy5xy6','xy'); string_to_array ----------------- {1,2,3,4,5,6}
数组比较
-
值操作符ANY(array)
(1)SOME是ANY的同意词;
(2)如果数组中有任一元素都满足比较条件则返回TRUE;
1 = ANY(array[1,2]) = TRUE
2 < ANY(array[1,2]) = FALSE
(3)如果任一结果返回 TRUE,则表达式返回TRUE -
值操作符 ALL(array)
(1)如果数组中所有的元素都满足比较条件则返回TRUE;
1 = ALL(array[1,2]) = FALSE
0 < ALL(array[1,2]) = TRUE
(2)如果任一结果返回FALSE,则表达式返回FALSE。
json/jsonb
- 区别
json 插入快查询慢
jsonb插入慢查询快 - 数据读取
select j_ext->>‘mc’ from t limit 1; - 更多操作符和函数参见官方文档
https://www.postgresql.org/docs/12/functions-json.html - 12新特性JSONPath
jsonb_path_match
jsonb_path_query
类型转换
cast (列名 as newtype)
列名::newtype
数据库对象类型
- 数据库/模式/表空间
- 用户/角色
- 表/索引/视图/物化视图/函数/触发器/存储过程
- 插件/外部服务/外部表
…
https://www.postgresql.org/docs/current/sql-commands.html
-
索引
创建索引命令
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] 名称 ] ON [ ONLY ] 表名 [ USING 方法 ] ( { 列名称 | ( 表达式 ) } [ COLLATE 校对规则 ] [ 操作符类型的名称 ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] ) [ INCLUDE ( 列名称 [, ...] ) ] [ WITH ( 存储参数 = 值 [, ... ] ) ] [ TABLESPACE 表空间的名称 ] [ WHERE 述词 ] 索引种类 btree, gin, gist, spgist, brin, hash, rum 等 表达式索引 create index i_t_ext_mc on t using btree ((j_ext->>'mc')); 条件索引 create index i_t_xx on t (xx) where xx>1; 12新特性reindex concurrently -
内置函数
https://www.postgresql.org/docs/current/functions.html
select proname from pg_proc; -
常用运维函数
select id,md5(id::text) from generate_series(1,1000) id;
select pg_reload_conf();
select pg_blocking_pids();
select pg_terminate_backend();
select pg_cancel_backend();
select pg_switch_wal(); -
过程语言
PostgreSQL 允许用户自定义的函数,它可以用各种过程语言编写。
当前支持的过程语言:
PL/pgSQL
PL/Tcl
PL/Perl
PL/Python
PL/Java
PL/Ruby
其他语言可以由用户自定义 -
PL/pgSQL
PL/pgSQL是一种块结构(block-structured)的语言。 函数定义的所有文本都必须是一个块。 一个块用下面的方法定义:
[ <块中的每个声明和每条语句都是用一个分号终止的, 如果一个子块在另外一个块里,那么 END 后面必须有个分号,如上所述; 不过结束函数体的最后的 END 可以不要这个分号。
-
自定义函数
PL/pgSQL是 PostgreSQL 数据库系统的一个可装载的过程语言create or replace function random_string(integer) returns setof text as $body$ declare begin return query select array_to_string(array(select substring('赵钱孙李周吴郑王' FROM (ceil(random()*8))::int FOR 1) FROM generate_series(1, $1)), ''); return; end; $body$ language plpgsql volatile; - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - create or replace function random_string1(integer) returns text as $body$ select array_to_string(array(select substring('赵钱孙李周吴郑王' FROM (ceil(random()*8))::int FOR 1) FROM generate_series(1, $1)), ''); $body$ language sql volatile; - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - create or replace function create_hash_partition(t text,n int) returns text as $body$ begin for i in 0..n-1 loop execute format('create table %s_p%s partition of %s for values WITH (MODULUS %s, REMAINDER %s)', t, i, t, n, i); raise info 'create %_p%',t,i; end loop; return 'success'; end; $body$ LANGUAGE plpgsql; - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 函数的条件控制: IF-THEN / IF-THEN-ELSE / IF-THEN-ELSE IF / IF-THEN-ELSIF-ELSE 函数的循环:LOOP – EXIT (CONTINUE) WHILE / FOR 检查异常: EXCEPTION 游标: Cursor
高级SQL
- 数据抽样
- CTE&递归
- 全文索引
- 物化视图
- 模糊查询
- 数据批量更新
- 删除重复数据
- 字段加密
-
数据采样
select * from t order by random() LIMIT 1;
select * from t limit 1 offset floor(random()*记录数);
select * from t tablesample system(百分比) limit 1;
select * from t tablesample bernoulli(百分比) limit 1;
块级随机采样 system,采样比例过低可能查询不到数据
行级随机采样 bernoulli -
CTE&递归
CTE (common table expressions) 公共表表达式
WITH子句可以认为只存在于一个查询中的临时表
WITH RECURSIVE 递归查询例如,存在一张包含如下数据的test_area表。 id name fatherid 1 中国 0 2 辽宁 1 3 山东 1 4 沈阳 2 5 大连 2 6 济南 3 7 和平区 4 8 沈河区 4使用PostgreSQL的WITH查询检索ID为7以及以上的所有父节点,如下:
WITH RECURSIVE r AS ( SELECT * FROM test_area WHERE id = 7 UNION ALL SELECT test_area.* FROM test_area, r WHERE test_area.id = r.fatherid ) SELECT * FROM r ORDER BY id;查询结果如下:
id | name | fatherid ----+--------+---------- 1 | 中国 | 0 2 | 辽宁 | 1 4 | 沈阳 | 2 7 | 和平区 | 4 (4 rows) -
全文检索&全文索引
官方文档地址 http://postgres.cn/docs/11/textsearch.html
select * from t where to_tsvector(‘zhparsercfg’,c1) @@ to_tsquery(‘zhparsercfg’,’查询’);
select * from t where to_tsvector(‘zhparsercfg’,c1||c2||c3||c4) @@ to_tsquery(‘zhparsercfg’,’查询’);create index i_t_c1 on t using gin (to_tsvector(‘zhparsercfg’,c1) );
常用的中文分词插件 1. zhparser 2. jieba
-
物化视图
(1) 物化视图的定义:
VIEW 普通视图的作用在于避免用户直接接触数据表,而将数据表中允许用户看到的字段整合,方便查询。
MATERIALIZED VIEW 物化视图是视图的一种,但不同于普通视图,物化视图会独立存储视图中各个字段的值。相比较原本复杂的 SQL 查询而言,直接查询物化视图节省了大量的 SQL 解析、执行计划生成以及对目标数据的复杂关系计算的成本。而普通视图其本质只是存储了视图定义的查询 SQL 语句,当查询该视图时,本质还是查询的是定义视图的 SQL,这对于 SQL 性能优化没有帮助,普通视图只是一个虚拟表。
物化视图的特性(仅针对 ArteryBase):
物化视图会独立创建一个自己的表文件,如果物化视图中包含变长字段,也会创建一个关联的 Toast 表
物化视图可以创建自己的索引,但是无法创建主键
无法直接对物化视图进行 DML (INSERT、UPDATE、DELETE)操作(2) 物化视图的应用场景:
独立存储字段的值,可以用于优化表连接查询
用于统计信息的汇总(多表的指定字段值汇总到物化视图中)
存储临时/静态的查询结果(例如某项结果需要经常被查询,但并不关注该数据是否是实时的,且这样的 SQL 通常查询成本偏高,难以通过常规手段优化到可接受范围内,我们可以把数据存在物化视图里,以后只需要查询这个视图就可以)create materialized view mv_t1(id) as select id from t1; refresh materialized view mv_t1; create unique index on mv_t1(id); -
模糊查询
pg_trgm插件,支持前后双百分号like走索引create extension pg_trgm with schema public; create index i_t_name on t using gin (name gin_trgm_ops); -
数据批量更新
- 修改前:
update t set n_yx=1 where n_yx is null; - 修改后:
每次更新10000条,重复执行(可以使用shell脚本),直到矫正完全部数据。
update t set n_yx=1 where ctid=any(array(select ctid from t where n_yx is null limit 10000));
- 修改前:
-
新加字段数据批量更新
- 新增字段同时设置默认值,PG11新特性。新增带默认值的字段,不回写表
alter table t add column n_yx int default 1; - 删除默认值设置
alter table t alter column n_yx drop default;
- 新增字段同时设置默认值,PG11新特性。新增带默认值的字段,不回写表
-
删除重复数据
- 利用ctid删除表中的重复记录:
DELETE FROM t a WHERE
a.ctid <> (SELECT min(b.ctid) FROM t b where a.id =b.id); - 上述的SQL语句在表t的记录比较多时,效率比较差,这时可以使用下面更高效的删除表中重复数据的SQL:
DELETE FROM t WHERE ctid=ANY(ARRAY (SELECT ctid FROM
(SELECT row_number() OVER (PARTITION BY id),ctid FROM t) x
where x.row_number >1));
- 利用ctid删除表中的重复记录:
-
字段加密
pgcrypto 插件,支持对称加密和非对称加密参考官方文档
http://postgres.cn/docs/11/pgcrypto.html
事务隔离级别
事务的概念
事务(Transaction)是并发控制的基本单位。所谓事务是一个操作序列,这些操作要么都做,要么都不做,是一个不可分的工作单位。
事务通常以BEGIN开始,以COMMIT或ROLLBACK操作结束。
单语句事务
多语句事务
事务的特性
- A 原子性
- C 一致性
- I 隔离性
- D 持久性
数据库的并发和一致性
数据库一致性(Database Consistency)是指事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态
例:火车订票系统(无并发控制)的一个活动序列:
甲售票点读出某列车次车票剩余A=16
乙售票点读出某列车次车票剩余也为A=16
甲售票点卖出一张车票,修改余票A=A-1, A=15
乙售票点卖出一张车票,修改余票A=A-1, A=15
结果,卖出两张票,数据库中余票只减少1
数据库一致性被破坏
数据库的并发性是指DBMS需要对并发操作进行正确调度,使一个用户事务的执行不受其他事务的干扰,保证数据库的一致性
数据库并发可能存在的问题
-
脏读:
(针对未提交数据)如果一个事务中对数据进行了更新,但事务还没有提交,另一个事务可以“看到”该事务没有提交的更新结果,这样造成的问题就是,如果 第 一 个事务回滚,那么,第二个事务在此之前所“看到”的数据就是一笔脏数据。 -
不可重复读:
(针对其他提交前后,读取数据本身的对比)一个事务两次读同一行数据,可是这两次读到的数据不一样。不可重复读取是指同一个事务在整个事务过 程中 对同一笔数据进行读取,每次读取结果都不同。如果事务1在事务2的更新操作之前读取一次数据,在事务2的更新操作之后再读取同一笔数据一次,两 次结果是不同的。 -
幻读:
(针对其他提交前后,读取数据条数的对比) 一个事务执行两次查询,但第二次查询比第一次查询多出了一些数据行。 -
丢失更新:撤消一个事务时,把其它事务已提交的更新的数据覆盖了。
隔离级别
SQL92标准定义了4种隔离级别
Read uncommited
Read commited
Repeatable read
Serializable
隔离级别的特点
| 隔离级别 | 读脏数据 | 不可重复读 | 幻读 | 可串行化异常 |
|---|---|---|---|---|
| Read uncommited | 可能(pg不可能) | 可能 | 可能 | 可能 |
| Read commited | 不可能 | 可能 | 可能 | 可能 |
| Repeatable read | 不可能 | 不可能 | 可能(pg不可能) | 可能 |
| Serializable | 不可能 | 不可能 | 不可能 | 不可能 |
注:pg中一些数据类型和函数不遵循事务行为,如序列值变化对所有事务可见且不能回滚
PostgreSQL的事务隔离级别
- Read commited(默认值)
事务中的查询只能看到该查询(无for update/share子句)执行之前提交的数据
并发更新同一个元组时,一个事务提交,另一个事务对新元组进行更新(满足更新条件) - Repeatable read(快照隔离SI)
事务中的查询只能看到该事务执行之前提交的数据
晚于本事务开始的其它事务修改的记录,在本事务中不能被修改或锁定
并发更新同一个元组时,一个事务提交,另一个事务回滚
Pg9.1之前与Serializable行为相同 - Serializable(可串行化快照隔离SSI)
与Repeatable read是一样的,除了不允许串行化异常
发生串行化异常时,一个事务提交,另一个事务回滚
设置事务隔离级别
- 修改全局的事务隔离级别:
修改postgresql.conf中default_transaction_isolation参数
alter system set default_transaction_isolation to ‘serializable’; - 设置当前会话的事务隔离级别
session characteristics as transaction isolation level repeatable read; - 设置当前事务的事务隔离级别
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
PostgreSQL的并发控制
在多用户环境中,PostgreSQL使用多版本并发控制(Multiversion Concurrency Contro,MVCC)和多种锁相结合来维护数据的一致性
PostgreSQL的封锁类型
PostgreSQL的封锁有以下几类:
- 自旋锁(spinlock)
- 轻量级锁(LWLock)
- 常规锁(Lock)
-
自旋锁
一般不直接使用,而是利用它来实现其它锁(LWLock)。使用互斥信号量实现,自旋锁就是通过不停的循环检查锁的状态来获得封锁的机制。
特点:
封锁时间很短
没有等待队列,不支持死锁检测
自旋锁在锁等待期间会占用CPU
事务结束时不能自动释放 -
轻量锁
轻量锁通常使用自旋锁实现,主要提供对共享内存中数据结构的互斥访问,
支持读锁(LW_SHARED)和写锁(LW_EXCLUSIVE)两种模式。
读锁和读锁不冲突,读锁和写锁、写锁和写锁冲突。
特点:有等待队列、无死锁检测、能自动释放 -
常规锁
数据库事务管理中所指的锁,由LWLock实现
特点:有等待队列、自动进行死锁检测、能自动释放
封锁对象:
数据库对象:
表、事务
封锁时间(2PL)
对象打开的时候加锁
事务结束时放锁
-
锁的类型
ccessShareLock 1 owShareLock 2 owExclusiveLock 3 hareUpdateExclusiveLock 4 hareLock 5 hareRowExclusiveLock 6 xclusiveLock 7 ccessExclusiveLock 8 编号 锁模式 对应操作 预支冲突的模式 1 AccessShareLock SELECT 8 2 AccessShareLock SELECT FOR UPDATE/SHARE 7,8 3 RowShareLock INSERT/UPDATE/DELETE 5,6,7,8 4 RowExclusiveLock VACUUM(without full), ANALYZE, CREATE INDEX CONCURRENTLY, REINDEX CONCURRENTLY, CREATE STATISTICS, and certain ALTER INDEX and ALTER TABLE 4,5,6,7,8 5 ShareUpdateExclusiveLock CREATE INDEX(without CONCURRENTLY). 3,4,6,7,8 6 ShareLock CREATE TRIGGER and some forms of ALTER TABLE 3,4,5,6,7,8 7 ShareRowExclusiveLock REFRESH MATERIALIZED VIEW CONCURRENTLY. 2,3,4,5,6,7,8 8 ExclusiveLock DROP TABLE/TRUNCATE/REINDEX/CLUSTER /VACUUM FULL, and REFRESH MATERIALIZED VIEW (without CONCURRENTLY) Many forms of ALTER INDEX and ALTER TABLE LOCK TABLE statements that do not specify a mode explicitly 全部
其他
-
死锁
所谓死锁,是指两个或两个以上的进程(或线程)在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。死锁的检测
PostgreSQL自动检测死锁,检测到死锁后,回滚其中的一个语句。
对于多表死锁的预防办法是事务按照同一顺序对表加锁。
例如所有的应用开发人员都遵守下面的规则,当需要修改表和锁表时,按一定的顺序进行 -
查看系统的封锁状态
系统视图pg_locks
LOCKTYPE:封锁对象类型
DATABASE :数据库OID
RELATION : 表OID
PAGE : 页面号
TUPLE :元组号
VIRTUALXID/TRANSACTIONID
CLASSID/ OBJID/ OBJSUBID
VIRTUALTRANSACTION:封锁的事务
PID:会话号
MODE:封锁模式
GRANTED:是否获得
FASTPATH -
查看系统的封锁状态
SELECT * FROM pg_locks pl LEFT JOIN pg_stat_activity psa ON pl.pid = psa.pid; SELECT pg_blocking_pids(进程号) ; -
触发器
触发器声明了当执行一种特定类型的操作时数据库应该自动执行一个特殊的函数。
触发器函数必须在触发器本身被创建之前被定义好。触发器函数必须被定义成一个没有参数的函数,并且返回类型为trigger。
同一个触发器函数可以被用于多个触发器。
PostgreSQL同时提供每行的触发器和每语句的触发器。
触发器也可以根据它们是否在操作之前、之后触发,或者被触发来取代操作来分类。它们分别指BEFORE触发器、AFTER 触发器以及INSTEAD OF触发器create table t1 (id int ,name varchar(100)); create table t2 (id int ,name varchar(100),usr varchar(100), ipaddr varchar(100),time timestamp without time zone); -
创建插入数据的函数
create or replace function t1_logfunc() returns trigger as $body$ begin insert into t2(id, name, usr, ipaddr, time) values (new.id, new.name, current_user, inet_client_addr(), current_timestamp); return new; end; $body$ LANGUAGE plpgsql; -
创建触发器,调用上面的函数
create trigger trg1 after insert on t1 for each row execute procedure t1_logfunc();
-
插入记录,测试触发器
insert into t1 values (1,'zz'); postgres=# select * from t1; id | name ----+------ 1 | zz (1 row) postgres=# select * from t2; id | name | usr | ipaddr | time ----+------+----------+------------------+---------------------------- 1 | zz | postgres | 192.168.146.1/32 | 2020-03-01 16:50:03.652228 (1 row) -
事件触发器
与一个事件触发器相关的事件在事件触发器所在的数据库中发生, 该事件触发器就会被引发。当前支持的事件是 ddl_command_start、ddl_command_end、 table_rewrite和sql_drop。
ddl_command_end在同一组命令的执行之后发生。可以使用集合返回函数 pg_event_trigger_ddl_commands()得到发生的DDL操作的更多细节。
sql_drop为任何删除数据库对象的操作在 ddl_command_end事件触发器之前发生。可以使用集合返回函数 pg_event_trigger_dropped_objects()列出已经被删除的对象。CREATE FUNCTION trg2_func() RETURNS event_trigger LANGUAGE plpgsql AS $$ DECLARE obj record; BEGIN FOR obj IN SELECT * FROM pg_event_trigger_dropped_objects() LOOP RAISE NOTICE '% dropped object: % %.% %', tg_tag, obj.object_type, obj.schema_name, obj.object_name, obj.object_identity; END LOOP; END $$; CREATE EVENT TRIGGER trg2 ON sql_drop WHEN TAG in('drop table') EXECUTE PROCEDURE trg2_func(); -
规则
其它数据库系统定义活动的数据库规则,通常是存储过程和触发器。在PostgreSQL中,这些东西可以通过函数和触发器来实现。规则系统(查询重写规则系统)与存储过程和触发器完全不同。它把查询修改为需要考虑规则,并且然后把修改过的查询传递给查询规划器进行规划和执行。它非常强大,并且可以被用于许多东西如查询语言过程、视图和版本。
-
INSERT、UPDATE和DELETE上的规则
CREATE [ OR REPLACE ] RULE name AS ON event TO table [ WHERE condition ] DO [ ALSO | INSTEAD ] { NOTHING | command | ( command ; command ... ) } create table t01 (id int ,name varchar(100)); create table t02 (id int ,name varchar(100),time time_stamp); create or replace rule r01 as on insert to t01 do also insert into t02 values (new.id, new.name, now()); postgres=# insert into t01 values (1,'zz'); INSERT 0 1 postgres=# select * from t01; id | name ----+------ 1 | zz (1 row) postgres=# select * from t02; id | name | time ----+------+---------------------------- 1 | zz | 2020-03-01 13:49:08.727519 (1 row) create table t03 (id int ,name varchar(100),time timestamp without time zone); create or replace rule r02 as on update to t01 do also insert into t03 values (old.id,old.name,now()); postgres=# update t01 set name='tt' where id = 1; UPDATE 1 postgres=# select * from t01; id | name ----+------ 1 | tt (1 row) postgres=# select * from t03; id | name | time ----+------+---------------------------- 1 | zz | 2020-03-01 13:51:57.697101 (1 row) -
表继承
create table t (id int ,name varchar(100),info varchar(300)); create table t1 () inherits(t); create table t2 (j_ext jsonb) inherits(t); insert into t values (0,'zz','0'); insert into t1 values (1,'tt','1'); insert into t2 values (2,'yy','2','{"mc":"t2"}'); postgres=# select * from t; id | name | info ----+------+------ 0 | zz | 0 1 | tt | 1 2 | yy | 2 (3 rows) postgres=# select * from only t; id | name | info ----+------+------ 0 | zz | 0 (1 row) postgres=# select * from t2; id | name | info | j_ext ----+------+------+-------------- 2 | yy | 2 | {"mc": "t2"} (1 row) postgres=# \d+ t Table "public.t" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+------------------------+-----------+----------+---------+----------+--------------+------------- id | integer | | | | plain | | name | character varying(100) | | | | extended | | info | character varying(300) | | | | extended | | Child tables: t1, t2 Access method: heap postgres=# drop table t; ERROR: cannot drop table t because other objects depend on it DETAIL: table t1 depends on table t table t2 depends on table t HINT: Use DROP ... CASCADE to drop the dependent objects too. -
解除继承
alter table t2 no inherit t; -
分区表
分区的意思是把逻辑上的一个大表分割成物理上的几块。分区可以提供若干好处:
某些类型的查询性能可以得到极大提升。 特别是表中访问率较高的行位于一个单独分区或少数几个分区上的情况下。 分区可以减少索引体积从而可以将高使用率部分的索引存放在内存中。 如果索引不能全部放在内存中,那么在索引上的读和写都会产生更多的磁盘访问。
当查询或更新一个分区的大部分记录时, 连续扫描那个分区而不是使用索引离散的访问整个表可以获得巨大的性能提升。
如果需要大量加载或者删除的记录位于单独的分区上, 那么可以通过直接读取或删除那个分区以获得巨大的性能提升, 因为ALTER TABLE NO INHERIT和DROP TABLE 比操作大量的数据要快的多。这些命令同时还可以避免由于大量DELETE 导致的VACUUM超载。
很少用的数据可以移动到便宜一些的慢速存储介质上。
这种好处通常只有在表可能会变得非常大的情况下才有价值。 到底多大的表会从分区中收益取决于具体的应用, 不过有个基本的拇指规则就是表的大小超过了数据库服务器的物理内存大小。PG9.X 利用表继承配合触发器或规则实现
http://postgres.cn/docs/9.4/ddl-partitioning.html
PG10 支持声明式分区
http://postgres.cn/docs/10/ddl-partitioning.html
PG11、PG12分区表性能进行优化
分区表相关参数
constraint_exclusion=partition
第三方插件pg_pathman -
分区方式
- Range Partitioning
- List Partitioning
- Hash Partitioning
-
分区表创建
创建分区表create table t (c1 char(32), c2 char(32), c_name varchar(300)) partition by hash (c2);
创建分区create table t_p1 partition of t for values WITH (MODULUS 4, REMAINDER 0);
create table t_p2 partition of t for values WITH (MODULUS 4, REMAINDER 1);
create table t_p3 partition of t for values WITH (MODULUS 4, REMAINDER 2);
create table t_p4 partition of t for values WITH (MODULUS 4, REMAINDER 3); -
分区表分区管理
删除分区将其转换为独立表
alter table t detach partition t_p4;将表添加为分区
alter table t attach partition t_p4 for values WITH (MODULUS 4, REMAINDER 3); -
分区表的索引
分区键不是主键的,主键需要包含分区键。(c2为分区键)
alter table t add constraint pk_t primary key (c1,c2);
其他索引不需要包含分区键。
create index i_t_name on t (c_name); -
异步消息
监听listen channel; select * from pg_listening_channels();发布消息
notify channel , 'message'; select pg_notify('channel', 'message');取消监听
unlisten channel;
unlisten *; -
触发器内置发布消息
…